卷积神经网络|完整代码实现
发布时间:2024年01月06日
对于如何加载数据,在前面的文章中已经我们已经学会,那么接下来,就是要搭建卷积神经网络,并对网络进行训练,使其可以完成一些功能。
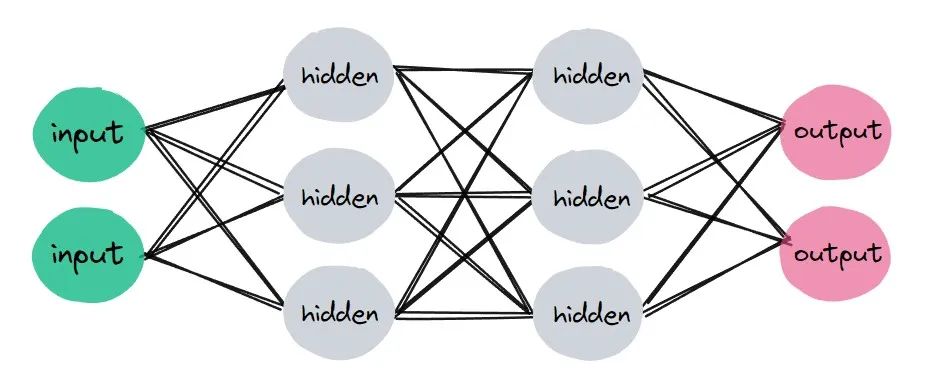
通常,训练一个神经网络需要这些步骤:
-
定义一个神经网络
-
准备一个可迭代的数据集
-
将数据集输入到神经网络进行处理
-
计算损失
-
通过梯度下降算法更新参数
好吧,明白大致步骤之后,就可以简单实现一个神经网络,并训练这个神经网络,使它可以用来完成一些超酷的事。so amazing!
import torchimport torchvisionimport torchvision.transforms as transformsimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimtrain_set = torchvision.datasets.FashionMNIST(root = 'FashionMNIST/',train = True,download = True,transform = transforms.Compose([transforms.ToTensor()]))test_set = torchvision.datasets.FashionMNIST(root = 'FashionMNIST/',train = False,download = True,transform = transforms.Compose([transforms.ToTensor()]))# 创建网络class Network(nn.Module):def __init__(self):super(Network,self).__init__()self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)self.fc1 = nn.Linear(in_features= 12*4*4, out_features=120)self.fc2 = nn.Linear(in_features= 120, out_features=60)self.out = nn.Linear(in_features=60, out_features=10)def forward(self, t):t = tt = F.relu(self.conv1(t))t = F.max_pool2d(t, kernel_size =2, stride=2)t = F.relu(self.conv2(t))t = F.max_pool2d(t, kernel_size=2, stride=2)t = t.reshape(-1, 12*4*4)t = F.relu(self.fc1(t))t = F.relu(self.fc2(t))t = self.out(t)return tnetwork = Network()if torch.cuda.is_available:network=network.cuda()train_loader = torch.utils.data.DataLoader(train_set, batch_size=100)test_loader=torch.utils.data.DataLoader(test_set, batch_size=100)optimizer = optim.Adam(network.parameters(), lr=0.01)for epoch in range(10):total_loss = 0total_correct = 0for batch in train_loader: # Get batchimages, labels =batchif torch.cuda.is_available:images=images.cuda()labels=labels.cuda()optimizer.zero_grad() #告诉优化器把梯度属性中权重的梯度归零,否则pytorch会累积梯度preds = network(images)loss = F.cross_entropy(preds, labels)loss.backward()optimizer.step()total_loss += loss.item()_,prelabels=torch.max(preds,dim=1)total_correct += (prelabels==labels).sum().item()accuracy = total_correct/len(train_set)print("Epoch:%d , Loss:%f , Accuracy:%f "%(epoch,total_loss,accuracy))#测试模型correct=0total=0network.eval()with torch.no_grad():for batch in test_loader:imgs,labels=batchif torch.cuda.is_available:imgs=imgs.cuda()labels=labels.cuda()preds=network(imgs)_,prelabels=torch.max(preds,dim=1)#print(prelabels.size())total=total+labels.size(0)correct=correct+int((prelabels==labels).sum())#print(total)accuracy=correct/total????print("Accuracy:?",accuracy)
环境:jupyter notebook
好吧,代码看起来似乎有点长,但其逻辑还是比较清晰的,我们可以很容易在代码中找到训练神经网络的对应的五个步骤.
明白整体逻辑很重要,然后再注重细节,这是一种可以快速学习知识的方法。
具体的细节大致有这些:每个层参数的设置,卷积核的大小,有无填充,步长,激活函数,损失函数,池化层等等当然,这是后话!
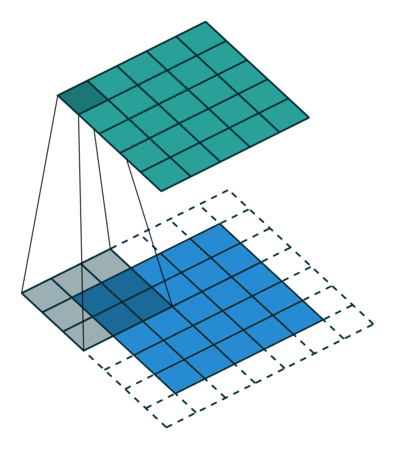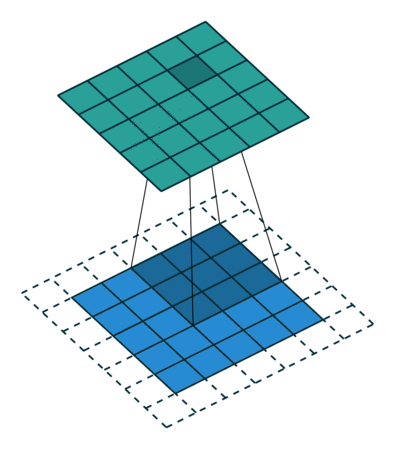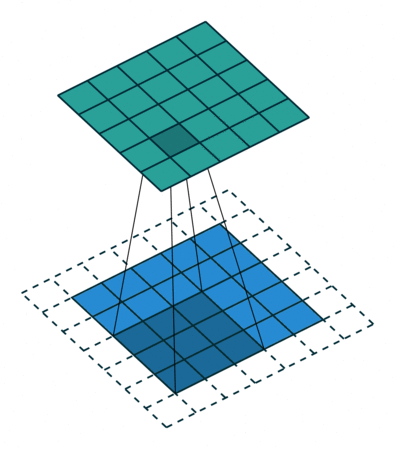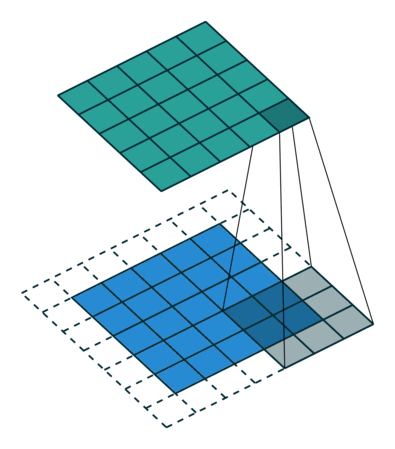
再次回顾我们的代码结构:
-
定义一个神经网络
-
准备一个可迭代的数据集
-
将数据集输入到神经网络进行处理
-
计算损失
-
通过梯度下降算法更新参数
那么到了这里,你已经有一个可以完成预测目标的神经网络了,请确保此网络在你的电脑上能运行起来!这样会对代码有更深的理解,赶紧打开电脑试试吧!
文章来源:https://blog.csdn.net/m0_57569438/article/details/135428786
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TA百人计划学习笔记 3.1.2深度测试
- Python通过函数名调用函数的几种场景
- P with Spacy:自定义文本分类管道
- 【推荐100个unity插件】3D物品描边效果——Quick Outline免费插件
- 水印消除:三种简单方法教你如何去除图片水印
- 【JUC】二十九、synchronized锁升级之轻量锁与重量锁
- C++学习笔记(二十五):c++ 智能指针
- 开启新篇章!迅软科技牵手行业巨擘,引爆开门红!
- 云服务器哪家强?当属阿里云腾讯云or华为云?
- 【代码随想录06】454. 四数相加 II 383. 赎金信 15. 三数之和 18. 四数之和