Python实现自动化办公(使用第三方库操作Excel)
发布时间:2024年01月18日
1 使用 xlrd 读取Excel数据
1.1 获取具体单元格的数据
import xlrd
# 1. 打开工作簿
workbook = xlrd.open_workbook("D:/Python_study_projects/Python自动化办公/Excel/test1.xlsx")
# 2. 打开工作表
sheet1 = workbook.sheets()[0] # 选择所有工作表中的第一个
# 下面方法也可以
# sheet1 = workbook.sheet_by_index(0)
# sheet1 = workbook.sheet_by_name("Sheet1")
# 3.通过行号和列号读取具体单元格中的数据
data = sheet1.cell_value(0, 0) # 获取第 0行,第 0列的数据
print(data)
1.2 批量获取数据
相关知识:
获取所有工作表的数目
# 获取所有工作表的数目
sheet_nums: int = workbook.nsheets
print(sheet_nums) # 返回一个整数获取所有工作表的名称
# 获取所有工作表的名称
sheet_names: list = workbook.sheet_names()
print(sheet_names) # 返回一个列表获取一张表中单元格的行数
# 获取一张表单元格的行数
rows_num: int = sheet1.nrows
print(rows_num)获取一张表中单元格的列数
# 获取一张表单元格的列数
cols_num: int = sheet1.ncols
print(cols_num)?
批量读取数据:【代码】
# 批量读取数据
sheets = workbook.sheets()
for sheet in sheets: # 遍历所有的工作表
rows_num: int = sheet.nrows # 获取一张表中的所有行
cols_num: int = sheet.ncols # 获取一张表中的所有列
for row in range(rows_num): # 遍历行
for col in range(cols_num): # 遍历一行中的所有列
print(sheet.cell_value(row, col), end="\t\t\t\t")
print()
print("-------------------------")2 使用xlwt 向Excel中写入数据
2.1 向Excel中具体的单元格中写入数据
import xlwt
# 1.首先创建一个工作簿
people = xlwt.Workbook()
# 2.创建一个工作表
sheet = people.add_sheet('人员表')
# 3.写入数据
sheet.write(0, 0, '姓名')
sheet.write(0, 1, '性别')
sheet.write(0, 2, '年龄')
# 保存文件
people.save('D:/Python_study_projects/Python自动化办公/Excel/people.xlsx')2.2 向Excel中批量写入数据
import xlwt
# 1.首先创建一个工作簿
people = xlwt.Workbook()
# 2.创建一个工作表
sheet = people.add_sheet('人员表')
# 3.写入数据
list_detail = [{"student_id": "1001", "name": "张三", "sex": "男"},
{"student_id": "1002", "name": "李四", "sex": "女"},
{"student_id": "1003", "name": "王五", "sex": "男"}]
row = 0
for rows in list_detail:
for i, key in enumerate(rows): # enumerate()遍历对象,返回下标和数据
sheet.write(row, i, rows[key])
row = row + 1
# 保存文件
people.save('D:/Python_study_projects/Python自动化办公/Excel/people.xlsx')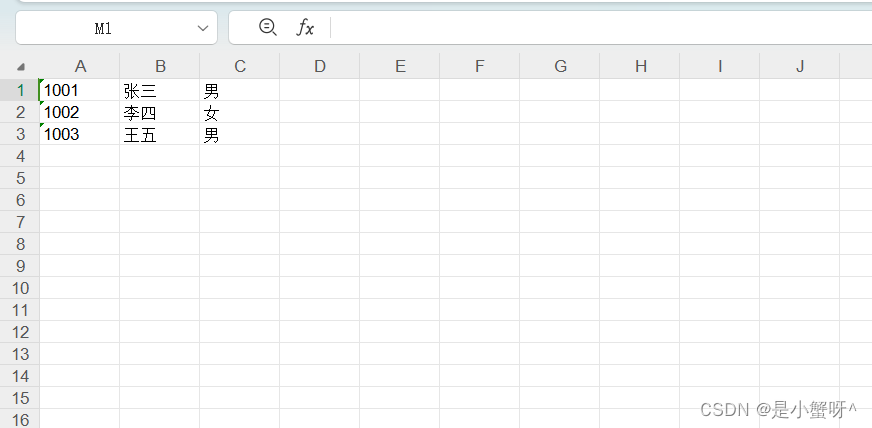
3 使用 xlutils 修改Excel工作簿
# 需要导入两个包,因为必须打开文件,才能作修改
import xlrd
from xlutils.copy import copy
# 1.首先打开需要读的工作簿并获取到具体得到工作表
read_book = xlrd.open_workbook('D:/Python_study_projects/Python自动化办公/Excel/test1.xlsx')
read_sheet = read_book.sheets()[0]
# 2.先拷贝一份作为修改
write_book = copy(read_book)
# 在拷贝的工作簿中获取工作表
write_sheet = write_book.get_sheet(0)
# 3.遍历所有行,并修改下标为3的列的内容
for row in range(read_sheet.nrows):
write_sheet.write(row, 3, "修改的内容")
write_book.save("D:/Python_study_projects/Python自动化办公/Excel/test1_修改后.xlsx")4 使用 openpyxl 读取Excel内容
注意openpyxl 和前面的xlrd不一样,openpyxl读取的行列是从1开始的,这就对应了Excel表格中的行列的位置
import openpyxl
# 读取操作
# 打开工作簿
workbook = openpyxl.load_workbook('D:/Python_study_projects/Python自动化办公/Excel/test1.xlsx')
# 选择第一个工作表
sheet_1 = workbook['Sheet1']4.1 读取具体单元格中的数据
# 获取指定单元格数据
cell = sheet_1.cell(1, 1) # 第一个参数是行,第二个参数是列
print(cell.value)4.2 读取指定行的数据
# 获取指定行的数据读 (取第三行数据)
cell_list = sheet_1[3] # 参数 3表示第几行
for cell in cell_list: # 遍历第三行,获得所有单元格
print(cell.value)4.3 读取所有行中的单元格的数据
# 读取所有的行中的指定单元格
for row in sheet_1.rows:
print(row[1].value)4.4 读取所有行中的所有单元格
读取所有行中的所有单元格,并读取一行放入列表中输出
# 读取所有的行中的所有单元格
for row in sheet_1.rows:
row_text_list = []
for cell in row:
row_text_list.append(cell.value)
print(row_text_list)4.5 读取某些行
# 输出最大行数和列数、最小行数和列数 注意这边下标是从 1 开始的
print(f"最大行数: {sheet.max_row}")
print(f"最小行数: {sheet.min_row}")
print(f"最大列数: {sheet.max_column}")
print(f"最小列数: {sheet.min_column}")# 读取某些行
# for col in sheet_1.iter_cols(min_col=2, max_col=4, min_row=1, max_row=3, values_only=True):
for row in sheet_1.iter_rows(min_row=2):
# 里面参数指定读取的范围
for cell in row:
print(cell.value)
for row in sheet_1.iter_rows(min_row=2, max_row=4, min_col=1, max_col=3):
# 里面参数指定读取的范围
for cell in row:
print(cell.value)5 使用 openpyxl 向Excel中写入数据
5.1 向已有的Excel文件中写入数据
from openpyxl import workbook, load_workbook
# 读取操作
"""
1.打开已有的文件
"""
# 打开工作簿
wb = load_workbook('D:/Python_study_projects/Python自动化办公/Excel/test1.xlsx')
# 选择第一个工作表
sheet = wb.worksheets[0]
# 获取到具体的单元格
cell = sheet.cell(1,2)
cell.value = "姓名hello"
wb.save('D:/Python_study_projects/Python自动化办公/Excel/test1.xlsx')5.2 向没有的Excel文件中写入数据
文件不存在,首先需要创建
from openpyxl import workbook, load_workbook
"""
2.如果文件不存在,则直接创建
"""
wb1 = workbook.Workbook() # 创建工作簿
sheet1 = wb1.worksheets[0]
# 找到单元格
cell = sheet1.cell(1,2)
# 写入内容
cell.value = "hello"5.3 向Excel文件中批量写入数据
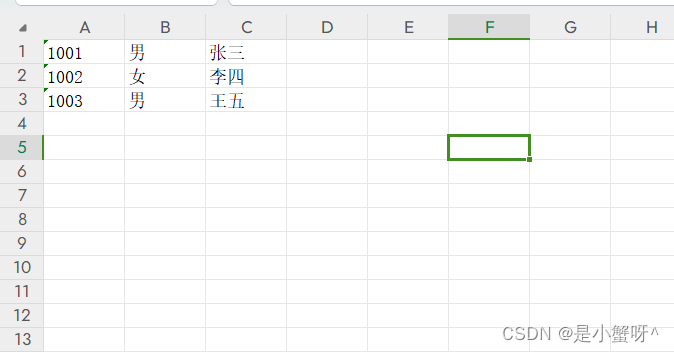
wb1 = workbook.Workbook() # 创建工作簿
sheet1 = wb1.worksheets[0]
list_detail = [{"student_id": "1001", "name": "张三", "sex": "男"},
{"student_id": "1002", "name": "李四", "sex": "女"},
{"student_id": "1003", "name": "王五", "sex": "男"}]
row = 1
for rows in list_detail:
for i, key in enumerate(rows):
cell = sheet1.cell(row, i+1)
cell.value = rows[key]
row += 1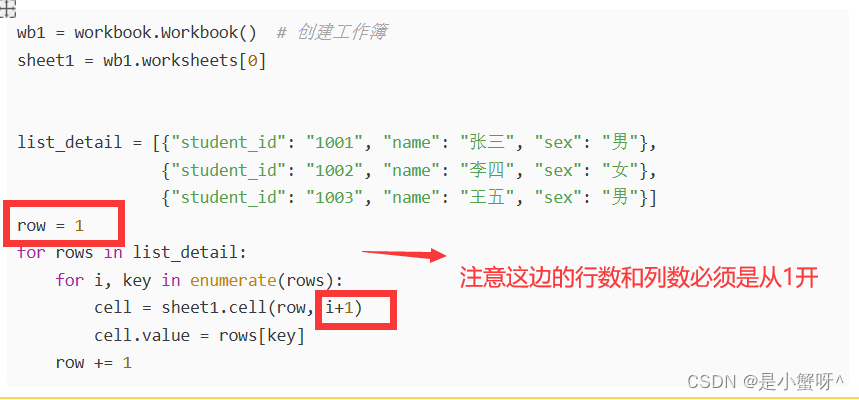
?
文章来源:https://blog.csdn.net/m0_61495539/article/details/135680908
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 批量创建文件夹事半功倍,有三种方法可以实现
- 国产CRM厂商迎来替代迁移“东风”
- NLP论文阅读记录 - 2021 | WOS01 通过对比学习增强 Seq2Seq 自动编码器进行抽象文本摘要
- 原创AI图片可定制可商用
- 【ctf】whireshark流量分析之tcp_杂篇
- 如何制作网址链接活码?网址二维码生成器的使用方法
- Git常用命令总结
- 解决ELement-UI懒加载三级联动数据不回显(天坑)
- 微服务-理论(CAP,一致性协议)
- 洛谷 P1020 导弹拦截 (dp+二分+Dilworth 定理)