CNN:Convolutional Neural Network(上)
目录
3? Convolution v.s. Fully Connected
原视频:李宏毅 2020:Convolutional Neural Network
1? 为什么使用 CNN 处理图像
李宏毅老师提出了以下三点理由。
① Some patterns are much smaller than the whole image.
通常来讲,图片的一些样式(pattern)远比整张图片小,从而使一个神经元不需要观察整张图片就能够发现某个样式(pattern),这样做还能减少网络中的参数。

比如,可以让一个神经元专门充当鸟嘴检测器(beak detector),它只需要关注这张图片中是否出现了鸟嘴这一样式(pattern),而不需要关注整张图片中的所有样式(pattern)。
② The same patterns appear in different regions.
在不同的图片中可能存在相同的样式(pattern),但是这些样式(pattern)可能出现在图片中的不同位置。在 CNN 中,将会使用同一神经元来检测相同的样式,避免参数的冗余。
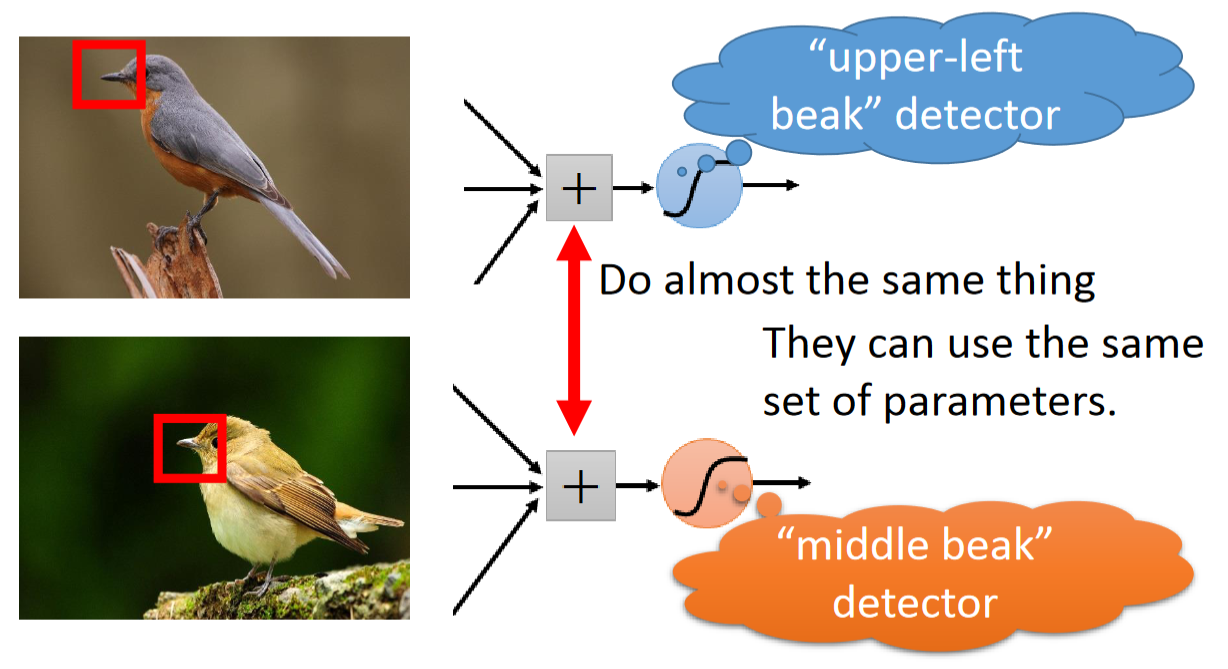
比如,针对鸟嘴这一样式(pattern),CNN 不会专门拿两个神经元来分别检测 “左上角的鸟嘴” 和 “中间的鸟嘴”,而是复用同一神经元。
③ Subsampling the pixels will not change the object.
取一张图片像素的子集可能并不会影响整张图片的内容。这样做能减小图片的大小,从而减少网络中的参数。

比如,去除这张图片中的奇数行和奇数列,图片变为原始图片的 1/4,但这并不影响我们获取图片中的内容。
2? CNN 的整体结构
CNN 的整体结构如下图所示,其中 Convolution 和 Max Pooling 结构可以叠加多次:

CNN 各部分的性质(property):
- Convolution 实现上一节提到的 ①② 功能
- Max Pooling 实现上一节提到的 ③ 功能
2.1? Convolution
本节将具体介绍 Convolution 模块是干啥的。
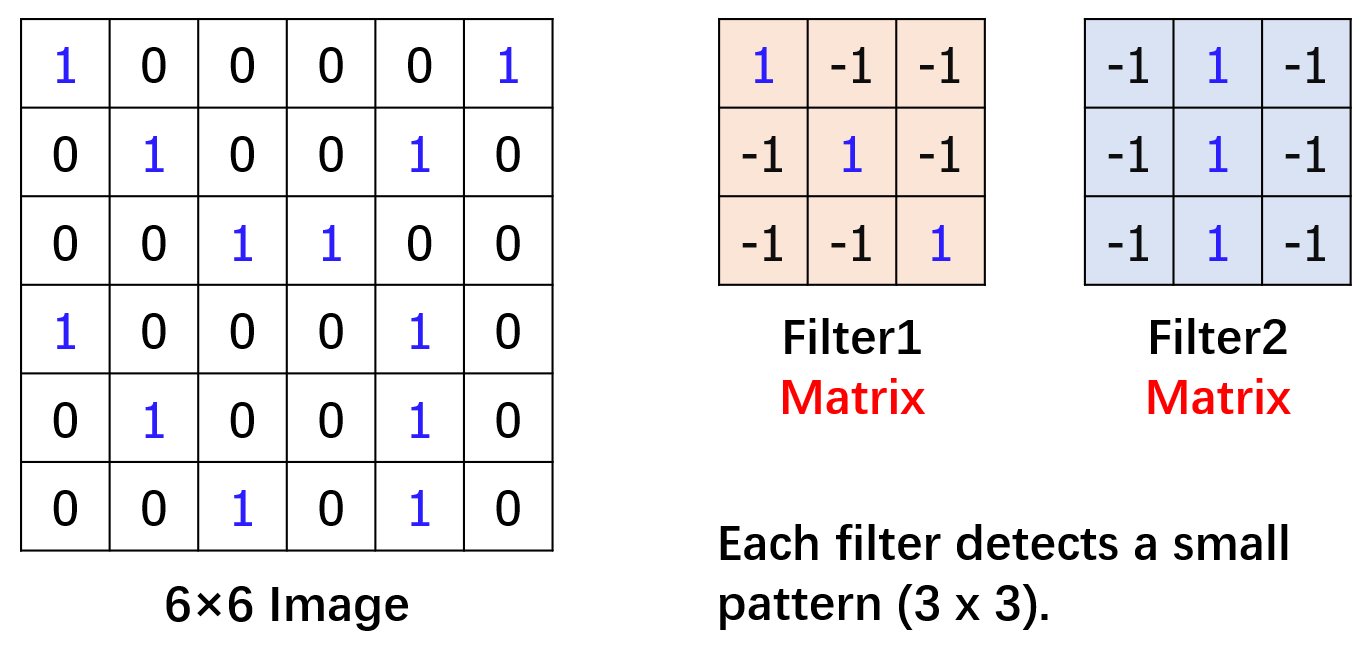
假设这里有一张非常简单的黑白图片,大小为 6×6 个像素,1 表示黑色,0 表示白色。同时,提出一个新的概念叫 “过滤器”(filter)。假设这里只有两个过滤器(filter),均为 3×3 的矩阵。
过滤器(filter)的个数不限,不同的过滤器(filter)将被用于检测图片中的不同样式(pattern),实现了上一小节中提到的 ① 号功能。
为了检测图片中的样式(pattern),这两个过滤器(filter)将会分别和图片进行一个称为卷积(convolution)的操作。下面这个动图演示得非常直观(图源:卷积层 | 鲁老师):

具体来说,就是过滤器(filter)会逐行逐列扫描整张图片。被扫描到的图片区域将会和过滤器(filter)进行逐元素相乘再相加,如下图所示:
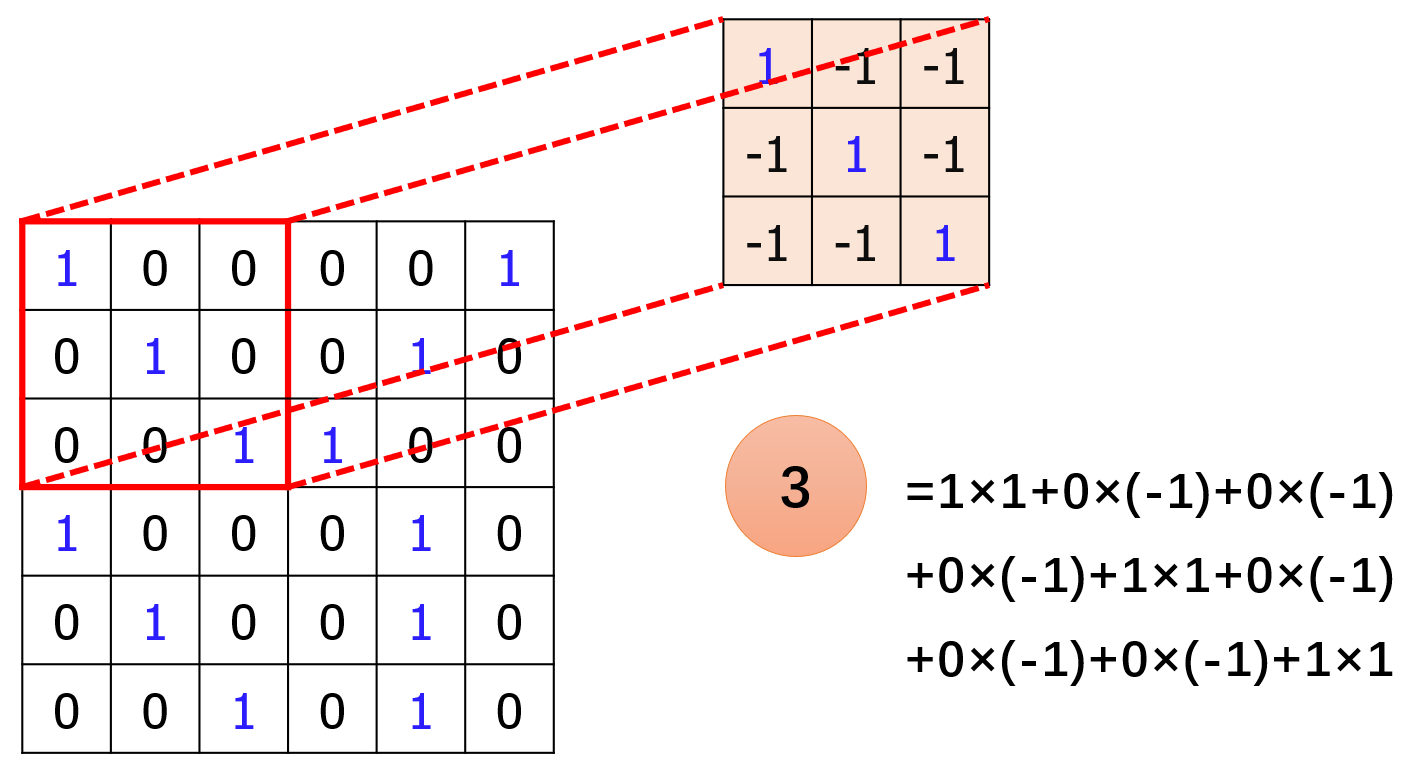
接着,过滤器(filter)会移动一个步长(stride),和下一个被扫描到的图片区域进行卷积操作。假设步长(stride)为 1,则有:
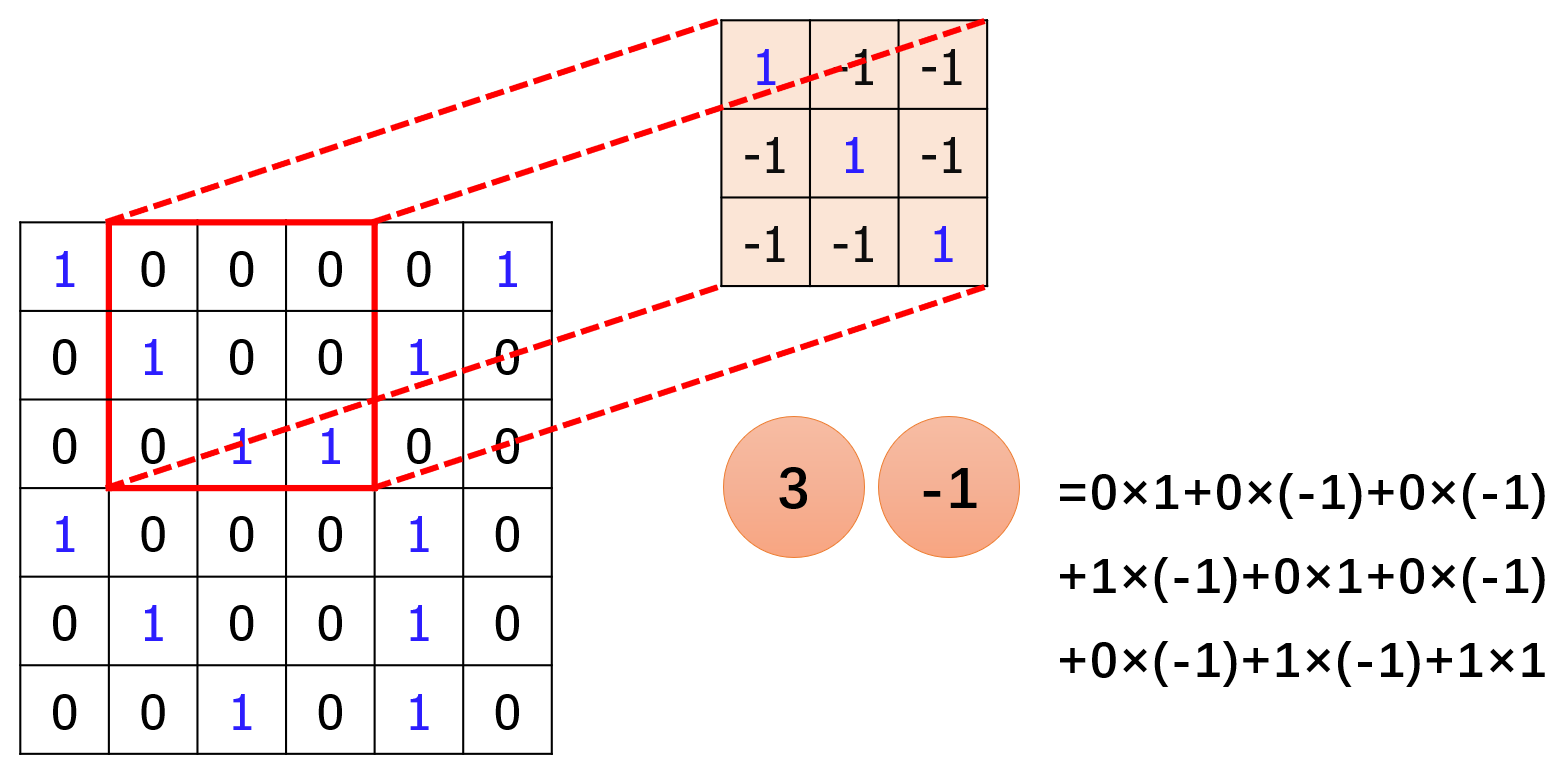
假设步长(stride)为 2,则有:

显然,你发现过滤器扫描不到图片的一些边缘位置,因此人们提出可以为图片 “加边”,也就是加一圈 0,然后再做卷积操作。
这里我们就假设步长(stride)为 1,把所有卷积操作做完,结果如下:
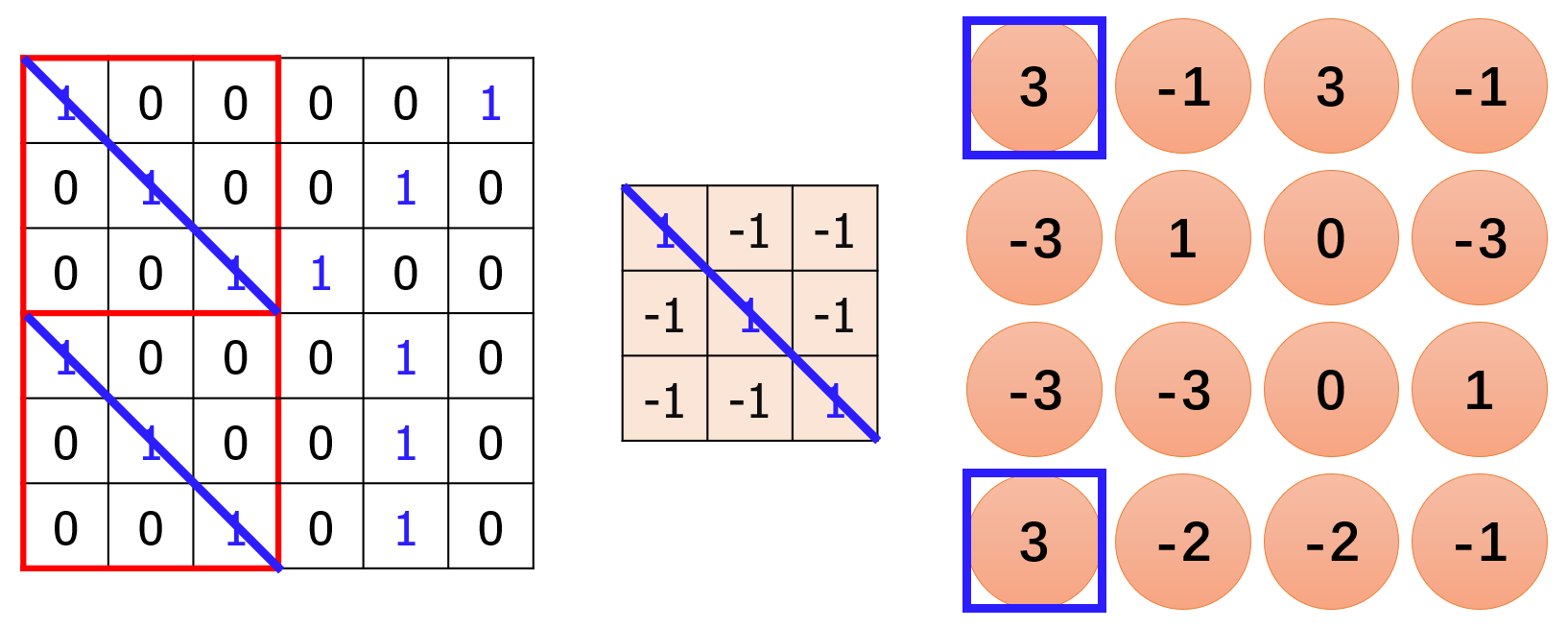
众所周知,向量点积的结果值越大,代表两个向量越相似。在卷积结果中,左上角和左下角的结果值最大。追溯到原始图片,左上角和左下角的图片确实和过滤器(filter)的结构类似。而过滤器(filter)自身的数值代表一种样式,因此可以认为图片的左上角和左下角存在该过滤器(filter)代表的样式(pattern),实现了上一小节中提到的 ② 号功能。
类似地,我们做第二个过滤器(filter)和图片的卷积操作:
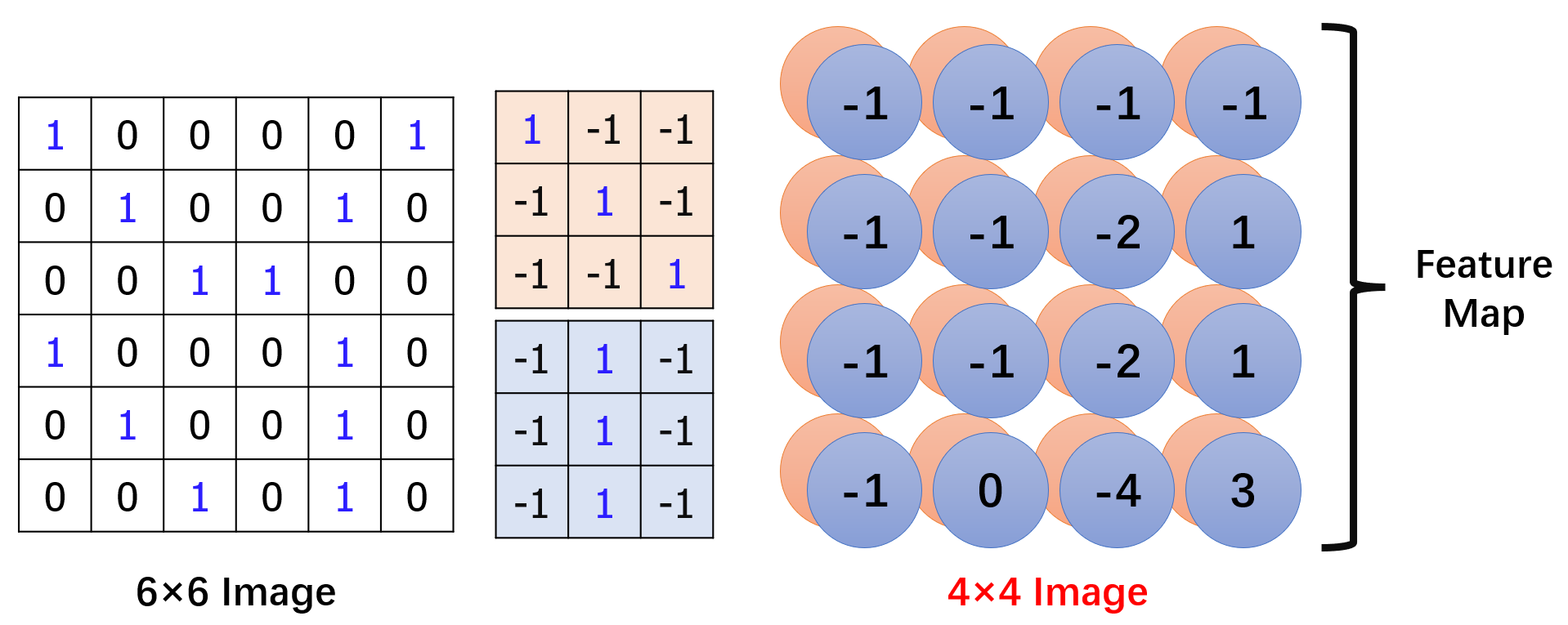
图片和两个过滤器(filter)分别得到两个卷积结果,被统称为 “Feature Map”,这里的卷积结果均为 4×4 的图片。
卷积结果的大小取决于图片大小、步长大小和过滤器大小。
2.2? Colorful image
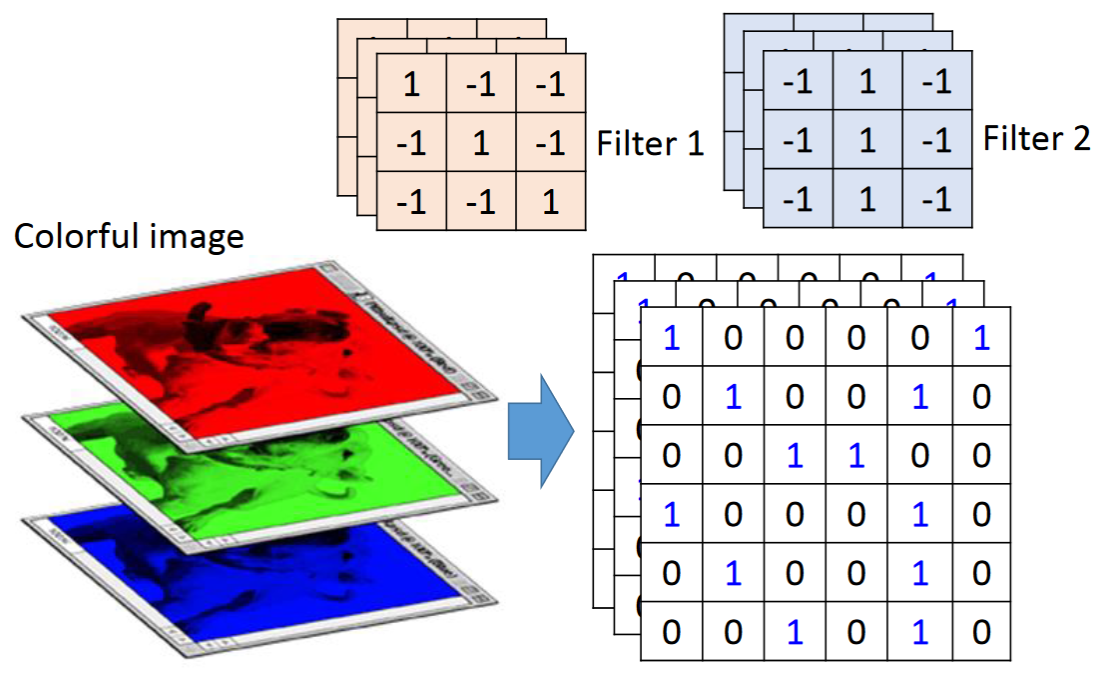
在 2.1 节,我们讨论的是简单的黑白照片,每一个像素点由一个数值组成。
对于彩色照片,每一个像素点由三个数值组成,因此过滤器(filter)不再是一个二维向量,而是升级成了一个三维向量。这个第三维被称为 “通道”(channel)。
3? Convolution v.s. Fully Connected
请不要认为卷积(Convolution)是一个与全连接(Fully Connected)毫无关系的、新鲜的操作,它其实就是全连接(Fully Connected)的一个简化版。下图是两者的比较:

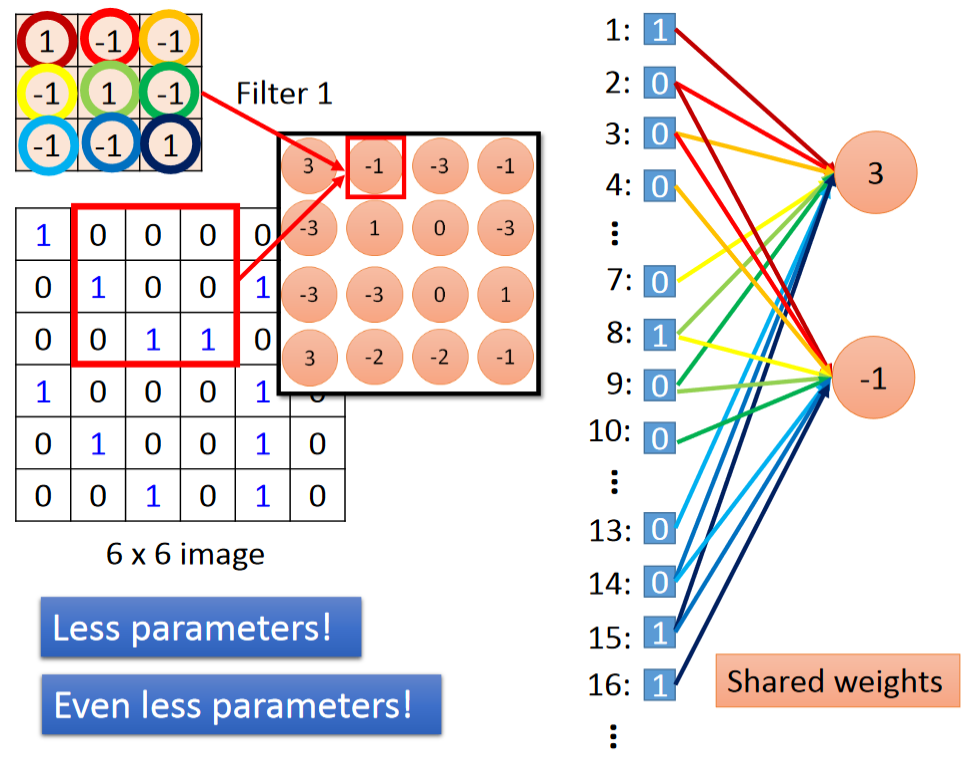
这里过滤器(filter)中的数值等价于全连接(Fully Connected)中的黑线,即充当一个权重的作用。换句话说,它们就是网络中的参数(parameter),是在模型训练中学习而来的。而绿框中的圆圈都代表的是一个神经元。
下面具体来看如何将 CNN 中的卷积(Convolution)操作理解为简化版的全连接。
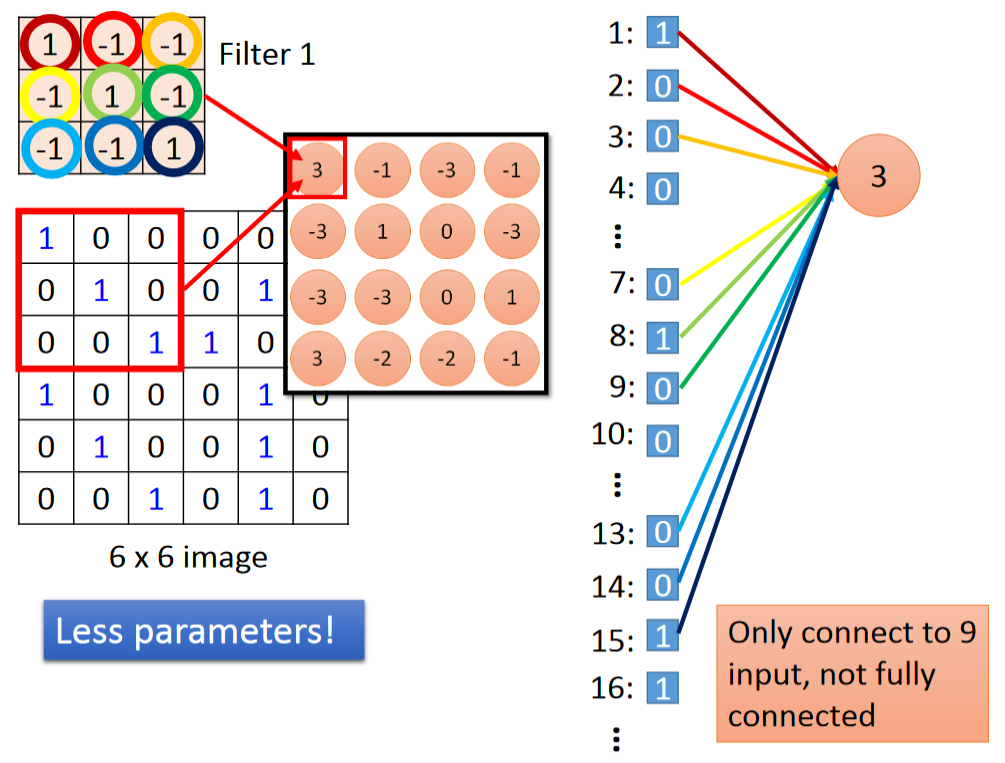
对于全连接(Fully Connected),每个神经元等于所有输入的加权求和;而对于卷积(Convolution),每个神经元只等于部分输入的加权求和。比如,对于第一个神经元,它只需要关注 1、2、3、7、8、9、13、14、15 号输入。这样的部分连接能够减少网络中的参数!
再来看第二个神经元,由于它是和第一个神经元同属于一个过滤器(filter)卷积得到的结果,因此它连接 2、3、4、8、9、10、14、15、16 号输入的参数和第一个神经元是对应相同的。在图中,李宏毅老师用相同的颜色表示具有相同参数的连接。这样的设定又能够进一步减少网络中的参数!
4? Max Pooling
Max Pooling 模块主要实现了 CNN 的 ③ 号功能,即缩小原始图片的大小。比如,在通过卷积(Convolution)模块后我们得到以下结果:
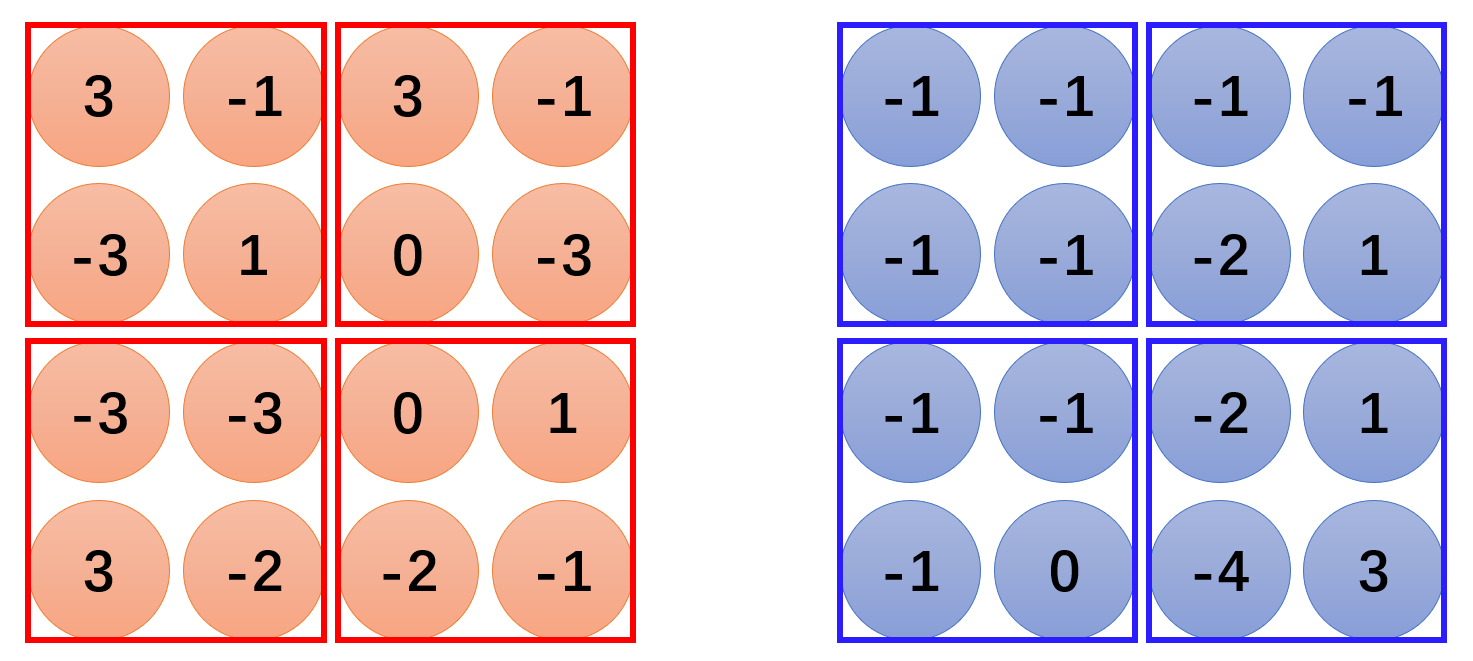
为了缩小原始图片的大小,Max Pooling 操作可能是在一个 2×2 的范围内取其中的最大值,操作结果如下图最右侧所示:

我们最后得到的新图片将比原始图片小,同时新图片的通道数(channel)等于过滤器(filter)的个数。
5? Flatten
Flatten 模块所做的事,就是把新图片的皮展开,即把每个通道的值挨个挨个地排开,最后送入 FFN 中,如下图所示:

6? CNN in Keras
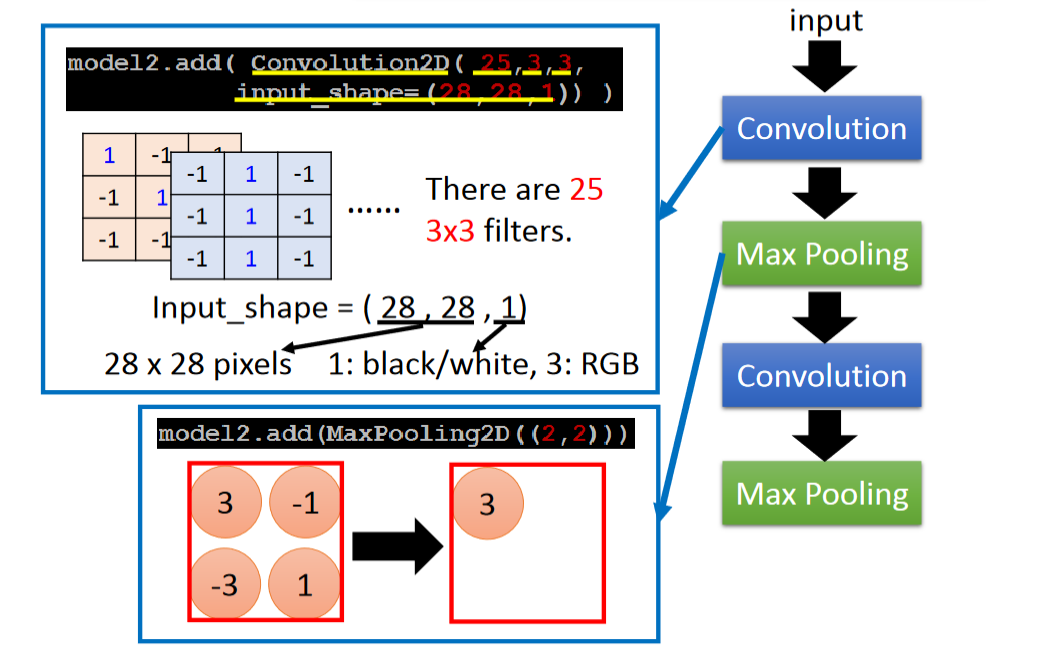
这一页介绍了每个函数参数的含义:
这一页介绍了每个过滤器(filter)含有的参数个数:
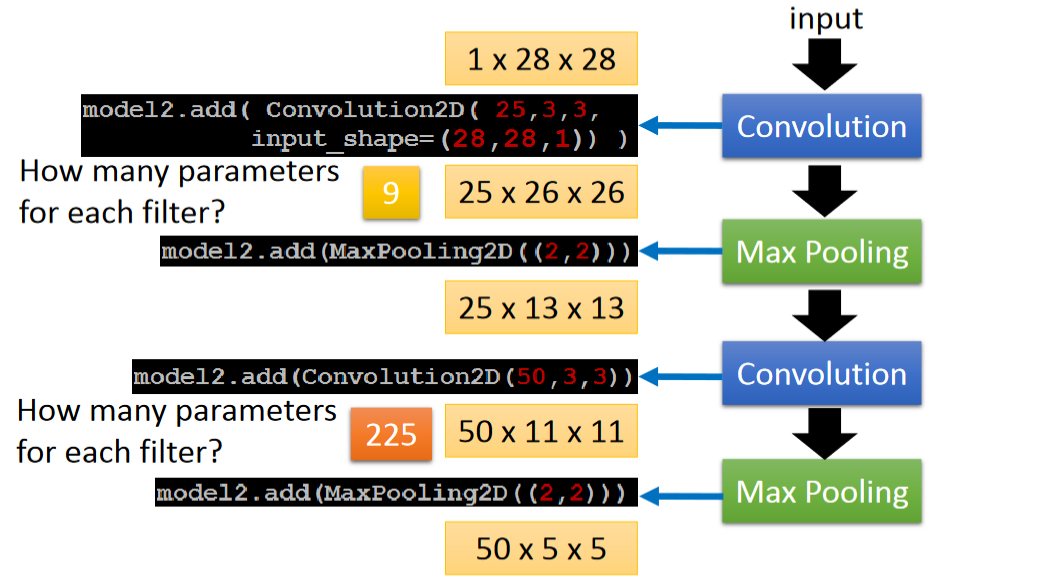
9 是因为 3×3,225 是因为 25×3×3,因为第一个 Max Pooling 后的新图片有 25 个通道(channel),因此相应地,第二个 Convolution 中的过滤器(filter)也应该有 25 个通道(channel)。
介于篇幅过长,将于下一篇介绍 CNN 的有趣应用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 家庭教育|孩子教育小妙招,让孩子更优秀
- T-SQL 备份数据库
- 慕课热搜01
- Python中matplotlib库的使用2
- LLM、AGI、多模态AI 篇五:基于LoRA微调ChatGLM3
- USACO历年青铜组真题解析 | 2023年12月Farmer John Actually Farms
- 腾讯云轻量应用服务器快速入门_建站/环境部署/云盘/电商/宝塔/SRS教程汇总
- cookie共享和session共享实例演示
- python Socket无限发送接收数据
- 超全面网络安全学习知识——(黑客)自学