MySQL数据库学习三
5 事务隔离级别
RC 和 RR 主要有几个区别:
1、 RR 的间隙锁会导致锁定范围的扩大。
2、 条件列未使用到索引,RR 锁表,RC 锁行。
3、 RC 的“半一致性”(semi-consistent)读可以增加 update 操作的并发性。
在 RC 中,一个 update 语句,如果读到一行已经加锁的记录,此时 InnoDB 返回记录最近提交的版本,由 MySQL 上层判断此版本是否满足 update 的 where 条件。若满足(需要更新),则 MySQL 会重新发起一次读操作,此时会读取行的最新版本(并加锁)
实际上,如果能够正确地使用锁(避免不使用索引去枷锁),只锁定需要的数据,用默认的 RR 级别就可以了。
在我们使用锁的时候,有一个问题是需要注意和避免的,我们知道,排它锁有互斥的特性。一个事务或者说一个线程持有锁的时候,会阻止其他的线程获取锁,这个时候会造成阻塞等待,如果循环等待,会有可能造成死锁。
6 死锁
6.1 锁的释放与阻塞
回顾:锁什么时候释放?
事务结束(commit,rollback);客户端连接断开。
如果一个事务一直未释放锁,其他事务会被阻塞多久?会不会永远等待下去?如果是,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。
[Err] 1205 - Lock wait timeout exceeded; try restarting transaction
MySQL 有一个参数来控制获取锁的等待时间,默认是 50 秒。
show VARIABLES like 'innodb_lock_wait_timeout';
对于死锁,是无论等多久都不能获取到锁的,这种情况,也需要等待 50 秒钟吗?那不是白白浪费了 50 秒钟的时间
6.2 死锁的发生和检测
| Session1 | Session2 |
|---|---|
| begin; | |
| select * from t2 where id =1 for update | |
| begin; | |
| delete from t2 | |
| update t2 set name= ‘4d’ where id =4 | |
| delete from t2 where id =1 |
在第一个事务中,检测到了死锁,马上退出了,第二个事务获得了锁,不需要等待50 秒:
[Err] 1213 - Deadlock found when trying to get lock; try restarting transaction
为什么可以直接检测到呢?是因为死锁的发生需要满足一定的条件,所以在发生死锁时,InnoDB 一般都能通过算法(wait-for graph)自动检测到。
那么死锁需要满足什么条件?死锁的产生条件:
因为锁本身是互斥的,(1)同一时刻只能有一个事务持有这把锁,(2)其他的事务需要在这个事务释放锁之后才能获取锁,而不可以强行剥夺,(3)当多个事务形成等待环路的时候,即发生死锁。
6.3 查看锁信息(日志)
SHOW STATUS 命令中,包括了一些行锁的信息:
show status like 'innodb_row_lock_%'
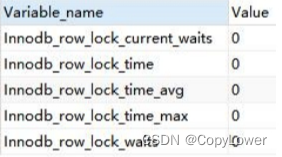
Innodb_row_lock_current_waits:当前正在等待锁定的数量;
Innodb_row_lock_time :从系统启动到现在锁定的总时间长度,单位 ms;
Innodb_row_lock_time_avg :每次等待所花平均时间;
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间;
Innodb_row_lock_waits :从系统启动到现在总共等待的次数。
SHOW 命令是一个概要信息。InnoDB 还提供了三张表来分析事务与锁的情况
select * from information_schema.INNODB_TRX; -- 当前运行的所有事务 ,还有具体的语

select * from information_schema.INNODB_LOCKS; -- 当前出现的

select * from information_schema.INNODB_LOCK_WAITS; – 锁等待的对应关系

如果一个事务长时间持有锁不释放,可以 kill 事务对应的线程 ID,也就是INNODB_TRX 表中的 trx_mysql_thread_id,例如执行 kill 4,kill 7,kill 8
当然,死锁的问题不能每次都靠 kill 线程来解决,这是治标不治本的行为。我们应该尽量在应用端,也就是在编码的过程中避免。
6.4 死锁的避免
1、 在程序中,操作多张表时,尽量以相同的顺序来访问(避免形成等待环路);
2、 批量操作单张表数据的时候,先对数据进行排序(避免形成等待环路);
3、 申请足够级别的锁,如果要操作数据,就申请排它锁;
4、 尽量使用索引访问数据,避免没有 where 条件的操作,避免锁表;
5、 如果可以,大事务化成小事务;
6、 使用等值查询而不是范围查询查询数据,命中记录,避免间隙锁对并发的影响
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用js做随机切换功能
- 实战之-Redis代替session实现用户登录
- 门控循环单元(GRU)-多输入回归预测
- 分享5款简单实用的软件,值得收藏
- 满意度问卷如何做SPSS数据分析论文?
- K8s:Pod生命周期
- Open CV 图像处理基础:(六)在Java中使用 Open CV进行图片翻转和图片旋转
- [USACO 1.1.3]黑色星期五
- StringBuilder、StringBuffer
- 【诊断】linux系统下的内存溢出问题定位