超简单,不用GPU,3步教你轻松在笔记本上部署聊天大模型 LLaMA
大家好啊,我是董董灿。
今天带大家在自己的电脑(笔记本)上部署一个类似于 chatGPT 的 AI 聊天大模型。
部署完之后,你就拥有了一个私人 AI 聊天机器人,无需联网,随时进行实时对话。
0. 简单说下背景
大模型我们都不陌生了,但是以 chatGPT 为代表的大模型是闭源的,他们的源代码不开放,我们只能用他们的商业化产品。
好在 Meta(也就是原来的 FaceBook)?开源了他们家的大模型 LLaMa。
之所以叫“大”模型,是因为它的参数量巨大。
以 LLaMa举例子,它开源了 LLaMa-7B, LLaMa-33B 等模型,后面的数字就代表着参数数量。
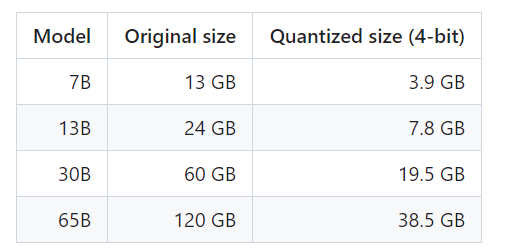
7B,就意味着参数有 70 亿,但是很多人微调后,发现它的效果却一点也不输拥有几千亿的 chatGPT-3.5 模型。
但是参数量大,就会对计算机的算力有更高的要求,因此很多大模型,基本部署都是要求在 GPU 上进行。

后来有人为了在传统 CPU 电脑上运行大模型,就开发了比较牛的框架,我们今天要用的,就是其中的一个明星产品:llama.cpp 。

它是全部使用 C++ 语言来重写的 llama 项目,不像 python 那样需要依赖大量的包,显的臃肿。
而且这个 C++ 项目可以利用 CPU 的特性,完成模型的极致性能优化。
举个例子:llama.cpp 项目中,针对 Intel CPU 会利用 avx2 向量指令集来做优化。
avx2 指令集有些小伙伴可能不清楚,但是之前看过我的小册(计算机视觉从入门到调优)内容的同学肯定知道。
我在小册中就利用 avx2 指令集完成了对 resnet50 这个神经网络的性能优化,下图是小册中关于 avx2 部分的介绍。

总的来说,llama.cpp 项目不仅可以运行在 CPU 上,而且对于电脑的配置要求也不高。
一般有 4G 以上的内存就够了,这点要求基本上很多笔记本都可以满足要求。
另外需要说明的是,我本身很少用?Windows 和?MacOS?环境做开发,因此本篇文章以?Linux?环境来介绍,并且默认大家熟悉 Linux 操作。
如果没有Linux 环境,可以参考这篇文章快速搭建一个:不用虚拟机,10 分钟快速在 windows 下安装 linux 系统。(右键复制链接打开)
至于 Windows 和 MacOS 环境的部署,可以去项目主页查看说明自行完成,llama.cpp 项目主页:https://github.com/ggerganov/llama.cpp/tree/master
好了,话不多说,我们直接开始,以下 3 步轻松搞定。
1、下载?llama.cpp 源码并编译
以下所有命令均在 Linux Ubuntu 环境下执行。
如果缺少 Linux 命令,使用?`sudo apt-get install` 来安装。
如果缺少 python 包,使用 `pip3 install `命令来安装。
首先,利用 git 下载?llama.cpp 源码。
git?clone?git@github.com:ggerganov/llama.cpp.git下载完成后,进入 llama.cpp 目录。
cd?llama.cpp执行 make 命令,完成编译。
make编译完成后,在 llama.cpp 目录下,会看到一个名称为?main?的可执行文件,这个就是等会要启动聊天的执行文件。
只要网络链接没问题,这一步很快就可以完成。
2. 下载量化后的模型文件
很多文章把这部分讲复杂了,我今天看了一些文章感觉也很吃力,跟别提新手了。
所以这部分我不打算介绍任何知识点,我们不用关心什么是量化操作,直接下载一个已经量化好的模型使用就行。
这一步需要从 huggingface (这是一个专门保存大模型的网站) 下载大模型(主要就是70 亿的参数)。
第一次下载估计很多人都会遇到问题,因此,我直接给出可行的步骤,一定按步骤来做。
复制以下 3 条命令,在 Linux 环境下执行:
pip3 install -U huggingface_hubpip install -U "huggingface_hub[cli]"export?HF_ENDPOINT=https://hf-mirror.com
简单来说就是访问 huggingface 的国内镜像网站,而不去访问国外的 huggingface 网站。
执行完上面两步后,执行:
huggingface-cli download TheBloke/Llama-2-7b-Chat-GGUF llama-2-7b-chat.Q4_K_M.gguf --local-dir .该命令会直接把模型文件下载到执行该命令的目录下,建议以上所有命令都在 llama.cpp 根目录下执行。
从上面的命令中我们可以看出,下载的是 llama-2-7b 模型,也就是有着 70 亿参数的那个模型。
需要说明一下,由于模型文件比较大,这一步下载时间会比较长,耐心等待即可,中途如果有问题可以多尝试几次。
3、开始聊天吧
下载完模型后,就可以直接开始聊天了。
在 llama.cpp 目录下执行:
./main -m llama-2-7b-chat.Q4_K_M.gguf -c 4096 --temp 0.7 --repeat_penalty 1.1 -i就会进入聊天交互界面,在交互界面里,就开始你的畅聊体验吧,你可以问这个模型任意问题,由它来回答。

比如,我问了一个问题:“Three birds in the tree, i killed one by a gun, how many birds left?”
模型竟然先反问了我一下,确认是不是这个问题,在我回答“yes"后,它才开始回答。
通过以上这 3 步就完成了大模型部署,是不是感觉挺简单的?
需要说明的是,上面的示例中我下载的是 llama-7b 模型,它还不支持中文。
如果你想要进行中文对话,可以去 hugging-face 网站上找一些支持中文的模型来下载,其余的步骤不变。
好啦,今天关于如何在 CPU 上部署大模型的介绍到这,如果体验成功的小伙伴记得回来点个赞哦。
延伸阅读:手把手教你免费升级 GPT-4。
文章原创,请勿随意转载,转载请联系作者授权,谢谢配合。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- QT上位机开发(文件对话框和目录对话框)
- LeetCode 每日一题 Day 13 || BFS
- open failed: ENOENT (No such file or directory) 解决办法
- MySQL——进阶篇
- 星筱授权系统源码有后台
- CSGO服务器搭建细节
- 智慧工地源码,数字孪生可视化大屏,支持多端展示(PC端、手机端、平板端)
- 怎么他们都有开源项目经历|手把手教你参与开源
- 机器学习_基本机器学习术语
- Day01 【苍穹外卖】环境搭建和前后端联调