简单了解Redis,及其持久化机制之AOF和RDB模式
认识Redis
Redis简介
一个分布式缓存系统,初学者可以认为是一个独立于Python应用之外的字典。除了缓存功能,还有数据库MQ的特性。
Redis缓存的重要性
缓存将用户需要的数据放到离用户最近的地方,提供访问速度,特别是访问频繁的热点数据,可以节省不必要的计算访问消耗(计算
、网络传输、内存占用、数据库资源占用)
- 独立应用系统之外的缓存系统,应用系统崩溃,对redis缓存系统不受影响
- 功能强大,数据类型丰富。是目前分布式缓存系统中功能最强大,支持的数据类型最丰富的缓存系统
- 上手容易,易于使用。采用键值对的形式存取数据。
Redis和MySQL的区别
MySQL是一个关系型数据库,能够保证数据库事务的ACID(原子性、一致性、隔离性、持久性)四个特性的数据库系统,需要通过SQL语句进行访问操作
Redis属于NoSQL数据库范围,既不需要通过SQL语句访问的数据库。NoSQL数据库还包括:ElasticSearch、MongoDB等等,Redis只是其中一个成员。Redis不支持数据库事务,无法保证ACID四大特性。
| 比较项 | MySQL | Redis |
|---|---|---|
| 事务特性 | 支持 | 不支持 |
| 访问数据 | 慢 | 快 |
| 学习成本 | 高 | 低 |
Redis的基本操作
redis系统目前主要支持linux系统,windows系统版本较老。
Linux系统安卓Redis
1、下载
$ wget https://download.redis.io/releases/redis-x.x.x.tar.gz
2、解压
$ tar xzf redis-x.x.x.tar.gz
3、打开redis目录
$ cd redis-x.x.x/
4、make命令安装redis
$ make
启动Redis服务端
$ src/redis-server
启动Redis客户端
$ src/redis-cli
Redis命令
redis下有很多的操作命令,包含丰富的数据类型,Strings、Hashes、Lists、Sets、Zsets等,详见之前的文章
1、为什么要做持久化
Redis的数据都存储在内存中,如果没有配置持久化,一旦断电、服务出现崩溃、或者redis重启后数据就全丢失了。
于是需要开启redis的持久化功能,将数据保存在硬盘上,当redis服务重启后,可以把存储在磁盘上的数据加载到内存当中,这样就不需要重新通过复杂的逻辑计算放到内存当中,而是直接通过硬盘来恢复数据,保证数据的快速恢复功能。
Redis针对这种情况提供了一种机制,可以使用这种机制,像数据库那样可以持久化放到磁盘上去。
2、持久化的好处
当redis在运行当中,通过持久化机制,放到内存中,当崩溃的时候,数据还可以在硬盘中找到,可以从指定文件从磁盘去加载数据。
但,这种持久化没有办法100%保证数据一定会持久化到硬盘上,可能会有数据丢失。
3、RDB持久化流程
-
客户端直接通过命令BGSAVE或者SAVE来创建一个内存快照
-
BGSAVE调用fork来创建一个子进程,子进程负责将内存快照写入磁盘,而父进程仍然继续处理命令。
当redis客户端,set一个值的时候,这个请求会把值放到内存里。如果做持久化的机制,必须还把这个key value的值使用线程放到硬盘里。线程会另外抽一个时间去放到磁盘,请求和线程不会同时去做,因此不确保每次请求,数据都持久化到磁盘(即使set成功了,但是数据不一定到磁盘上去)。 -
SAVE执行SAVE命令过程中,不再响应其他命令。
4、开启RDB持久化
在redis.conf中调整save配置项,当在规定的时间内,redis发生了写操作的个数满足条件会触发发生BGSAVE命令。当不满足条件时,手动执行BGSAVE命令也可以触发保存。
# 900秒之内至少一次写操作
save 900 1
# 300秒之内至少发生10次写操作
save 300 10
# 60秒之内发生至少10000次
save 60 10000
内存的操作非常快,微秒级别,如果超过1毫秒,就属于慢操作了。
如果sql超过500毫秒,就要优化了。硬盘的io操作是非常长的。差距是几百倍,甚至是上千倍。
5、RDB的优缺点
| 优点 | 缺点 |
|---|---|
| 对性能影响最小 | 同步时丢失数据 |
| RDB文件进行数据恢复比使用AOF要快很多 | 如果数据集非常大且CPU不够强(比如单核CPU), Redis在fork子进程时可能会消耗相对较长的时间,影响Redis对外提供服务的能力 |
6、RDB持久化效果验证
1、启动redis服务
sudo src/redis-server redis.conf
2、登录到redis客户端
sudo src/redis-cli
3、设置a的值
> set a 3
> get a
> 3
4、查询到redis-server的进程,10401
> ps -ef|grep redis
5、kill掉redis-server进程,模拟断电。
sudo kill -9 pid
6、redis-server会显示“已杀死”,再查询a的值,返回null,因为没有做持久化
> get a
> null
7、修改redis.conf(windows:redis.windows.conf), sudo vim redis.conf,找到save命令,save配置项,改成 save 3 3,同时检查下文件名dbfilename dump.rdb
8、重启redis服务,执行set操作。执行3次才触发了bgsave操作。
如果3秒中之内,没有满足3次set操作,是否会保存呢?
不会,所以仍然可能存在数据的丢失,可以用多个组合起来去触发bgsave命令。
当不满足次数时,手动执行bgsave命令,也可以触发保存。
> set a 1
> set b 2
> set c 3
9、看到redis的log,子进程10475保存了内存快照到硬盘上。并且路径下多了一个dump.rdb的数据文件,数据就是存在此文件中的。
Server initialized
Ready to accept connections
3 changes in 3 seconds. Saving...
Background saving started by pid 10475
DB saved on disk
RDB:0 MB of memory used by copy-on-write
Background saving terminated with success
10、再次模拟断电
11、重启redis,使用get命令查询a,b, c的值,都可以查询到。并且在重启时,会看到log比之前没有持久化的时候多了一条。DB loaded from disk:0.000 seconds
7、AOF持久化方式
AOF持久化方式,针对RDB进行了改进,AOF会记录每次服务器收到的写操作,作为日志存储下来,比RDB的内存快照更细致一些。数据的丢失基本不会有,但是性能也不会那么强悍。
当服务器重启的时候会重新执行这些命令来恢复原始的数据化方式,能够在指定的时间间隔对你的数据进行快照存储。
BGREWRITEAOF命令可以触发日志重写或自动重写,废除对同一个Key历史的无用命令,重建当前数据集所需的最短命令序列。例如同一个key,有多个set命令,那么触发日志重写后,它只会记录最后一个set命令,前面对此key的set命令就不会被log了。
意外重点,如果最后的命令只写了一部分,恢复时会跳过它,执行后面完整的命令
8、开启AOF持久化
appendonly yes
9、AOF策略调整
# 每次有数据修改发生时,都会写入AOF文件,非常安全非常慢。
# 想要数据不丢失就用这种,只要有修改就持久化到磁盘
# aof的always机制基本不会用,用也不会用在主库。
appendfsync always
# 每秒钟同步一次,该策略为AOF的缺省策略,够快可能会丢失1秒的数据
# 比较推荐,相对另外两种居中一点,一秒钟内数据丢失问题也不大
appendfsync everysec
# 不主动fsync,由操作系统决定,更快,更不安全的方法。
# 按照操作系统刷磁盘的机制,系统可能是5-6分钟。因为系统刷磁盘的代价很高。
appendfsync no
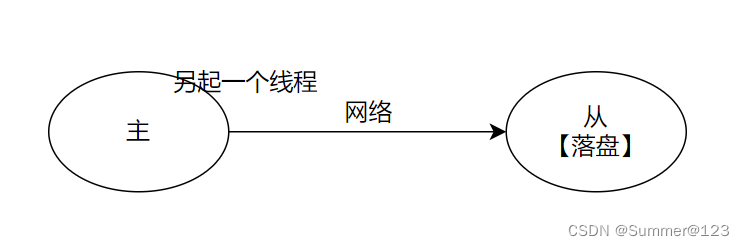
aof的always机制基本不会用,用也不会用在主库。保证数据的落盘不在主redis上边,在从redis上边。主从集群。
当请求主的时候有数据改动。当主通过网络将数据同步给从的时候,让从去落盘。
网络本身就不稳定,并且主从同步是另起一个线程去干这件事。这之间存在延时。以下这2种情况都会存在数据丢失:
- 如果主redis挂掉了,有些数据没来得及通过线程网络发过去
- 网络有问题,数据同步过去但是从redis没有收到,然后主redis挂了,数据也会有丢失。
- 因此没办法既保证redis的高性能,又保证数据不丢失。
10、AOF优点和缺点
| 优点 | 缺点 |
|---|---|
| 最安全 | 文件体积大 |
| 容灾 | 性能消耗比RDB高 |
| 易读 | 可修改,数据恢复速度比RDB慢 |
rdb是内存当时是啥样子,就恢复啥样子,内存快照
11、AOF持久化效果验证
1、关闭save命令,确保只开启了AOF持久化
2、找到appendonly命令,当前是没有开启的,是appendonly no,改成appendonly yes。
同时检查下appendfilename是appendonly.aof
同时看一下策略是哪个,此次验证使用的是appendfsync everysec
3、在执行命令之前,先删掉旧的appendonly.aof
4、重启redis
5、执行set命令
> set a 1
> set b 2
> set c 3
6、模拟断电,redis显示“已杀死”
7、再次查询a, b, c, 可以查询到值。
可以查看下appendonly.aof的文件内容,记录下来的set操作

12、Redis丢失数据的可能性
持久化丢失的可能
12.1 RDB方式
快照产生的策略,天生就不保证数据安全
12.2 AOF持久化策略
默认每秒同步一次磁盘,可能会有1秒的数据丢失
每次修改都同步,数据安全可保证,但Redis高性能的特性全无
12.3 主从复制丢失的问题
异步复制,存在一定的时间窗口数据丢失
网络、服务器问题,存在一定数据的丢失
12.4 总结:持久化和主从都可能出现数据丢失
12.5 RDB和AOF可以结合使用
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言const 与#define 相?有何优点?
- uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -投票帖子分享以及测试版本发布实现
- 简易的555函数信号发生器电路图
- 自建私有git进行项目发布
- springboot注解@Configuration属性proxyBeanMethods详解
- CHS_01.1.2+操作系统的发展与分类
- 出现 SyntaxError: future feature annotations is not defined 解决方法
- C# 编程语言有什么特点?
- C++中[Error] ‘rand‘ was not declared in this scope如何解决?
- java八股 多线程