【GNN】常见15种应用场景
目录
简介
“强基固本,行稳致远”,科学研究离不开理论基础,人工智能学科更是需要数学、物理、神经科学等基础学科提供有力支撑,为了紧扣时代脉搏,我们推出“强基固本”专栏,讲解AI领域的基础知识,为你的科研学习提供助力,夯实理论基础,提升原始创新能力,敬请关注。
应用场景
社会影响的预测
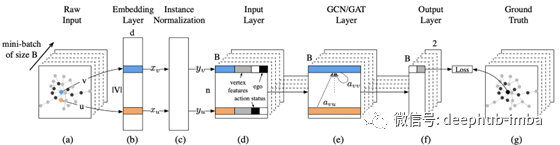
社会影响预测侧重于朋友之间行为的影响,尤其是在社交网络中。例如,如果一些社交网络上的朋友买了一件衣服,他/她会不会也买呢?以社交图作为输入,DeepInf为用户学习网络嵌入(一种潜在的社会表征)。结合下面(d)中手工制作的特征,对社会影响进行预测,比如v是否也会观看广告片段(步骤f)。在训练过程中,将预测结果与真值进行对比,学习这个网络嵌入。
电子健康记录建模
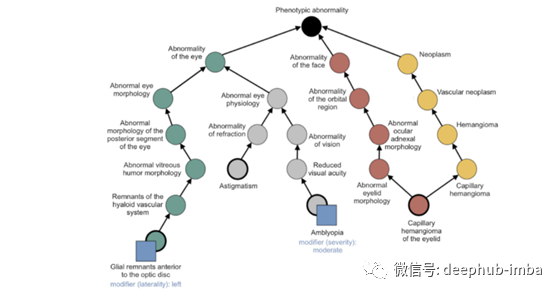
我们可以用图来建立医学本体的模型。下面是一个使用DAG(有向无环图)表示本体的例子。
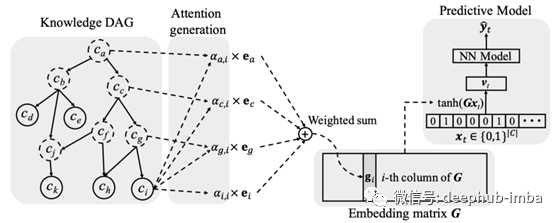
为了利用本体论,我们通过将嵌入的e?与其父节点结合使用,学习出一个为节点c?嵌入的网络g?。为了进行预测,我们将本体知识G与当前访问的xt相乘,并通过神经网络进行传递。例如,它们可以是诊断预测任务或心力衰竭预测任务。利用RNN网络,该模型可以通过以往的访问信息进一步增强。
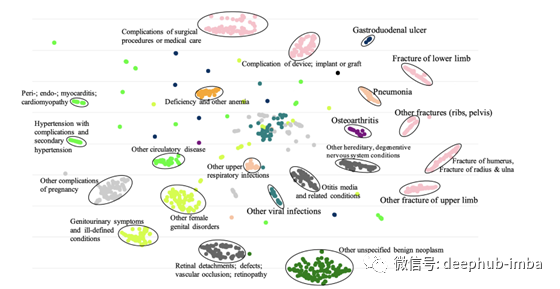
以下是使用t-SNE对不同疾病的最终代表g?的散点图。
药物发现和合成化合物
DNN可以训练成千上万的化学结构来编码和解码分子,还可以构建预测因子,根据潜在的表征来估计化学性质。例如,我们可以学习一个自编码器来编码一个分子的图形表示,然后用解码器重建分子。目的是学习一个潜在的表示,最大限度地减少重建损失。我们可以使用这个潜在表示来预测合成可及性和药物与另一个DNN(下面的绿色网络)的相似性。
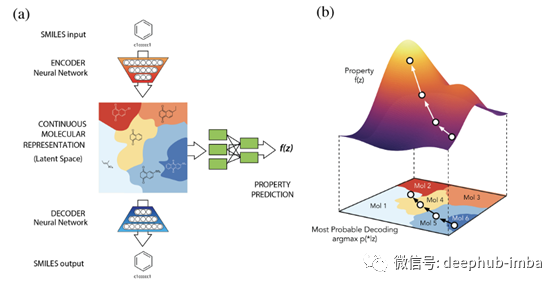
这些潜在的表达方式允许研究人员在潜在空间中通过扰乱已知的化学结构或插入分子之间的简单操作自动生成新的化学结构。
这是麻省理工学院的另一个项目,将深度学习应用于图形对象,从而发现新的抗生素。
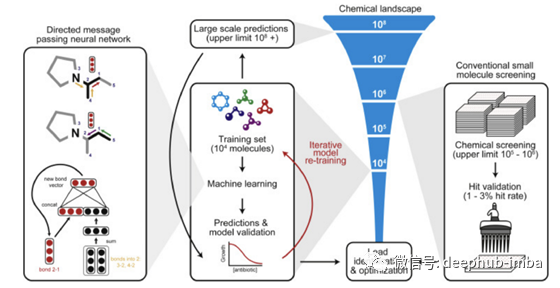
Open Catalyst项目是利用人工智能发现用于可再生能源存储的新催化剂的另一个例子。
推荐系统
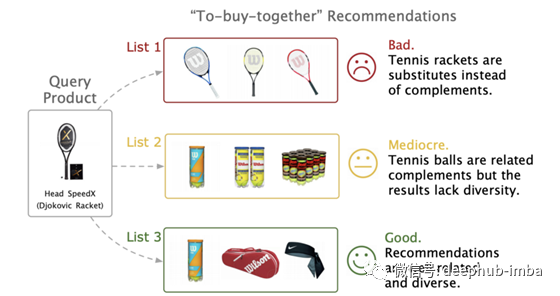
物体可以在视觉上相似,但实际上是完全不同的物体。例如,下面的第一行包含的对象与左侧的预期图像查询截然不同,尽管它们在视觉上是相似的。
在Pinterest中,将pins连接在一起形成图。pinage是一个随机行走的GCN,它学习了Pinterest图形中的节点(图像)嵌入。由于图中包含数十亿个对象,在如此巨大的图中进行卷积是没有效率的。相反,Pinterest动态地构建这些图形。它根据访问次数使用加权抽样来模拟随机行走。这个过程构建动态的和更小的图和卷积之后被用于计算节点的嵌入。
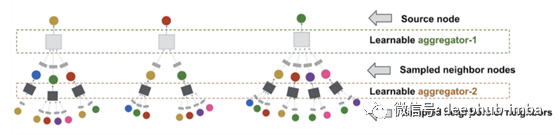
在Uber Eats上,它使用GraphSage来进行推荐。
交通预测
DCRNN融合了交通流的空间依赖性和时间依赖性,用于交通预测。道路上的传感器被建模为图中的节点。DCRNN利用图上的双向随机游动来捕获空间依赖关系,利用编解码器来捕获时间依赖关系。

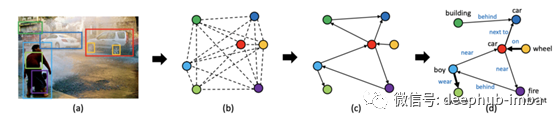
生成场景关系图
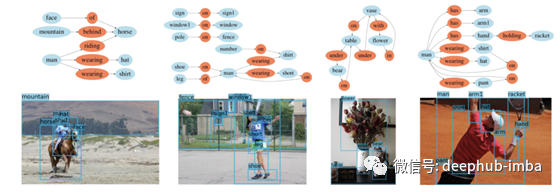
给定一幅图像,我们可以生成描述图像中物体及其关系的场景图。
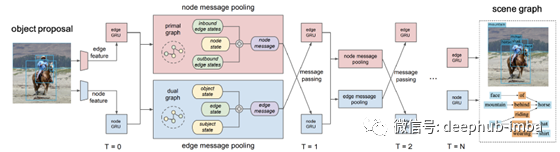
下面的模型使用GRUs生成场景图,并通过消息传递学习迭代改进其预测。
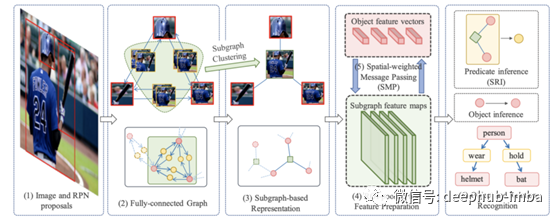
F-net使用自底向上的聚类方法将整个图分解成子图,每个子图包含几个对象及其关系的子集。采用分治方法,大大减少了中间阶段的计算量。
反过来,我们可以根据场景图生成图像。
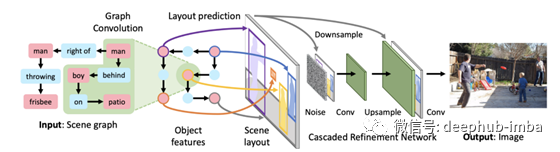
引用这篇论文的内容:https://arxiv.org/pdf/1804.01622.pdf
我们的模型使用图形卷积处理输入图形,通过预测包围框和分割掩码计算场景布局,并通过级联的细化网络将布局转换为图像。网络对抗的形式进行训练,以确保真实的输出。
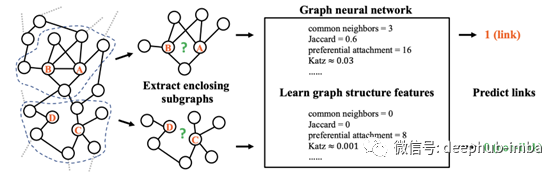
链接预测
链路预测网络中的两个节点是否可能存在链路。在推荐系统中,我们推荐的是高度“连接”的产品。
SEAL提取了一个围绕下面a和B的局部包围子图,省略了链接AB。然后,用GNN训练模型来预测这种链路是否存在。
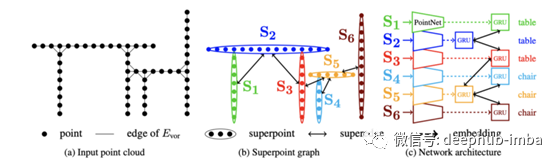
点云分类与分割
像激光雷达这样的3D扫描仪会产生3D点云,一种带有坐标的3D空间中物体的表示,以及可能的颜色信息。
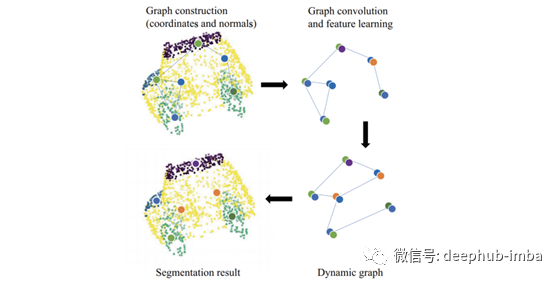
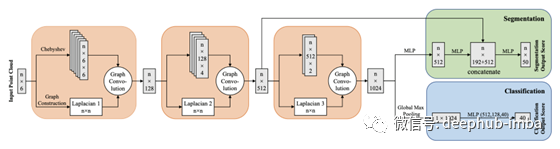
下面是一个对点云进行分类和分割的模型。
这是另一个使用RGB点云的3D对象分割的例子。
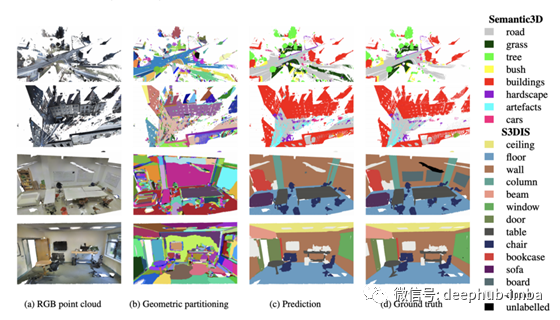
这是生成3D分割的模型。
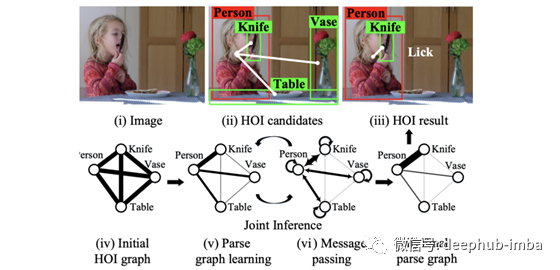
人物交互
GPNN用图形结构来解释一个给定的场景。例如,它用“舔”来标记人与刀之间的联系。
文本分类
我们可以应用GNN进行主题文本分类,包括新闻分类、Q&A、搜索结果组织等。
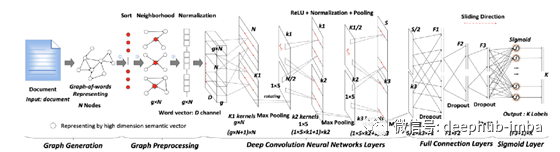
在下面的模型中,它在原始文本上滑动一个三个单词的窗口,以创建单词图。这张图表示三个词范围内的词共现。然后,它根据每个节点的秩(节点的连接数)从图中选择节点。对于每个节点,它使用广度优先搜索查找包含该节点和另外四个节点的4个节点的子图。子图将是有序的,这样卷积可以一致地应用到所有子图。
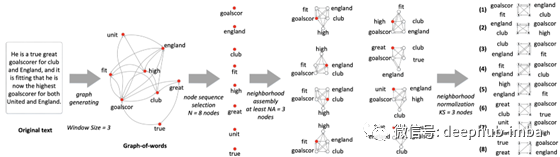
下面的图是从这些子图中进行标签预测的架构。
序列标签
句子中的单词可以被建模为图中的节点,我们可以计算每个节点的隐藏表示,并使用它来标记序列(序列中的单词的标签)。
潜在的应用包括POS-tagging、NER(命名实体识别)和语义角色标签(SRL)。SRL给句子中的单词或短语贴上标签,表明它们的语义角色,如下图所示。
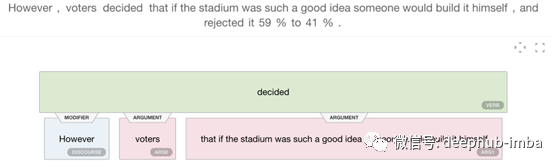
因此,给定一个谓词(“disputed”这个词),下面的模型会识别并标记它的所有参数。
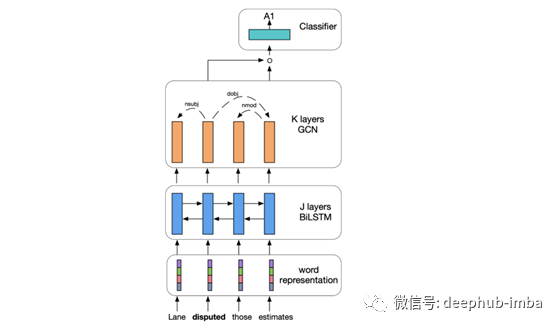
NLP中的关系提取
下面的图表表示了各种依赖关系,如线性上下文(相邻词)、句法依赖关系和语篇关系。
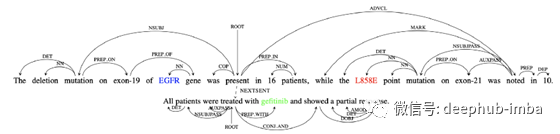
这句话表明EGFR基因L858E突变的肿瘤对药物吉非替尼有反应。如果我们将三者定义为(药物、基因、突变),这些句子将表明三者(gefitinib、EGFR、L858E)具有“应答”关系。
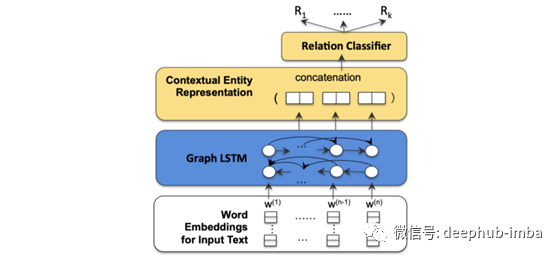
在下面的架构中,句子中的单词是用单词嵌入来编码的。然后,它使用一个图形LSTM来学习每个单词的上下文表示。接下来,我们将单词(gefitinib, EGFR, L858E)的上下文表示连接在一起。最后,我们使用一个关系分类器对这三个词的关系进行评分(分类)。因此关系式“Respond”(说成“R?”)得分最高。
姿态估计

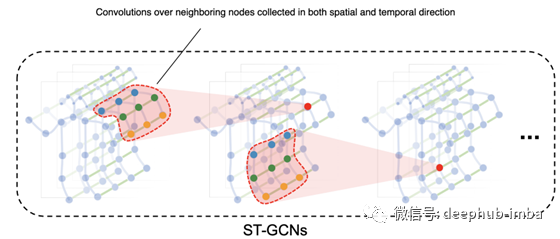
ST-GCN对其空间和时间邻居进行卷积,以估计输入视频的姿态。
芯片设计
在晶片设计中,标准晶片单元的放置和路线会影响晶片的功率、晶片模具尺寸和性能。谷歌证明了使用GNN和强化学习来优化单元的放置。

芯片网表图(节点类型和图邻接信息)和当前放置的节点通过GNN进行输入状态编码。
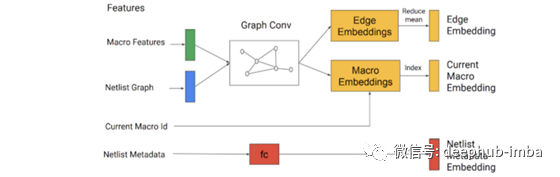
这些嵌入与嵌入的元数据(如电线的总数)相连接,并提供给一个神经网络。输出是一个学习的潜在表示,并作为输入的策略和损失进行强化学习。策略网络在当前节点所有可能的单元布局上产生一个概率分布。

粒子物理
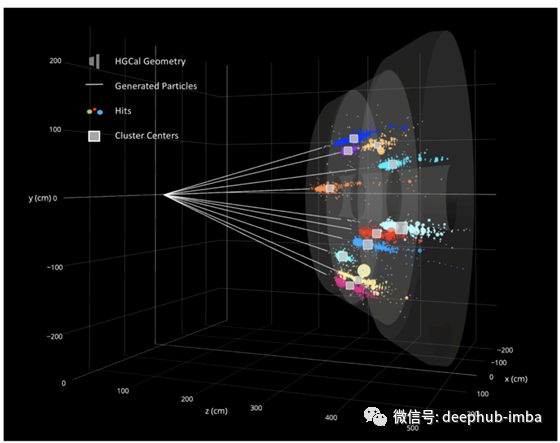
在费米实验室,研究人员使用GNN来分析大型强子对撞机CMS探测器产生的图像,以识别粒子物理实验需要的有趣粒子。
参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024,智能座舱不要再过度“装修”了!
- vue watch props无效
- 线性代数笔记3 1.1
- 【unity小技巧】实现没有动画的FPS武器摇摆和摆动效果
- josef 约瑟抗干扰中间继电器 UEG/F-4H 四常开 导轨安装
- 部署tomcat单机多实例,keepalived+mysql的互为主从高可用,mysql+keepalived高可用
- 将类声明为全局作为单一对象供其它对象调用
- 使用管家婆分销ERP集成CRM系统:无代码开发的连接解决方案
- 图解双指针解决三数之和、最接近的三数之和
- 网络通信(4)-数据链路层解析