Redis源码——压缩列表
压缩列表ziplist本质上就是一个字节数组,是Redis为了节约内存而设计的一种线性数据结构,可以包含多个元素,每个元素可以是一个字节数组或一个整数。Redis的有序集合、散列和列表都直接或者间接使用了压缩列表。当有序集合或散列表的元素个数比较少,且元素都是短字符串时,Redis便使用压缩列表作为其底层数据存储结构。列表使用快速链表(quicklist)数据结构存储,而快速链表就是双向链表与压缩列表的组合。
例如,使用如下命令创建一个散列键并查看其编码。
127.0.0.1:6379> hmset person name zhangsan gender 1 age 22
OK
127.0.0.1:6379> object encoding person
"ziplist"本章将从源码层次详细介绍压缩列表的存储结构及基本操作。
压缩列表的存储结构
Redis使用字节数组表示一个压缩列表,压缩列表结构示意如下图所示:

各字段的含义如下:
- zlbytes:压缩列表的字节长度,占4个字节,因此压缩列表最多有
-1个字节。
- zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节。
- zllen:压缩列表的元素个数,占2个字节。zllen无法存储元素个数超过65535(
-1)的压缩列表,必须遍历整个压缩列表才能获取到元素个数。
- entryX:压缩列表存储的元素,可以是字节数组或者整数,长度不限。entry的编码结构将在后面详细介绍。
- zlend:压缩列表的结尾,占1个字节,恒为0xFF。
假设char * zl指向压缩列表首地址,Redis可通过以下宏定义实现压缩列表各个字段的存取操作。
/* zl返回zlbytes的总字节数。 */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
/* zl+4返回zltail的偏移量。 */
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
/* 返回ziplist的长度,如果无法确定长度,则返回UINT16_MAX。 */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
/* ziplist头部的大小:两个32位整数用于总字节数和最后一个项的偏移量。一个16位整数用于项数字段。 */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
/* 返回zlend的大小,只有一个字节。 */
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
/* 返回ziplist的第一个条目的指针。 */
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
/* 使用ziplist头部中的最后一个条目偏移量,返回ziplist的最后一个条目的指针。 */
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
/* 返回ziplist的最后一个字节的指针,即"end of ziplist" FF条目的末尾。 */
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-ZIPLIST_END_SIZE)其中头部是zlbytes+zltail+zllen,一共占用了4+4+2,即ZIPLIST_HEADER_SIZE。压缩列表中第一个元素的指针偏移量是zl+ZIPLIST_HEADER_SIZE。
了解了压缩列表的基本结构,我们可以很容易地获得压缩列表的字节长度、元素个数等,那么如何遍历压缩列表呢?对于任意一个元素,我们如何判断其存储的是什么类型呢?我们又如何获取字节数组的长度呢?
回答这些问题之前,需要先了解压缩列表元素的编码结构,如下所示:

previous_entry_length字段表示前一个元素的字节长度,占1个或者5个字节,当前一个元素的长度小于254字节时,用1个字节表示;当前一个元素的长度大于或等于254字节时,用5个字节来表示。而此时previous_entry_length字段的第1个字节是固定的0xFE,后面4个字节才真正表示前一个元素的长度。假设已知当前元素的首地址为p,那么p-previous_entry_length就是前一个元素的首地址,从而实现压缩列表从尾到头的遍历。
encoding字段表示当前元素的编码,即content字段存储的数据类型(整数或者字节数组),数据内容存储在content字段。为了节约内存,encoding字段同样长度可变。压缩列表元素的编码如下表所示:
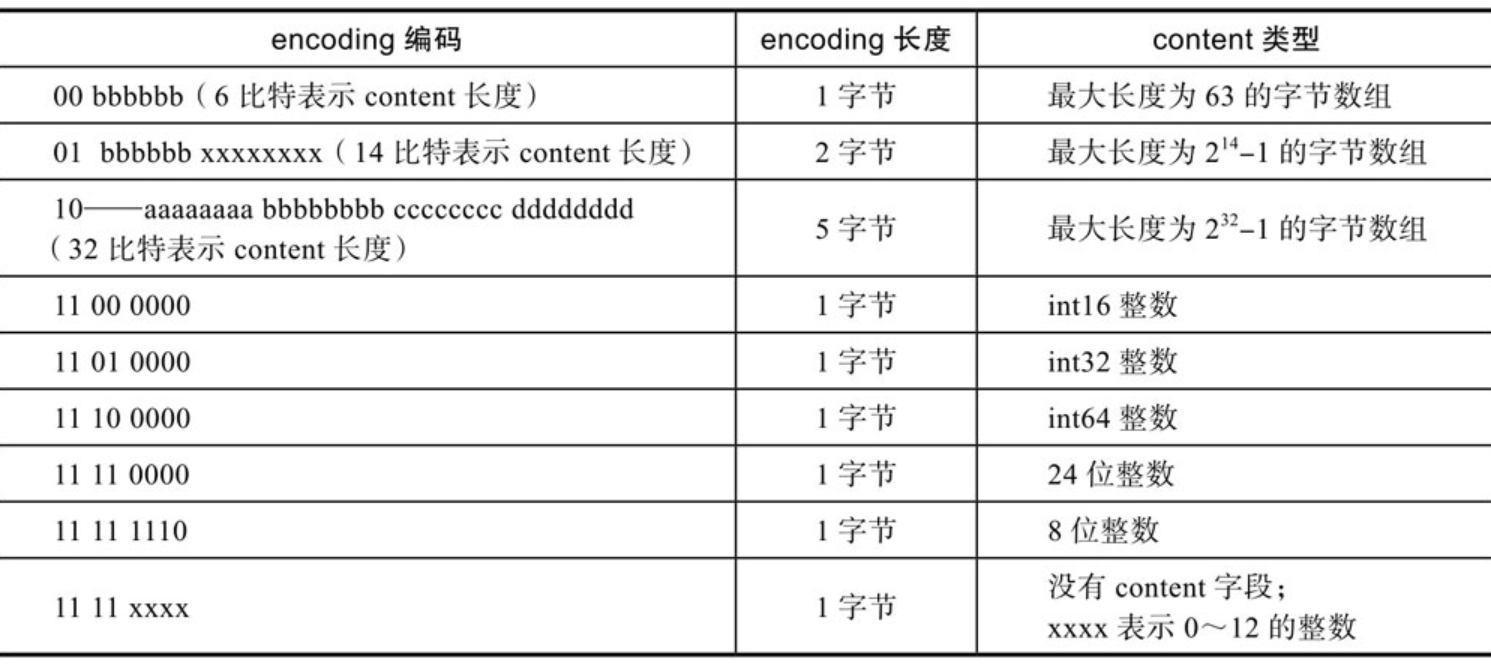
可以看出,根据encoding字段第1个字节的前2位,可以判断content字段存储的是整数或者字节数组(及其最大长度)。当content存储的是字节数组时,后续字节标识字节数组的实际长度;当content存储的是整数时,可根据第3、第4位判断整数的具体类型。而当encoding字段标识当前元素存储的是0~12的立即数时,数据直接存储在encoding字段的最后4位,此时没有content字段。参照encoding字段的编码表格,Redis预定义了以下常量对应encoding字段的各编码类型:
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
#define ZIP_INT_16B (0xc0 | 0<<4)
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe结构体
我们发现对于压缩列表的任意元素,获取前一个元素的长度、判断存储的数据类型、获取数据内容都需要经过复杂的解码运算。解码后的结果应该被缓存起来,为此定义了结构体zlentry,用于表示解码后的压缩列表元素。
/* 我们使用这个函数来接收关于ziplist条目的信息。
* 注意,这些数据并不是这样编码的,这只是我们通过一个函数填充的以便更轻松地操作的数据。 */
typedef struct zlentry {
unsigned int prevrawlensize; /* 编码前一个条目长度所使用的字节数 */
unsigned int prevrawlen; /* 前一个条目长度 */
unsigned int lensize; /* 编码条目类型/长度所使用的字节数。
例如,字符串有1、2或5个字节的头部。整数始终使用一个字节。*/
unsigned int len; /* 表示实际条目的字节数。
对于字符串,这只是字符串的长度,而对于整数,取决于数值范围,
可以是1、2、3、4、8或0(对于4位立即整数)。 */
unsigned int headersize; /* prevrawlensize + lensize */
unsigned char encoding; /* 根据条目的编码,设置为ZIP_STR_*或ZIP_INT_*。然而,
对于4位立即整数,它可以假设一组值并需要进行范围检查。 */
unsigned char *p; /* 指向条目开头的指针,即指向前条目长度字段。 */
} zlentry;回顾压缩列表元素的编码结构,可变因素实际上不止3个:previous_entry_length字段的长度(prevrawlensize)、previous_entry_length字段存储的内容(prevrawlen)、encoding字段的长度(lensize)、encoding字段的内容(len表示元素数据内容的长度,encoding表示数据类型)和当前元素首地址(p);而headersize则表示当前元素的首部长度,即previous_entry_length字段长度与encoding字段长度之和。
函数zipEntry用来解码压缩列表的元素,存储于zlentry结构体。
/* 填充一个关于条目的信息的结构体。
* 此函数是下面那个函数的"不安全"替代方案。
* 一般情况下,返回ziplist中元素指针的所有函数都会断言这个元素是有效的,因此可以自由使用。
* 一般情况下,ziplistGet等函数假设输入指针已经经过验证(因为它是另一个函数的返回值)。
*/
static inline void zipEntry(unsigned char *p, zlentry *e) {
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
assert(e->lensize != 0); /* 检查编码是否有效。*/
e->headersize = e->prevrawlensize + e->lensize;
e->p = p;
}解码主要可以分为以下两个步骤。
1)解码previous_entry_length字段,此时入参ptr指向元素首地址。
#define ZIP_END 255 /* 特殊的 "ziplist结尾" 标记值。 */
#define ZIP_BIG_PREVLEN 254 /* ZIP_BIG_PREVLEN - 1 是前一个条目的最大长度,用于表示每个条目
的"prevlen"字段前缀,如果长度大于等于254字节,则使用FE AA
BB CC DD表示,其中AA BB CC DD是一个无符号整数,
使用4个字节表示前一个条目的长度。 */
/*
* 返回用于编码上一个条目的长度的字节数。
* 长度通过将变量 'prevlensize' 设置为特定值来返回。
*/
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \
if ((ptr)[0] < ZIP_BIG_PREVLEN) { \
(prevlensize) = 1; \
} else { \
(prevlensize) = 5; \
} \
} while(0)
/* 返回前一个元素的长度以及用于编码前一个元素长度的字节数。
* 'ptr' 必须指向一个元素的前一个元素长度的 prevlen 前缀(用于遍历元素向后导航)。
* 前一个元素的长度存储在 'prevlen' 中,编码前一个元素长度所需的字节数存储在 'prevlensize' 中。 */
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
(prevlen) = (ptr)[0]; \
} else { /* prevlensize == 5 */ \
(prevlen) = ((ptr)[4] << 24) | \
((ptr)[3] << 16) | \
((ptr)[2] << 8) | \
((ptr)[1]); \
} \
} while(0)2)解码encoding字段逻辑,此时入参ptr指向元素首地址偏移previous_entry_length字段长度的位置。
#define ZIP_STR_MASK 0xc0
/* 从指向 'ptr' 的字节中提取编码,并将其设置为 'zlentry' 结构体中的 'encoding' 字段 */
#define ZIP_ENTRY_ENCODING(ptr, encoding) do { \
(encoding) = ((ptr)[0]); \
if ((encoding) < ZIP_STR_MASK) (encoding) &= ZIP_STR_MASK; \
} while(0)
/*
* 解码'ptr'中的条目编码类型和数据长度(字符串长度为字符串,整数条目使用的字节数)。
* 'encoding'变量为输入参数,调用者提取,'lensize'变量将保存用于编码条目长度的字节数,
* 'len'变量将保存条目长度。在无效编码错误的情况下,lensize被设置为0。
*/
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
if ((encoding) < ZIP_STR_MASK) { \
if ((encoding) == ZIP_STR_06B) { \
(lensize) = 1; \
(len) = (ptr)[0] & 0x3f; \
} else if ((encoding) == ZIP_STR_14B) { \
(lensize) = 2; \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \
} else if ((encoding) == ZIP_STR_32B) { \
(lensize) = 5; \
(len) = ((uint32_t)(ptr)[1] << 24) | \
((uint32_t)(ptr)[2] << 16) | \
((uint32_t)(ptr)[3] << 8) | \
((uint32_t)(ptr)[4]); \
} else { \
(lensize) = 0; /* 编码错误,应该在之前的代码中被覆盖 */ \
(len) = 0; /* ZIP_ASSERT_ENCODING / zipEncodingLenSize,或者 */ \
/* 在此宏之后将lensize与0匹配 */ \
} \
} else { \
(lensize) = 1; \
if ((encoding) == ZIP_INT_8B) (len) = 1; \
else if ((encoding) == ZIP_INT_16B) (len) = 2; \
else if ((encoding) == ZIP_INT_24B) (len) = 3; \
else if ((encoding) == ZIP_INT_32B) (len) = 4; \
else if ((encoding) == ZIP_INT_64B) (len) = 8; \
else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) \
(len) = 0; /* 4位立即值 */ \
else \
(lensize) = (len) = 0; /* 编码错误 */ \
} \
} while(0)字节数组只根据ptr[0]的前2个比特即可判断类型,而判断整数类型需要ptr[0]的前4个比特,代码如下。
/*
* 返回由'encoding'编码的整数所需的字节数
*/
static inline unsigned int zipIntSize(unsigned char encoding) {
switch(encoding) {
case ZIP_INT_8B: return 1;
case ZIP_INT_16B: return 2;
case ZIP_INT_24B: return 3;
case ZIP_INT_32B: return 4;
case ZIP_INT_64B: return 8;
}
if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX)
return 0; /* 4位立即值 */
/* 编码错误,通过之前的ZIP_ASSERT_ENCODING调用已覆盖 */
redis_unreachable();
return 0;
}基本操作
本节主要介绍压缩列表的基本操作,包括创建压缩列表、插入元素、删除元素及遍历压缩列表,让读者从源码层次进一步理解压缩列表。
创建压缩列表
创建压缩列表的API定义如下,函数无输入参数,返回参数为压缩列表首地址。
unsigned char *ziplistNew(void);创建空的压缩列表,只需要分配初始存储空间11(4+4+2+1)个字节,并对zlbytes、zltail、zllen和zlend字段初始化即可。
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
//ZIPLIST_HEADER_SIZE = zlbytes + zltail + zllen;
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END; //结尾标识0XFF
return zl;
}插入元素
压缩列表插入元素的API定义如下,函数输入参数zl表示压缩列表首地址,p指向元素插入位置,s表示数据内容,slen表示数据长度,返回参数为压缩列表首地址。
/*
* 在指定位置 "p" 插入一个键值对。
*
* 参数:
* - zl: 待操作的 ziplist。
* - p: 待插入的位置。
* - s: 键值对的键。
* - slen: 键值对的键的长度。
*
* 返回值:
* - 插入后的 ziplist。
*/
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
return __ziplistInsert(zl,p,s,slen);
}
/*
* 在指定位置插入项目。
*
* @param zl 待插入的ziplist
* @param p 插入位置的指针
* @param s 待插入的字符串
* @param slen 待插入字符串的长度
* @return 更新后的ziplist
*/
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, newlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* 初始化为避免警告。使用一个易于看到的值,
如果由于某种原因未初始化,则使用。 */
zlentry tail;
/* 确定要插入的条目的前一条记录的长度。 */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLengthSafe(zl, curlen, ptail);
}
}
/* 查看是否可以对条目进行编码 */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 将encoding设置为相应的整数编码 */
reqlen = zipIntSize(encoding);
} else {
/* encoding不变,但是zipStoreEntryEncoding将使用字符串长度来确定如何编码。 */
reqlen = slen;
}
/* 我们需要为之前的记录长度和有效负载长度腾出空间。 */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* 如果插入位置不等于尾部,则需要确保下一个条目的prevlen字段可以容纳此条目的长度。 */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
/* 存储realloc可能改变ziplist地址的情况下的地址。 */
offset = p-zl;
newlen = curlen+reqlen+nextdiff;
zl = ziplistResize(zl,newlen);
p = zl+offset;
/* 应用必要的内存移动并更新尾部偏移量。 */
if (p[0] != ZIP_END) {
/* 减少一个是由于ZIP_END字节 */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* 在下一个条目中编码此条目的raw长度。 */
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* 更新尾部偏移量。 */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* 当尾部包含多于一个条目时,我们还需要考虑"nextdiff"。
否则,prevlen大小的变化对尾部偏移量没有影响。 */
assert(zipEntrySafe(zl, newlen, p+reqlen, &tail, 1));
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* 这个元素将是新的尾部。 */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* 当nextdiff不为0时,下一个条目的原始长度发生变化,因此需要在ziplist中进行更新。 */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* 写入条目 */
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}插入元素可以简要分为3个步骤:① 将元素内容编码;② 重新分配空间;③ 复制数据。下面分别讲解每个步骤的实现逻辑。
1.编码
编码即计算previous_entry_length字段、encoding字段和content字段的内容。那么如何获取前一个元素的长度呢?此时就需要根据元素的插入位置分情况讨论。插入元素位置示意如下所示:

1)当压缩列表为空、插入位置为P0时,不存在前一个元素,即前一个元素的长度为0。
2)当插入位置为P1时,需要获取entryX元素的长度,而entryX+1元素的previous_entry_length字段存储的就是entryX元素的长度,比较容易获取。
3)当插入位置为P2时,需要获取entryN元素的长度,entryN是压缩列表的尾元素,计算元素长度时需要将其3个字段长度相加,函数实现如下。
/*
* 返回由指针 'p' 指向的条目使用的总字节数。 */
static inline unsigned int zipRawEntryLengthSafe(unsigned char* zl, size_t zlbytes, unsigned char *p) {
zlentry e;
assert(zipEntrySafe(zl, zlbytes, p, &e, 0));
return e.headersize + e.len;
}
/**
* 将结构体填充为关于条目的所有信息。
*
* 这个函数是安全使用的,即使是指向不受信任的指针,也能确保不会尝试访问ziplist负载外部的内存。
* 返回1表示条目是有效的,返回0表示否则。
*/
static inline int zipEntrySafe(unsigned char* zl, size_t zlbytes, unsigned char *p, zlentry *e, int validate_prevlen) {
unsigned char *zlfirst = zl + ZIPLIST_HEADER_SIZE;
unsigned char *zllast = zl + zlbytes - ZIPLIST_END_SIZE;
#define OUT_OF_RANGE(p) (unlikely((p) < zlfirst || (p) > zllast))
/* 如果头部不可能超出ziplist范围,那么走快速路径。(最大lensize和prevrawlensize均为5字节) */
if (p >= zlfirst && p + 10 < zllast) {
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
e->headersize = e->prevrawlensize + e->lensize;
e->p = p;
/* 我们没有调用ZIP_ASSERT_ENCODING,所以检查lensize是否被设置为0。 */
if (unlikely(e->lensize == 0))
return 0;
/* 确保条目不会超出ziplist边缘 */
if (OUT_OF_RANGE(p + e->headersize + e->len))
return 0;
/* 如果需要验证prevlen,则确保prevlen不会超出ziplist边缘 */
if (validate_prevlen && OUT_OF_RANGE(p - e->prevrawlen))
return 0;
return 1;
}
/* 确保指针不会超出ziplist的边缘 */
if (OUT_OF_RANGE(p))
return 0;
/* 确保编码的prevlen头部不会超出分配范围 */
ZIP_DECODE_PREVLENSIZE(p, e->prevrawlensize);
if (OUT_OF_RANGE(p + e->prevrawlensize))
return 0;
/* 确保编码的条目头是有效的。 */
ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding);
e->lensize = zipEncodingLenSize(e->encoding);
if (unlikely(e->lensize == ZIP_ENCODING_SIZE_INVALID))
return 0;
/* 确保编码的条目头不会超出分配范围 */
if (OUT_OF_RANGE(p + e->prevrawlensize + e->lensize))
return 0;
/* 解码prevlen和条目长度头。 */
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
e->headersize = e->prevrawlensize + e->lensize;
/* 确保条目不会超出ziplist边缘 */
if (OUT_OF_RANGE(p + e->headersize + e->len))
return 0;
/* 如果需要验证prevlen,则确保prevlen不会超出ziplist边缘 */
if (validate_prevlen && OUT_OF_RANGE(p - e->prevrawlen))
return 0;
e->p = p;
return 1;
#undef OUT_OF_RANGE
}encoding字段标识的是当前元素存储的数据类型和数据长度。编码时首先尝试将数据内容解析为整数,如果解析成功,则按照压缩列表整数类型编码存储;如果解析失败,则按照压缩列表字节数组类型编码存储。
/* 查看是否可以对条目进行编码 */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 将encoding设置为相应的整数编码 */
reqlen = zipIntSize(encoding);
} else {
/* encoding不变,但是zipStoreEntryEncoding将使用字符串长度来确定如何编码。 */
reqlen = slen;
}
/* 我们需要为之前的记录长度和有效负载长度腾出空间。 */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);上述程序尝试按照整数解析新添加元素的数据内容,数值存储在变量value中,编码存储在变量encoding中。如果解析成功,还需要计算整数所占字节数。变量reqlen最终存储的是当前元素所需空间大小,初始赋值为元素content字段所需空间大小,再累加previous_entry_length和encoding字段所需空间大小。
重新分配空间
由于新插入了元素,压缩列表所需空间增大,因此需要重新分配存储空间。那么空间大小是不是添加元素前的压缩列表长度与新添加元素长度之和呢?并不完全是。压缩列表长度变化示意如下图所示。
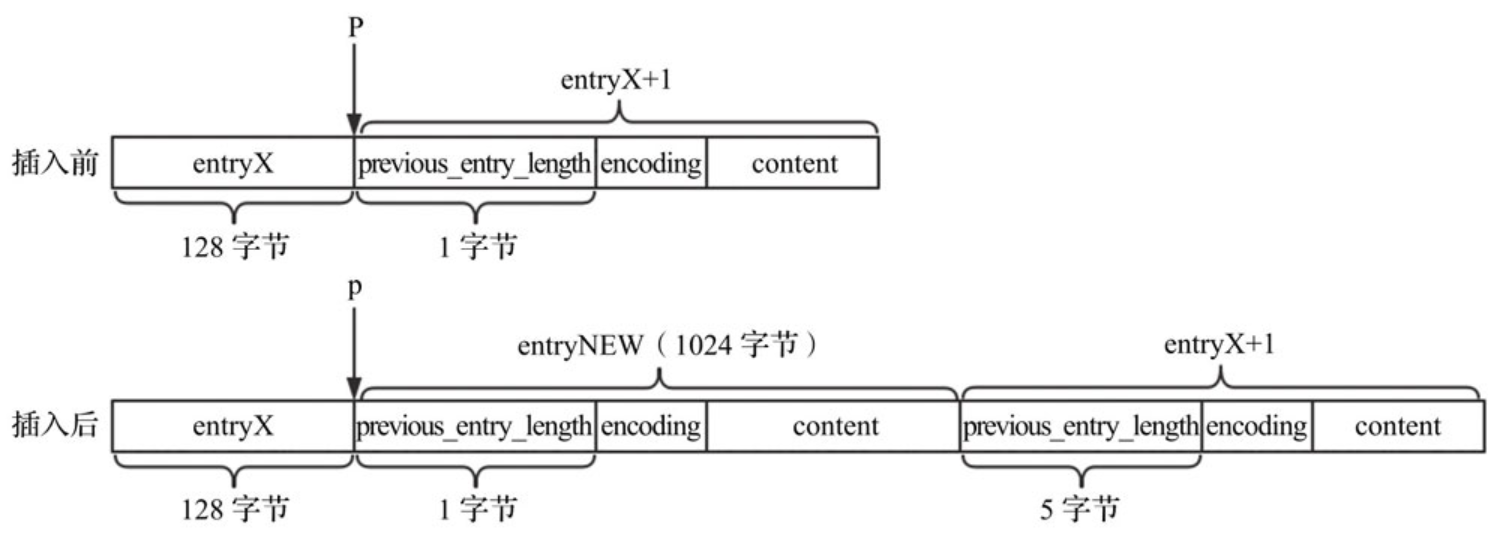
插入元素前,entryX元素的长度为128字节,entryX+1元素的previous_entry_length字段占1个字节;添加元素entryNEW,元素长度为1024字节,此时entryX+1元素的previous_entry_length字段需要占5个字节,即压缩列表的长度不仅增加了1024个字节,还要加上entryX+1元素扩展的4个字节。而entryX+1元素的长度可能增加4个字节、减少4个字节或不变。
由于重新分配了空间,新元素插入的位置指针P会失效,可以预先计算好指针P相对于压缩列表首地址的偏移量,待分配空间之后再偏移即可。
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl));
int forcelarge = 0;
nextdiff = (p[0] ! = ZIP_END) ? zipPrevLenByteDiff(p, reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
//存储偏移量
offset = p-zl;
//调用realloc重新分配空间
zl = ziplistResize(zl, curlen+reqlen+nextdiff);
//重新偏移到插入位置P
p = zl+offset;nextdiff与forcelarge在这里有什么用呢?分析ziplistResize函数的第二个参数,curlen表示插入元素前压缩列表的长度;reqlen表示新插入元素的长度;而nextdiff表示entryX+1元素长度的变化,取值可能为0(长度不变)、4(长度增加4)或-4(长度减少4)。我们再思考下,当nextdiff=4而reqlen<4时会发生什么呢?没错,插入元素导致压缩列表所需空间减小了,即函数ziplistResize内部调用realloc重新分配的空间小于指针zl指向的空间。我们知道realloc重新分配空间时,返回的地址可能不变(当前位置有足够的内存空间可供分配),当重新分配的空间减小时,realloc可能会将多余的空间回收,导致数据丢失。因此需要避免这种情况的发生,即重新赋值nextdiff=0,同时使用forcelarge标记这种情况。
那么,nextdiff=-4时,reqlen会小于4吗?nextdiff=-4说明插入元素之前entryX+1元素的previous_entry_length字段的长度是5字节,即entryX元素的总长度大于或等于254字节,所以entryNEW元素的previous_entry_length字段同样需要5个字节,即entryNEW元素的总长度肯定是大于5个字节的,reqlen又怎么会小于4呢?正常情况下是不会出现这种情况的,但是由于存在连锁更新(将在4.4节介绍),可能会出现nextdiff=-4但entryX元素的总长度小于254字节的情况,此时reqlen可能会小于4。
数据复制
重新分配空间之后,需要将位置P后的元素移动到指定位置,将新元素插入到位置P。我们假设entryX+1元素的长度增加4(即nextdiff=4),此时压缩列表数据复制示意如下图所示。
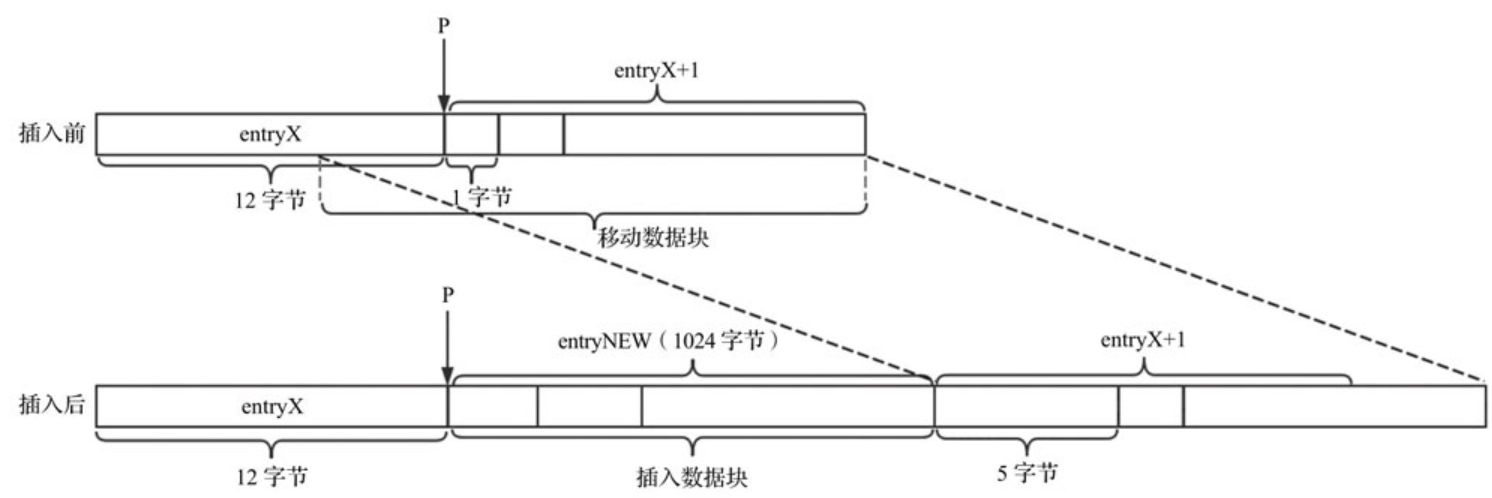
从上图中可以看到,位置P后的所有元素都需要移动,移动的偏移量是待插入元素entryNEW的长度,移动的数据块长度是位置P后所有元素的长度之和加上nextdiff的值,数据移动之后还需要更新entryX+1元素的previous_entry_length字段。
/* 应用必要的内存移动并更新尾部偏移量。 */
if (p[0] != ZIP_END) {
//为什么减1呢?zlend结束表示恒为0xFF,不需要移动
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
//更新entryX+1元素的previous_entry_length字段
if (forcelarge)
//entryX+1元素的previous_entry_length字段依然占5个字节;
//但是entryNEW元素的长度小于4字节
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
//更新zltail字段
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* 当尾部包含多于一个条目时,我们还需要考虑"nextdiff"。
否则,prevlen大小的变化对尾部偏移量没有影响。 */
assert(zipEntrySafe(zl, newlen, p+reqlen, &tail, 1));
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* 这个元素将是新的尾部。 */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}第一次更新尾元素偏移量之后,为什么指向的元素可能不是尾元素呢?因为当entryX+1元素就是尾元素时,只需要更新一次尾元素的偏移量;但是当entryX+1元素不是尾元素且entryX+1元素的长度发生了改变时,尾元素偏移量还需要加上nextdiff的值。
删除元素
压缩列表删除元素的API定义如下,函数输入参数zl指向压缩列表首地址;*p指向待删除元素的首地址(参数p同时可以作为输出参数);返回参数为压缩列表首地址。
/* 删除指针 *p指向的ziplist中的单个条目。
* 同时在place中更新*p,以便能够迭代ziplist,同时删除条目。 */
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p) {
size_t offset = *p-zl;
zl = __ziplistDelete(zl,*p,1);
/* 将当前元素的指针存储在p中,因为ziplistDelete会进行realloc,可能会导致不同的"zl"指针。
* 当删除方向为从后往前时,可能会删除最后一个条目,并导致"p"指向ZIP_END,因此需要检查这一点。 */
*p = zl+offset;
return zl;
}ziplistDelete函数只是简单调用底层_ziplistDelete函数实现删除功能。_ziplistDelete函数可以同时删除多个元素,输入参数p指向的是首个待删除元素的地址;num表示待删除元素数目。
/* Delete "num" entries, starting at "p". Returns pointer to the ziplist. */
unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
unsigned int i, totlen, deleted = 0; // 定义变量i, totlen, deleted并初始化
size_t offset; // 定义变量offset
int nextdiff = 0; // 定义变量nextdiff并初始化
zlentry first, tail; // 定义变量first和tail
size_t zlbytes = intrev32ifbe(ZIPLIST_BYTES(zl)); // 获取ziplist的大小并赋值给zlbytes
zipEntry(p, &first); // 获取p所在entry的信息并赋值给first
for (i = 0; p[0] != ZIP_END && i < num; i++) { // 循环删除entry
p += zipRawEntryLengthSafe(zl, zlbytes, p); // 移动到下一个待删除的entry
deleted++; // 删除的entry数量加1
}
assert(p >= first.p); // 断言p大于等于first的起始位置
totlen = p-first.p; // 计算待删除的entry总长度
if (totlen > 0) { // 如果删除的entry总长度大于0
uint32_t set_tail; // 定义变量set_tail
if (p[0] != ZIP_END) { // 如果下一个entry不是ZIP_END
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen); // 计算prevlen字节大小的变化量
p -= nextdiff; // 移动到上一个entry的位置
assert(p >= first.p && p<zl+zlbytes-1); // 断言p在正确的位置上
zipStorePrevEntryLength(p,first.prevrawlen); // 在上一个entry中存储prevlen的长度
set_tail = intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen; // 计算更新后的tail偏移量
if (p[tail.headersize+tail.len] != ZIP_END) {
set_tail += nextdiff; // 如果下一个entry的长度发生了变化,更新tail偏移量
}
size_t bytes_to_move = zlbytes-(p-zl)-1; // 计算需要移动的字节数
memmove(first.p,p,bytes_to_move); // 将内存中的数据向前移动
} else {
set_tail = (first.p-zl)-first.prevrawlen; // 尾部已经被删除,不需要移动内存
}
zlbytes -= totlen - nextdiff; // 更新ziplist的剩余大小
zl = ziplistResize(zl, zlbytes); // 调整ziplist的大小
p = zl+offset; // 更新p的位置
ZIPLIST_INCR_LENGTH(zl,-deleted); // 更新ziplist中的记录数
assert(set_tail <= zlbytes - ZIPLIST_END_SIZE); // 断言tail偏移量在有效范围内
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(set_tail); // 更新tail偏移量
if (nextdiff != 0) {
zl = __ziplistCascadeUpdate(zl,p); // 如果nextdiff不等于0,递归更新下一个entry的长度
}
}
return zl; // 返回ziplist的指针
}删除元素同样可以简要分为三个步骤:① 计算待删除元素的总长度;② 数据复制;③ 重新分配空间。下面分别讨论每个步骤的实现逻辑。
1)计算待删除元素的总长度。
//解码第一个待删除元素
zipEntry(p, &first);
//遍历所有待删除元素,同时指针p向后偏移
for (i = 0; p[0] ! = ZIP_END && i < num; i++) {
p += zipRawEntryLength(p);
deleted++;
}
//totlen即为待删除元素总长度
totlen = p-first.p;2)数据复制。第1步完成之后,指针first与指针p之间的元素都是待删除的。当指针p恰好指向zlend字段时,不再需要复制数据,只需要更新尾节点的偏移量即可。下面分析另一种情况,即指针p指向的是某一个元素,而不是zlend字段。
删除元素时,压缩列表所需空间减小,减小的量是否仅为待删除元素的总长度呢?答案同样是否定的。举个简单的例子,下图是经过第1步之后的压缩列表示意。
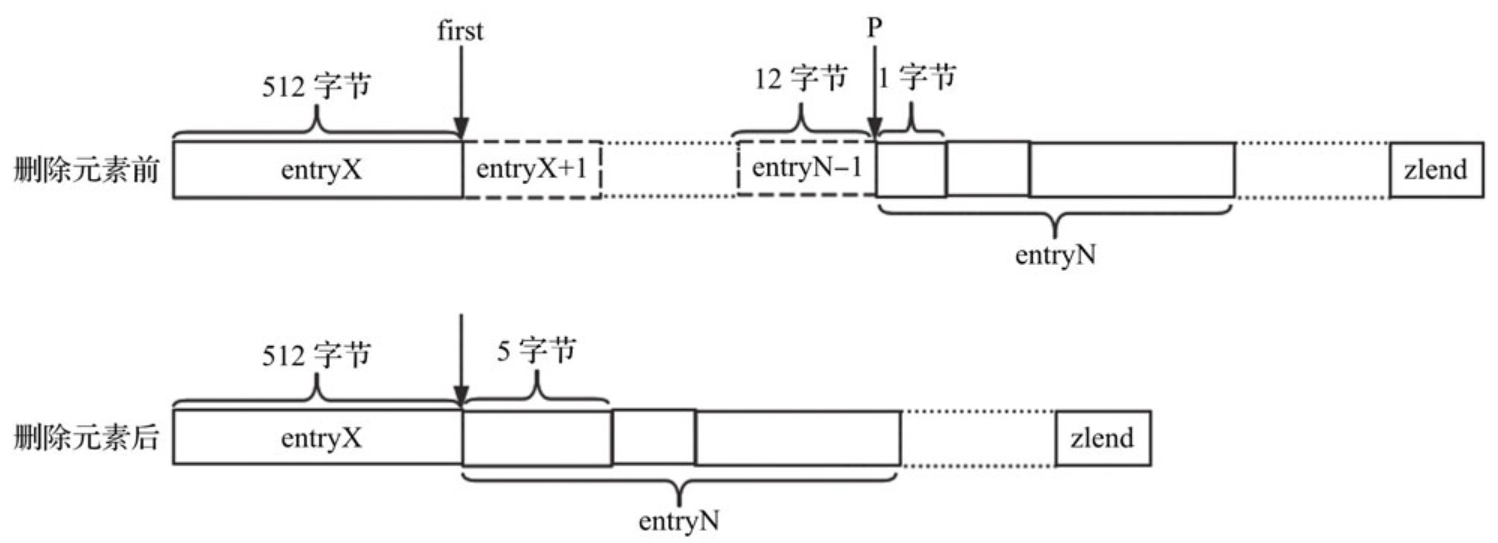
删除元素entryX+1到元素entryN-1之间的N-X-1个元素,元素entryN-1的长度为12字节,因此元素entryN的previous_entry_length字段占1个字节;删除这些元素之后,entryX成为了entryN的前一个元素,元素entryX的长度为512字节,因此元素entryN的previous_entry_length字段需要占5个字节,即删除元素之后的压缩列表的总长度还与元素entryN长度的变化量有关。
//计算元素entryN长度的变化量
nextdiff = zipPrevLenByteDiff(p, first.prevrawlen);
//更新元素entryN的previous_entry_length字段
p -= nextdiff;
zipStorePrevEntryLength(p, first.prevrawlen);
//更新zltail
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
zipEntry(p, &tail);
if (p[tail.headersize+tail.len] ! = ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
//数据复制
memmove(first.p, p, intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);与之前更新zltail字段的操作相同,当entryN元素就是尾元素时,只需要更新一次尾元素的偏移量;但是当entryN元素不是尾元素且entryN元素的长度发生了改变时,尾元素偏移量还需要加上nextdiff的值。
3)重新分配空间。
offset = first.p-zl;
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff);
p = zl+offset;
ZIPLIST_INCR_LENGTH(zl, -deleted);调用ziplistResize函数重新分配空间时,如果重新分配的空间小于指针zl指向的空间时,可能会出现问题。而删除元素时,压缩列表的长度肯定是减小的。因为删除元素时,先复制数据,再重新分配空间,即调用ziplistResize函数时,多余的那部分空间存储的数据已经被复制了,此时回收这部分空间并不会造成数据丢失。
遍历压缩列表
遍历就是从头到尾(后向遍历)或者从尾到头(前向遍历)访问压缩列表中的每个元素。压缩列表的遍历API定义如下,函数输入参数zl指向压缩列表首地址,p指向当前访问元素的首地址;ziplistNext函数返回后一个元素的首地址,ziplistPrev返回前一个元素的首地址。
//后向遍历
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p);
//前向遍历
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p);压缩列表每个元素的previous_entry_length字段存储的是前一个元素的长度,因此压缩列表的前向遍历相对简单,表达式p-previous_entry_length即可获取前一个元素的首地址,这里不做详述。后向遍历时,需要解码当前元素,计算当前元素的长度,才能获取后一个元素首地址;ziplistNext函数实现如下。
/* 返回ziplist中的下一个元素的指针。
*
* zl是ziplist的指针
* p是当前元素的指针
*
* 返回下一个元素的指针,如果没有下一个元素则返回NULL。 */
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p) {
((void) zl);
size_t zlbytes = intrev32ifbe(ZIPLIST_BYTES(zl));
/* "p"可能等于ZIP_END,这是由ziplistDelete引起的,此时应该返回NULL。
* 否则,当下一个元素是ZIP_END时(即没有下一个元素),应该返回NULL。 */
if (p[0] == ZIP_END) {
return NULL;
}
p += zipRawEntryLength(p);
if (p[0] == ZIP_END) {
return NULL;
}
zipAssertValidEntry(zl, zlbytes, p);
return p;
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 黑马程序员JavaWeb开发|原理篇
- C++最优算法实现:假设以数组Q[m]存放循环队列中的元素, 同时以rear和length分别指示环形队列中的队尾位置和队列中所含元素的个数。
- 具有不规则结果的常规 PyTorch 张量函数
- python爬取数据,需的安装的库
- 【MySQL】语法 sum(条件表达式) 的巧用
- Chapter 7 - 5. Congestion Management in Ethernet Storage Networks以太网存储网络的拥塞管理
- Three.js简介;Three.js使用与作品生成
- 云化XR技术于农业领域中的表现
- Node.js
- [MySQL]SQL优化之sql语句优化