Kubernetes 架构原则和对象设计
什么是 Kubernetes
Kubernetes 是谷歌开源的容器集群管理系统
? 基于容器的应用部署、维护和滚动升级;
? 负载均衡和服务发现;
? 跨机器和跨地区的集群调度;
? 自动伸缩;
? 无状态服务和有状态服务;
? 插件机制保证扩展性
命令式( Imperative)vs 声明式( Declarative)
- 命令:方法明确写出系统应该执行某指令,并且期待系统返回期望结果
- 声明式:描述要达到什么目的,怎么做交给系统
- 直接声明:我直接告诉你我需要什么。
- 间接声明:我不直接告诉你我的需求,我会把我的需求放在特定的地方,请在方便的时候拿出来处理
- 幂等性:状态固定,每次我想要干的事情,返回相同的结果
- 把一切抽象成对象
Kubernetes:声明式系统
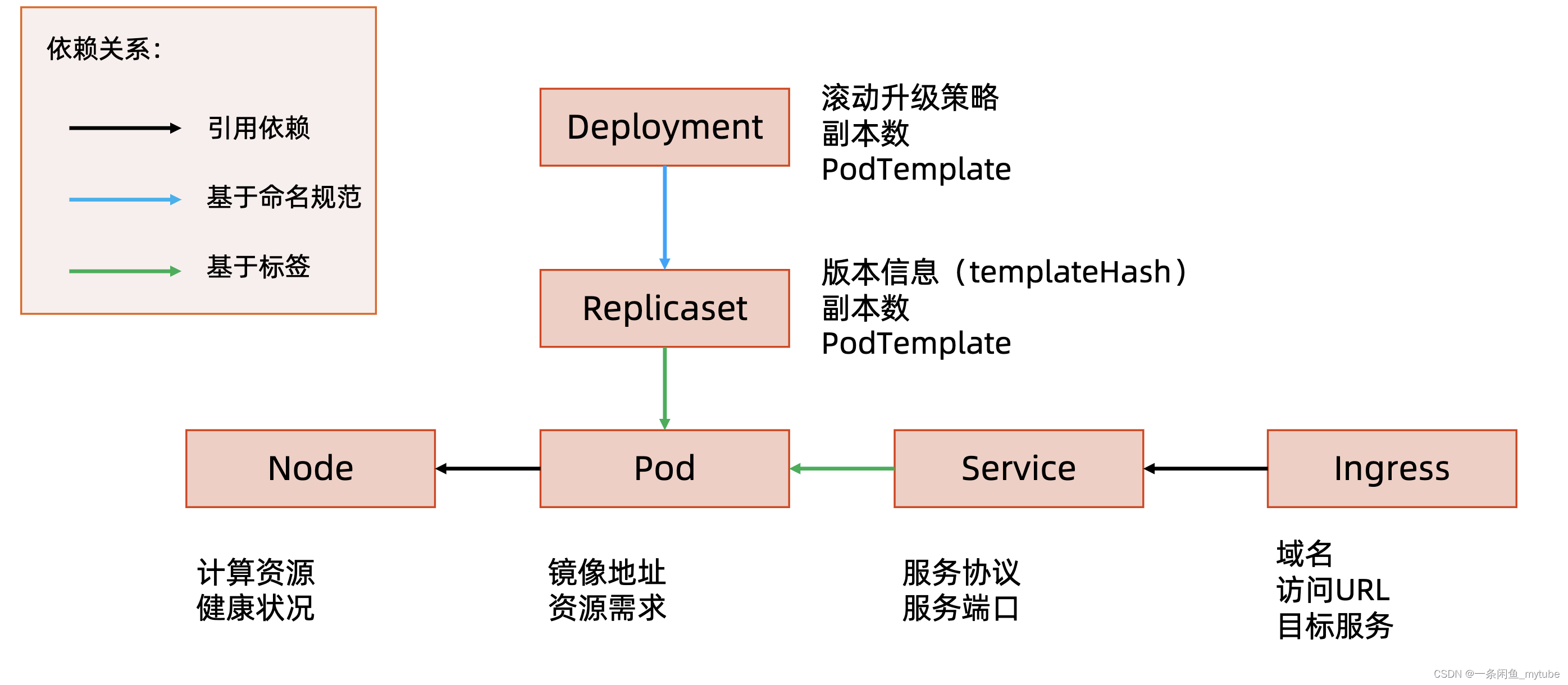
? Node:计算节点的抽象,用来描述计算节点的资源抽象、健康状态等。
? Namespace:资源隔离的基本单位,可以简单理解为文件系统中的目录结构。
? Pod:用来描述应用实例,包括镜像地址、资源需求等。 Kubernetes 中最核心的对象,也是打通应用和基础架构的秘密武器。
? Service:服务如何将应用发布成服务,本质上是负载均衡和域名服务的声明
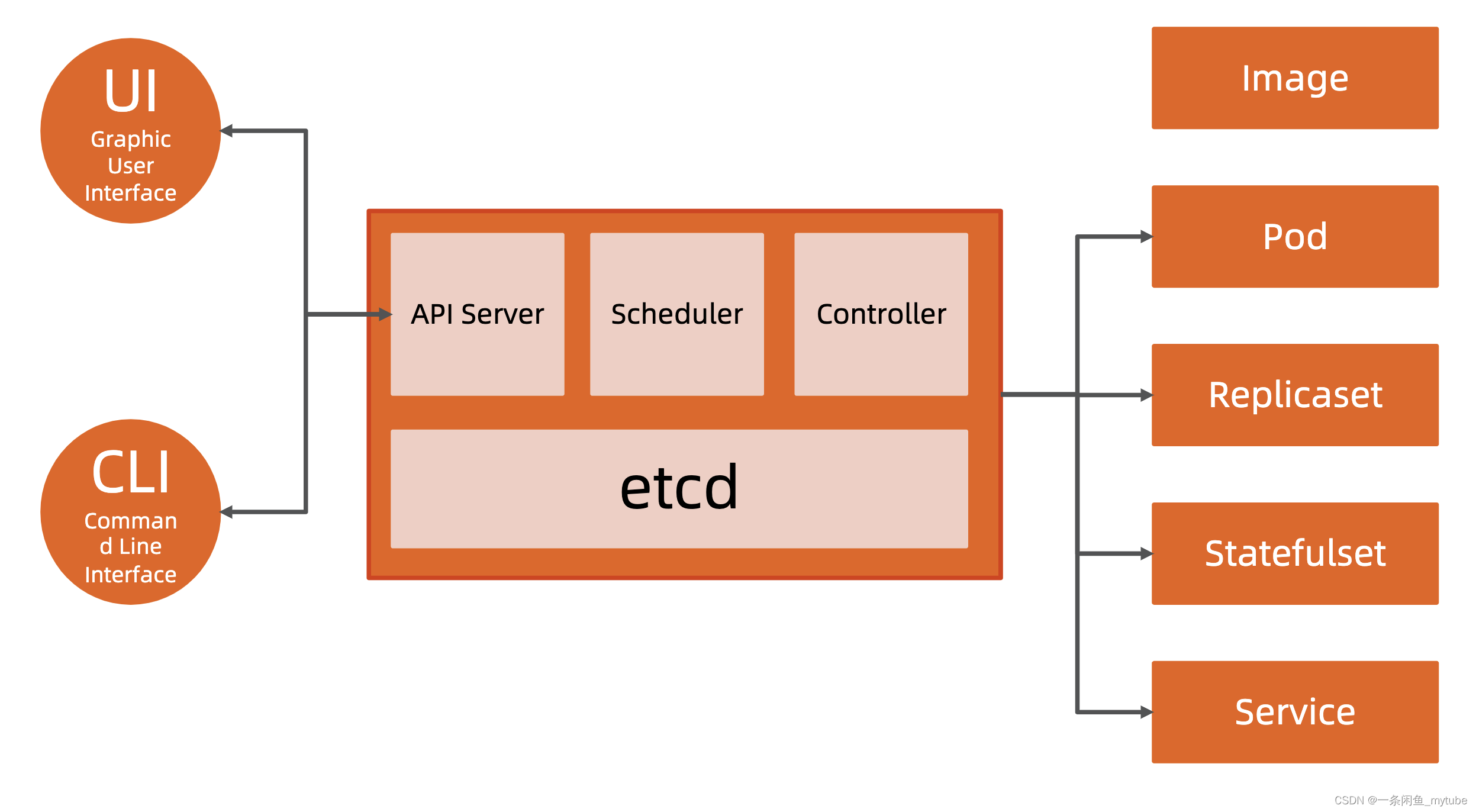
主要组件

Kubernetes 的主节点
API Server
- 这是 Kubernetes 控制面板中唯一带有用户可访问 API 以及用户可交互的组件。API 服
务器会暴露一个 RESTful 的 Kubernetes API 并使用 JSON 格式的清单文件(manifest
files)
群的数据存储
- Kubernetes 使 用 “ etcd” 。这 是 一 个 强 大 的 、 稳 定 的 、 高 可 用 的 键 值 存 储 , 被,Kubernetes 用于长久储存所有的 API 对象。
控制管理器
- 被称为“kube-controller manager”,它运行着所有处理集群日常任务的控制器。包
括了节点控制器、副本控制器、端点(endpoint)控制器以及服务账户等。
调度器
- 调度器会监控新建的 pods(一组或一个容器)并将其分配给节点。
Kubernetes 的工作节点
Kubelet
- 负责调度到对应节点的 Pod 的生命周期管理,执行任务并将 Pod 状态报告给主节
点的渠道,通过容器运行时(拉取镜像、启动和停止容器等)来运行这些容器。它
还会定期执行被请求的容器的健康探测程序。
Kube-proxy
- 它负责节点的网络,在主机上维护网络规则并执行连接转发。它还负责对正在服务的 pods 进行负载平衡。
etcd
- CoreOS 基于 Raft 开发的分布式 key-value 存储
- 基本的 key-value 存储
- 监听机制
- key 的过期及续约机制,用于监控和服务发现
- 原子 CAS 和 CAD,用于分布式锁和 leader 选举
APIServer
-
提供集群管理的 REST API 接口
- 认证 Authentication
- 授权 Authorization
- 准入 Admission(Mutating & Valiating)
-
提供其他模块之间的数据交互和通信的枢纽(其他模块通过 APIServer 查询或修改数据,只有 APIServer 才直接操作 etcd
-
APIServer 提供 etcd 数据缓存以减少集群对 etcd 的访问
-
APIServer 展开
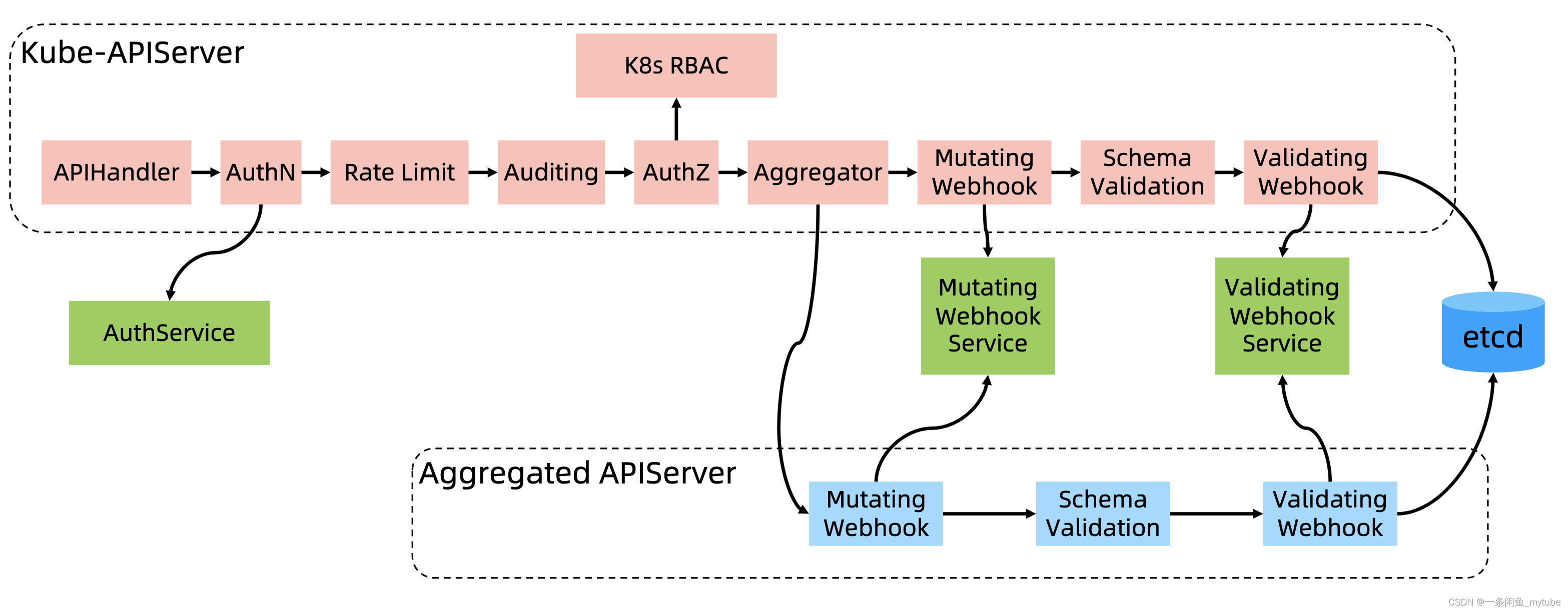
Controller Manager
-
集群的大脑
-
确保 Kubernetes 遵循声明式系统规范,确保系统的真实状态(ActualState)与用户定义的期望状态(Desired State)一致
-
是多个控制器的组合,每个 Controller 事实上都是一个control loop,负责侦听其管控的对象,当对象发生变更时完成配置
-
Controller 配置失败通常会触发自动重试,整个集群会在控制器不断重试的机制下确保最终一致性( Eventual Consistency)
-
控制器的工作流程
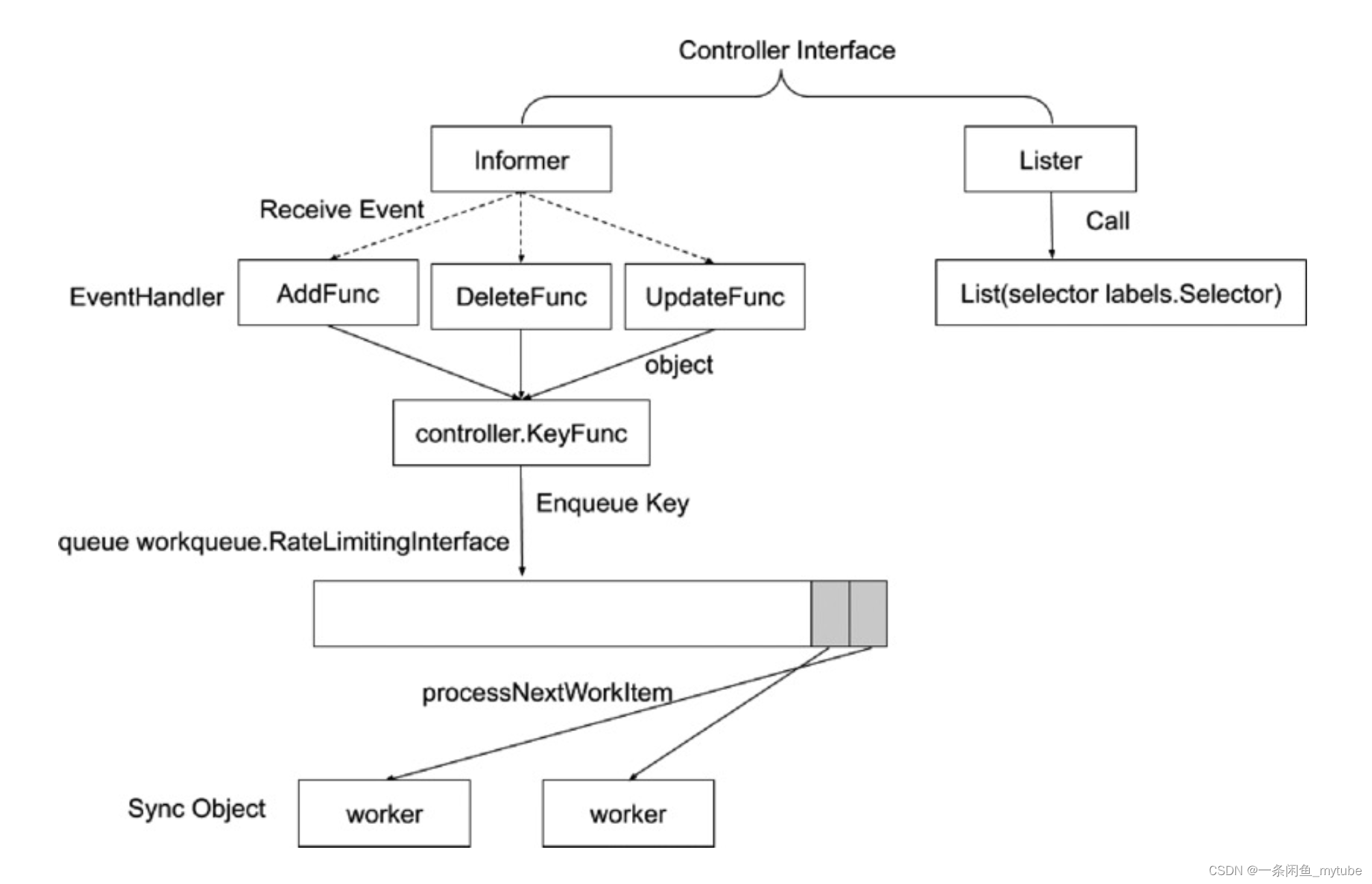
-
Informer 的内部机制

-
控制器的协同工作原理
-
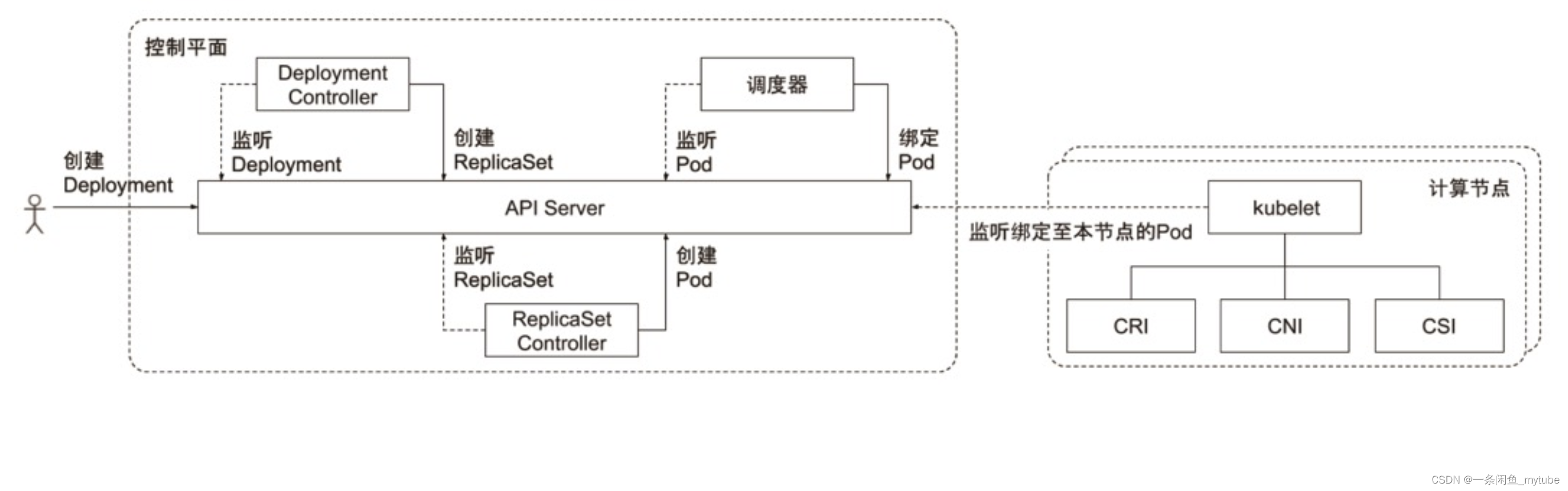
Scheduler
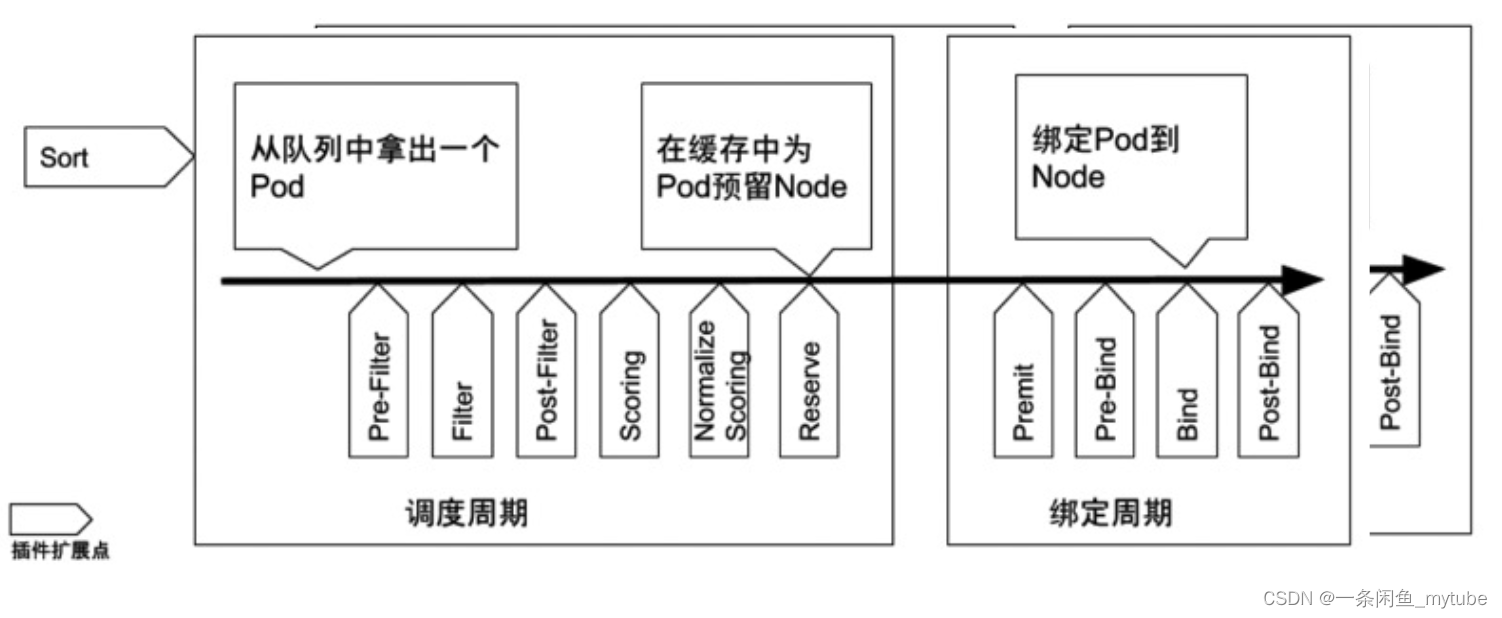
- Scheduler 的特殊职责在于监控当前集群所有未调度的 Pod,并且获取当前集群所有节点的健康状况和资源 Pod,并且获取当前集群所有节点的健康状况和资源使用情况,为待调度 Pod 选择最佳计算节点,完成调度
- 调度阶段分
- Predict:过滤不能满足业务需求的节点,如资源不足、端口冲突等
- Priority:按既定要素将满足调度需求的节点评分,选择最佳节点
- Bind:将计算节点与 Pod 绑定,完成调度
Kubelet
- 从不同源获取 Pod 清单,并按需求启停 Pod 的核心组件
- Pod 清单可从本地文件目录,给定的 HTTPServer 或 Kube-APIServer 等源头获取
- Kubelet 将运行时,网络和存储抽象成了 CRI,CNI,CSI
- 负责汇报当前节点的资源信息和健康状态
- 负责 Pod 的健康检查和状态汇报
Kube-Proxy
- 监控集群中用户发布的服务,并完成负载均衡配置
- 每个节点的 Kube-Proxy 都会配置相同的负载均衡策略,使得整个集群的服务发现建立在分布式负载均衡器之上,服务调用无需经过额外的网络跳转(Network Hop)
- 负载均衡配置基于不同插件实现
- userspace
- iptables
- ipvs
推荐的 Add-ons
- kube-dns:负责为整个集群提供 DNS 服务
- Ingress Controller:为服务提供外网入口
- MetricsServer:提供资源监控;
- Dashboard:提供 GUI
- Fluentd-Elasticsearch:提供集群日志采集、存储与查询
kubectl
- kubectl 会将接收到的用户请求转化为 rest 调用以rest client 的形式与 apiserver 通讯
- 默认读取配置文件 ~/.kube/config
kubectl 常用命令
-
kubectl get po –oyaml -w
-
kubectl describe po ubuntu-6fcf6c67db-xvmjh
-
kubectl exec
- kubectl exec 提供进入运行容器的通道,可以进入容器进行 debug 操作
-
kubectl logs 查看 pod 的标准输入(stdout, stderr),与 tail 用法类似
深入理解 Kubernetes
Kubernetes 生态系统
Kubernetes 设计理念
- 可扩展性
? 基于CRD的扩展
? 插件化的生态系统 - 高可用
- 给予replicates,statefulset 高可用
- 本身高可用
- 可移植性
? 多种 host Os 选择
? 多种基础架构的选择
? 多云和混合云 - 安全
基于 TLS 提供服务
? Serviceaccount 和 user
? 基于 Namespace 的隔离
? secret
? Taints,psp, networkpolicy
Kubernetes Master
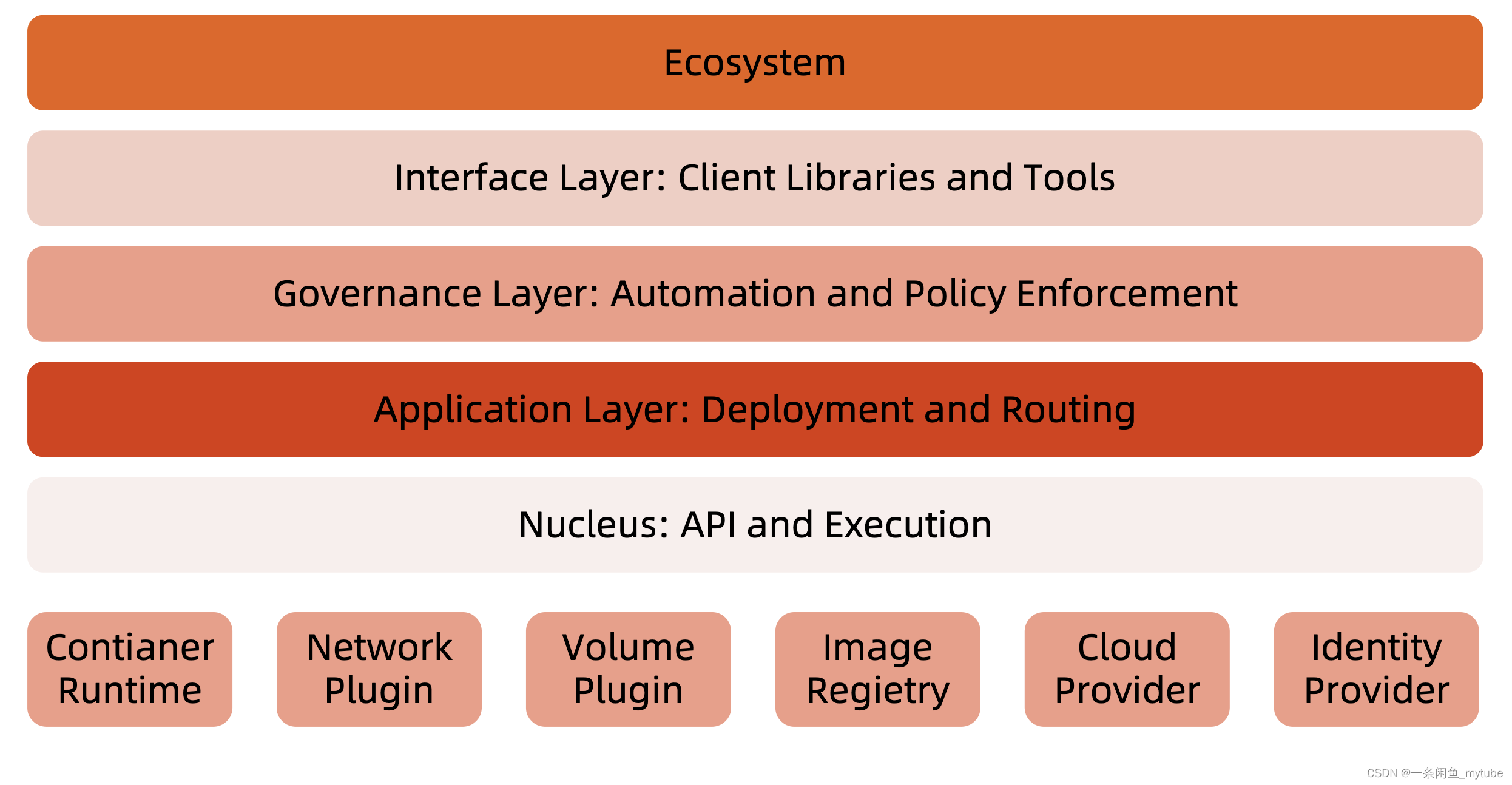
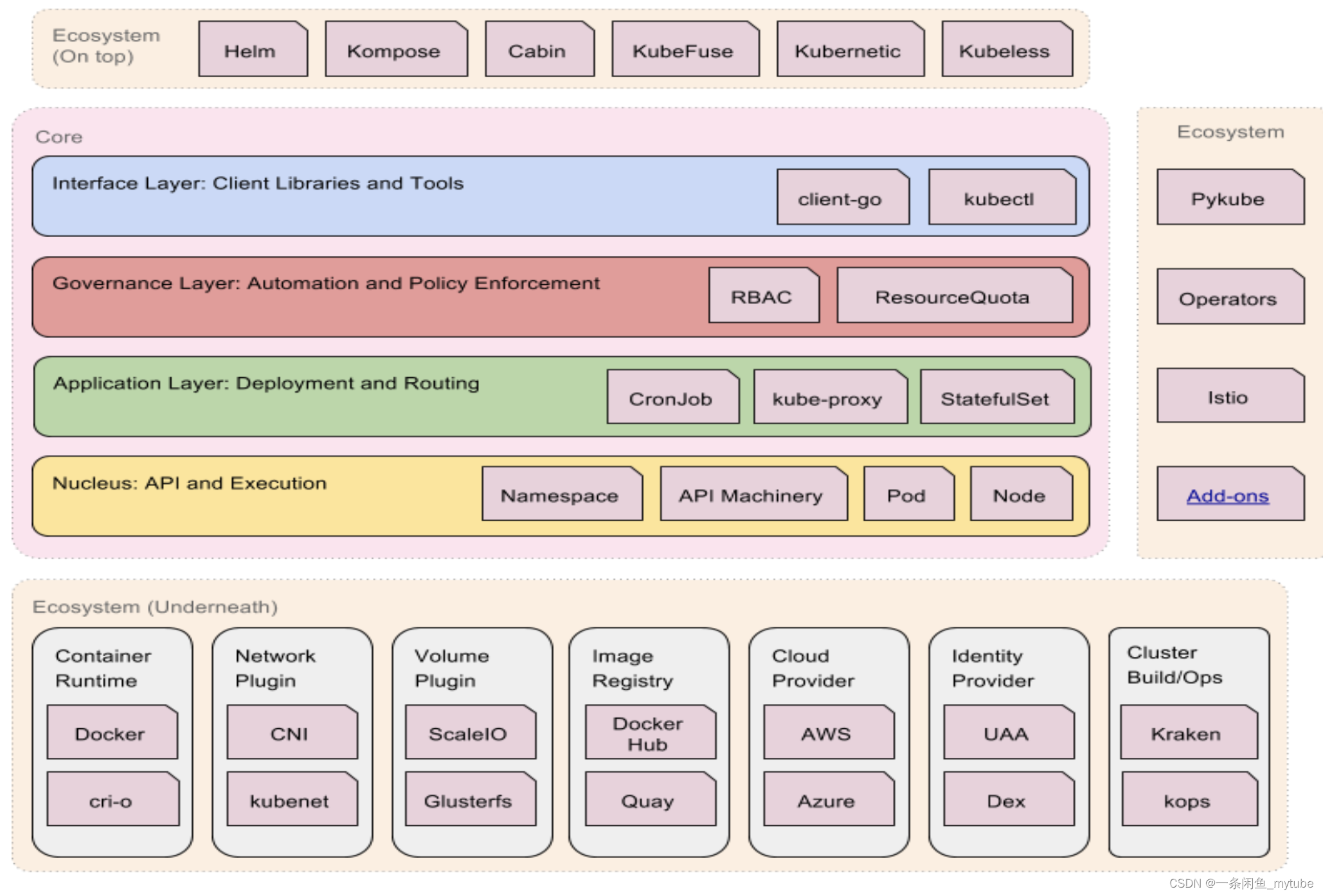
分层架构
? 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境。
? 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析
等)。
? 管理层:系统度量(如基础设施、容器和网络的度量)、自动化(如自动扩展、动态 Provision 等)、
策略管理(RBAC、Quota、PSP、NetworkPolicy 等)。
? 接口层:Kubectl 命令行工具、客户端 SDK 以及集群联邦。
? 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴:
? Kubernetes 外 部 : 日 志 、 监 控 、 配 置 管 理 、 CI 、 CD 、 Workflow 、 FaaS 、 OTS 应 用 、
ChatOps 等;
? Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等。
API 设计原则
-
低层 API 根据高层 API 的控制需要设计
- 设计实现低层 API 的目的,是为了被高层 API 使用,考虑减少冗余、提高重用性的目的,低层 API
的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑
- 设计实现低层 API 的目的,是为了被高层 API 使用,考虑减少冗余、提高重用性的目的,低层 API
-
尽量避免简单封装,不要有在外部 API 无法显式知道的内部隐藏的机制
- StatefulSet 和 ReplicaSet,本来就是两种 Pod 集合,那么 Kubernetes 就用不同 API 对象
来定义它们,而不会说只用同一个 ReplicaSet,内部通过特殊的算法再来区分这个 ReplicaSet 是
有状态的还是无状态
- StatefulSet 和 ReplicaSet,本来就是两种 Pod 集合,那么 Kubernetes 就用不同 API 对象
-
API 操作复杂度与对象数量成正比
- API 的操作复杂度不能超过 O(N),否则系统就不具备水平伸缩性了
-
API 对象状态不能依赖于网络连接状态
- 由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证 API 对象状态能应对网络的不稳定,API 对象的状态就不能依赖于网络连接状态
-
尽量避免让操作机制依赖于全局状态
- 因为在分布式系统中要保证全局状态的同步是非常困难的
Kubernetes 如何通过对象的组合完成业务描述
架构设计原则
- 只有 APIServer 可以直接访问 etcd 存储,其他服务必须通过 Kubernetes
API 来访问集群状态 - 单节点故障不应该影响集群的状态
- 在没有新请求的情况下,所有组件应该在故障恢复后继续执行上次最后收到的请求
(比如网络分区或服务重启等) - 所有组件都应该在内存中保持所需要的状态,APIServer 将状态写入 etcd 存储,而其
他组件则通过 APIServer 更新并监听所有的变化; - 优先使用事件监听而不是轮询
引导(Bootstrapping)原则
? Self-hosting 是目标。
? 减少依赖,特别是稳态运行的依赖。
? 通过分层的原则管理依赖。
? 循环依赖问题的原则:
? 同时还接受其他方式的数据输入(比如本地文件等),这样在其他服务不可
用时还可以手动配置引导服务;
? 状态应该是可恢复或可重新发现的;
? 支持简单的启动临时实例来创建稳态运行所需要的状态,使用分布式锁或文
件锁等来协调不同状态的切换(通常称为 pivoting 技术);
? 自动重启异常退出的服务,比如副本或者进程管理器等
核心技术概念和 API 对象
- API 对象是 Kubernetes 集群中的管理操作单元
- 每个 API 对象都有四大类属性
? TypeMeta
? MetaData
? Spec
? Status
TypeMeta
-
引入GKV(Group,Kind,Version)模型定义了一个对象的类型
-
Group
- 将对象依据其功能范围归入不同的分组,
比如把支撑最基本功能的对象归入 core 组,把与应用部署有关的对象归入 apps 组
- 将对象依据其功能范围归入不同的分组,
-
Kind
- 定义一个对象的基本类型,比如 Node、Pod、Deployment 等
-
Version
Metadata
- Metadata 中有两个最重要的属性:Namespace和Name,分别定义了对象的
Namespace 归属及名字,这两个属性唯一定义了某个对象实例。 - Label:Label 定义了对象的可识别属性,Kubernetes API 支持以 Label 作为过滤条件
查询对象- key/value 的方式附加到对象上
- key 最长不能超过 63 字节,value 可以为空,也可以是不超过 253 字节的字符串
- Label 不提供唯一性,并且实际上经常是很多对象(如 Pods)都使用相同的 label 来标志具体的应用
- Label 定义好后其他对象可以使用 Label Selector 来选择一组相同 label 的对象
- Label Selector 支持以下几种方式:
? 等式,如 app=nginx 和 env!=production;
? 集合,如 env in (production, qa);
? 多个 label(它们之间是 AND 关系),如 app=nginx,env=test
- Annotation: Annotation 与 Label 一样用键值对来定义,但 Annotation 是作为属性扩展,
更多面向于系统管理员和开发人员,因此需要像其他属性一样做合理归类。- Annotations 是 key/value 形式附加于对象的注解
- 不同于 Labels 用于标志和选择对象,Annotations 则是用来记录一些附加信息,用来辅助应用部署、安
全策略以及调度策略等 - 如 deployment 使用 annotations 来记录 rolling update 的状态
Metadata
- Finalizer 本质上是一个资源锁,Kubernetes 在接收某对象的删除请求时,会检
查 Finalizer 是否为空,如果不为空则只对其做逻辑删除,即只会更新对象中的
metadata.deletionTimestamp 字段
ResourceVersion
- ResourceVersion 可以被看作一种乐观锁,每个对象在任意时刻都有其
ResourceVersion,当 Kubernetes 对象被客户端读取以后,ResourceVersion
信息也被一并读取。此机制确保了分布式系统中任意多线程能够无锁并发访问对
象,极大提升了系统的整体效率。
Spec 和 Status
- Spec 是用户的期望状态,由创建对象的用户端来定义。
- Status 是对象的实际状态,由对应的控制器收集实际状态并更新。
- 与 TypeMeta 和 Metadata 等通用属性不同,Spec 和 Status 是每个对象独有的
常用 Kubernetes 对象及其分组
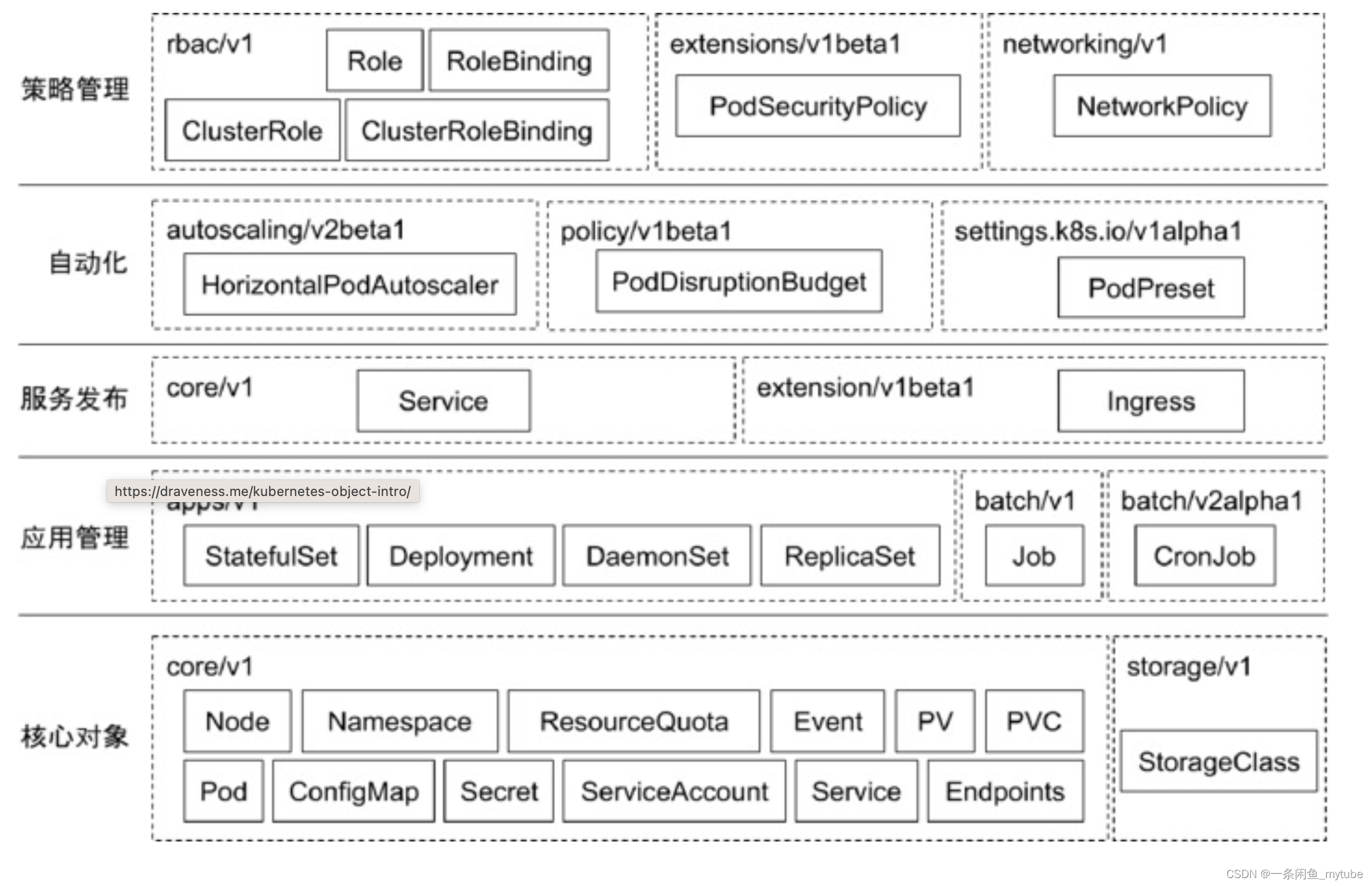
核心对象概览
Node
? Node 是 Pod 真正运行的主机,可以物理机,也可以是虚拟机。
? 为了管理 Pod,每个 Node 节点上至少要运行 container runtime
(比如 Docker 或者 Rkt)、Kubelet 和 Kube-proxy 服务
Namespace
- Namespace 是对一组资源和对象的抽象集合
- 常见的 pods, services, replication controllers 和 deployments 等都是属于
某一个 Namespace 的(默认是 default),而 Node, persistentVolumes
等则不属于任何 Namespace
什么是 Pod
- Pod 是一组紧密关联的容器集合,它们共享 PID、IPC、Network 和 UTS namespace,是 Kubernetes
调度的基本单位 - Pod 的设计理念是支持多个容器在一个 Pod 中共享网络和文件系统,可以通过进程间通信和文件共享这
种简单高效的方式组合完成服务 - 同一个 Pod 中的不同容器可共享资源:
? 共享网络 Namespace;
? 可通过挂载存储卷共享存储;
? 共享 Security Context
如何通过 Pod 对象定义支撑应用运行
- 环境变量:
? 直接设置值;
? 读取 Pod Spec 的某些属性;
? 从 ConfigMap 读取某个值;
? 从 Secret 读取某个值
存储卷
? 通过存储卷可以将外挂存储挂载到 Pod 内部使用。
? 存储卷定义包括两个部分: Volume 和 VolumeMounts。
? Volume:定义 Pod 可以使用的存储卷来源;
? VolumeMounts:定义存储卷如何 Mount 到容器内部
apiVersion: v1
kind: Pod
metadata:
name: hello-volume
spec:
containers:
- image: nginx:1.15
name: nginx
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
emptyDir: {}
Pod 网络
-
Pod的多个容器是共享网络 Namespace 的
-
同一个 Pod 中的不同容器可以彼此通过 Loopback 地址访问
- 在第一个容器中起了一个服务 http://127.0.0.1
- 在第二个容器内,是可以通过 httpGet http://172.0.0.1 访问到该地址的
-
这种方法常用于不同容器的互相协作
资源限制
- Kubernetes 通过 Cgroups 提供容器资源管理的功能,可以限制每个容器的
CPU 和内存使用
kubectl set resources deployment nginx-app -c=nginx --
limits=cpu=500m,memory=128Mi
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: "500m"
memory: "128Mi"
健康检查
探针类型
? LivenessProbe
? 探测应用是否处于健康状态,如果不健康则删除并重新创建容器。
? ReadinessProbe
? 探测应用是否就绪并且处于正常服务状态,如果不正常则不会接收来自 Kubernetes Service 的流量。
? StartupProbe
? 探测应用是否启动完成,如果在 failureThreshold*periodSeconds 周期内未就绪,则会应用进程会被重启。
探活方式
? Exec
? TCP socket
? HTTP
健康检查 spec
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-default
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: http
resources: {}
terminationMessagePath:
/dev/termination-log
terminationMessagePolicy: File
resources:
limits:
cpu: "500m"
memory: "128Mi"
ivenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 15
timeoutSeconds: 1
readinessProbe:
httpGet:
path: /ping
port: 80
initialDelaySeconds: 5
timeoutSeconds: 1
ConfigMap
? ConfigMap 用来将非机密性的数据保存到键值对中。
? 使用时, Pods 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。
? ConfigMap 将环境配置信息和 容器镜像解耦,便于应用配置的修改
密钥对象(Secret)
? Secret 是用来保存和传递密码、密钥、认证凭证这些敏感信息的对象。
? 使用 Secret 的好处是可以避免把敏感信息明文写在配置文件里。
? Kubernetes 集群中配置和使用服务不可避免的要用到各种敏感信息实现登录、认
证等功能,例如访问 AWS 存储的用户名密码。
? 为了避免将类似的敏感信息明文写在所有需要使用的配置文件中,可以将这些信息
存入一个 Secret 对象,而在配置文件中通过 Secret 对象引用这些敏感信息。
? 这种方式的好处包括:意图明确,避免重复,减少暴漏机会
用户(User Account)& 服务帐户(Service Account)
- 用户帐户为人提供账户标识,而服务账户为计算机进程和 Kubernetes 集群中运行的 Pod 提供
账户标识
? 用户帐户对应的是人的身份,人的身份与服务的 Namespace 无关,所以用户账户是跨
Namespace 的;
? 而服务帐户对应的是一个运行中程序的身份,与特定 Namespace 是相关的
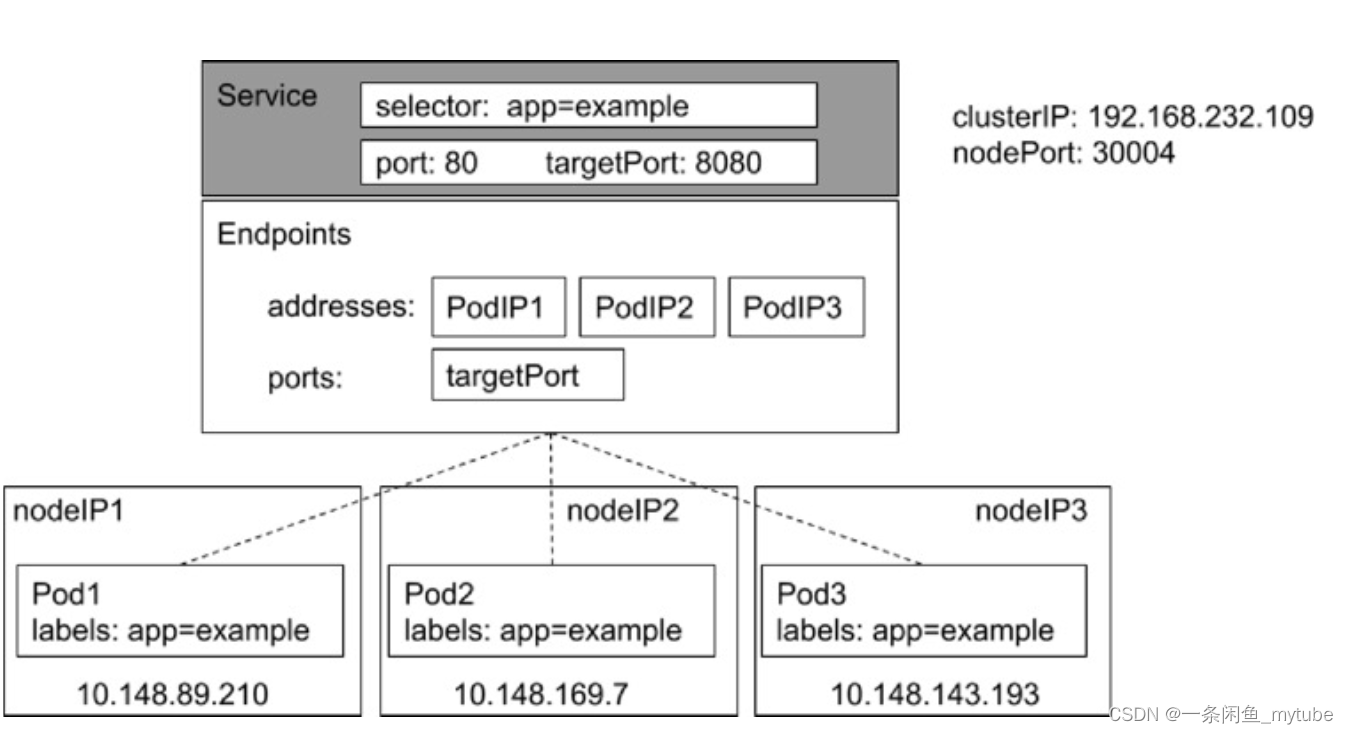
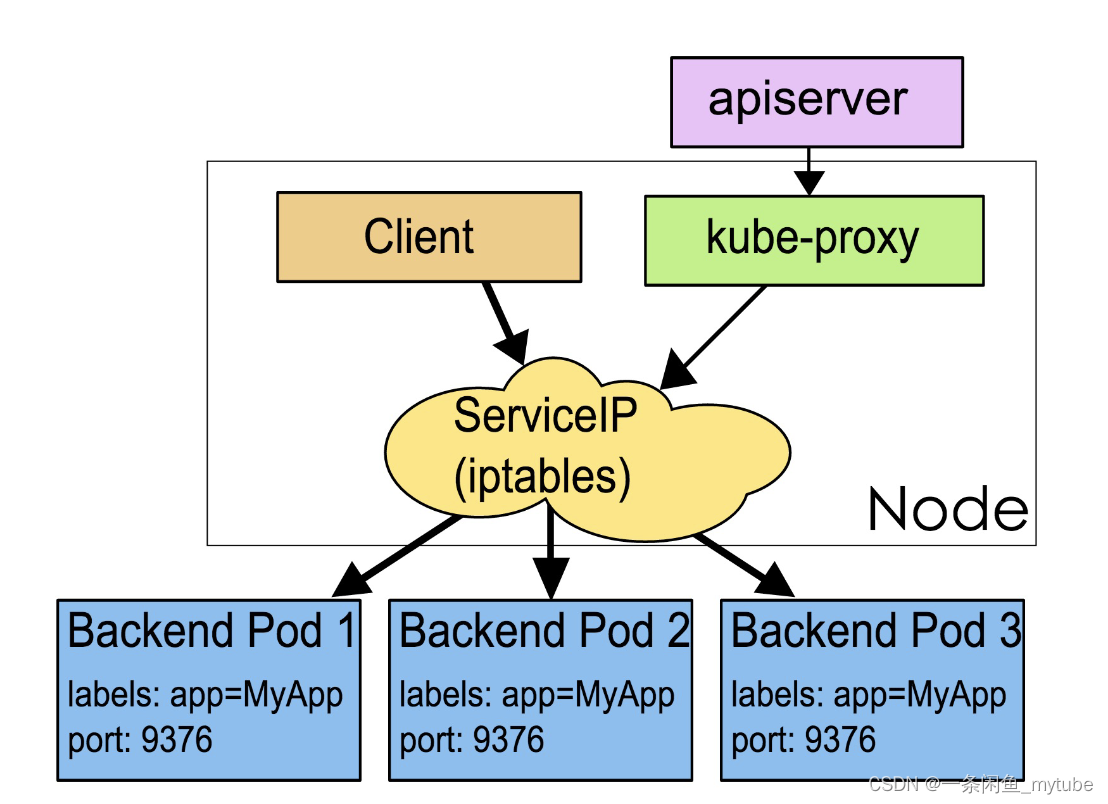
Service
- Service 是应用服务的抽象,通过 labels 为应用提供负载均衡和服务发现。匹
配 labels 的 Pod IP 和端口列表组成 endpoints,由 Kube-proxy 负责将服务
IP 负载均衡到这些 endpoints 上 - 每个 Service 都会自动分配一个 cluster IP(仅在集群内部可访问的虚拟地址)
和 DNS 名,其他容器可以通过该地址或 DNS 来访问服务,而不需要了解后端
容器的运行
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
ports:
- port: 8078 # the port that this service should serve on
name: http
# the container on each pod to connect to, can be a name
# (e.g. 'www') or a number (e.g. 80)
targetPort: 80
protocol: TCP
selector:
app: nginx
副本集(Replica Set
? Pod 只是单个应用实例的抽象,要构建高可用应用,通常需要构建多个同样的副本,提供同一个服务。
? Kubernetes 为此抽象出副本集 ReplicaSet,其允许用户定义 Pod 的副本数,每一个 Pod 都会被当作一
个无状态的成员进行管理,Kubernetes 保证总是有用户期望的数量的 Pod 正常运行
? 当某个副本宕机以后,控制器将会创建一个新的副本。
? 当因业务负载发生变更而需要调整扩缩容时,可以方便地调整副本数量
部署(Deployment)
? 部署表示用户对 Kubernetes 集群的一次更新操作。
? 部署是一个比 RS 应用模式更广的 API 对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。
? 滚动升级一个服务,实际是创建一个新的 RS,然后逐渐将新 RS 中副本数增加到理想状态,将旧 RS 中的副本数减小到 0 的
复合操作。
? 这样一个复合操作用一个 RS 是不太好描述的,所以用一个更通用的 Deployment 来描述。
? 以 Kubernetes 的发展方向,未来对所有长期伺服型的的业务的管理,都会通过 Deployment 来管理

有状态服务集(StatefulSet)
? 对于 StatefulSet 中的 Pod,每个 Pod 挂载自己独立的存储,如果一个 Pod 出现故障,从其他节点启动一个同样名字的
Pod,要挂载上原来 Pod 的存储继续以它的状态提供服务。
? 适合于 StatefulSet 的业务包括数据库服务 MySQL 和 PostgreSQL,集群化管理服务 ZooKeeper、etcd 等有状态服务。
? 使用 StatefulSet,Pod 仍然可以通过漂移到不同节点提供高可用,而存储也可以通过外挂的存储来提供高可靠性,
StatefulSet 做的只是将确定的 Pod 与确定的存储关联起来保证状态的连续性

Statefulset 与 Deployment 的差异
- 身份标识
? StatefulSet Controller 为每个 Pod 编号,序号从0开始 - 数据存储
? StatefulSet 允许用户定义 volumeClaimTemplates,Pod 被创建的同时,Kubernetes 会以
volumeClaimTemplates 中定义的模板创建存储卷,并挂载给 Pod - StatefulSet 的升级策略不同
- 的升级策略不同
? onDelete
? 滚动升级
? 分片升级
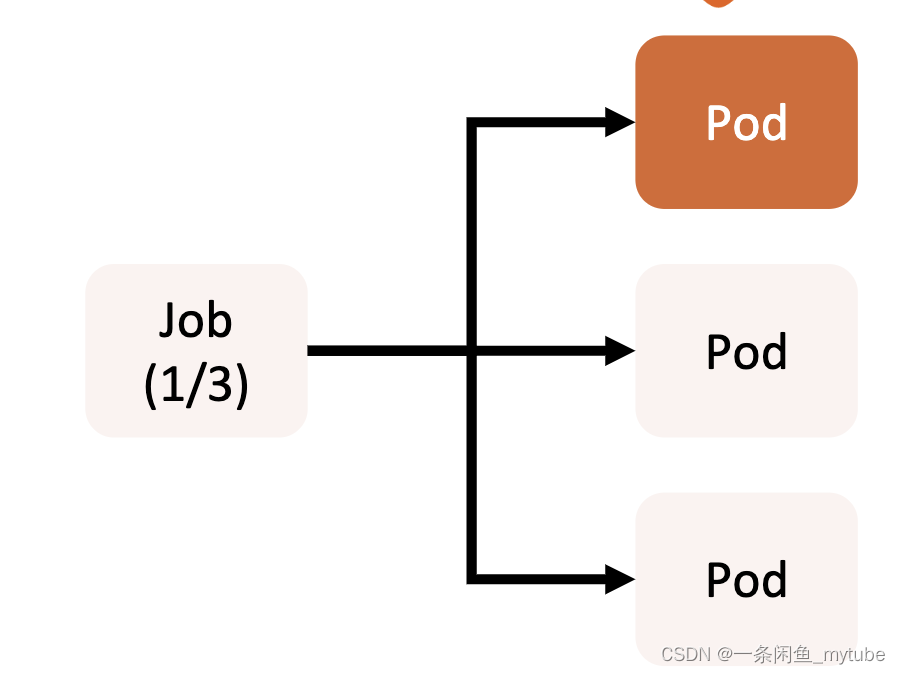
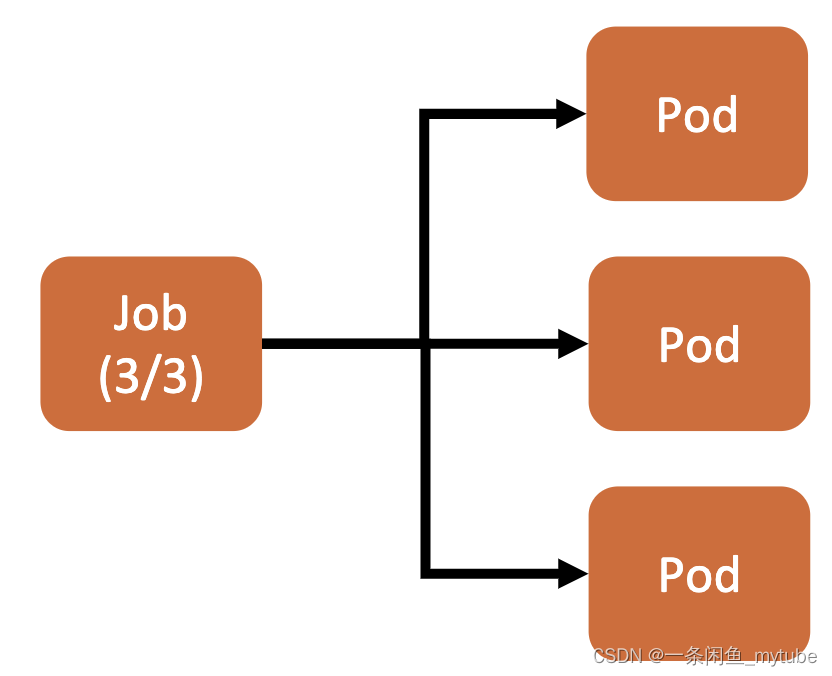
任务(Job)
? Job 是 Kubernetes 用来控制批处理型任务的 API 对象。
? Job 管理的 Pod 根据用户的设置把任务成功完成后就自动退出。
? 成功完成的标志根据不同的 spec.completions 策略而不同:
? 单 Pod 型任务有一个 Pod 成功就标志完成;
? 定数成功型任务保证有 N 个任务全部成功;
? 工作队列型任务根据应用确认的全局成功而标志成功
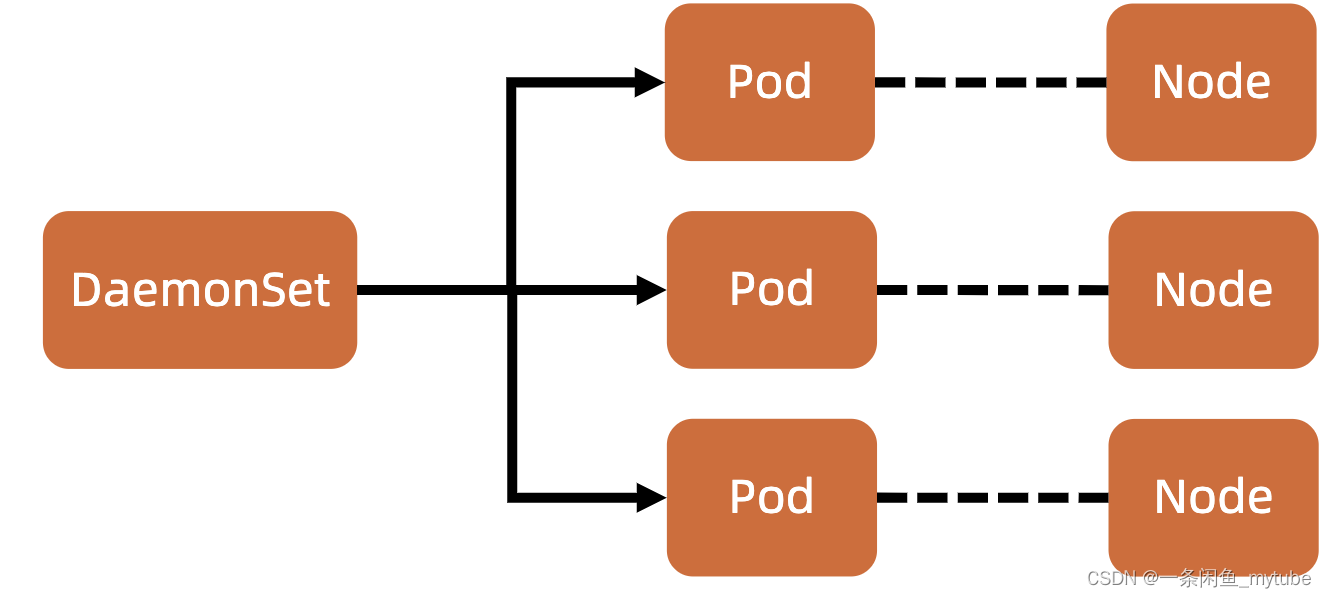
后台支撑服务集(DaemonSet)
? 长期伺服型和批处理型服务的核心在业务应用,可能有些节点运行多个同类业务的 Pod,有些节点上又没有这类 Pod 运行;
? 而后台支撑型服务的核心关注点在 Kubernetes 集群中的节点(物理机或虚拟机),要保证每个节点上都有一个此类 Pod 运行。
? 节点可能是所有集群节点也可能是通过 nodeSelector 选定的一些特定节点。
? 典型的后台支撑型服务包括存储、日志和监控等在每个节点上支撑 Kubernetes 集群运行的服务。
存储 PV 和 PVC
? PersistentVolume(PV)是集群中的一块存储卷,可以由管理员手动设置,
或当用户创建 PersistentVolumeClaim(PVC)时根据 StorageClass 动
态设置。
? PV 和 PVC 与 Pod 生命周期无关。也就是说,当 Pod 中的容器重新启动、
Pod 重新调度或者删除时,PV 和 PVC 不会受到影响,Pod 存储于 PV 里
的数据得以保留。
? 对于不同的使用场景,用户通常需要不同属性(例如性能、访问模式等)
的 PV
CustomResourceDefinition
? CRD 就像数据库的开放式表结构,允许用户自定义 Schema。
? 有了这种开放式设计,用户可以基于 CRD 定义一切需要的模型,满足不同
业务的需求。
? 社区鼓励基于 CRD 的业务抽象,众多主流的扩展应用都是基于 CRD 构建
的,比如 Istio、Knative。
? 甚至基于 CRD 推出了 Operator Mode 和 Operator SDK,可以以极低的
开发成本定义新对象,并构建新对象的控制器。
refer 云原生训练营
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- VUE--组件通信(父子)
- 【Dart】=> [02] Dart初体验-基础语法(ing~
- yolov5_master的下载、环境搭建、数据处理及训练全过程
- 1月18号“纯鸿蒙”千帆启航,程序员预备!
- 产品经理和项目经理怎么区分?看完你也会
- 深入理解堆(Heap):一个强大的数据结构
- uni-app只执行一次事件
- QAM 归一化因子
- 【论文精读】A Survey on Large Language Model based Autonomous Agents
- AtCoder Toyota Programming Contest 2023#8(AtCoder Beginner Contest 333)B题解