springboot整合kafka附源码
前提:确保kafka环境
我使用的方案是docker
我使用的镜像为:wurstmeister/kafka
我使用的镜像为:wurstmeister/zookeeper
docker安装kafka和zk教程:点这里手把手教你使用Docker搭建kafka【详细教程】
使用kafka前,要确保你对kafka有一个基本的了解,如topic(可以看成是rabbitmq的队列),分区,offset,生产者,消费者,消费者组等
此教程源码地址:https://gitee.com/jackXUYY/springboot-example.git
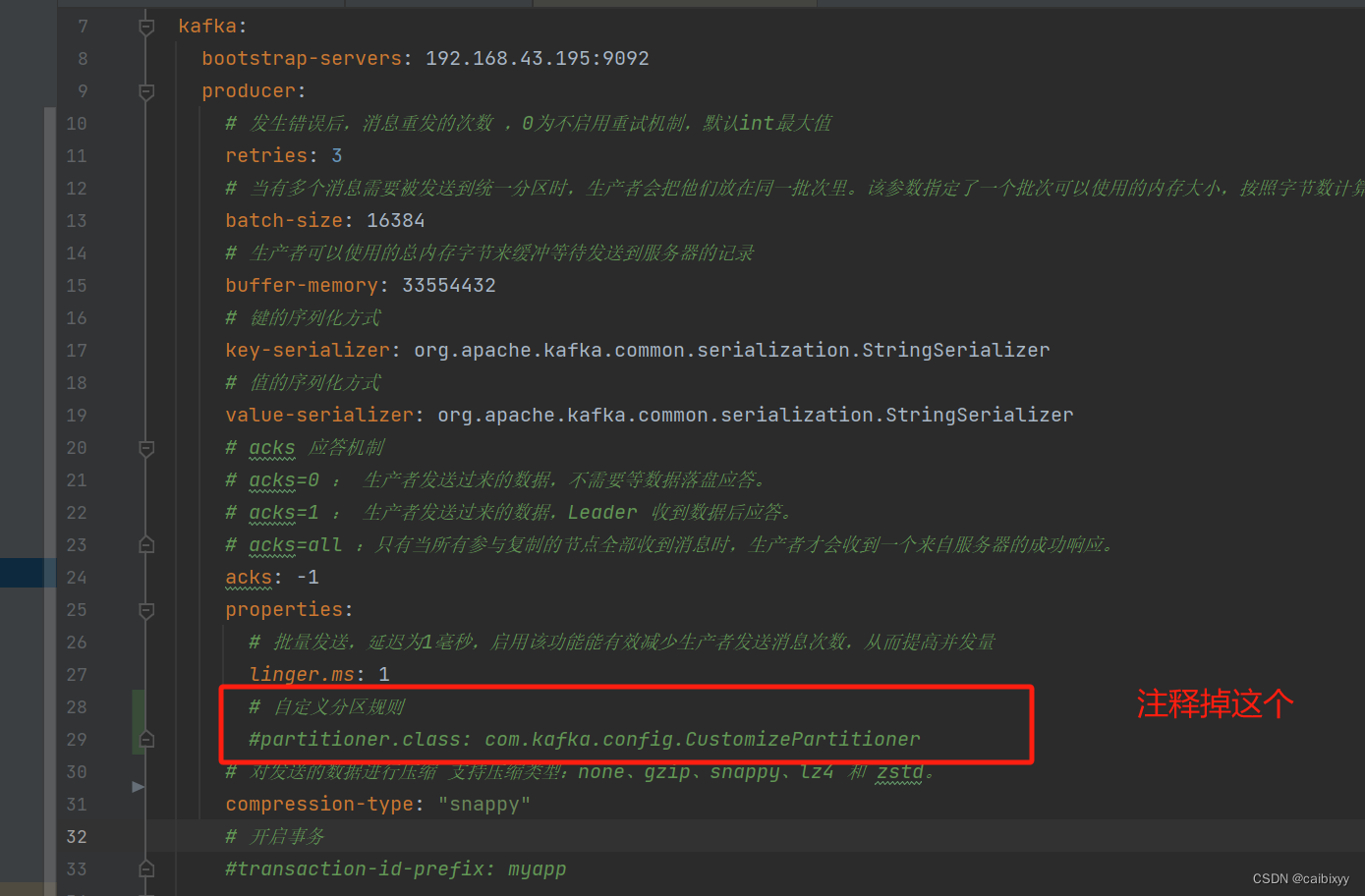
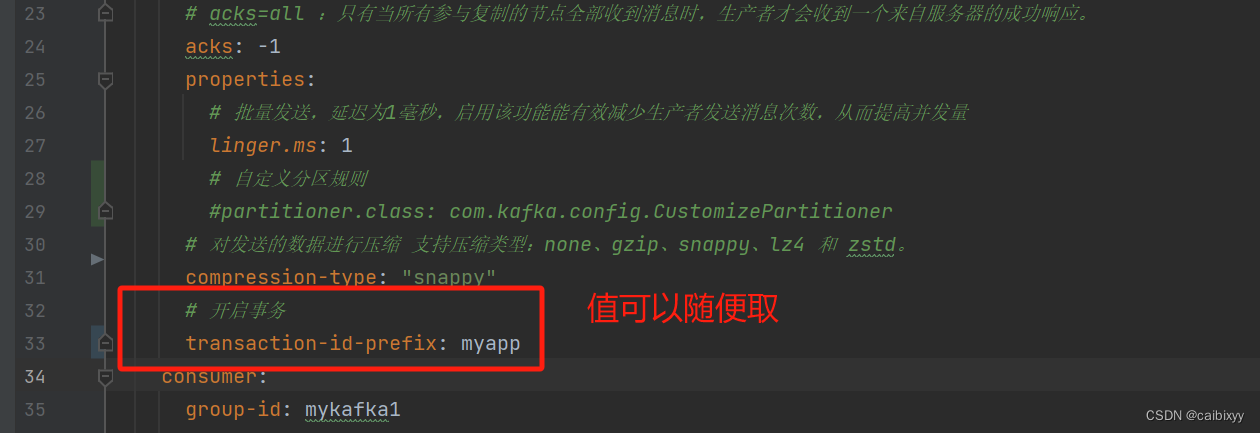
拉下代码之后,改一下kafka的地址为自己的kafka地址,然后把事务配置先注释掉
配置文件里的transaction-id-prefix属性
检查项目能否正常启动
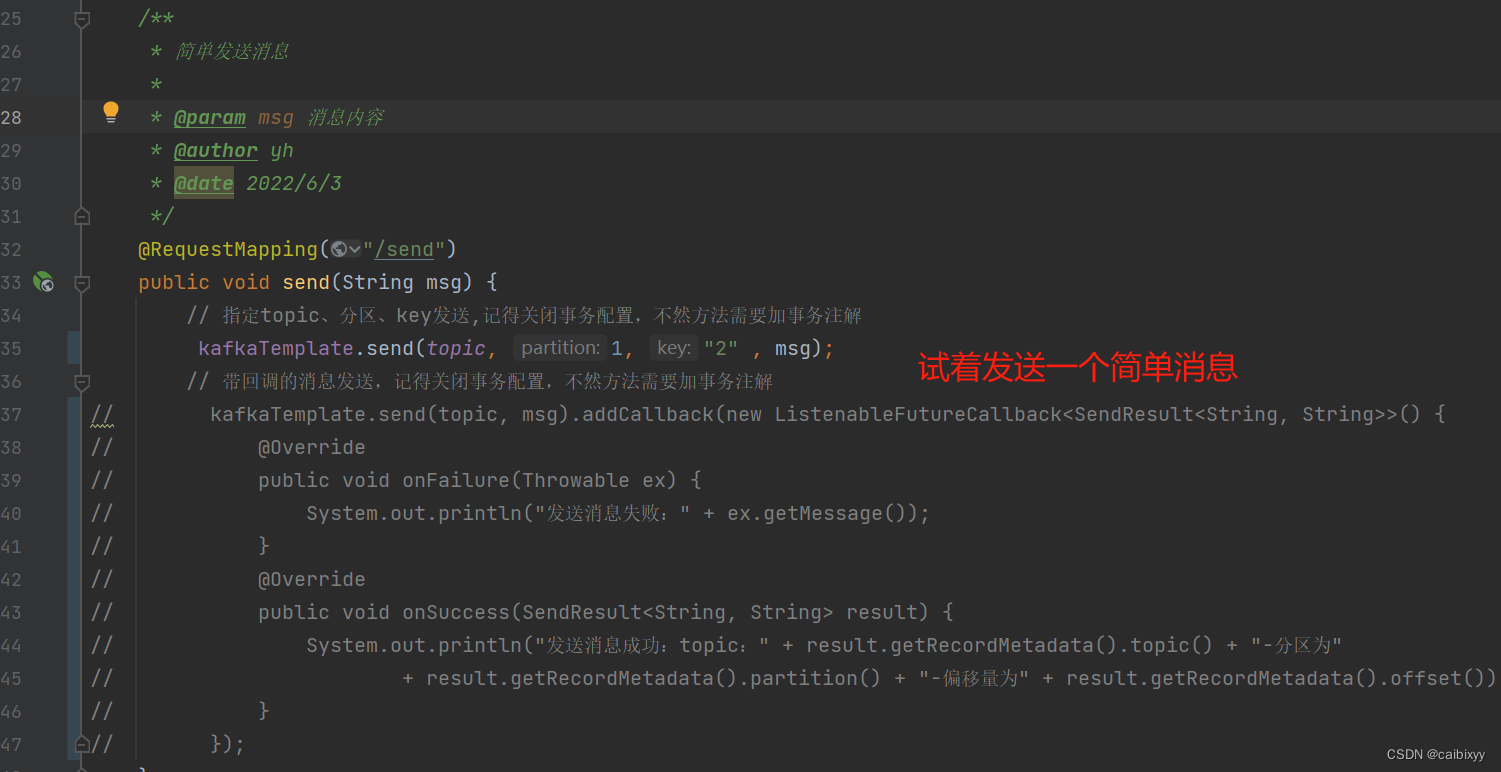
我们先试一下简单的生产消费

发送消息
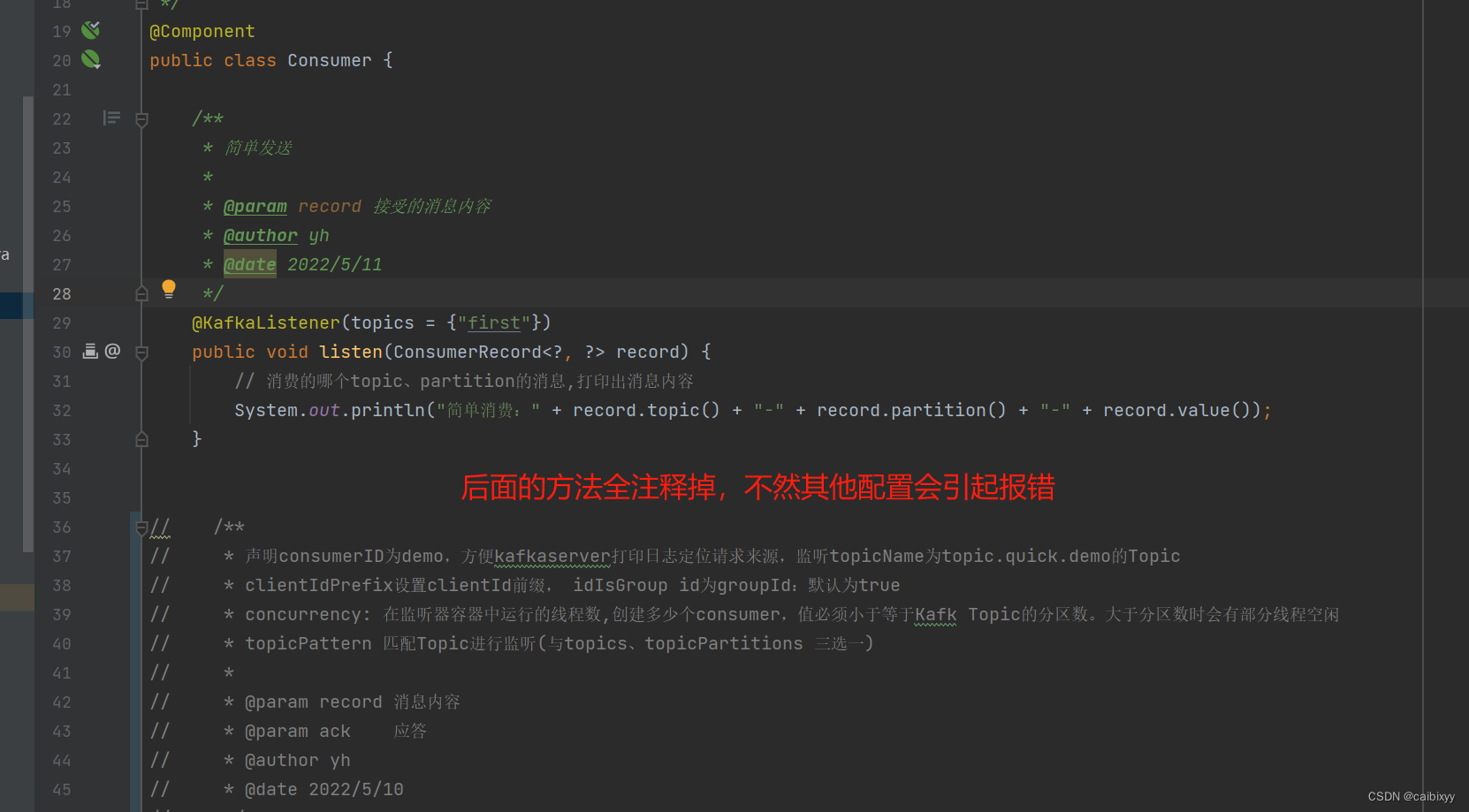
消费者
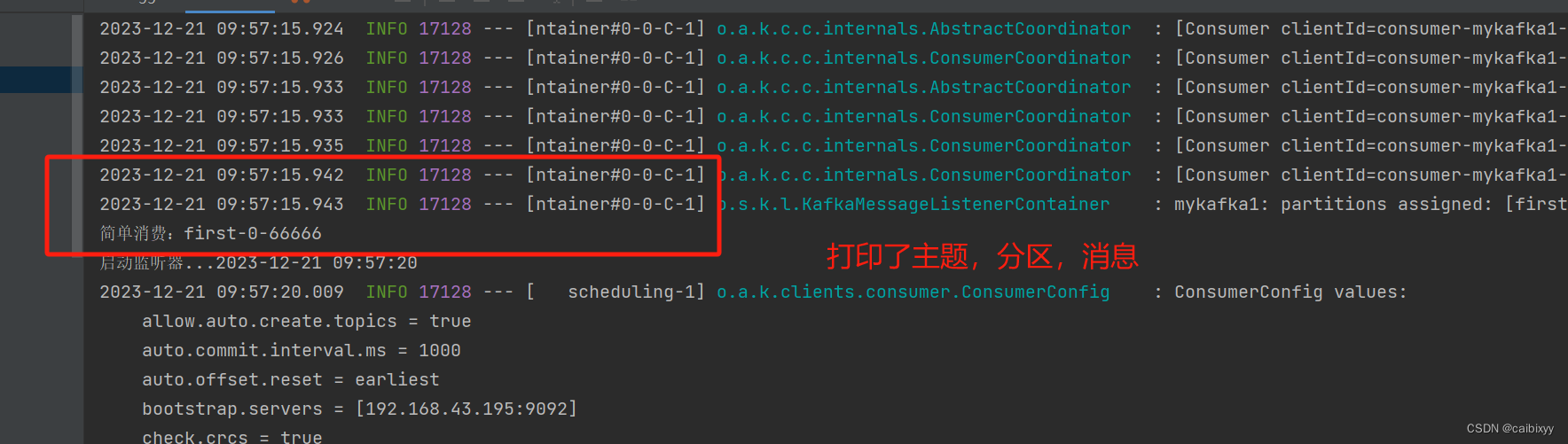
打印结果
再试一下发送消息带回调的方式
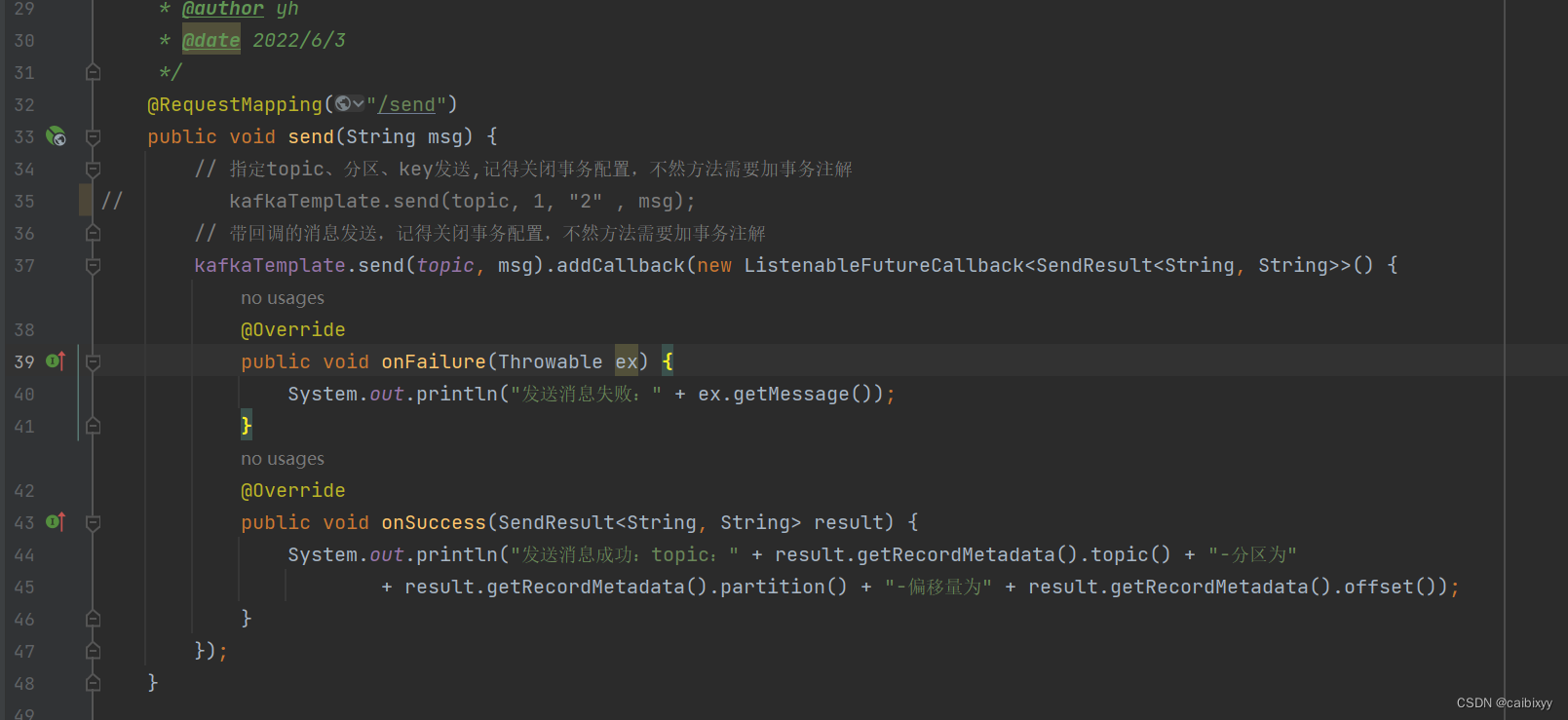

发送和消费结果

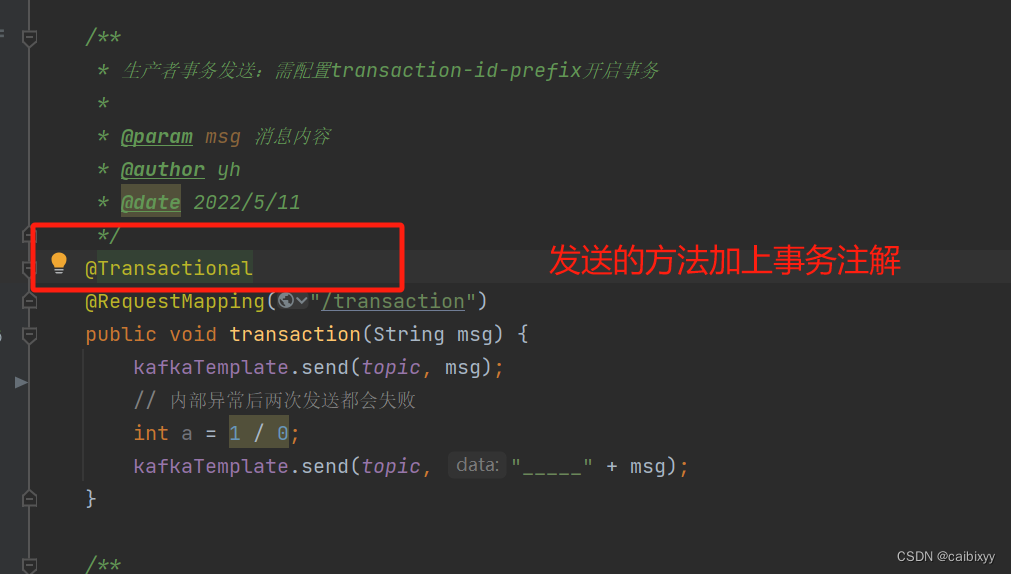
我们再试一下事务消息
生产者事务发送:需配置transaction-id-prefix开启事务
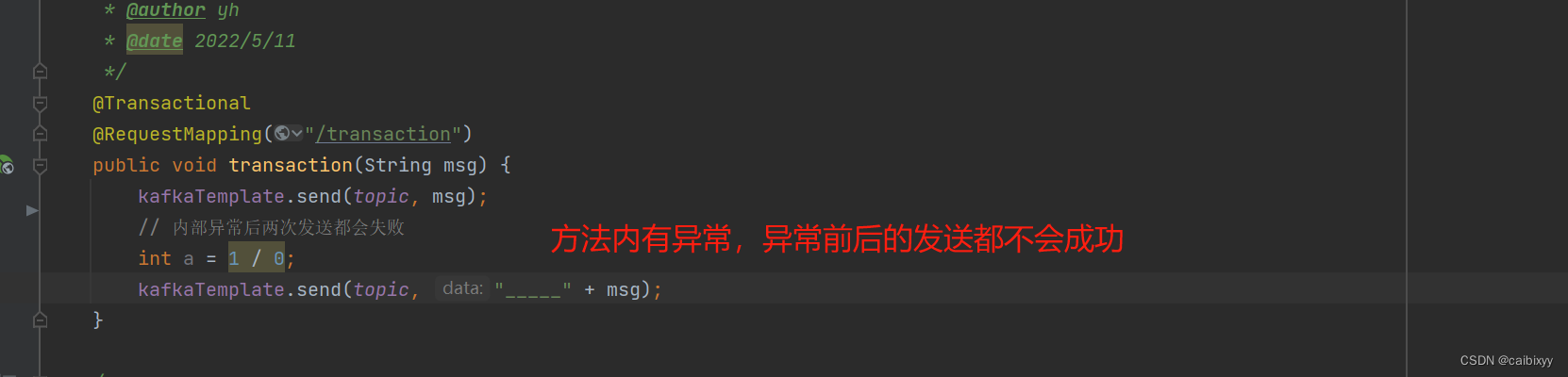
结果
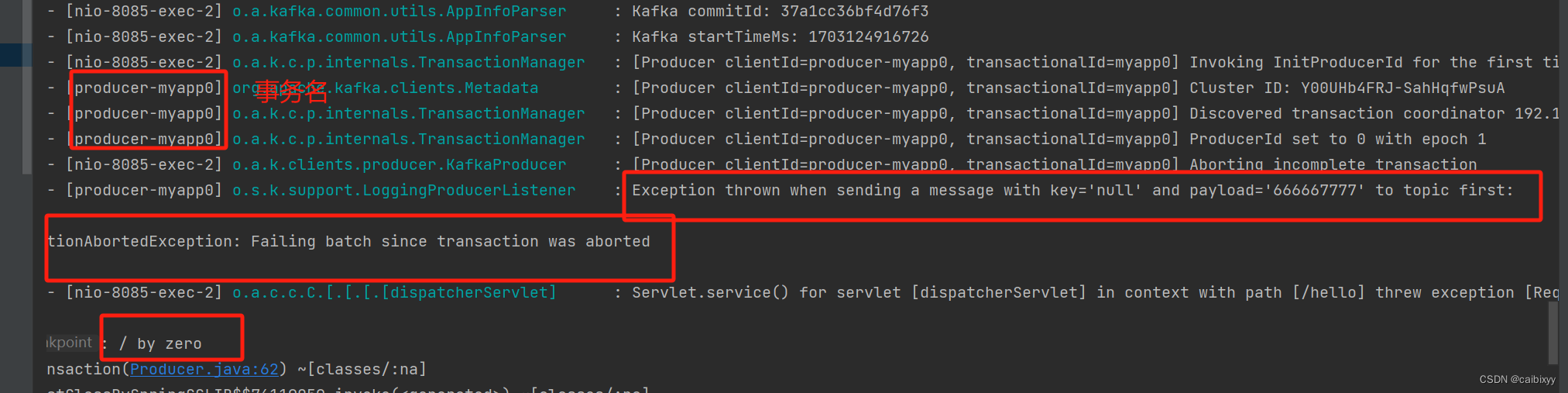
再试一下第二种事务发送
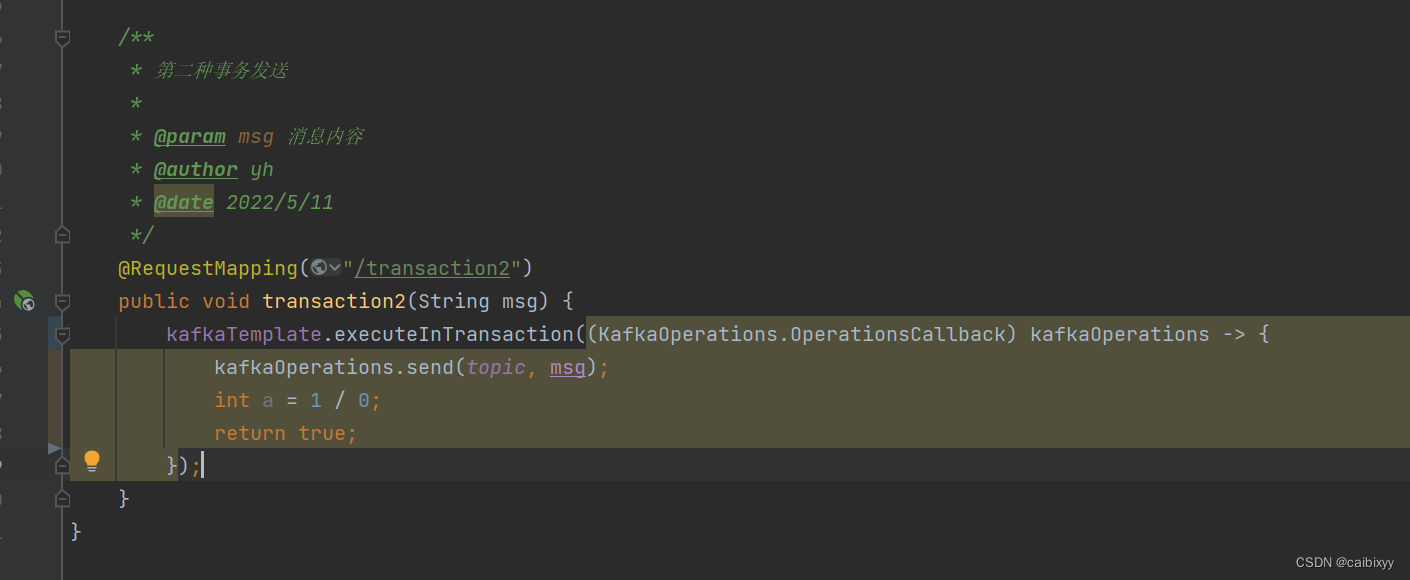
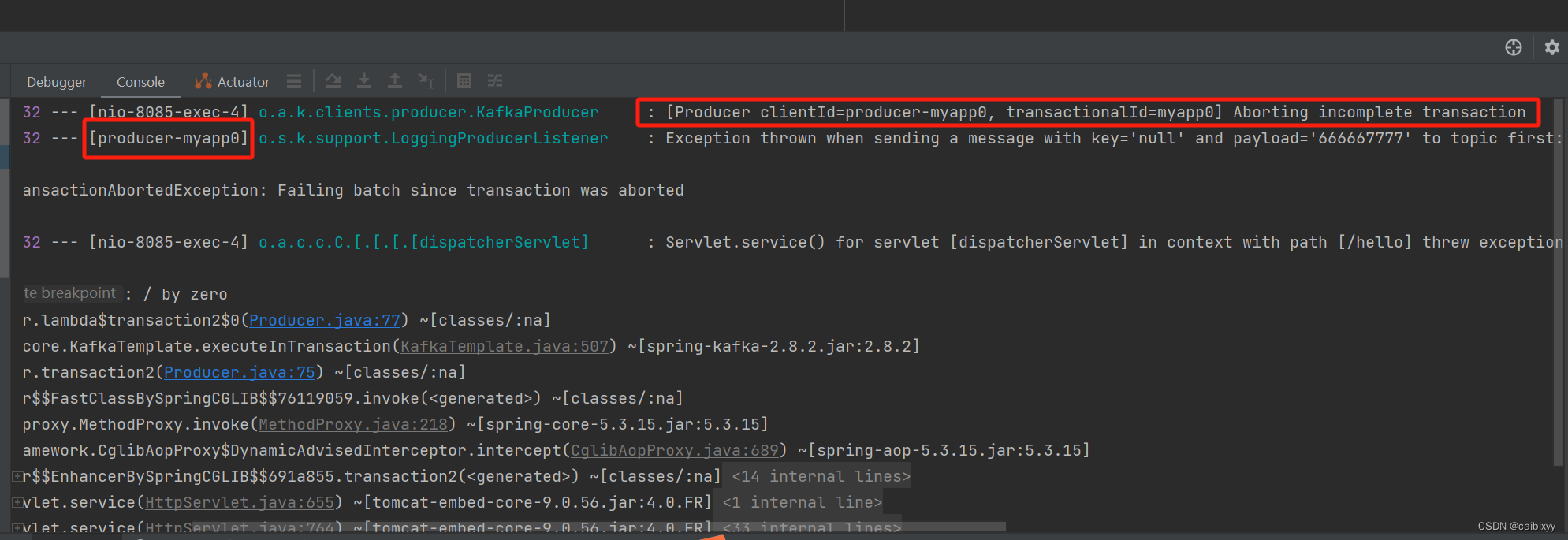
结果
自定义分区规则,CustomizePartitioner
我们把这个类的注释打开,同时配置文件里的,partitioner.class配置开启,把消费者组group-id改为mykafka2,再把事务的配置也注释掉
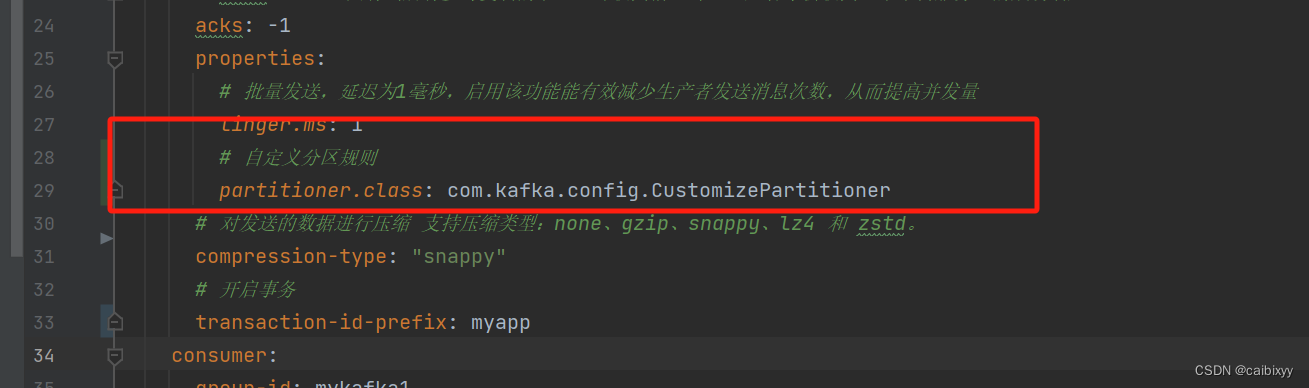
把上面的方法注释掉,把此方法的注释打开
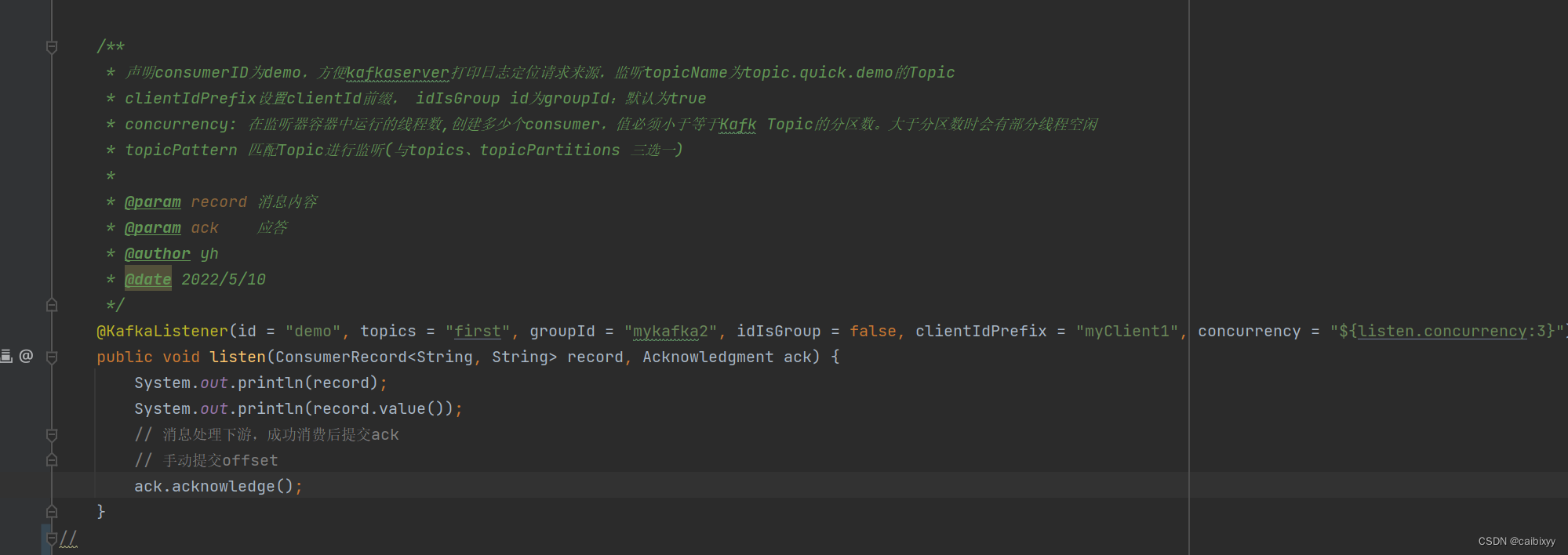
发送一个符合分区的消息内容

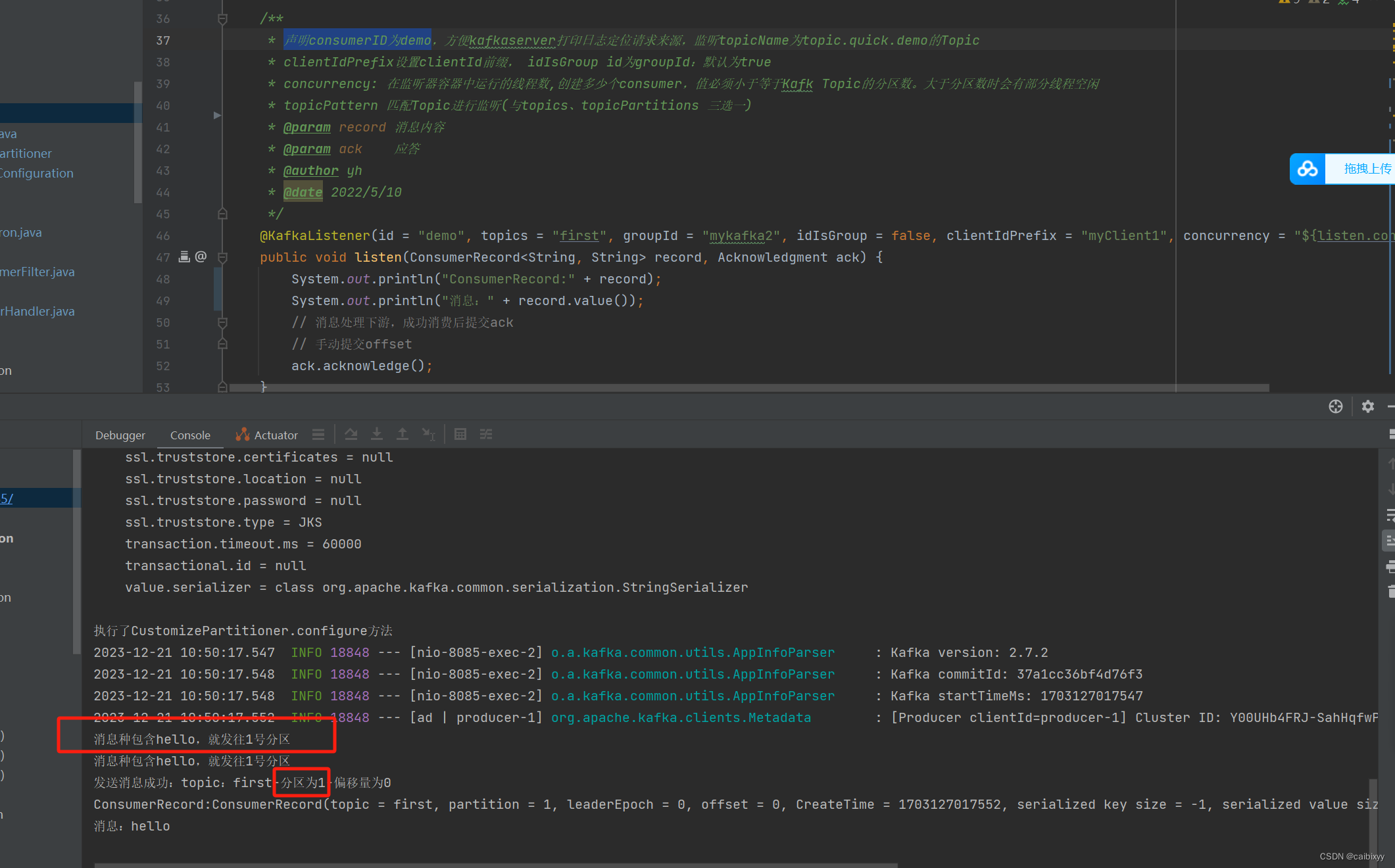
因为此时没有1号分区,消息会发送超时
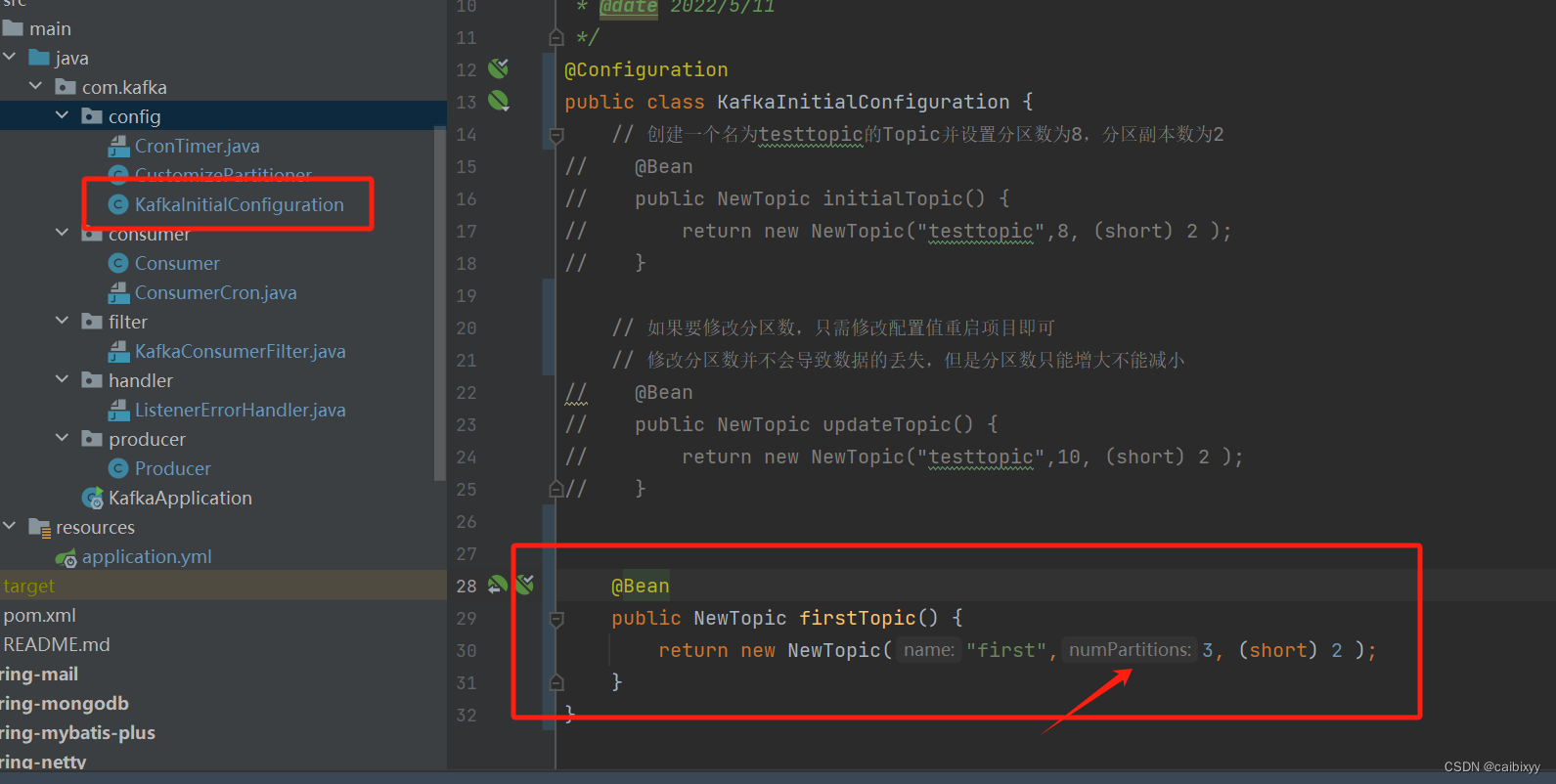
我们可以新建配置类,声明分区数
然后在发送消息试一下
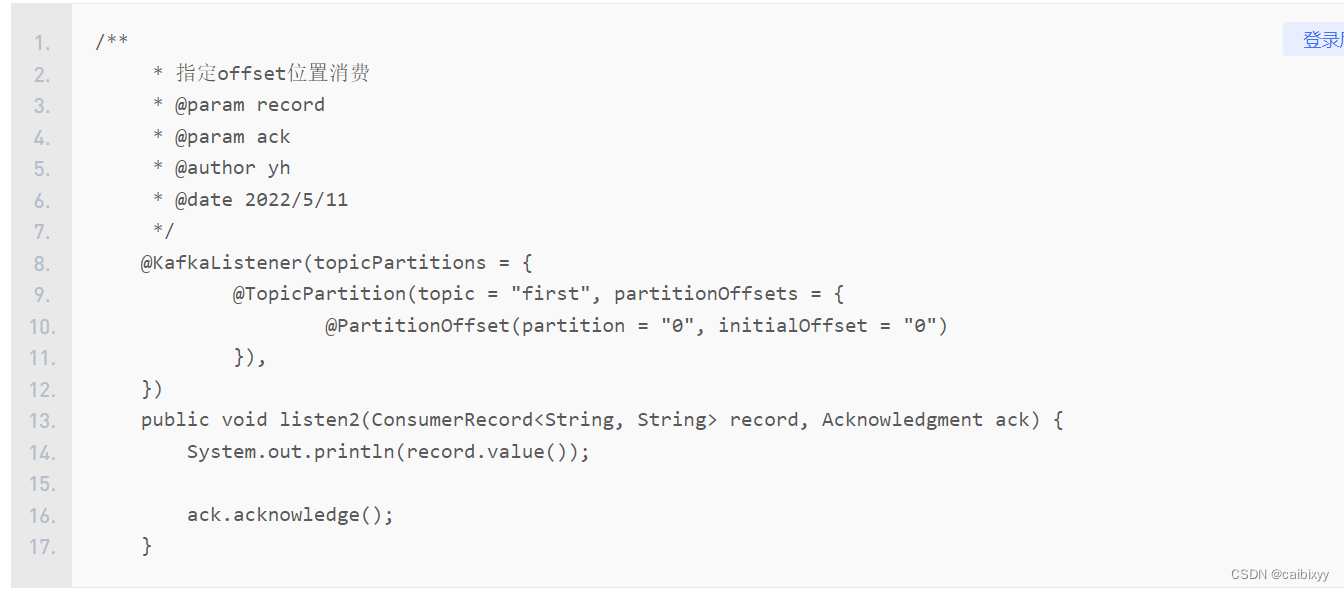
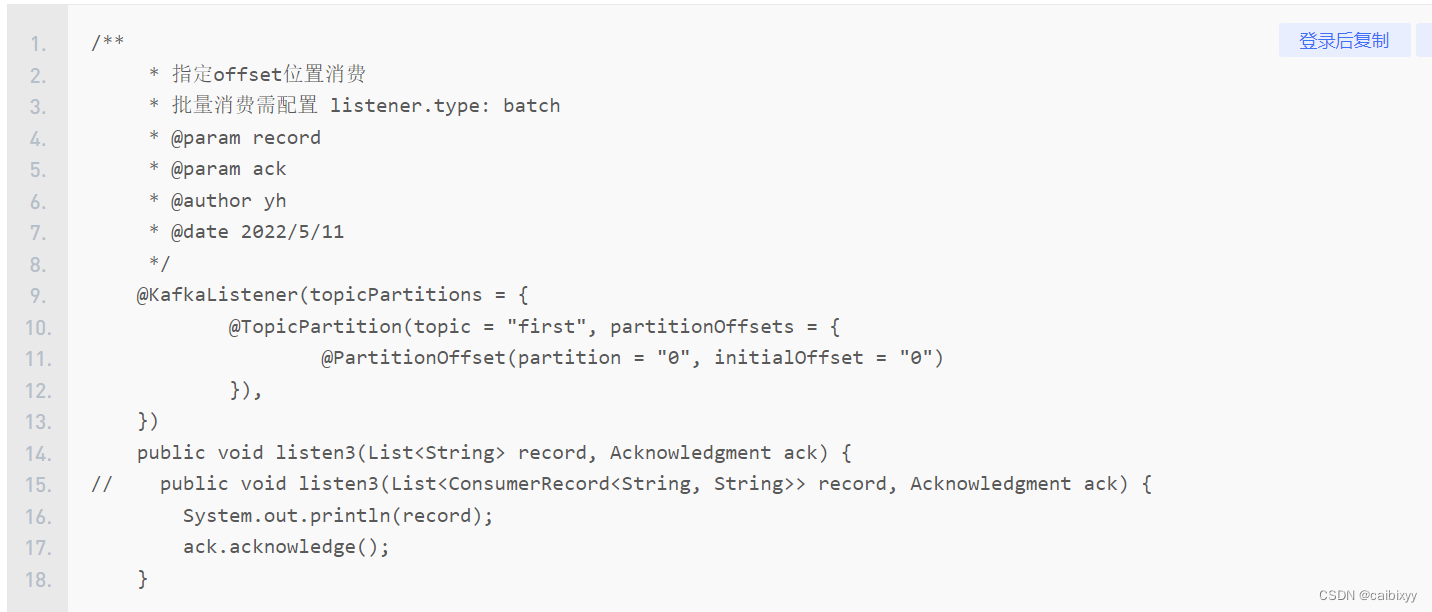
后续,刚才我们是手动ack,提交偏移量
我们也可以指定偏移量去消费,方法代码里都有的,这里就截图了
批量消费
过滤消息内容再进行消费,异常处理

消息转发

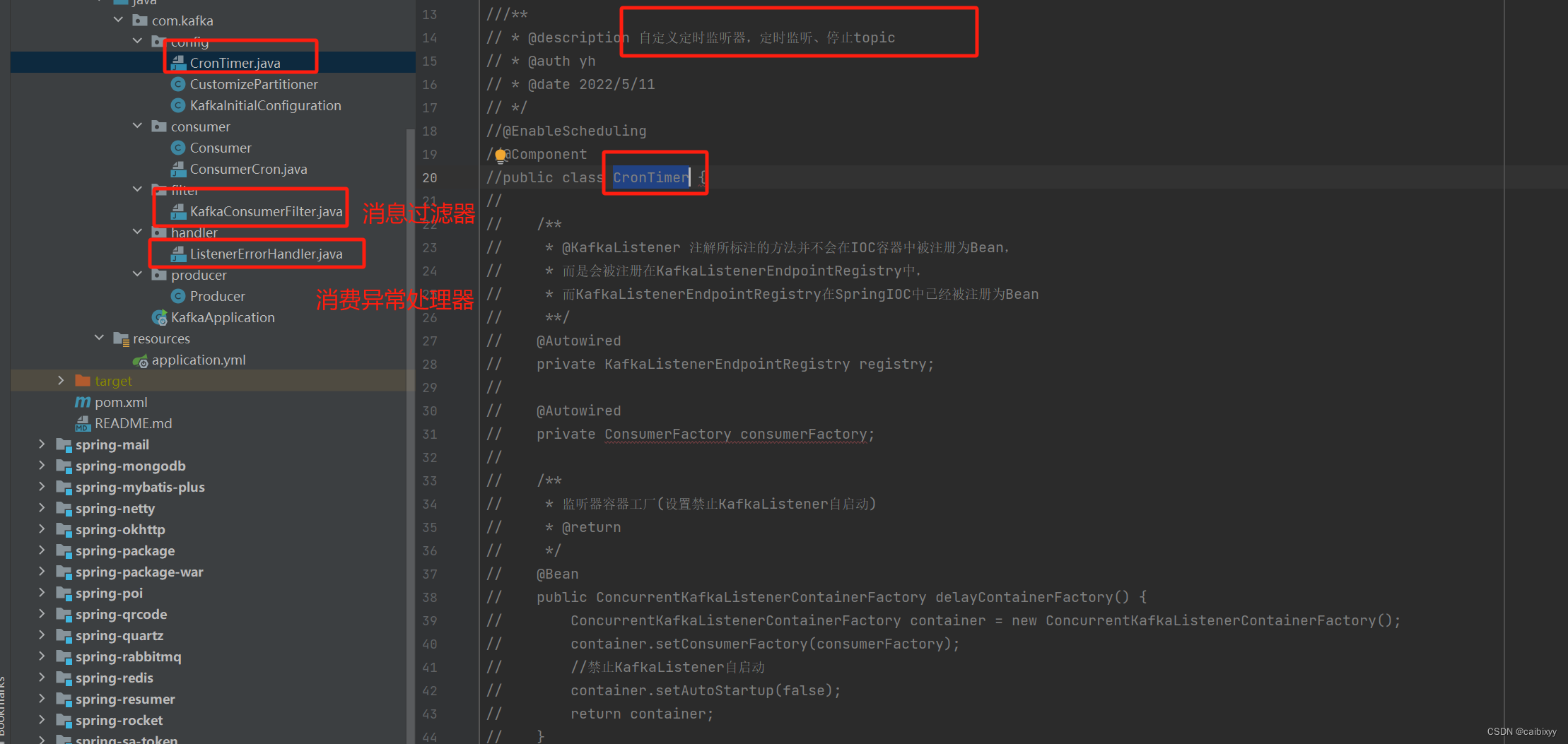
定时启动,停止监听器
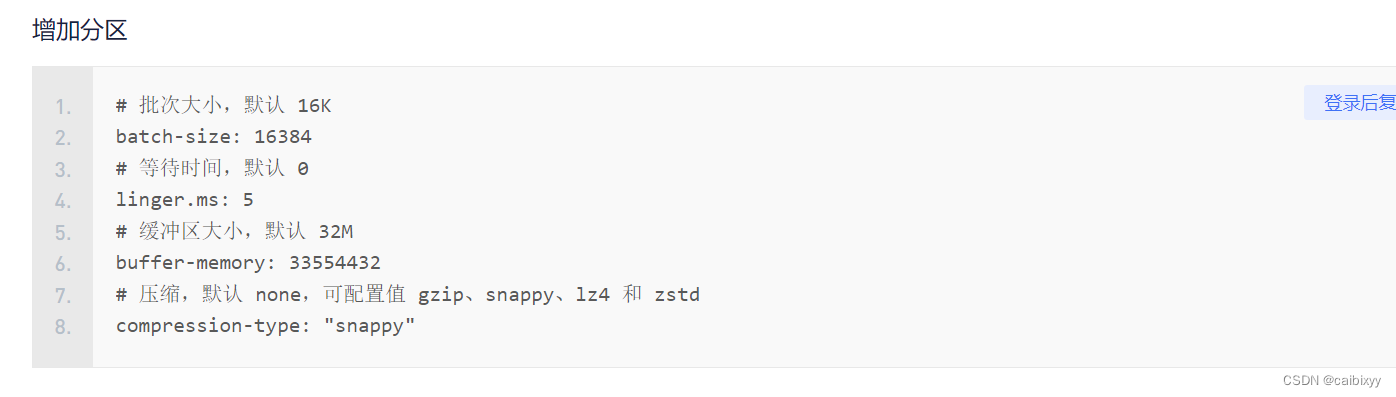
生产者如何提高吞吐量

参考博客:https://blog.51cto.com/u_14452299/6019881
思考,如果其他中间件或框架,想要自定义配置的话,那可能也会继承它的接口,重写方法,或者声明自己的配置类啥的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python+requests接口自动化测试框架实例详解
- vue computed和watch有什么区别
- 一篇文章讲透python双层独立循环(--附案例(python如何实现循环存放文件)
- FileZilla的使用以及主动模式跟被动模式
- 使用opencv的Laplacian算子实现图像边缘检测
- Scrapy 1.3.0 使用简介
- BSWM 模式管理(二)ESH
- 九州金榜|孩子不自信,根源在父母,莫让孩子失去自我
- MAC苹果笔记本电脑如何彻底清理垃圾文件软件?
- 低功耗智能雨量监测站现代化雨水情监测网络