MegatronLM源码阅读-数据预处理
数据处理入口:
python tools/preprocess_data.py \
--input content.jsonl \
--output-prefix wudaocorpus_01 \
--vocab ../starcoder/vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file ../starcoder/merges.txt \
--json-keys content \
--workers 10 \
--chunk-size 500 \
--append-eod--input:要处理的jsonl数据
--output-prefix:处理完成后生成的bin和idx文件的名称前缀
--vocab-file:分词表文件,列出了模型已知的所有单词和子词,一般也是“字典文件”,可以将字符或者字符串转为模型可以读取的索引号
--tokenizer-type:tokenzier类型,如果选择是GPT2BPETokenizer的话,则一定要有:--vacal-file和--merge-file两个参数,这里根据./megatron/tokenizer/tokenizer.py#40和#52行可知;GPTBPETokenizer所用算法为BPE(byte-pair encoding)字节对编码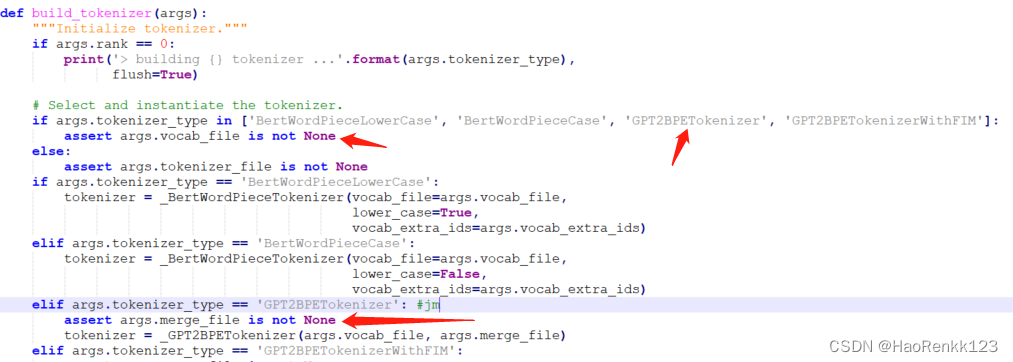
--merge-file:合并文件,指示如何合并字符和字词以形成更长字词的文件,每行都是一个合并操作,合并操作的大概步骤为:
举例处理英文字符串“lower”:
初始状态,将字符串分解为单个字符:'l','o','w','e','r'
假设merge-file中的内容为:
merges = [
('l', 'o'),
('o', 'w'),
('e', 'r')
]
使用第一个合并规则(l + o -> lo):'lo','w','e','r'
第二个合并规则(o + w)在此上下文中不适用,因此没有改变
使用第三个合并规则(e + r -> er):'lo','w','er'
最终的BPE分词结果为:'lo','w','er'
如果是处理中文字符串时,如果vocab.txt中不支持中文,那么可以将中文字符串先转为utf-8编码格式的字符串,然后按照上边的步骤进行合并--json-key:需要处理的jsonl中对应key-value
--workers:进程数
--chunk-size:每进程一次处理的文本数
--append-eod:是否在文本末尾添加 标记
进入preprocess_data.py
假设我们提供的jsonl为:
{"src": "www.nvidia.com", "content": "The quick brown fox", "type": "Eng", "id": "0", "title": "First Part"}
{"src": "The Internet", "content": "jumps over the lazy dog", "type": "Eng", "id": "42", "title": "Second Part"}
{"src": "The Internet", "content": "apple is 苹果。", "type": "Eng", "id": "42", "title": "Second Part"}
class Encoder(object):
def __init__(self, args):
self.args = args
def initializer(self):
# Use Encoder class as a container for global data
Encoder.tokenizer = build_tokenizer(self.args)#当前入口为这个:GPT2BPETokenizer
if self.args.split_sentences:
if not nltk_available:
print("NLTK is not available to split sentences.")
exit()
splitter = nltk.load("tokenizers/punkt/english.pickle")
if self.args.keep_newlines:
# this prevents punkt from eating newlines after sentences
Encoder.splitter = nltk.tokenize.punkt.PunktSentenceTokenizer(
train_text = splitter._params,
lang_vars = CustomLanguageVars())
else:
Encoder.splitter 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Cmake(2)——Cmake的基础应用
- python程序打包成exe全流程纪实(windows)
- 深度解析HubSpot数据分析:洞察未来商业趋势
- Java并发 - 线程基础
- 机器视觉系统选型-工业视觉图像质量的影响因素
- 官宣!OpenTiny 前端 Web 应用开发挑战赛开赛啦~30万奖金等你拿!
- CentOS7安装 Docker Compose
- STL:std::array 和 基本数组类型array 浅谈一二三
- 通用路由封装协议GRE原理与配置
- Python中魔术方法汇总