Flink|《Flink 官方文档 - 部署 - 概览》学习笔记
学习笔记如下:
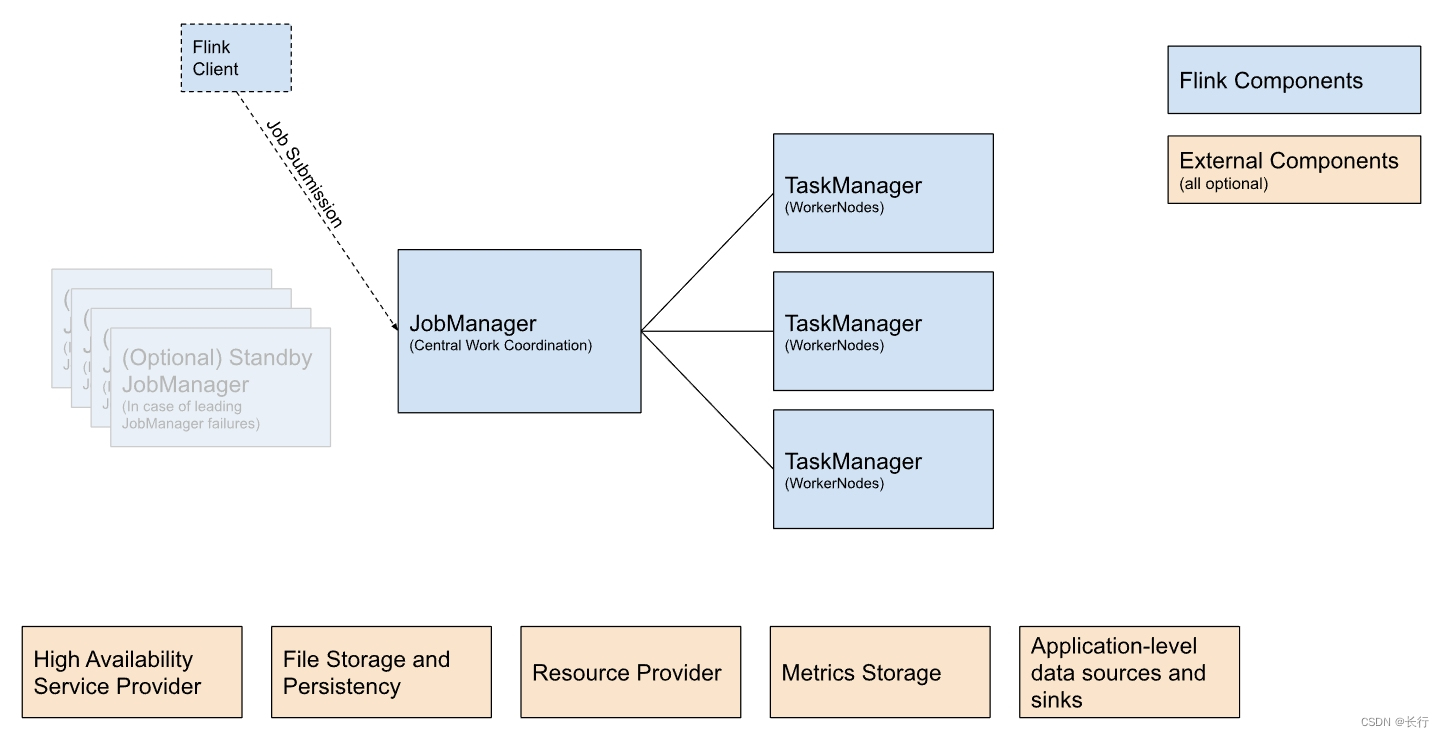
上图展示了 Flink 集群的各个构建(building blocks)。通常来说:
- 客户端获取 Flink 应用程序代码,将其转换为 JobGraph,并提交给 JobManager
- JobManager 将工作分配给 TaskManager,并在那里执行实际的算子操作
- 在部署 Flink 时,每个构建(building blocks)通常会有多种可用选项。
组成部分
- Flink 客户端(Flink Client):将批处理或流处理的应用程序编译为 dataflow graph,并将其提交给 JobManager。
- JobManager:JobManager 是 Flink 的核心工作协调组件,它实现了对不同 source、高可用程度、资源分配行为和作业提交模式的支持。
- TaskManager:TAskManager 是实际执行 Flink Job 的服务。
可选的外部组件:
- 高可用服务管理者:Flink 的 JobManager 可以在高可用模式下运行,这使得 Flink 可以从 JobManager 故障中恢复。为了更快地进行故障转移,可以启动多个备用 JobManagers 作为备份。
- 文件存储和持久性:Flink 的 checkpointing 依赖于外部文件存储系统。
- 资源管理者:Flink 可以部署在不同资源管理框架下,例如 Kubernetes 或 YARN。
- 指标存储:Flink 的组件会报告内部指标,同时 Flink Job 也可以报告额外的基于特定作业的指标。
- 应用层级的 source 和 sink:虽然应用级的 source 和 sink 在技术上不是 Flink 集群组件部署的一部分,但在规划新的 Flink 生产部署时应该考虑它们。将频繁使用的数据与 Flink 共置可以带来显著的性能优势。
可重复的资源清理
一旦作业到达了全局结束的状态(包括完成、失败和被取消),与作业关联的外部组件资源将被清理。在资源清理失败时,Flink 将会重试清理,重试策略可以配置。
当资源清理达到最大重试次数,但还没有成功时,其组件需要手动清理。重新启动相同作业(根据 job ID 判断)将导致资源清理重新开始,而不会再次运行作业。
部署模式
Flink 有以下三种应用执行模式:
- Application Mode
- a Per-Job Mode
- Session Mode
以上模式的差异包括:
- 集群生命周期以及资源隔离保障
- 应用程序的
main()方法在客户端执行还是在集群执行
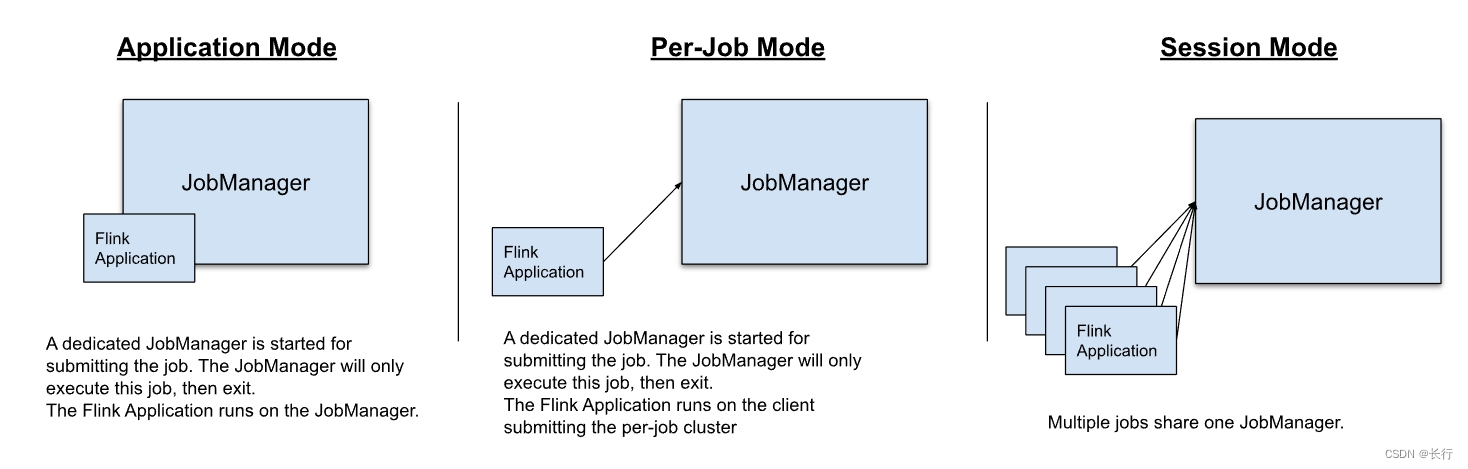
Application Mode
在其他所有模式下,应用程序的 main() 方法都是在客户端执行。这就要求在本地下载应用程序的依赖项,执行 main() 以提取 Flink 可以理解的应用程序标识形式(即 JobGraph),并将依赖项和 JobGraph 发送给集群。此时,客户端需要大量的网络带宽来下载依赖项并将二进制文件发送给集群,同时需要 CPU 来执行 main(),使得客户端成了资源的重度消耗者。当客户端在用户之间共享时,这个问题会更加明显。
出于这个考虑,Application Mode 为每个提交的应用创建一个集群,但是应用程序的 main() 方法由 JobManager 来执行。为每个应用程序创建一个集群,可以被视为在特定应用程序的作业之间创建了一个会话集群(session cluster),并在应用程序完成时拆除。通过这种架构,Application Mode 提供了与 Per-Job Mode 相同的资源隔离和负载均衡保证,但是是在整个应用程序的粒度上。在 JobManager 上执行 main() 方法,可以节省 CPU 资源,还可以节省本地下载依赖项所需的带宽。此外,因为每个应用程序都有一个 JobManager,所以还可以支持更均匀的分布式网络负载,以便在集群中下载应用程序的依赖项,
在应用程序模式下,main() 在集群上执行,而不是在其他模式下在客户端上执行。这将对代码逻辑产生影响,例如,在环境中使用 registerCachedFile() 注册的任何路径都必须能够被应用程序的 JobManager 访问。
相较于 Per-Job Mode,Application Mode 允许提交由多个 Job 组成的应用程序。作业执行的顺序不受部署模式的影响,但受到作业启动的调用的影响。使用阻塞的 execute() 方法,这将导致下一个任务直到当前任务完成后才会执行;使用非阻塞的 executeAsync(),将导致下一个任务在当前任务完成前就会开始。
Application Mode 允许应用程序中包含多个 execute(),但是在这种情况下不支持高可用。Application Mode 的高可用性仅支持包含单个 execute() 的应用程序。
此外,当 Application Mode 下运行的多个 Job 中的任何一个被取消,则会导致所有 Job 都被停止并且 JobManager 将会关闭。支持通过关闭数据源完成 Job。
Per-Job Mode
为了提供更好的资源隔离保证,Per-Job Mode 使用资源提供者框架(例如 YARN、Kubernetes)为每个提交的作业启动一个集群。该集群仅用于该作业。当作业完成时,这个集群会被拆除,任何残留的资源(例如文件等)都将被清除。这提供了更好的资源隔离,因为一个行为错误(misbehaving)的 Job 只能导致自己的 TaskManagers 被关闭。
此外,它通过让每个 Job 都有一个 JobManager,分散了 book-keeping 的压力。
Session Mode
Session Mode 假设已经有一个集群正在运行,并使用该集群的资源来执行任何提交的应用程序。所有的应用程序都在同一个集群上运行,并因此竞争相同的资源。
优势:不需要为每个提交的作业支付启动完整集群的资源开销
劣势:
- 其中一个 Job 的不正确行为(misbehave)都将导致 TaskManager 崩溃,进而导致所有在 TaskManager 上运行的程序都会受到影响
- 可能会出现潜在的大规模恢复过程,所有重新启动的 Job 将同时访问文件系统,导致其无法用于其他服务
- 让单个集群运行多个任务,将会导致单个 JobManager 处理了所有 Job 的 book-keeping,导致 JobManager 负载较大
Summary
在 Session Mode 中,集群的生命周期独立于集群上的任何作业,资源在所有作业之间共享。
在 Per-Job Mode 中,需要为每个 Job 支付启动集群的资源,但是有更好的资源隔离,因为资源不会在作业之间共享。在这种情况下,集群的生命周期和 Job 的生命周期绑定在一起。
在 Application Mode 中,会为每个应用程序创建一个 Session Cluster 并在集群上执行应用程序的 main() 方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!