【ICCV 2022】(MAE)Masked Autoencoders Are Scalable Vision Learners
何凯明一作文章:https://arxiv.org/abs/2111.06377
感觉本文是一种新型的自监督学习方式 ,从而增强表征能力
本文的出发点:是BERT的掩码自编码机制:移除一部分数据并对移除的内容进行学习。mask自编码源于CV但盛于NLP,恺明对此提出了疑问:是什么导致了掩码自编码在视觉与语言之间的差异?尝试从不同角度进行解释并由此引申出了本文的MAE。
恺明提出一种用于计算机视觉的可扩展自监督学习方案Masked AutoEncoders(MAE)。所提MAE极为简单:对输入图像的随机块进行mask并对遗失像素进行重建。它基于以下两个核心设计:
- 我们设计了一种非对称编解码架构,其中解码器仅作用于可见块(无需mask信息),而解码器则通过隐表达与mask信息进行原始图像重建;
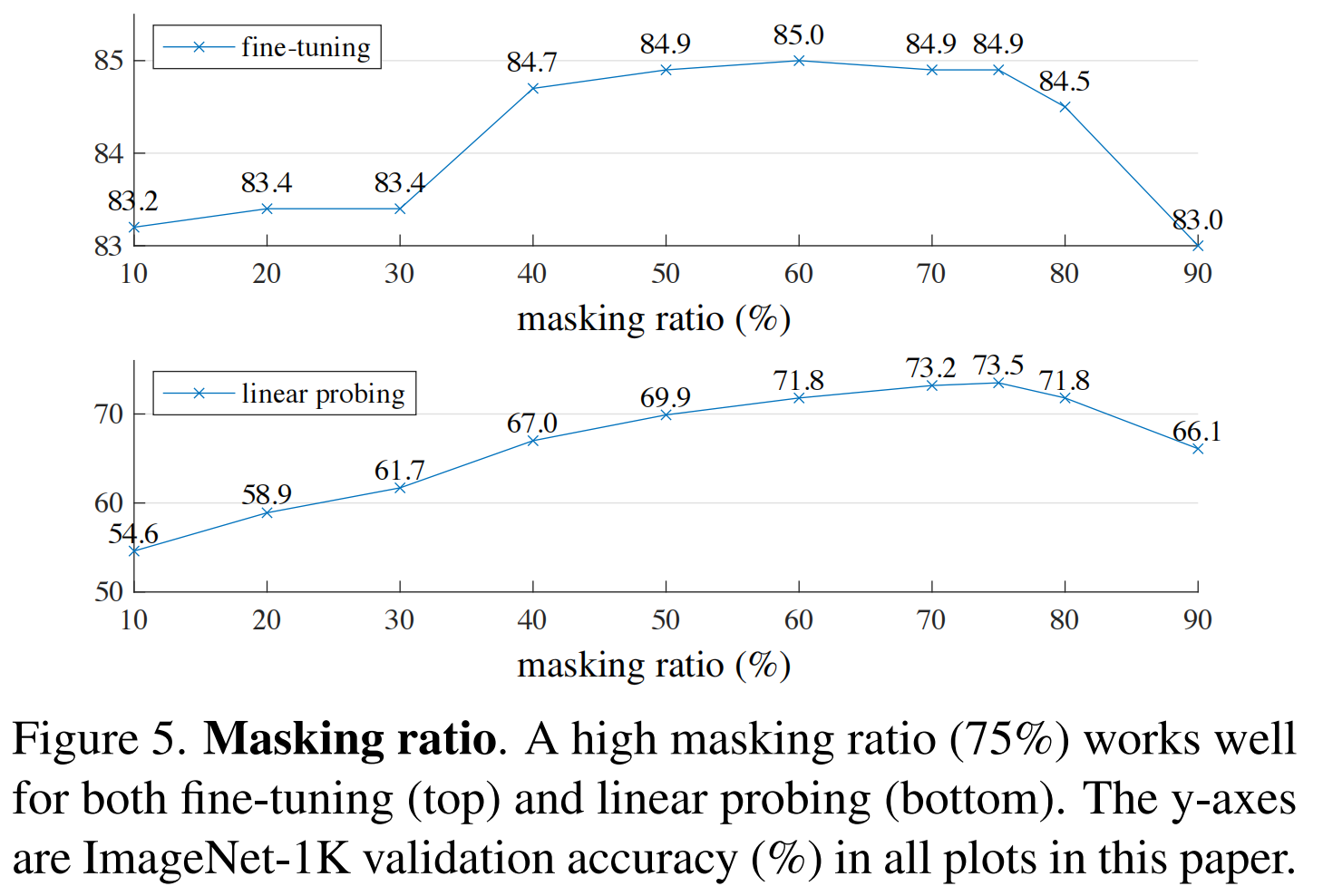
- 我们发现对输入图像进行高比例mask(比如75%被mask掉,不同于 NLP,在 CV 中可能要配合较高的 mask 比例才能作为“有效”的自监督代理任务。“有效”指的是任务本身足够困难,这样模型才能学到有效的潜在特征表示。)可以产生一项重要且有意义的自监督任务。
上述两种设计促使我们可以更高效的训练大模型:我们加速训练达3x甚至更多,同时提升模型精度。所提方案使得所得高精度模型具有很好的泛化性能:仅需ImageNet-1K,ViT-Huge取得了87.8%的top1精度?。下游任务的迁移取得了优于监督训练的性能,证实了所提方案的可扩展能力。
整体架构:

图 1:我们的 MAE 架构。
1、在预训练期间,图像patches 的大量随机子集(例如 75%)被mask。
2、Encoder应用于可见patches的小子集。
3、将encoder后的所有patches 和masked tokens由小型decoder处理,该解码器以像素为单位重建原始图像。
4、预训练后,decoder被丢弃,encoder应用于未损坏的图像(完整的patches)以进行识别任务。
方法:
我们的MAE是一种简单的自动编码方法,可以在给定部分观察的情况下重建原始信号。与所有AE一样,我们的方法具有将观察到的信号映射到?latent representation?的encoder,以及从?latent representation 重建原始信号的decoder。与经典AE不同,我们采用非对称设计,允许编码器仅对部分观察到的信号(没有掩码标记)进行操作,并采用轻量级解码器,从?latent representation?和?mask tokens?中重建完整信号。图 1 说明了接下来介绍的想法。
Masking
我们的采样策略非常简单:服从均匀分布的无重复随机采样?。我们将该采样策略称之为“随机采样”。具有高掩码比例的随机采样可以极大程度消除冗余,进而构建一个不会轻易的被近邻块推理解决的任务。而均匀分布则避免了潜在的中心偏置问题。【提升自监督学习任务的难度】
MAE Encoder
编码器用于生成用于:encoder image + 识别的完整图像的representations?
MAE中的编码器是一种ViT,但仅作用于未被Mask的块。类似于标准ViT,该编码器通过线性投影于位置嵌入对块进行编码,然后通过一系列Transformer模块进行处理。然而,由于该编解码仅在未mask的patches(比如25%)进行处理。这就使得我们可以用很小的计算资源训练一个非常大的编码器?。
MAE Decoder:
?MAE解码器的输入包含:(1) encoded visible patches;(2) mask?token。如Figure1所示,每个mask token共享的可学习向量,它用于指示待预测mask块。我们还会对所有token添加位置嵌入信息。解码器同样包含一系列Transformer模块。
MAE decoder 仅在预训练期间用于执行图像重建任务。因此,可以以独立于编码器设计的方式灵活地设计解码器架构。我们用非常小的解码器进行实验,比encoder更窄、更浅。例如,我们的默认decoder 与encoder 相比,每个token?的计算量?<?10%。通过这种非对称设计,全套 token?仅由轻量级解码器处理,这显着减少了预训练时间。
Reconstruction target
基本:我们的 MAE 通过预测每个mask patch的像素值来重建输入。解码器输出中的每个元素是vector of pixel values representing a patch。解码器的最后一层是线性投影,其输出通道的数量等于patch?中像素值的数量。decoder的输出从a reconstructed image被reshaped。我们的损失函数计算像素空间中重建图像和原始图像之间的均方误差(MSE)。我们仅在mask patches上计算损失,类似于 BERT [14](计算所有像素的损失会导致精度略有下降)。
变体:我们还研究了一种变体,其重建目标是每个masked patch的归一化像素值。具体来说,我们计算补丁中所有像素的平均值和标准差,并使用它们来标准化该?patch。使用归一化像素作为重建目标可以提高我们实验中的表示质量。
Simple implementation
Simple implementation?MAE预训练极为高效,更重要的是:它不需要任何特定的稀疏操作。实现过程可描述如下:
- 首先,我们通过线性投影与位置嵌入(by linear projection with an added positional embedding)?对每个输入 patch 生成token;【对图像的所有patch --> token】
- 然后,我们 random shuffle token 并根据掩码比例(masking ratio)移除最后一部分token;【根据mask比例,将shuffle后的所有token的最后一些元素删除(其实这一步就是服从均匀分布的无重复随机采样mask)】
- 将所有的未被mask的patch完成encoding后(得到encoded patches),将encoded patches后加入所有mask tokens ==> full list。
- 对full list 进行?unshuffle(inverting the random shuffle operation),从而将all tokens与它们的target进行对齐;
- 最后,我们将解码器作用于上述full list(添加了位置编码的)?。
注意:MAE无需稀疏操作。此外,shuffle与unshuffle操作非常快,引入的计算量可以忽略。
实验
不同的mask ratio对实验产生的影响
何恺明最新一作:简单实用的自监督学习方案MAE,ImageNet-1K 87.8%! - 知乎
文献阅读:MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【无标题】【一周安全资讯1223】一图读懂《工业和信息化部办公厅关于组织开展网络安全保险服务试点工作的通知》;15亿条纽约房产记录泄露
- 2024.1.10力扣每日一题——删除子串后的字符串最小长度
- DrGraph原理示教 - OpenCV 4 功能 - 二值化
- 有线桥接|Wifi隔了一堵墙就没信号?房间的网线口利用起来,让房间死角也有网!
- 人工智能(AI)技术应用:解锁未来的无限可能
- 网页首页案例(使用框架:继上一篇博客结尾)
- Leetcode—47.全排列II【中等】
- Cookie中的Expiry标示是什么
- 《BackTrader量化交易图解》第10章:Trade 交易操作
- Unity C#中LuaTable、LuaArrayTable、LuaDictTable中数据的增删改查