目标检测-Two Stage-Mask RCNN
前言
前文目标检测-Two Stage-Faster RCNN提到了Faster RCNN主要缺点是:
- ROI Pooling有两次量化操作,会引入误差影响精度
Mask RCNN针对这一缺点做了改进,此外Mask RCNN还添加了全卷积网络的分支,拓展了网络的应用范围,使其可用于多种视觉任务:包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等
提示:以下是本篇文章正文内容,下面内容可供参考
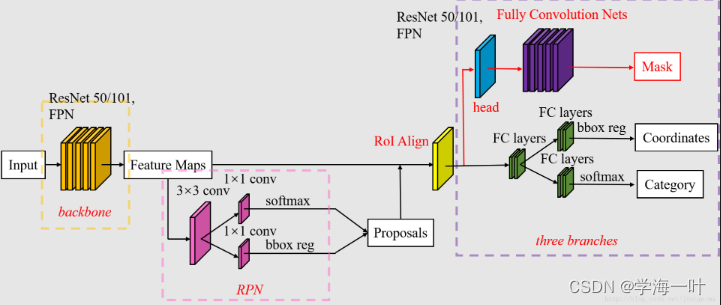
一、Mask RCNN的网络结构和流程
- 利用骨干网架构(Backbone Architecture)提取多尺度特征,获得多尺度共享卷积特征图(Feature Maps)
Backbone Architecture由Backbone(ResNet50)和特征金字塔网络FPN(Feature Pyramid Network)组成
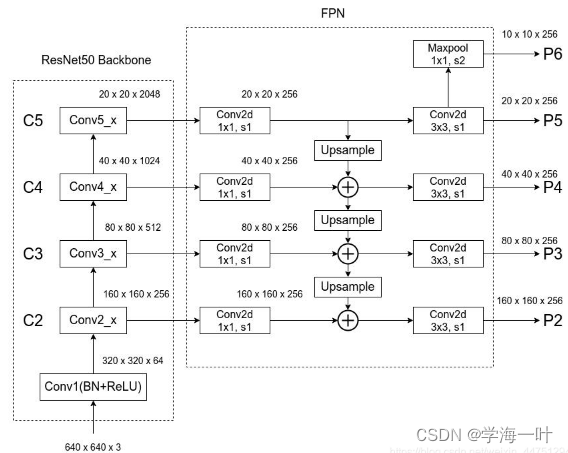
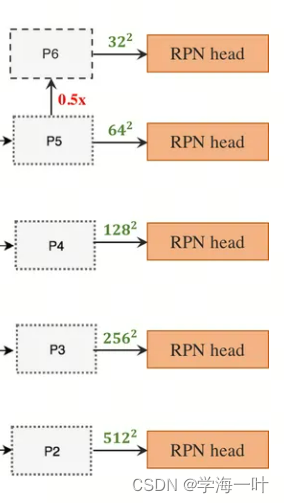
- 利用RPN(Region Proposal Network)网络生成候选框,进行分类和第一次边框修正
ps:输入的是多个尺度特征图,每个特征图对应一个RPN,因为输入是多尺度特征,就不需要再对每层都使用3种不同尺度的anchor了,所以只为每层设定一种尺寸的anchor
在P2-P6的五个特征图上分别对应设置5个不同的anchor size(32, 64, 128, 256, 512)并设置3种长宽比(0.5, 1.0, 2.0),也就是每个特征图的每个像素点生成3个anchor(x, y, w, h)
例如,输入图像为512 × 512,那么五个特征图的尺寸分别为128, 64, 32, 16, 8,那么生成的anchors的数量为(128 × 128 + 64 × 64 + 32 × 32 + 16 × 16 + 8 × 8) × 3 = 21824 × 3 = 65472
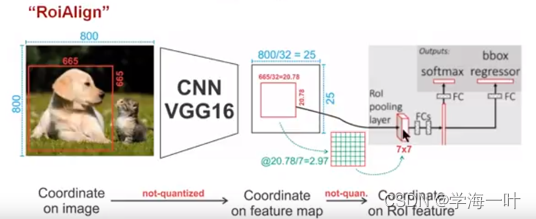
- 将生成的Region Proposal和多尺度共享卷积特征图(Feature Maps)输入RoI Align,获取每个候选框的多尺度池化特征图
ps:ROI Align是RoI Pooling的改进
ROI Align并没有采用量化操作,而是使用线性插值算法计算特征图,因为没有用到量化操作,就没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。
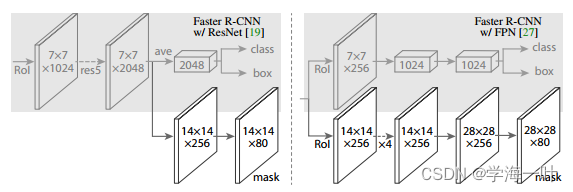
- 将候选框的池化特征图输入Head Architecture结构进行分类、第二次边框修正以及生成掩膜(mask)
ps:当使用FPN时,Head Architecture为左边结构,反之为右边结构,实际使用中右边结构更加常用

二、Mask RCNN的创新点
- 结合FCN增加了Mask Prediction Branch,使得到的网络可用于多种视觉任务,向通用视觉模型迈出了一步
- 提出了RoI Pooling的改良方法RoI Align,提高了精度
- 通过引入特征金字塔网络(Feature Pyramid Network,简称FPN)来处理不同尺度的目标,有助于改进目标检测的性能,尤其是小尺寸对象目标检测。
总结
- 整个Mask R-CNN算法非常的灵活,可以用来完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等多个任务
- 除此之外,我们可以更换不同的Backbone Architecture和Head Architecture来获得不同性能的结果。
- 但是,Mask RCNN仍未脱离Two Stage算法速度慢的限制,难以用于实时场景,因此,出现了目标检测新的流派:One Stage算法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!