学习笔记——克里金插值
有一篇大神的文章写得非常的具体,
https://xg1990.com/blog/archives/222
下面写下一些学习笔记:
1、关于克里金插值的基本原理
克里金插值来源于地理学,它的前提是地理学第一定律:所有事物都与其他事务相关,但是近处的事物比远处的事物更相关。这里就引出克里金插值的
第一个核心思想:在一定范围内,两点属性值的差异性(不相关性)与二者间距离在一定距离范围内成正相关;两点属性值相关性与二者之间距离正相关。
可以举一个简单的例子,苏州和上海的气温差异要小于苏州和北京的差异;但是也有距离限制,比如苏州和伦敦的差异就不一定比苏州和北京的差距大;
这里有一个关键结论:一点的属性值可以由其周围点的属性值推导出;
2、克里金插值的数学形式
做一些基础的假设,已知点坐标及属性值,已知待求点的坐标,已知点间距离矩阵,已知点-待求点之间的距离矩阵。根据克里金插值的第一核心思想,可以得到空间内某未知点(x0,y0)估计值Z0是部分已知点值的加权和。可被表示为:

其中n代表点的数量,zi代表第 i 个已知点的属性值, wi 代表第 i 个已知点的权重;Zi 都是已知点,但是 wi 目前还不是一个已知量。具体需要一个什么样的 wi 才能求得准确的 Z0 呢?为了得到更加准确的估测结果,权重系数 wi 应使得点(x0,y0)处估计值与真实值之差最小,?我们需要做如下期望:
2.1 估计值 Z0 与真实值 Z0 之间方差尽可能小
估计值 Z0 与真实值 Z0 之间的差值为:(期望为0)
![]()
估计值 Z0 与真实值 Z0 之间方差最小:
![]()
即该假设使得结果尽可能准确;
?2.2 空间偏差的方差不变
为了维持空间是平稳的,空间任意一点处的值 z = z(x,y)由区域平均值 c 和随机偏差 R(x,y) 组成,其中偏差的方差均为常数。

写成期望的形式:

这个假设就保证了可以通过已知点值估算未知点值(空间平稳、具备一定的趋势)。对于 z(x0,y0),估计值 Z0'、真实值 Z0、使用n个已知属性值的领域点求其值,每个点有一直的属性值zi,权重 wi ;经过文章所示的推导过程克里金推导,然后稍加求逆,可以得到权重系数的表达矩阵:

2.3 半方差的矩阵
对 Zi = Z(xi,yj),Zj = Z(xi,yj),其半方差函数可被表示为:

这个是非常关键的一个点。他表示了第 i , j 个领域点之间的半方差,第0个领域点表示待求点本身。Z1....Zn已知,y11 和 ynn 可计算得到。但真实值 Z0是未知的,y10,yn0是未知的。如何求y10...yn0是需要解决的问题;
2.4 解算的思路:建立拟合函数
从上面的分析可知,我们已知每个点之间的距离,有了每个点之间距离组成的n*n的矩阵,并且还已知维持空间稳定的半方差矩阵,是不是可以理解为我既知道了已知点和未知点之间的相对距离,还知道了一部分这个空间不同点之间的一个约束关系,那么是否拟合出一个非常接近真实情况的函数形式,来表达不同点在不同距离的变化趋势呢?
建立一个拟合函数:
![]()
该拟合函数的 d 即为待求点的位置,假如将其代入到上面的权重系数矩阵可得;

如果这个拟合函数已知,那么 w1- wn 就可以被求得。最后通过方程即可完成 z0 的估计。
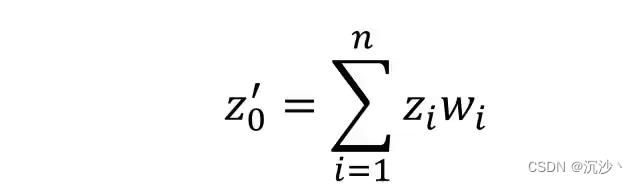
2.5 为什么可以通过函数拟合?
在进行拟合函数构建之前,需要讨论的是为什么可以通过函数拟合?这个时候回到地理学第一定律:在一定范围内,两点差异随着两点间距离增大而增大,并且空间是稳定的,也就是说他必然是存在趋势的,因此这个拟合是可以接受的。在已经有了半方差 矩阵之后,我们可以通过这种潜在的约束和已知点的集合,去对真实的空间变化趋势进行拟合。
2.6 如何构建拟合函数呢?
根据克里金差值的原理,两点差异随着两点间距离增大而增大,因此这个函数一定是一个增函数。然后这个差异的变化趋势是在一定范围内满足的,因此这个函数一定存在某个极值或者边界。这个函数自变量增大到一定的值后,因变量不再增大。已有的模型可以用来借鉴,主其中球型模型、指数模型、高斯模型都比较符合。

为了得到更加精确的结果,采用先分组再拟合的方式,已知n*n组距离-半方差关系,
![]()
按照距离d大小排序这n*n组关系,再分组得到m个距离-半方差关系组g1、g2...gm。计算每组平均距离和平均半方差:
![]()
根据每组的平均距离和平均半方差,构建拟合函数。
如果我们整体回顾一下整个克里金差值模型的思路,为了完成 Z0真实值的估计,我们进行了如下步骤:
第一步:建立期望——差值最小、方差最小,得到估计值表达式;要得到估计值就必须要求得权重系数矩阵;
第二步:建立权重系数表达矩阵——依据优化目标构建权重系数表达矩阵。y11-ynn均已知。要求解权重系数矩阵必须先求解y10...yn0矩阵。
第三步:求解y10...yn0矩阵——构建拟合函数 y = f(d),要构建拟合函数必须进行模型选择及数据处理;
第四步:选择模型、数据分组,分段函数拟合;
所以最关键的就是这些数据的处理、模型的选择、函数的拟合,下面就针对这个进行学习。
3 函数的拟合
首先有这个么数据,其二维平面的分布如下图所示:

第一步:求取距离与半方差;求每个点之间的距离和半方差,半方差和距离都是75*75的矩阵,最后将其变为一个二维的矩阵,即代码?d_r=[d_r;[dij(i,j),rij(i,j)]];? 其中dij是距离,rij是半方差。
S=[0.700000000000000,59.6000000000000;2.10000000000000,82.7000000000000;4.70000000000000,75.1000000000000;4.80000000000000,52.8000000000000;5.90000000000000,67.1000000000000;6,35.7000000000000;6.40000000000000,33.7000000000000;7,46.7000000000000;8.20000000000000,40.1000000000000;13.3000000000000,0.600000000000000;13.3000000000000,68.2000000000000;13.4000000000000,31.3000000000000;17.8000000000000,6.90000000000000;20.1000000000000,66.3000000000000;22.7000000000000,87.6000000000000;23,93.9000000000000;24.3000000000000,73;24.8000000000000,15.1000000000000;24.8000000000000,26.3000000000000;26.4000000000000,58;26.9000000000000,65;27.7000000000000,83.3000000000000;27.9000000000000,90.8000000000000;29.1000000000000,47.9000000000000;29.5000000000000,89.4000000000000;30.1000000000000,6.10000000000000;30.8000000000000,12.1000000000000;32.7000000000000,40.2000000000000;34.8000000000000,8.10000000000000;35.3000000000000,32;37,70.3000000000000;38.2000000000000,77.9000000000000;38.9000000000000,23.3000000000000;39.4000000000000,82.5000000000000;43,4.70000000000000;43.7000000000000,7.60000000000000;46.4000000000000,84.1000000000000;46.7000000000000,10.6000000000000;49.9000000000000,22.1000000000000;51,88.8000000000000;52.8000000000000,68.9000000000000;52.9000000000000,32.7000000000000;55.5000000000000,92.9000000000000;56,1.60000000000000;60.6000000000000,75.2000000000000;62.1000000000000,26.6000000000000;63,12.7000000000000;69,75.6000000000000;70.5000000000000,83.7000000000000;70.9000000000000,11;71.5000000000000,29.5000000000000;78.1000000000000,45.5000000000000;78.2000000000000,9.10000000000000;78.4000000000000,20;80.5000000000000,55.9000000000000;81.1000000000000,51;83.8000000000000,7.90000000000000;84.5000000000000,11;85.2000000000000,67.3000000000000;85.5000000000000,73;86.7000000000000,70.4000000000000;87.2000000000000,55.7000000000000;88.1000000000000,0;88.4000000000000,12.1000000000000;88.4000000000000,99.6000000000000;88.8000000000000,82.9000000000000;88.9000000000000,6.20000000000000;90.6000000000000,7;90.7000000000000,49.6000000000000;91.5000000000000,55.4000000000000;92.9000000000000,46.8000000000000;93.4000000000000,70.9000000000000;94.8000000000000,71.5000000000000;96.2000000000000,84.3000000000000;98.2000000000000,58.2000000000000];
Y=[34.1000000000000;42.2000000000000;39.5000000000000;34.3000000000000;37;35.9000000000000;36.4000000000000;34.6000000000000;35.4000000000000;44.7000000000000;37.8000000000000;37.8000000000000;43.9000000000000;37.7000000000000;42.8000000000000;43.6000000000000;39.3000000000000;42.3000000000000;39.7000000000000;36.9000000000000;37.8000000000000;41.8000000000000;43.3000000000000;36.7000000000000;43;43.6000000000000;42.8000000000000;37.5000000000000;43.3000000000000;38.8000000000000;39.2000000000000;40.7000000000000;40.5000000000000;41.4000000000000;43.3000000000000;43.1000000000000;41.5000000000000;42.6000000000000;40.7000000000000;42;39.3000000000000;39.2000000000000;42.2000000000000;42.7000000000000;40.1000000000000;40.1000000000000;41.8000000000000;40.1000000000000;40.9000000000000;41.7000000000000;40.8000000000000;38.7000000000000;41.7000000000000;40.8000000000000;38.7000000000000;38.6000000000000;41.6000000000000;41.5000000000000;39.4000000000000;39.8000000000000;39.6000000000000;38.8000000000000;41.6000000000000;41.3000000000000;41.2000000000000;40.5000000000000;41.5000000000000;41.5000000000000;38.9000000000000;39;39.1000000000000;39.7000000000000;39.7000000000000;40.3000000000000;39.5000000000000];
n=size(S,1);
rij=zeros(n,n);
dij=zeros(n,n);
d_r=[];
for i=1:n
for j=1:n
rij(i,j)=0.5*(Y(i,1)-Y(j,1)).^2; % 半方差
dij(i,j)=sqrt(sum((S(i,:)-S(j,:)).^2));%欧式距离 绝对距离
% dij(i,j)=sum(abs(S(i,:)-S(j,:)));%曼哈顿距离(在优化问题中易于线性化)
d_r=[d_r;[dij(i,j),rij(i,j)]]; % dij是i = x j = y是的距离,rij是半方差,两个dr就是持续往下叠叠乐下
end
end将其画为点状图的形式可得;
绘图代码:
S=[0.700000000000000,59.6000000000000;2.10000000000000,82.7000000000000;4.70000000000000,75.1000000000000;4.80000000000000,52.8000000000000;5.90000000000000,67.1000000000000;6,35.7000000000000;6.40000000000000,33.7000000000000;7,46.7000000000000;8.20000000000000,40.1000000000000;13.3000000000000,0.600000000000000;13.3000000000000,68.2000000000000;13.4000000000000,31.3000000000000;17.8000000000000,6.90000000000000;20.1000000000000,66.3000000000000;22.7000000000000,87.6000000000000;23,93.9000000000000;24.3000000000000,73;24.8000000000000,15.1000000000000;24.8000000000000,26.3000000000000;26.4000000000000,58;26.9000000000000,65;27.7000000000000,83.3000000000000;27.9000000000000,90.8000000000000;29.1000000000000,47.9000000000000;29.5000000000000,89.4000000000000;30.1000000000000,6.10000000000000;30.8000000000000,12.1000000000000;32.7000000000000,40.2000000000000;34.8000000000000,8.10000000000000;35.3000000000000,32;37,70.3000000000000;38.2000000000000,77.9000000000000;38.9000000000000,23.3000000000000;39.4000000000000,82.5000000000000;43,4.70000000000000;43.7000000000000,7.60000000000000;46.4000000000000,84.1000000000000;46.7000000000000,10.6000000000000;49.9000000000000,22.1000000000000;51,88.8000000000000;52.8000000000000,68.9000000000000;52.9000000000000,32.7000000000000;55.5000000000000,92.9000000000000;56,1.60000000000000;60.6000000000000,75.2000000000000;62.1000000000000,26.6000000000000;63,12.7000000000000;69,75.6000000000000;70.5000000000000,83.7000000000000;70.9000000000000,11;71.5000000000000,29.5000000000000;78.1000000000000,45.5000000000000;78.2000000000000,9.10000000000000;78.4000000000000,20;80.5000000000000,55.9000000000000;81.1000000000000,51;83.8000000000000,7.90000000000000;84.5000000000000,11;85.2000000000000,67.3000000000000;85.5000000000000,73;86.7000000000000,70.4000000000000;87.2000000000000,55.7000000000000;88.1000000000000,0;88.4000000000000,12.1000000000000;88.4000000000000,99.6000000000000;88.8000000000000,82.9000000000000;88.9000000000000,6.20000000000000;90.6000000000000,7;90.7000000000000,49.6000000000000;91.5000000000000,55.4000000000000;92.9000000000000,46.8000000000000;93.4000000000000,70.9000000000000;94.8000000000000,71.5000000000000;96.2000000000000,84.3000000000000;98.2000000000000,58.2000000000000];
Y=[34.1000000000000;42.2000000000000;39.5000000000000;34.3000000000000;37;35.9000000000000;36.4000000000000;34.6000000000000;35.4000000000000;44.7000000000000;37.8000000000000;37.8000000000000;43.9000000000000;37.7000000000000;42.8000000000000;43.6000000000000;39.3000000000000;42.3000000000000;39.7000000000000;36.9000000000000;37.8000000000000;41.8000000000000;43.3000000000000;36.7000000000000;43;43.6000000000000;42.8000000000000;37.5000000000000;43.3000000000000;38.8000000000000;39.2000000000000;40.7000000000000;40.5000000000000;41.4000000000000;43.3000000000000;43.1000000000000;41.5000000000000;42.6000000000000;40.7000000000000;42;39.3000000000000;39.2000000000000;42.2000000000000;42.7000000000000;40.1000000000000;40.1000000000000;41.8000000000000;40.1000000000000;40.9000000000000;41.7000000000000;40.8000000000000;38.7000000000000;41.7000000000000;40.8000000000000;38.7000000000000;38.6000000000000;41.6000000000000;41.5000000000000;39.4000000000000;39.8000000000000;39.6000000000000;38.8000000000000;41.6000000000000;41.3000000000000;41.2000000000000;40.5000000000000;41.5000000000000;41.5000000000000;38.9000000000000;39;39.1000000000000;39.7000000000000;39.7000000000000;40.3000000000000;39.5000000000000];
figure(4)
scatter(S(:,1),S(:,2))
第二步:数据的预处理。从上面的图可以看到 距离-方差 散点分布图非常的混乱,没有任何规律,常规的是根据距离进行点的分组,但是目前这种情况也没办法直接根据不同的距离进行分组。因此需要对数据进行一个基本的处理,查找了一下大佬们所用的方法:用k-means聚类对距离进行聚类,聚到一类的距离和半方差均取平均值,再进行拟合,
k-means聚类是对基础的数据进行分簇处理(英文直译是这个词),
K-means 算法是一种迭代聚类算法,它将数据集划分为 k 个不同的簇,每个簇包含具有相似特征的数据点。该算法的基本原理如下:
-
初始化: 随机选择 k 个数据点作为初始质心(簇的中心)。
-
分配: 将每个数据点分配到离其最近的质心所在的簇。
-
更新质心: 计算每个簇的新质心,即该簇中所有数据点的平均值。
-
重复: 重复步骤 2 和 3,直到簇不再发生变化,或者达到预定的迭代次数。
K-means 的目标是最小化每个数据点与其所属簇的质心之间的平方欧氏距离的总和。这被称为簇内平方和(inertia)。整个过程的目标是最小化以下损失函数:

其中:
- n 是数据点的数量。
- k 是簇的数量。
- xi? 是第 i 个数据点。
- cj? 是第 j 个簇的质心。
K-means 算法的迭代过程不保证全局最优解,因此对于不同的初始质心可能会得到不同的聚类结果。通常采用多次运行算法(即设置 'Replicates' 参数)来找到最佳的聚类。
在matlab中。这个函数的一般语法如下:
[idx, C] = kmeans(X, k)
其中:
X是包含观测值的矩阵,每行代表一个观测值,每列代表一个特征。k是要分为的簇的数量。idx是一个列向量,包含了每个观测值所属的簇的索引。C是一个矩阵,包含了每个簇的质心的坐标。
以下是一个简单的示例:
% 创建一个示例数据集
X = [randn(50,2)+2; randn(50,2)-2];
% 使用 kmeans 进行聚类,将数据分为 k = 2 个簇
k = 2;
[idx, C] = kmeans(X, k);
% 绘制聚类结果
scatter(X(:,1), X(:,2), 20, idx, 'filled');
hold on;
plot(C(:,1), C(:,2), 'rx', 'MarkerSize', 10, 'LineWidth', 2);
hold off;
title('K-Means Clustering Result');
在这个例子中,X 是一个包含两个聚类的示例数据集。kmeans 函数将数据分为两个簇,并返回每个点的簇索引和质心坐标。最后,使用散点图可视化聚类结果,每个簇用不同的颜色表示,质心用红色叉号标记。

对目标数据函数进行处理的结果为:绘图代码与结果如下所示;
figure(8)
scatter(d_r(:,1),d_r(:,2),'.')
hold on
scatter(d_r_divided(:,1),d_r_divided(:,2));
hold on;
plot(d_r_divided(:,1),d_r_divided(:,2), 'rx', 'MarkerSize', 10, 'LineWidth', 2);
hold on 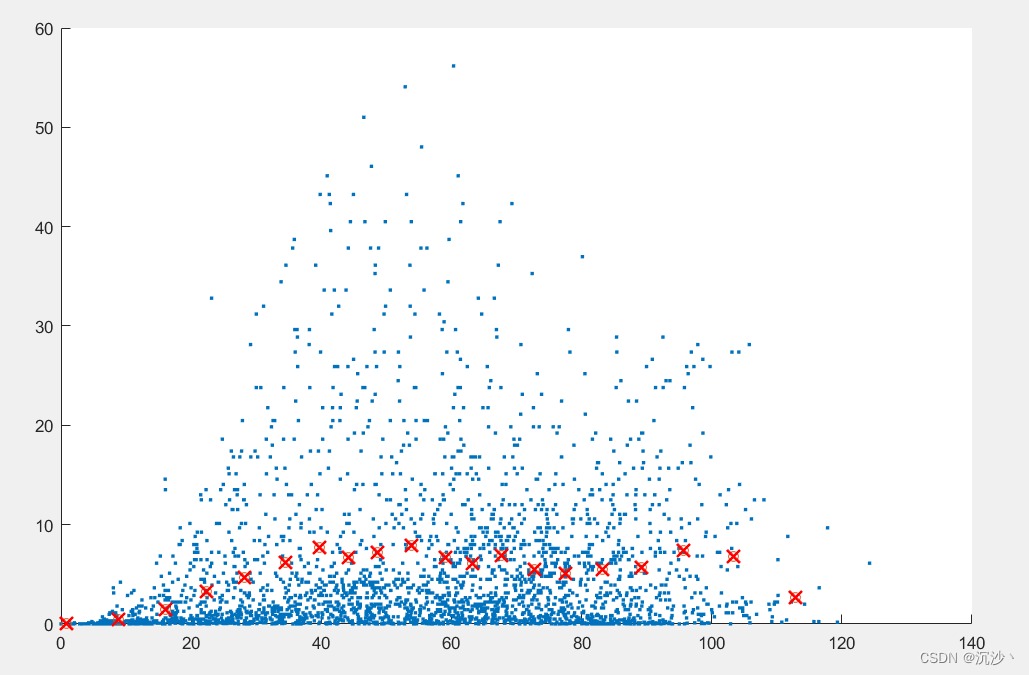
?此时的K值选择的是20,也可以选择为40;或者更多;
第三步:选择拟合模型,进行曲线拟合。选择高斯模型为目标模型,
高斯半变异函数是半变异函数的一种类型,通常用于描述数据在空间上的平滑性和相关性。
高斯半变异函数的数学表达式通常如下:
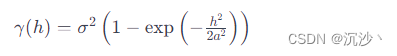
其中:
- γ(h) 是半变异函数,表示两个点之间的半变异。
- σ2 是变异的总体方差。
- ?是两个点之间的空间 lag(间隔)或距离。
- a 是半变异函数的范围参数,控制了半变异函数的横向展布。
高斯半变异函数的图形呈钟形(bell-shaped)或类似正态分布的形状。该函数在 lag 达到一定距离 a 时趋于平稳,表示空间相关性在这个距离上基本消失,这和地理学相符。在地统计学和地理信息系统 (GIS) 中,通过半变异函数的拟合和分析,可以对空间数据的相关性结构进行建模,有助于空间插值、空间预测和地理空间数据分析。
这个时候关键一步:调用matlab拟合工具箱,
cftool(d_r_divided(:,1),d_r_divided(:,2))cftool 是 MATLAB 中的 Curve Fitting 工具,是一个交互式工具,用于拟合曲线和表面拟合。这个工具使用户能够使用不同的拟合模型(如线性、多项式、指数、对数等)来拟合数据,并通过可视化工具来调整拟合参数以达到最佳拟合效果。操作过程如下图所示,(1)选择数据源(2)选择高斯模型(3)选择高斯阶数(4)观察曲线拟合效果

符合的话就按照公式与系数撰写一个单独的函数:
function [y] = Guassian_func_3(x)
a1 = 7.81 ;
b1 = 50.88 ;
c1 = 29.73 ;
a2 = 6.685 ;
b2 = 99.01 ;
c2 = 17.29 ;
[m,n]=size(x);
y=zeros(m,n);
for i=1:m
for j=1:n
y(i,j)=a1*exp(-((x(i,j)-b1)/c1)^2) + a2*exp(-((x(i,j)-b2)/c2)^2);
end
end
end
拟合结果如下所示,当然是阶数越高这个效果越好,但是计算量也越大,这个按照合适的定。
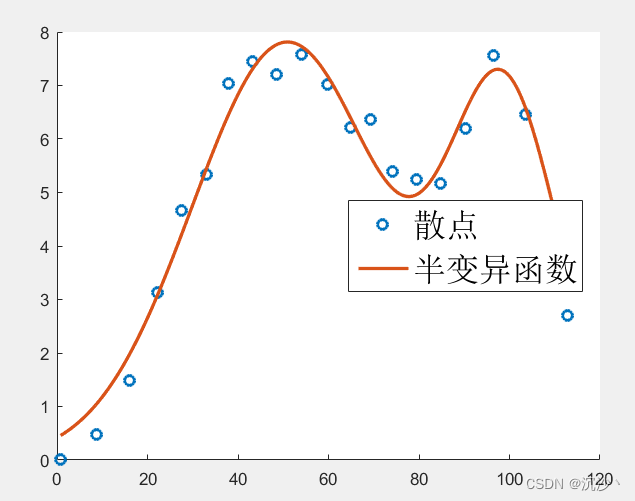
第四步:根据拟合曲线进行预测。在完成了 距离-半方差 曲线的拟合后,需要返回来求取具体的权重系数方程,然后对Z值进行估计;因此将距离值带回到高斯过程,
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 三年的功能测试,让我女朋友跑了,太难受了...
- Invalid bound statement (not found)异常解决方案归纳
- javascript 闭包详解
- 小米科技的辉煌与未来:发展、问题、解决、前景
- Google Gemini API快速上手
- Redis学习指南(0)-专栏前言
- 第三章 Qt5布局管理——3.3堆栈窗体QStackedWidget类
- 最优化理论期末复习笔记 Part 1
- php 的数据类型
- 阿里因侵权京东,赔款金额高达10亿】