ChatGPT提示词工程进阶
两种大型语言模型
- 基础大模型(Base LLM)
- 基于训练数据预测下文
- 指令调优大模型(Instruction?Tuned?LLM)
- 尝试听从指令
- 基于基础大模型,进一步使用指令内容输入+遵循指令内容输出来训练和微调模型
- RLHF(Reinforcement Learning with?Human Feedback):从人类反馈中进一步改进,让系统更得力,更听话。
清晰具体的书写提示词
- 原则1:编写清晰明确的提示词
- 在提示词中使用"定界符"? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
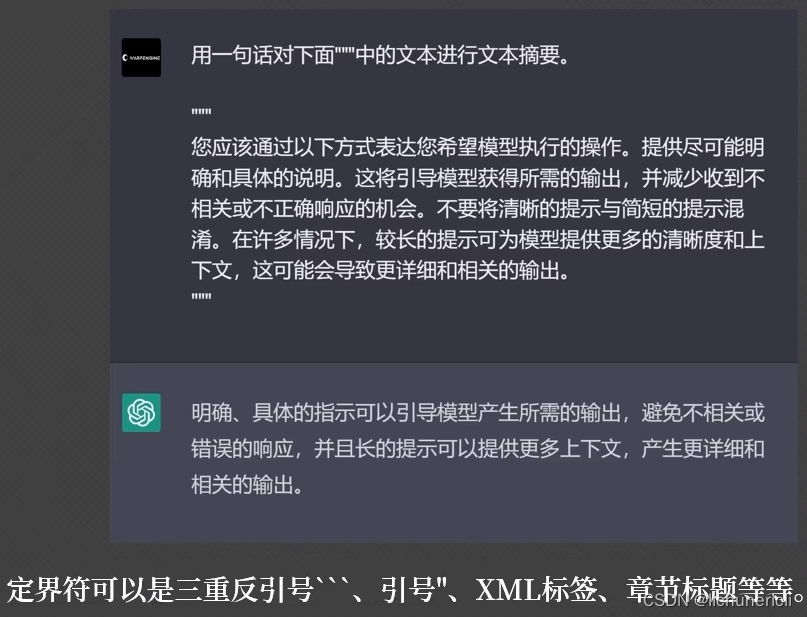
- 向模型请求结构化的输出
- 要求模型检查任务条件是否满足? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?

- 输入多范例提示,举例说明? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?

- 在提示词中使用"定界符"? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
- 原则2:给模型充足的思考时间
- 指定完成任务所需的步骤? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??

- 让模型自己推理并制定出解决方案? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??

- 指定完成任务所需的步骤? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
注意规避模型的局限性,例如:gpt-3.5-tuibo模型的局限性:
更好的迭代提示词

- 不奢求"一针见血",不断打磨,形成良好的提示词迭代流程
- 多维度,堆样本,踏实迭代提示词
用大语言模型总结文本


使用大语言模型的语义推理
语义推理:让模型针对文本内容执行某种分析,例如:提取标签,提取名称,文本情感分析等等。
在传统的机器学习工作流程中,如果您想识别一段文本到底是积极还是消极的情感,就必须收集标签数据集、训练模型,弄清楚如何在某个地方部署模型并进行推理。


在上述例子中,我们没有给它任何带有标记的训练数据,在机器学习中,这种算法叫做零样本学习算法。正如这个例子当中体现的一样,我们只需写一下提示词,它就能够确定该新闻文章涵盖了哪些主题,生成相应的推送,发送给指定的用户,这就是语义推理。
使用大模型进行文本转换
ChatGPT:天生的多语言能力者,利用GPT模型,轻轻松松实现通用翻译器。

语气转换,模型在语气和格式上都能做出转换,例如:将俚语翻译成商业书信。

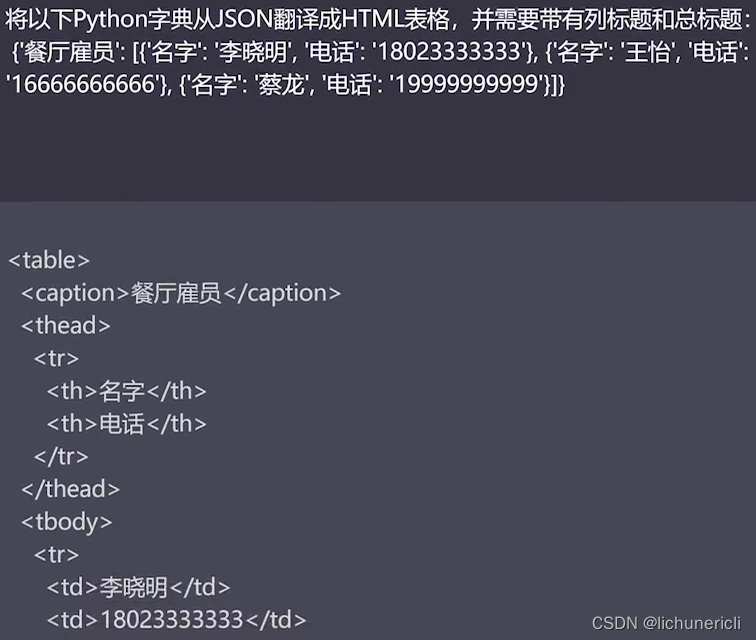
ChatGPT非常擅长格式转换,例如:JSON、XML、HTML、MarkDown等。
大语言模型的拼写检查和语法检查的技能。

使用ChatGPT的温度值(temperature)
在ChatGPT中,temperature值的高低能够影响模型输出的创造性和随机性。当温度值为"0"时,模型将始终选择概率最大的词。而温度值越高,它选择不太可能出现的词的概率越大,多次生成的结果也会更多样。当温度值为"1"时,生成的回复会非常随机,非常有创意,甚至可能会产生一些奇怪的回复。所以大多数情况下,为了构建一个可靠、可预测的系统,我们一般设置温度值为"0"。但如果需要模型更具有创意,可以试试调高温度值。

构建自己的聊天机器人
在大语言模型的对话中,我们发送的消息称之为user?message,模型的回答叫做assistant?message,系统消息system?message是指在user?message和assistant?message之间的一种类型的消息。系统消息通常由系统或对话管理器生成,用于在对话中引导和控制交互。
系统消息可以用于提供上下文、引导对话流程、提醒用户或助手采取特定的行动,以及提供其他对话管理方面的指令。系统消息的目的是影响对话的进展和行为,以确保对话在预期的方向上进行。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年寄快递,哪个平台比较便宜划算?
- 【数据库】MySQL数据库存储引擎、数据库管理和数据库账号管理
- nginx 1.14.0引入自己使用C语言写的模块
- Spring核心容器IOC案例讲解,带你理解IOC
- 如何使用react的hook实现复制粘贴操作?
- leetcode 437 路径总和
- C++继承与派生——(4)派生类的构造函数
- 探寻ChatGPT底层模型诞生之路 —— 3篇OpenAI关键论文解读
- 跑代码相关 初始环境配置
- CHD-Cloudera Manager API 详解