关于哈希的十到常见面试题
面试题一:HashMap为什么要使用红黑树而非其他数据结构来存储数据?
更快的搜索和插入速度:红黑树是一种自平衡二叉搜索树,因此查找和插入操作的时间复杂度为 O(log n),而链表的时间复杂度为 O(n)。在哈希冲突比较严重的情况下,使用红黑树能够更快地进行搜索和插入操作。
更稳定的性能:红黑树是"近似平衡"的。红黑树相比avl树,在检索的时候效率其实差不多,都是通过平衡来二分查找。但对于插入删除等操作效率提高很多。
面试题二:什么是负载因子?它的值为什么是0.75?
负载因子是用于衡量和哈希表中元素填满程度的一个参数,在HashMap中,负载因子和扩容机制有关系,当元素个数超过了容量*负载因子的时候,为了减少哈希冲突,就会进行扩容,提高HashMap性能。
负载因子太低会导致大量的空桶浪费空间,负载因子太高会导致大量的碰撞,降低性能。0.75 的负载因子在这两个因素之间取得了良好的平衡,它提供了空间和时间复杂度的良好平衡。
面试题三:HashMap是线程安全的吗?说下具体原因?
HashMap在多线程的环境下是不安全的,原因主要是两个方面:
- 原子性问题:HashMap操作不是原子性的,也就是说在多线程的环境下,如果多个线程同时对HashMap进行修改操作,可能会导致数据不一致。例如:让两个程序同时进行修改操作的时候,他们可能会计算出相同的文职,然后同时进行插入元素,这样会导致其中一个线程插入的元素被另一个线程所覆盖
- 内存可见性问题:在多线程的环境下,当一个线程修改了HashMap的状态,而另一个线程可能无法立即看到这个修改。
为了解决这个问题,Java提供了集中线程安全的Map实现,例如:Hashtable、ConcurrentHashMap和Collections.synchronizedMap,这些实现采用了不同的策略保证线程安全。但是这些实现在单线程的效率不如HashMap,所以我们需要按照需求来权衡
面试题四:HashMap会导致CPU 100%?什么场景下会出现这个问题?
HaahMap在多线程的环境下可能会导致CPU使用率达到100%,主要是由于HashMap在并发扩容可能会出现死循环:
后续不是很理解,会补充
面试题五:什么是哈希冲突?如何解决哈希冲突?
哈希冲突指的是在哈希表中,不同的键通过哈希函数计算后得到的相同的哈希地址。
解决哈希冲突的方法有以下几种:
- 开放地址法:当哈希冲突的时候,去寻找下一个新的空的哈希地址。
- 链地址法:将哈希表的每一个桶都设置为链表,当哈希冲突的时候,将新的元素添加到链表的末尾。缺点:当链表过长的时候,查询效率会降低。
- 再哈希法:当哈希冲突的时候,试试用另一个哈希函数计算出一个新的哈希值,然后将元素插入到对应的桶中。缺点需要额外的哈希函数,且当哈希函数不够随机会产生聚集
面试六:说一下HashMap的查询流程?
HashMap的查询流程分为以下几步:
- 计算哈希值:根据hashCode()计算出哈希值
- 计算索引:使用哈希值和数组长度计算出在数组中的索引位置
- 查找元素:在数组的这个索引上,可能有一个链表或者红黑树(如果链表超过一定的阈值,就会将链表转化为红黑树),遍历链表或者红黑树,通过equal()方法找到对应的元素
- 返回结果:如果招到了对应的元素,就返回该元素的值,如果没有找到,就返回null
面试题七:HashMap和Hashtable有什么区别?
HashMap和Hashtable都实现了Map接口,但是他们还是有以下几种区别:
- 线程安全:Haahtable是线程安全的,HashMap是非线程安全的。在多线程的环境下如果使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合。如:

- null键和null值:HashMap允许使用null作为键和值,大那是Hashtable不允许null作为键或值
- 继承类不同:HashMap继承自AbstractMap类,而Hashtable继承于Dictionary抽象类
- 默认容量不同:HashMap默认容量是16,Hashtable默认容量是11,影响因子都是0.75,HashMap扩容是翻倍,而Hashtable扩容是容量+1
- 底层数据结构:JDK 1.7中HashMap和Hashtable都是数组和链表,但是在JDK 1.8中HashMap引入了红黑树
面试题八:为什么Hashtable不允许插入null?而HashMap却可以?
Hashtable不允许插入null原因是:
- 空指针异常:Hashtable源码中,put方法会调用hashCode()方法来计算哈希值,如果key为null,则会抛出一个空指针异常,而value为null也会空指针异常
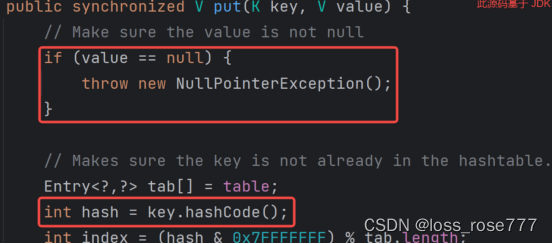
- 歧义性:当Hashtable的get方法返回nul,无法判断这个null是因为key是从未在Hashtable中映射过,还是因为value本身就是null
HashMap允许插入null原因是:
特殊处理:HashMap源码中,当key为null的时候,会将其哈希值设置为0,因此不会调用hashCode方法,避免空指针异常
面试题九:ConcurrentHashMap是怎么保证线程安全的?
- 分段锁技术:ConcurrentHashMap将内部的数据分为多个段,每个段都有自己的锁,这样在写操作的时候,只需要将锁定正在修改的哪一部分,而不是整个Map,这种锁分段技术可以让多个修改操作并发进行,提高并发性能
- 原子操作:ConcurrentHashMap提供了一些方法,如putIfAbsent()、replace()和remove(),这些方法都可以保证在并发的环境下的原子性
- 内存可见性:ConcurrentHashMap使用了volatile关键字和final关键字来保证内存可见性
- 并发级别:ConcurrentHashMap允许设置并发级别,这个并发级别决定了ConcurrentHashMap内部的段数量。并发级别越高,段数量越多,从而减少线程的竞争,提高并发性能
面试题十:说一下ConcurrentHashMap锁优化?
ConcurrentHashMap锁优化主要有两点:
- 锁粒度优化:JDK 1.7 ConcurrentHashMap使用的是分段锁,JDK 1.8之后使用的是枷锁一个数组的头接待你。锁粒度更小,意味着并发执行的时候效率更高
- 锁实现优化:JDK 1.7 使用的是ReentrantLock和synchronized实现加锁的,JDK 1.8 使用的是CAS或者synchronized来实现枷锁,CAS是乐观锁的实现,相比于ReentrantLock和synchronized的悲观锁,性能会有一定的优化
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!