Kaggle之泰坦尼克号(2)
发布时间:2024年01月02日
文章目录
书接上篇Kaggle之泰坦尼克号(1),上面提到的解决方案一经过特征工程、模型直接预测(0.78229)、优化超参数(0.78468),精度提升了0.2个百分点,最终精度排名为1700/14296(11.89%),下面说明基于特征工程的解决方案二。
解决方案二:
score:0.79425
Leaderboard:1244/14296(8.7%)
一、特征工程
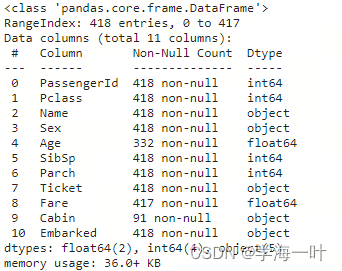
训练集一共提供11个特征包括6个数值型数据,5个文本型数据:
- 数值型:PassengerId(乘客ID)、Pclass(乘客等级)、Age(年龄)、SibSp(堂兄弟妹个数)、Parch(父母与小孩的个数)、Fare(票价)
- 文本型:Name(姓名)、Sex(性别)、Ticket(船票信息)、Cabin(船舱信息)、Embarked(登船港口)
缺失值处理
数据缺失情况
训练集

测试集
#对数据进行简单的预处理
#对fare缺失值使用均值替换
train_Fare_mean=train["Fare"].mean()
test.loc[test["Fare"].isnull()==True,"Fare"]=train_Fare_mean
#检验对test中fare空值是否替换完成
print("test对fare空值替换后为:\n",test.isnull().sum())
#对train中的embarked进行缺失值替换
train_embarked_mode=train["Embarked"].mode()
train.loc[train["Embarked"].isnull()==True,"Embarked"]=train_embarked_mode[0]
#检验成功对train的Embarked缺失值进行替换
print("train替换Embarked缺失值后为:\n",train.isnull().sum())
#对train\test中age数据采取mean替换
train.loc[train["Age"].isnull()==True,"Age"]=train["Age"].mean()
test.loc[test["Age"].isnull()==True,"Age"]=train["Age"].mean()
#验证train\test中Age缺失值补充完毕
print("补充train中Age后:\n",train.isnull().sum())
print("补充test中Age后:\n",test.isnull().sum())
#数据分割,模拟训练集和测试集的关系
label = train['Survived']
train.drop('Survived',axis=1,inplace=True)
X_train,X_test,Y_train,Y_test = train_test_split(train,label,test_size = 0.3,random_state = 1)
X_train['Survived'] = Y_train
X_test['Survived'] = Y_test
文本型数据处理-Sex
# 对sex进行编码 male==1,female==0
train['Sex'] = train['Sex'].apply(lambda x: 1 if x == 'male' else 0)
test['Sex'] = test['Sex'].apply(lambda x: 1 if x == 'male' else 0)
train = pd.get_dummies(data= train,columns=['Sex'])
test = pd.get_dummies(data= test,columns=['Sex'])
文本型数据处理-Name
- 名称类别对存活的影响(编码)
- 名称长度对存活的影响
# Name 名字开头的数量
def Name_Title_Code(x):
if x == 'Mr.':
return 1
if (x == 'Mrs.') or (x=='Ms.') or (x=='Lady.') or (x == 'Mlle.') or (x =='Mme'):
return 2
if x == 'Miss':
return 3
if x == 'Rev.':
return 4
return 5
X_train['Name_Title'] = X_train['Name'].apply(lambda x: x.split(',')[1]).apply(lambda x: x.split()[0])
X_test['Name_Title'] = X_test['Name'].apply(lambda x: x.split(',')[1]).apply(lambda x: x.split()[0])
# train.groupby(["Name_Call","Survived"])["Survived"].count()
train['Name_Title'] = train['Name'].apply(lambda x: x.split(',')[1]).apply(lambda x: x.split()[0])
test['Name_Title'] = test['Name'].apply(lambda x: x.split(',')[1]).apply(lambda x: x.split()[0])
train['Name_Title'] = train['Name_Title'].apply(Name_Title_Code)
# fig,axis=plt.subplots(1,1,figsize=(15,5))
# sns.barplot("Name_Call","Survived",data=train,ax=axis)
test['Name_Title'] = test['Name_Title'].apply(Name_Title_Code)
train = pd.get_dummies(columns = ['Name_Title'], data = train)
test = pd.get_dummies(columns = ['Name_Title'], data = test)
# 名字长度对存活的影响
X_train['Name_len'] = X_train['Name'].apply(lambda x: len(x))
X_test['Name_len'] = X_test['Name'].apply(lambda x: len(x))
train['Name_len'] = train['Name'].apply(lambda x: len(x))
test['Name_len'] = test['Name'].apply(lambda x: len(x))
文本型数据处理-Ticket
- Ticket首字母对存活的影响(编码)
#Ticket船票
#获取票的第一个字母
def Ticket_First_Let(x):
return x[0]
X_train['Ticket_First_Letter'] = X_train['Ticket'].apply(Ticket_First_Let)
X_test['Ticket_First_Letter'] = X_test['Ticket'].apply(Ticket_First_Let)
#可视化船票编号与存活的关系
#p1=plt.figure(figsize=(10,8))
#a1=p1.add_subplot(1,1,1)
def Ticket_First_Letter_Code(x):
if (x == '1'):
return 1
if x == '3':
return 2
if x == '4':
return 3
if x == 'C':
return 4
if x == 'S':
return 5
if x == 'P':
return 6
if x == '6':
return 7
if x == '7':
return 8
if x == 'A':
return 9
if x == 'W':
return 10
return 11
#test["Ticket_first"]=test["Ticket"].apply(Ticket_First_Letter)
#sns.barplot("Ticket_first","Survived",data=train_train.sort_values("Ticket_first"),ax=a1,capsize=0.2)
#sns.barplot("Ticket_first","Survived",data=test.sort_values("Ticket_first"),ax=axis[1])
#定义票的编号对存活的影响
train['Ticket_First_Letter'] = train['Ticket'].apply(Ticket_First_Let)
test['Ticket_First_Letter'] = test['Ticket'].apply(Ticket_First_Let)
train['Ticket_First_Letter'] = train['Ticket_First_Letter'].apply(Ticket_First_Letter_Code)
test['Ticket_First_Letter'] = test['Ticket_First_Letter'].apply(Ticket_First_Letter_Code)
train = pd.get_dummies(columns = ['Ticket_First_Letter'], data = train)
test = pd.get_dummies(columns = ['Ticket_First_Letter'], data = test)
#train.groupby(["Ticket_first","Survived"])["Survived"].count()
#fig,axis=plt.subplots(1,1,figsize=(15,5))
#sns.barplot("Ticket_first","Survived",data=train,ax=axis)
文本型数据处理-Cabin
- 缺失值补充及编码
#Cabin 缺失值,判断条件为是否为空
X_train['Cabin'] = X_train['Cabin'].fillna('Missing')
X_test['Cabin'] = X_test['Cabin'].fillna('Missing')
def Cabin_First_Letter(x):
if x == 'Missing':
return 'XX'
return x[0]
X_train['Cabin_First_Letter'] = X_train['Cabin'].apply(Cabin_First_Letter)
X_test['Cabin_First_Letter'] = X_test['Cabin'].apply(Cabin_First_Letter)
def Cabin_First_Letter_Code(x):
if x == 'XX':
return 1
if x == 'B':
return 2
if x == 'C':
return 3
if x == 'D':
return 4
return 5
train['Cabin'] = train['Cabin'].fillna('Missing')
test['Cabin'] = test['Cabin'].fillna('Missing')
#fig,axis=plt.subplots(1,2,figsize=(15,5))
#sns.barplot("Cabin_first","Survived",data=train_train.sort_values("Cabin_first"),ax=axis[0])
#sns.barplot("Cabin_first","Survived",data=train_test.sort_values("Cabin_first"),ax=axis[1])
train['Cabin_First_Letter'] = train['Cabin'].apply(Cabin_First_Letter)
test['Cabin_First_Letter'] = test['Cabin'].apply(Cabin_First_Letter)
train['Cabin_First_Letter'] = train['Cabin_First_Letter'].apply(Cabin_First_Letter_Code)
test['Cabin_First_Letter'] = test['Cabin_First_Letter'].apply(Cabin_First_Letter_Code)
train = pd.get_dummies(columns = ['Cabin_First_Letter'], data = train)
test = pd.get_dummies(columns = ['Cabin_First_Letter'], data = test)
#train.groupby(["Cabin_first","Survived"])["Survived"].count()
#fig,axis=plt.subplots(1,1,figsize=(15,5))
#sns.barplot("Cabin_first","Survived",data=train,ax=axis)
文本型数据处理-Embarked
- Embarked to 唯一值01编码字段
#对Embarked的处理,统计特性不强,候补
#p3=plt.figure(figsize=(10,8))
#a3=p3.add_subplot(1,1,1)
#sns.barplot("Embarked","Survived",data=train_train.sort_values("Embarked"),capsize=0.5,ax=a3)
train = pd.get_dummies(train,columns = ['Embarked'])
test = pd.get_dummies(test,columns = ['Embarked'])
特征扩充-SibSp、Parch
- 家庭情况对存活的影响
#Parch+SibSp 家人对存活的影响,0/>4存活较低,1<Family<3存活较高
#fig,axis=plt.subplots(1,2,figsize=(15,5))
#sns.barplot("Family","Survived",data=train_train.sort_values("Family"),ax=axis[0])
#sns.barplot("Family","Survived",data=train_test.sort_values("Family"),ax=axis[1])
# =============================================================================
X_train['Fam_Size'] = X_train['SibSp'] + X_train['Parch']
X_test['Fam_Size'] = X_test['SibSp'] + X_test['Parch']
def Family_feature(train, test):
for i in [train, test]:
i['Fam_Size'] = np.where((i['SibSp']+i['Parch']) == 0 , 'Solo',
np.where((i['SibSp']+i['Parch']) <= 3,'Nuclear', 'Big'))
del i['SibSp']
del i['Parch']
return train, test
train, test = Family_feature(train, test)
train = pd.get_dummies(train,columns = ['Fam_Size'])
test = pd.get_dummies(test,columns = ['Fam_Size'])
特征扩充-Pclass
# Pclass 票的等级对存活的影响
# PclassNumber=train.groupby(["Pclass","Survived"])["Survived"].count()
# PclassMean=train[["Pclass","Survived"]].groupby(by="Pclass").mean()
# PclassMean.plot(kind="bar",rot=0,figsize=(10,6),fontsize=18)
# =============================================================================
train['Pclass_1'] = np.int32(train['Pclass'] == 1)
train['Pclass_2'] = np.int32(train['Pclass'] == 2)
train['Pclass_3'] = np.int32(train['Pclass'] == 3)
test['Pclass_1'] = np.int32(test['Pclass'] == 1)
test['Pclass_2'] = np.int32(test['Pclass'] == 2)
test['Pclass_3'] = np.int32(test['Pclass'] == 3)
特征扩充-Age
#年龄对存活的影响
#AgeNumber=train.groupby(["Age","Survived"])["Survived"].count()
#SurvivedAge=train[train["Survived"]==1]["Age"]
#DeadAge=train[train["Survived"]==0]["Age"]
#AgeFrame=pd.concat([SurvivedAge,DeadAge],axis=1)
#AgeFrame.columns=["Survived","Dead"]
#AgeFrame.head()
## 为避免颜色覆盖,使用alpha通道属性
#AgeFrame.plot(kind="hist",bins=30,alpha=0.5,figsize=(10,6))
#年龄低于5岁,年龄在15-35岁间,年龄大于75岁
# =============================================================================
# fig,axis=plt.subplots(1,1,figsize=(15,5))
# sns.barplot("Age","Survived",data=train,ax=axis)
#
# =============================================================================
train['Small_Age'] = np.int32(train['Age'] <= 5)
train['Old_Age'] = np.int32(train['Age'] >= 65)
train['Middle_Age'] = np.int32((train['Age'] >= 15) & (train['Age'] <= 25))
test['Small_Age'] = np.int32(test['Age'] <= 5)
test['Old_Age'] = np.int32(test['Age'] >= 65)
test['Middle_Age'] = np.int32((test['Age'] >= 15) & (test['Age'] <= 25))
特征扩充-Fare
#对数据进行处理
#Fare,票价越高越容易生存,但价格分布大,选择log(fare+1)<=2时存活几乎为0
X_train['Fare'] = X_train['Fare'] + 1
X_test['Fare'] = X_test['Fare'] + 1
X_train['Fare'] = X_train['Fare'].apply(np.log)
X_test['Fare'] = X_test['Fare'].apply(np.log)
# =============================================================================
# fig,axis=plt.subplots(1,2,figsize=(15,5))
# sns.barplot("Fare","Survived",data=train_train.sort_values["Fare"],ax=axis[0],capsize=0.2)
# sns.barplot("Fare","Survived",data=train_test.sort_values["Fare"],ax=axis[1],capsize=0.2)
# =============================================================================
train['Fare'] = train['Fare'] + 1
test['Fare'] = test['Fare'] + 1
train['Fare'] = train['Fare'].apply(np.log)
test['Fare'] = test['Fare'].apply(np.log)
train['Fare_0_2'] = np.int32(train['Fare'] <= 2)
train['Fare_2_3'] = np.int32((train['Fare'] > 2) & (train['Fare'] <= 3) )
train['Fare_3_4'] = np.int32((train['Fare'] > 3) & (train['Fare'] <= 4) )
train['Fare_4_5'] = np.int32((train['Fare'] > 4) & (train['Fare'] <= 5))
train['Fare_5_'] = np.int32(train['Fare'] > 5)
test['Fare_0_2'] = np.int32(test['Fare'] <= 2)
test['Fare_2_3'] = np.int32((test['Fare'] > 2) & (test['Fare'] <= 3) )
test['Fare_3_4'] = np.int32((test['Fare'] > 3) & (test['Fare'] <= 4) )
test['Fare_4_5'] = np.int32((test['Fare'] > 4) & (test['Fare'] <= 5))
test['Fare_5_'] = np.int32(test['Fare'] > 5)
二、特征选择及建模预测
#特征选择,模型训练
#冗余数据及文本数据进行删除,共同列提取与对齐
train.drop(['Ticket','PassengerId','Name','Age','Cabin','Pclass'],axis = 1, inplace=True)
test.drop( ['PassengerId','Ticket','Name','Age','Cabin','Pclass'],axis =1, inplace=True)
X_train_ = train.loc[X_train.index]
X_test_ = train.loc[X_test.index]
Y_train_ = label.loc[X_train.index]
Y_test_ = label.loc[X_test.index]
X_test_ = X_test_[X_train_.columns]
test = test[train.columns]
#模型训练
#随机森林
rf_ = RandomForestClassifier(criterion='gini',
n_estimators=700,
# max_depth=5,
min_samples_split=16,
min_samples_leaf=1,
max_features='auto',
random_state=10,
n_jobs=-1)
rf_.fit(X_train_,Y_train_)
rf_.score(X_test_,Y_test_)
rf_.fit(train,label)
# 预测
pd.concat((pd.DataFrame(train.columns, columns = ['variable']),
pd.DataFrame(rf_.feature_importances_, columns = ['importance'])),
axis = 1).sort_values(by='importance', ascending = False)[:20]
submit = pd.read_csv('/kaggle/input/titanic/gender_submission.csv')
submit.set_index('PassengerId',inplace=True)
res_rf = rf_.predict(test)
submit['Survived'] = res_rf
submit['Survived'] = submit['Survived'].apply(int)
submit.to_csv('submission.csv')
文章来源:https://blog.csdn.net/long11350/article/details/135335848
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux笔记--VSCode利用交换机跳转服务器
- Android app无障碍服务增加
- SpringCloud系列(四)| 服务之间的调用
- VASP结合vaspkit+ShengBTE计算热电优值(一)
- 如何查看崩溃日志
- 威士忌的起源与历史:从古代酿酒工艺到现代产业的发展
- Java实现树结构(为前端实现级联菜单或者是下拉菜单接口)
- 批量在线迁移redis —— 筑梦之路
- 工单处理再升级:灵活自定义工作台,亿发系统解锁工单管理新潜能
- 几种常见的算法