跟着我学Python进阶篇:03. 面向对象(下)
往期文章
跟着我学Python基础篇:01.初露端倪
跟着我学Python基础篇:02.数字与字符串编程
跟着我学Python基础篇:03.选择结构
跟着我学Python基础篇:04.循环
跟着我学Python基础篇:05.函数
跟着我学Python基础篇:06.列表
跟着我学Python基础篇:07.文本
跟着我学Python基础篇:08.集合和字典
跟着我学Python进阶篇:01.试用Python完成一些简单问题
跟着我学Python进阶篇:02.面向对象(上)
目录
1. 面向对象的三大特征
面向对象开发思想具有三个典型特征:封装、继承和多态
- 封装
使用封装能隐藏对象的视线细节,使代码更容易维护,同时因为不能直接调用修改内部私有信息,在一定程度上保证了系统的安全性。 - 继承
继承主要描述类与类的关系,他可以在不必重写类的情况下,对原有类的功能进行扩展。继承不仅增强了代码的复用性,还提高了开发效率。为程序后期维护提供了便利。 - 多态
多态与继承紧密相连,是面向对象变成的另一个突出的特点。对象的多态性是指在父类中定义的属性和方法被子类继承后,可以使用同一个属性或方法在父类及各个子类中具有不同的含义,这称为多态性。简单来说,就是一种行为产生多种结果。
2. 封装
封装是面向对象编程中的一种重要概念,它允许将数据和相关的操作封装在一个单元中,同时隐藏内部细节并提供对外的接口。通过封装,我们可以实现信息的隐藏和保护,同时提供更清晰、简洁的编程接口。
在封装中,一个类被用来封装数据和方法。数据通常被定义为类的属性(或成员变量),而方法则是操作这些数据的函数。通过使用访问修饰符(如公有、私有、受保护等),我们可以控制数据和方法的可访问性。
封装的主要目的有以下几点:
-
数据隐藏:封装允许将数据隐藏在类的内部,只暴露必要的接口供外部使用。这样可以防止不合理的访问和修改数据,增强了程序的安全性和稳定性。
-
接口简化:通过封装,我们可以将复杂的内部实现细节隐藏起来,只提供一个简洁的接口供其他代码使用。这样可以降低代码的耦合度,提高代码的可维护性和可重用性。
-
代码隔离:封装将数据和方法封装在类内部,使得每个类都具有独立的作用域。这样可以避免命名冲突和代码混乱,提高代码的可读性和可理解性。
-
代码组织:封装使得代码按照功能模块进行组织,更易于管理和扩展。类的内部实现可以自由修改,而不会影响到其他代码。
3. 继承
3.1 单继承
在面向对象的编程里,所有的事物都对应一个类,一个类可以继承自另一个类,并自动拥有另一个类的属性和方法,并且可以进一步完善,添加新的特性和方法。当一个类继承自其他类时,继承类叫做子类,被继承类叫做超类或者父类。
在Python中,继承使用如下语法格式:
class 子类名(父类名)
如果在类定义时没有标注,则默认类是继承自object的。
需要说明的是,子类不能继承父类的私有属性和方法,也不能在子类中直接访问。但子类对象可以通过调用父类方法的途径访问父类私有属性。
3.2 isinstance()和issubclass()方法
Python提供isinstance和issubclass两个和继承相关的函数。
1.isinstance()函数
isinstance(o,t)函数用于检查对象的类型,它有两个参数,第一个参数是判断类型的对象(o),第二个参数是类型(t),如果o是t类型的对象,则返回True,否则返回False。
- issubclass()函数
函数issubclass(cls,classinfo)用于检查类和继承关系,它也有两个参数,第一个参数是要判断的子类类型(cls),第二个参数是要判断父类类型(classinfo),如果cls是classinfo的子类,则函数返回True,否则返回False。
3.3 多继承
一个子类可以继承自多个不同的父类,这种情况叫做多继承。Python语言是支持多继承的,多继承的基本语法格式如下:
class 子类(父类1,父类2)
我们创建房车类(RV),让他继承自房屋类(House)和车辆类(Car)两个父类。
class House():
def live(self):
print("--房子可以居住--")
class Car():
def move(self):
print("--汽车可以行驶--")
class RV(House,Car):
pass
rv=RV()
rv.live()
rv.move()

从运行结果可知,子类的对象同时继承了两个父类方法。那么问题来了,如果子类的多个父类有一个同名的方法,那么子类的对象继承来的是哪个父类的方法呢?我们来做一个测试:
class House():
def get_color(self):
print("白色的房子")
class Car():
def get_color(self):
print("红色的汽车")
class RV(House,Car):
pass
rv=RV()
rv.get_color()
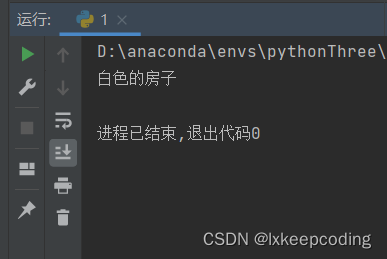
实际上,在Python3中,如果子类继承的多个父类间是平行关系,子类先继承哪个类就会调用哪个类的方法。如果当前类的继承关系非常复杂,Python会使用mro算法找到合适的类。
mro算法专门用在多继承时判断调用的属性方法和路径,即来自哪个类,可以通过类名访问_mro()_属性方法查看该类搜索属性和方法时先后顺序。
如果多个父类有同名的方法或属性,在子类中要指定使用某个父类的方法或属性时,我们可以在子类中对该属性或者方法名赋值来覆盖继承。
下面例子来说明多继承情况下指定父类元素的使用:
class House():
color="白色"
def get_color(self):
print(self.color)
class Car():
color="红色"
def get_color(self):
print(self.color)
class RV(House,Car):
color=Car.color
get_color=Car.get_color
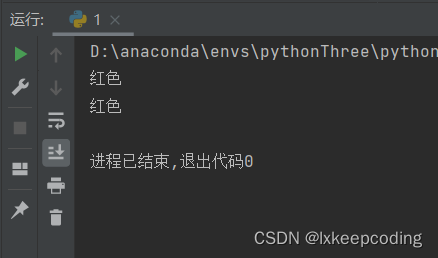
rv=RV()
print(rv.color)
rv.get_color()
3.4 重写
在有些情况下,子类希望对父类提供的属性和方法进行修改,提供自己的实现,这种行为就叫重写。
下面,我们使用子类InServiceStudent(在职生)重写父类Student(学生)的方法:
class Student(object):
def main(self):
print("学习")
class InServiceStudent(Student):
def main(self):
print("一边工作一边学习")
in_service_student=InServiceStudent()
in_service_student.main()
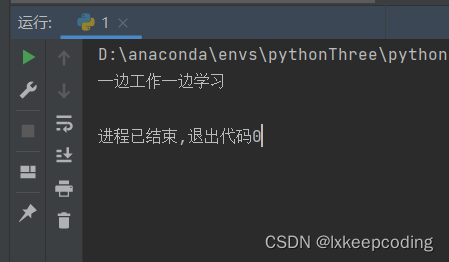
父类Student有一个main()方法,子类InServiceStudent重写了main()方法,从运行结果可以看出,在in_service_student对象调用方法时,调用的是子类的main()方法。
3.5 super关键字
在子类重写父类方法后,如果还需要访问父类的同名方法,可以使用super关键字,super关键字用在子类访问父类中。
使用super关键字的经典场合是在_init()_方法中,在Python中,如果子类重写了_init()_构造方法,子类并不会自动调用父类的构造方法,但是子类通常需要父类的构造方法,包括在构造方法里定义的父类的属性,或者初始化设置等,所以在子类重写的_init()_方法中,要调用父类的_init()_方法
class Father(object):
def __init__(self):
print("父类构造方法")
class Son(Father):
def __init__(self):
print("子类构造方法")
son=Son()
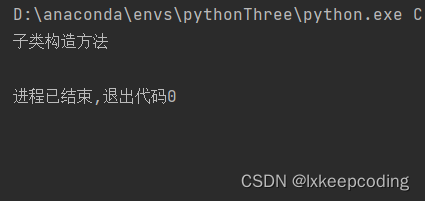
我们可以看出,子类重写构造方法后,并没有调用父类的构造方法。
如果子类需要在构造方法中增加自己的属性,或者扩充其他功能,而需要重写构造方法的话,一定要记住在最后调用父类的构造方法,比如上述代码中的Son类的构造方法可以更改为:
class Father(object):
def __init__(self):
print("父类构造方法")
class Son(Father):
def __init__(self):
super().__init__();
print("子类构造方法")
son=Son()
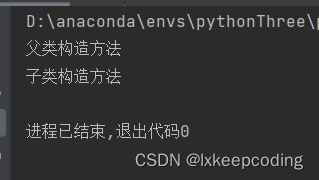
从结果可知,子类调用了父类的构造方法。
4. 多态
多态是面向对象的语言的最核心的特征。如果一个语言不具有多态性,那么就不能称之为面向对象的语言。
在Python中,多态指在不考虑对象类型的情况下使用对象。Python不关注对象的类型,而关注对象具体的行为。
由于Python是动态类型的语言,所以多态随处可见,Python中使用对象,并不需要显示指定对象类型,只要对象具有预期的方法和表达式操作符,就可以使用。
看一个多态的案例:
class Animal(object):
def move(self):
pass
class Rabbit(Animal):
def move(self):
print("兔子蹦蹦跳跳")
class Snail(Animal):
def move(self):
print("蜗牛缓慢爬行")
def test(obj):
obj.move()
rabbit=Rabbit()
test(rabbit)
snail=Snail()
test(snail)

从运行结果可以看出,根据传入参数对象不同,调用的是不同类型对象的move方法,实际上,test并没有规定参数的类型,所以传入其他类型的对象可以,只要该对象具有move方法,而不一定继承自animal类。
在强语言类型中,由于严格限制了变量类型,所以多态适用于把不同的子类对象都当作父类来看,可以屏蔽不同子类对象之间的差异,赋值之后,父类类型的对象就可以根据当前赋值给他的子类对象的特征以不同的方式运作,也就是,父类的行为像儿子,而非儿子的行为像父亲。
5. 运算符重载
在Python里,用户可以在自定义类里通过特殊方法来重载内建运算符,类可以重载所有表达式运算符,以及打印、函数调用、属性点号运算符等内置运算,重载使得类对象的行为更像内置类型,在类中提供特殊名称的类方法,可以实现对应运算符重载。
例如,加法+对应__add__方法,当调用+进行运算的时候,实际上调用了__add__方法。表中给出了部分运算符重载的方法:
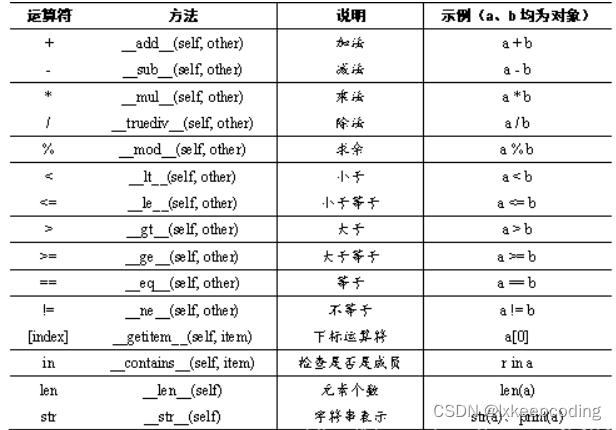
5.1 四则运算重载
我们创建一个简单的计算器,Calculator类,它能执行四则运算,并且把运算结果记录下来,作为下一次运算符的起始数字,代码如下:
class Calculator():
def __init__(self,number):
self.number=number
def __add__(self, other):
self.number=self.number+other
return self.number
def __sub__(self, other):
self.number=self.number-other
return self.number
def __mul__(self, other):
self.number=self.number*other
return self.number
def __truediv__(self, other):
self.number=self.number/other
return self.number
calucator=Calculator(10)
print(calucator+10)
print(calucator-5)
print(calucator*2)
print(calucator/3)

5.2 索引和分片重载
以下是跟索引和分片相关的3个重载方法:
getitem:索引、分片取值
setitem:索引、分片赋值
delititem:索引和分片删除
- __getitem__方法
在对实例对象进行索引、分片或者for迭代操作取值时,会自动调用该方法。
class ClassScore(object):
def __init__(self,numbers):
self.scores=numbers[:]
def __getitem__(self, index):
return self.scores[index]
mathscore=ClassScore([85,91,95,98])
print(mathscore[0])
print(mathscore[1:])
for score in mathscore:
print(score)

- __setitem__方法
通过赋值语句给索引或者分片赋值时,调用该方法可以实现对序列对象的修改。
class ClassScore(object):
def __init__(self,numbers):
self.scores=numbers[:]
def __setitem__(self, index, value):
self.scores[index]=value
mathscore=ClassScore([85,91,95,98])
print(mathscore.scores)
mathscore[0]=100
print(mathscore.scores)
mathscore[1:3]=[99,98,97]
print(mathscore.scores)

5.3 定制对象和字符串形式
重载__str__和__reper__ 方法可以定义对象转换为字符串的形式,在执行print,str,reper及交互模式下直接显示对象时,会调用__str__和__reper__方法,但是只重载某个方法与把两个方法都重载的效果是不同的。
当只重载__str__()方法时:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Person: {self.name}, Age: {self.age}"
person = Person("Alice", 25)
print(person) # 输出:Person: Alice, Age: 25
str_representation = str(person)
print(str_representation) # 输出:Person: Alice, Age: 25
repr_representation = repr(person)
print(repr_representation) # 输出:'<__main__.Person object at 0x00000123456789>'
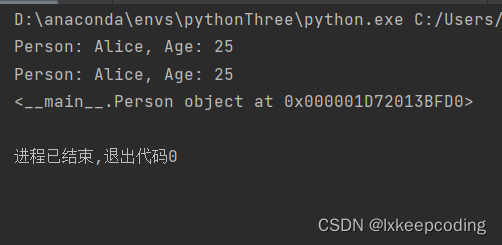
当只重载__repr__()方法时:
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Point({self.x}, {self.y})"
point = Point(3, 4)
print(point) # 输出:'<__main__.Point object at 0x00000123456789>'
str_representation = str(point)
print(str_representation) # 输出:'<__main__.Point object at 0x00000123456789>'
repr_representation = repr(point)
print(repr_representation) # 输出:'Point(3, 4)'
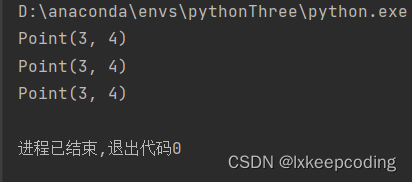
当同时重载__str__()和__repr__()方法时:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Person: {self.name}, Age: {self.age}"
def __repr__(self):
return f"Person({self.name}, {self.age})"
person = Person("Alice", 25)
print(person) # 输出:Person: Alice, Age: 25
str_representation = str(person)
print(str_representation) # 输出:Person: Alice, Age: 25
repr_representation = repr(person)
print(repr_representation) # 输出:'Person(Alice, 25)'

6. __new__方法
Python中object类还有一个内建方法__new__,用于创建类,在自定义类时一般不重写这个方法,但在特殊场合也会重写。
该方法是类的静态方法,即使重写时没有被加上静态方法修饰器。
我们来看一下object类中对该方法的定义:
@staticmethod
def __new__(cls,*more):
"""Create and return a new object"""
pass
关于定义的介绍如下:
cls 代表要实例化的类,此参数在实例化时由Python解释器自动提供。
该方法必须要有返回值,返回实例化出来的实例,这点在自己实现__new__方法时要特别注意,可以return 父类__new__方法返回的实例,或者直接返回object类的__new__方法返回的实例。
class Test(object):
def __init__(self):
print("执行init方法")
print("self对象的id是%s"%id(self))
def __new__(cls):
print("执行new方法")
demo_object=object.__new__(cls)
print("demo_object对象的id是%s"%id(demo_object))
return demo_object
test=Test()
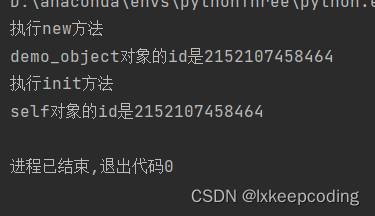
从结果可以看出,在创建test对象时,首先运行了__new__方法,然后才是__init__方法,并且__new__方法返回对象id与传入__init__方法的对象id相同,证明他们是同一个对象。
__new__方法和__init__方法还是有区别的:
new创建对象,init在new的基础上完成其他一些初始化工作,包括设置对象私有属性等。
init方法不需要返回值。
init方法的参数是self,就是new方法返回的实例。
7. 单例模式
单例模式是一种设计模式,用于确保一个类只有一个实例对象,并提供一个全局访问点来获取该实例。在单例模式中,通过限制类的实例化过程,可以确保只有一个实例对象存在,并且可以在程序的任何地方使用该实例。
实现单例模式的方法有多种,以下是其中两种常见的方式:
- 使用模块级别的变量:在 Python 中,模块是天然的单例,因为模块在程序的整个生命周期中只会被加载一次。可以将需要单例化的类定义在一个模块中,然后其他模块可以通过导入该模块来使用该类的唯一实例。例如:
# singleton.py
class SingletonClass:
def __init__(self):
# 初始化操作
pass
# 使用单例类
singleton_instance = SingletonClass()
在其他模块中使用这个单例类的实例:
# other_module.py
from singleton import singleton_instance
# 使用 singleton_instance 进行操作
- 使用装饰器:通过定义一个装饰器函数,可以将一个普通的类转换为单例类。装饰器函数在创建实例对象时,检查是否已经存在实例对象,如果存在则返回已有的实例,否则创建一个新的实例并返回。例如:
def singleton(cls):
instances = {}
def wrapper(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return wrapper
@singleton
class SingletonClass:
def __init__(self):
# 初始化操作
pass
# 使用单例类
singleton_instance = SingletonClass()
这样,每次创建 SingletonClass 的实例时,都会通过装饰器函数来获取唯一的实例对象。
8. 工厂模式
工厂模式是一种创建型设计模式,用于封装对象的实例化过程。它通过定义一个共同的接口来创建不同类型的对象,而无需直接指定其具体类。
工厂模式的主要目的是将对象的创建与使用代码解耦,以提高代码的灵活性和可维护性。它对于创建复杂对象或者对象有多个变体的情况非常有用。
在工厂模式中,通常存在一个抽象工厂类或者接口,用于定义创建对象的方法。具体的对象创建由其子类或者实现类来完成。这样,客户端代码只需要通过调用工厂方法来获取所需的对象,而无需直接依赖具体的类。
下面是一个简单的示例,展示了如何使用工厂模式创建不同类型的汽车对象:
from abc import ABC, abstractmethod
class Car(ABC):
@abstractmethod
def drive(self):
pass
class SedanCar(Car):
def drive(self):
print("Driving a sedan car.")
class SUVCar(Car):
def drive(self):
print("Driving an SUV car.")
class CarFactory(ABC):
@abstractmethod
def create_car(self):
pass
class SedanCarFactory(CarFactory):
def create_car(self):
return SedanCar()
class SUVCarFactory(CarFactory):
def create_car(self):
return SUVCar()
# 使用工厂模式创建汽车对象
sedan_factory = SedanCarFactory()
sedan_car = sedan_factory.create_car()
sedan_car.drive()
suv_factory = SUVCarFactory()
suv_car = suv_factory.create_car()
suv_car.drive()
在上述示例中,Car是一个抽象基类,定义了所有汽车对象的共同方法。SedanCar和 SUVCar是具体的汽车类,分别实现了 drive()`方法。
CarFactory 是抽象工厂类,定义了创建汽车对象的抽象方法 create_car()。SedanCarFactory`和 SUVCarFactory是具体的工厂类,分别实现了 create_car() 方法,用于创建 SedanCar和SUVCar对象。
通过使用工厂模式,客户端代码只需要和抽象工厂类以及抽象产品类交互,而无需直接依赖具体的类。这样,当需要添加新的汽车类型时,只需要新增对应的具体产品类和具体工厂类,并在客户端代码中使用相应的工厂对象即可,不会影响到原有代码的稳定性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深入了解pnpm:一种高效的包管理工具
- 英伟达发布 RTX 4090 D 显卡;《纽约时报》起诉 OpenAI 和微软侵权
- 微服务实战系列之Dubbo(下)
- 关于rewriteBatchedStatements的源码分析
- Android Studio新手实战——深入学习Activity组件
- 瑞芯微RV1103与FPGA图像传输,实现网络推流
- Javascript 函数调用讲解
- python 学生信息管理系统
- windows安装、基本使用vim
- Linux LVM逻辑卷