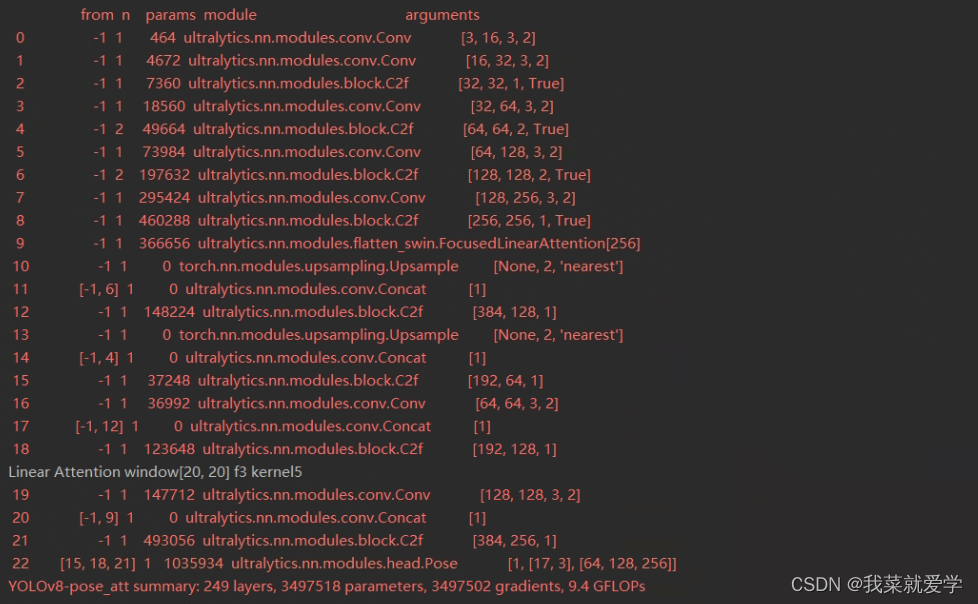
FLatten Transformer:聚焦式线性注意力模块
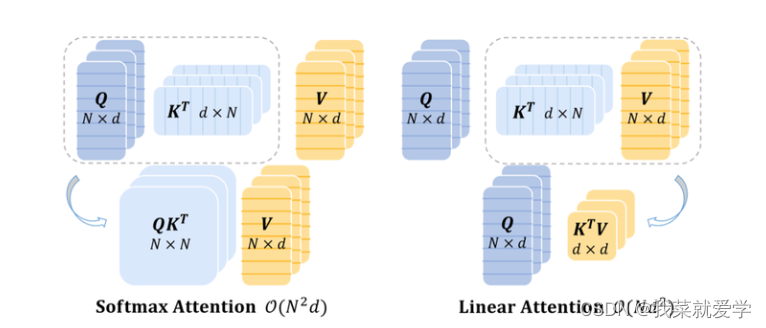
线性注意力将Softmax解耦为两个独立的函数,从而能够将注意力的计算顺序从(query·key)·value调整为query·(key·value),使得总体的计算复杂度降低为线性。然而,目前的线性注意力方法要么性能明显不如Softmax注意力,并且可能涉及映射函数的额外计算开销
首先,以往线性注意力模块的注意力权重分布相对平滑,缺乏集中能力来处理最具信息量的特征。作为补救措施,我们提出了一个简单的映射函数来调整查询和关键字的特征方向,使注意权值更容易区分。其次,我们注意到注意力矩阵的降低秩限制了线性注意力特征的多样性。提出了一个秩恢复模块,通过对原始注意矩阵进行额外的深度卷积(DWC),有助于恢复矩阵秩,并保持不同位置的输出特征多样化。
聚焦能力
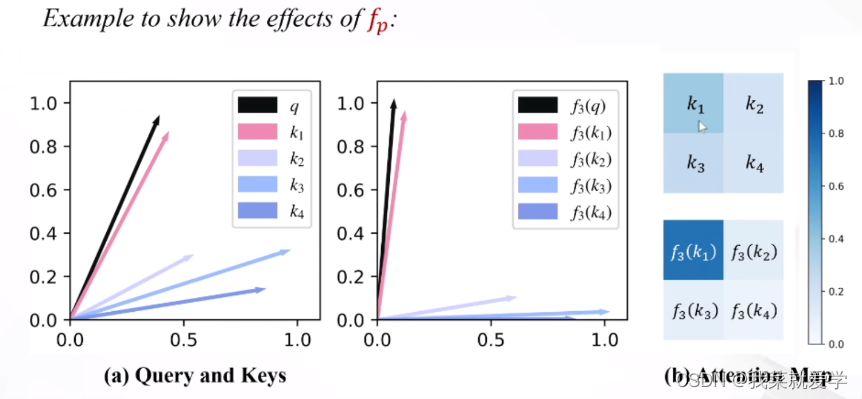
先前的一些工作中指出,在自注意力计算中,Softmax提供了一种非线性的权重生成机制,使得模型能够更好地聚焦于一些重要的特征。如下图所示,本文基于DeiT-tiny模型给出了注意力权重分布的可视化结果。可以看到,Softmax注意力能够产生较为集中、尖锐的注意力权重分布,能够更好地聚焦于前景物体;而线性注意力的分布则十分平均,这使得输出的特征接近所有特征的平均值,无法聚焦于更有信息量的特征。

Softmax Attention

Linear Attention
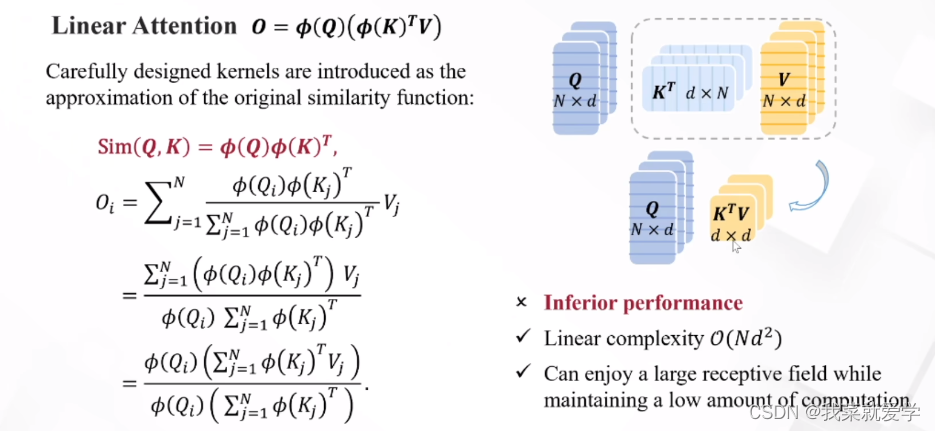
线性注意力被认为是一种有效的替代方法,它将计算复杂度从O(N2)限制到O(N)。具体来说,引入精心设计的核函数作为原始相似函数的近似,即
Focused Linear Attention
1、聚焦

2 、DWC 特征多样性
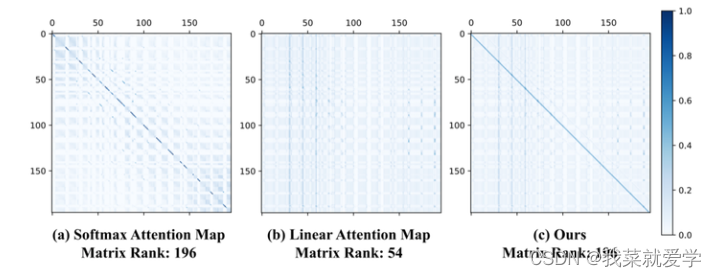
除聚焦能力外,特征多样性也是限制线性注意力性能的一个因素。本文基于DeiT-tiny可视化了完整的注意力矩阵,并计算了矩阵的秩,将Softmax注意力与线性注意力进行对比。从图中可以看到,Softmax注意力可以产生满秩的注意力矩阵,这反映出模型提取到的特征具有多样性。然而,线性注意力无法得到满秩的注意力矩阵,这意味着不同行的权重之间存在冗余性。。
线性注意力矩阵的秩会被每个head的维度d和特征数量N中的较小者所限制:
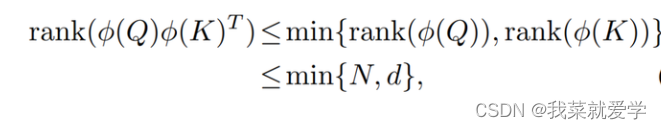
由于自注意力的输出是这些权重对同一组value加权组合得到的,权重的同质化就必然会导致模型输出的多样性下降,进而影响模型性能。
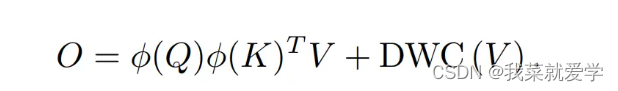
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java实现定时任务
- Java基础重点之四大内部类
- 【自动建表】自动化测试软件自动建表
- 2007~2016 年税调经纬度及其所处的省市区县乡镇数据
- 2024年您应该知道的 12个绝佳且免费的 AI 工具
- 【MySQL】ANY函数 的巧用(筛选字段 = ANY(语句))
- 50. Pow(x, n)(Leetcode) C++递归实现(超详细)
- java: 5-4 while循环
- 睿智的目标检测65——Pytorch搭建DETR目标检测平台
- python图片转灰度报错cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)