Kafka -- 初识
目录
kafka是什么
Kafka?是一个分布式的消息引擎,能够发布和订阅消息流(类似于消息队列) 以容错的、持久的方式存储消息流 多分区概念,提高了并行能力。
架构如下图:

Topic
消息的主题、队列,每一个消息都有它的 topic,Kafka 通过 topic 对消息进行归类。Kafka 中可以将 Topic 从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,以”topicName_partitionIndex” 的命名方式命名,该 dir 包含了这个分区的所有消息 (.log) 和索引文件 (.index),这使得 Kafka 的吞吐率可以水平扩展。
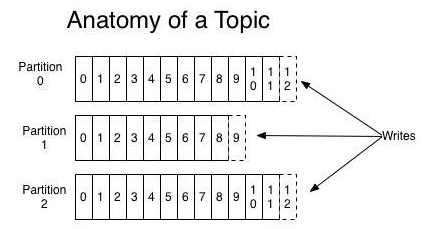
Partition
每个分区都是一个顺序的不可变的消息队列, 并且可以持续的添加;
分区中的消息都被分了一个序列号,称之为偏移量 (offset),在每个分区中此偏移量都是唯一的。
producer 在发布消息的时候,可以为每条消息指定 Key,这样消息被发送到 broker 时,会根据分区算法把消息存储到对应的分区中(一个分区存储多个消息),如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡。?
Broker
Kafka server,用来存储消息,Kafka 集群中的每一个服务器都是一个 Broker,消费者将从 broker 拉取订阅的消息 Producer 向 Kafka 发送消息,生产者会根据 topic 分发消息。生产者也负责把消息关联到 Topic 上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。算法可由开发者定义。
Cousumer
Consermer 实例可以是独立的进程,负责订阅和消费消息。消费者用 consumerGroup 来标识自己。同一个消费组可以并发地消费多个分区的消息,同一个 partition 也可以由多个 consumerGroup 并发消费,但是在 consumerGroup 中一个 partition 只能由一个 consumer 消费。
CousumerGroup
同一个 Consumer Group 中的 Consumers,Kafka 将相应 Topic 中的每个消息只发送给其中一个 Consumer
Offset
onsumer 的消息位移代表了当前 group 对 topic-partition 的消费进度,consumer 宕机重启后可以继续从该 offset 开始消费。 在 kafka0.8 之前,位移信息存放在 zookeeper 上,由于 zookeeper 不适合高并发的读写,新版本 Kafka 把位移信息当成消息,发往?consumersoffsets 这个 topic 所在的 broker,_consumersoffsets 默认有 50 个分区。 消息的 key 是 groupId+topicpartition,value 是 offset.
reblance
一些原因导致 consumer 对 partition 消费不再均匀时,kafka 会自动执行 reblance,使得 consumer 对 partition 的消费再次平衡。以下导致再平衡:
- 组订阅 topic 数变更
- topic partition 数变更
- consumer 成员变更
- consumer 加入群组或者离开群组的时候
- consumer 被检测为崩溃的时候
新版本之后,通过延迟进入 PreparingRebalance 状态减少 reblance 次数;
broker 消息存储
Kafka 的消息以二进制的方式紧凑地存储,节省了很大空间 此外消息存在 ByteBuffer 而不是堆,这样 broker 进程挂掉时,数据不会丢失,同时避免了 gc 问题 通过零拷贝和顺序寻址,让消息存储和读取速度都非常快 处理 fetch 请求的时候通过 zero-copy 加快速度
Isr
Kafka 结合同步复制和异步复制,使用 ISR(与 Partition Leader 保持同步的 Replica 列表)的方式在确保数据不丢失和吞吐率之间做了平衡。Producer 只需把消息发送到 Partition Leader,Leader 将消息写入本地 Log。Follower 则从 Leader pull 数据。Follower 在收到该消息向 Leader 发送 ACK。一旦 Leader 收到了 ISR 中所有 Replica 的 ACK,该消息就被认为已经 commit 了,Leader 将增加 HW 并且向 Producer 发送 ACK。这样如果 leader 挂了,只要 Isr 中有一个 replica 存活,就不会丢数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- docker——数据卷(volume)概念及使用案例
- Fiddler抓包PC端微信小程序
- C语言基础知识
- Kibana相关问题及答案(2024)
- Linux 命令解释程序(shell)的模拟实现
- Visual SVN Server实战
- Elasticsearch 查询命令执行时,如何通过词项索引、词项字典、倒排表定位文档逻辑介绍
- 风速预测(五)基于Pytorch的EMD-CNN-LSTM模型
- 小程序 样式 WXSS
- 软件测试|好用的pycharm插件推荐(三)——Rainbow Brackets