图像分割与修复
图像分割的方法
(1)传统的图像分割方法
(2)基于深度学习的图像分割方法
传统的图像分割方法
(1)分水岭法
(2)GrabCut法
(3)MeanShift法
(4)背景扣除
分水岭法
?分水岭法原理?
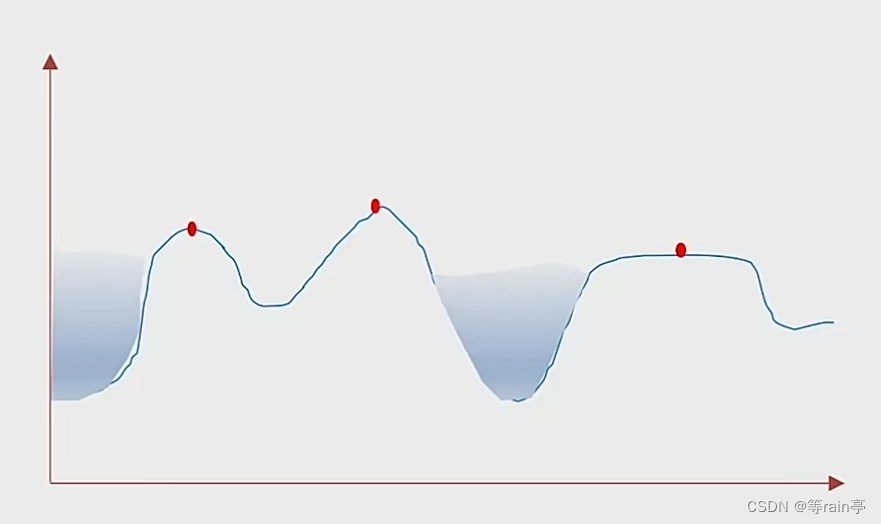
简单来说,如上图所示。图中有很多的沟壑,当用不同颜色的水灌到沟壑中时,在快灌满时会出现一个边界将两边分开。(每张图片有各种各样的像素,那不同的像素之间就形成沟壑)
分水岭法处理步骤
(1)标记背景
(2)标记前景
(3)标记未知域
(4)进行分割
分水岭法实战
分水岭法API
(1)watershed(img,masker)
(2)masker:前景,背景设置不同的值用于区分他们(如何获取前景,背景,和未知区域这个需要腐蚀膨胀的相关知识)
(3)前景可以通过腐蚀或距离变换得到,背景可以通过膨胀得到,未知区域可以使用背景减去前景
(4)距离变换API:distanceTransform(img,distanceType,maskSize)其中
distanceType:是测从非0值到0的距离? DIST_L1 DIST_L2??L1求绝对值 L2求勾股定理?; maskSize:就是扫描时kernel的大小 L1用3,L2用5
(7)连通域API:connectedComponents(img,connectivity,……)其中
connectivity:4,8(默认)4代表上下左右四个像素如果是一样的就代表是一个连通域,8在4的基础上加上了4个斜对角
?分水岭代码
import cv2
import numpy as np
# 获取背景
# 1,通过二值法得到黑白图片
# 2,通过心态学获取背景
img = cv2.imread('water_coins.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# THRESH_BINARY二进制阈值。把亮的处理成白色,暗的处理成黑色,超过100的就变成255,反之变为0。我们使用了_INV那就反过来
ret, thresh = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY_INV)
cv2.imshow('dst', thresh)
cv2.waitKey(0)
?可以得到图片,发现银币中间还是会出现黑色,但是我们不希望有黑色。

#改进前
ret, thresh = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY_INV)
#改进后
# cv2.THRESH_OTSU可以自适应阈值,将100写为0
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)??可以得到图片,发现银币中间没有黑色了,达到我们的目的。

?全部的代码
import cv2
import numpy as np
# 获取背景
# 1,通过二值法得到黑白图片
# 2,通过心态学获取背景(膨胀)
# 3.获取前景物体
img = cv2.imread('water_coins.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# THRESH_BINARY二进制阈值。把亮的处理成白色,暗的处理成黑色,超过100的就变成255,反之变为0。我们使用了_INV那就反过来
# ret, thresh = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY_INV)
# cv2.THRESH_OTSU可以自适应阈值,将100写为0
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 开运算(去噪)(真的有用!!!)
kernel = np.ones((3, 3), np.int8)
open = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# 膨胀
bg = cv2.dilate(open, kernel, iterations=1)
# 获取前景
dist = cv2.distanceTransform(open, cv2.DIST_L2, 5)
ret, fg = cv2.threshold(dist, 0.7 * dist.max(), 255, cv2.THRESH_BINARY)
# 获取未知区域
fg = np.uint8(fg)
unknow = cv2.subtract(bg, fg)
# 创建连通域
ret, marker = cv2.connectedComponents(fg)
marker = marker + 1 # 将所有背景都设为1 前景不变
marker[unknow == 255] = 0
# 进行图像分割
result = cv2.watershed(img, marker) # 结果中边沿都是-1表示
img[result == -1] = [0, 0, 255]
cv2.imshow('img', img)
cv2.imshow('bg', bg)
cv2.imshow('fg', fg)
cv2.imshow('unknow', unknow)
cv2.waitKey(0)

?GrabCut法
?GrabCut 原理
(1)用户指定前景区域,剩下的是背景区域
(2)用户可以明确指出某些地方为前景或背景
(3)GrabCut采用分段迭代的方法分析前景物体形成模型树
(4)最后根据权重决定某个像素是前景还是背景
GrabCut 实战
(1)主体结构(定义接口,成员变量)
(2)鼠标事件的处理
(3)调用GrabCut实现前景和背景的分离
GrabCut API
grabCut(img,mask,rect,bgdModel,fgdModel,iterator,mode)
mask:生成的掩码? ?BGD背景0? FGD前景1? PD_BGD可能是背景2? ?PR_FGD可能是前景3
rect: 检测区域
bgdModel: np.float64 type zero arrays of size (1,65)?
fgdModel:?np.float64 type zero arrays of size (1,65)
mode: GC_INIT_WITH_RECT? ? ? GC_INIT_WITH_MASK(第一次使用前一个,第二次使用后面的)
GrabCut实战代码?
(1)主体结构的搭建
import cv2
import numpy as np
class App:
def onmouse(self, event, x, y, flags, param): # 对于鼠标事件的监听
print("onmouse")
def run(self): # 主体函数
print("run……")
cv2.namedWindow('input')
cv2.setMouseCallback('input', self.onmouse)
img = cv2.imread('lena.png')
cv2.imshow('input', img)
cv2.waitKey(0)
App().run()(2)添加鼠标事件
def onmouse(self, event, x, y, flags, param): # 对于鼠标事件的监听
# 主要要实现的三个功能(左键的按下,移动和抬起)
if (event == cv2.EVENT_LBUTTONDOWN):
self.flag_ract = True
self.startX = x
self.startY = y
print("LBUTTONDOWN")
elif (event == cv2.EVENT_LBUTTONUP):
self.flag_ract = False
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(0, 0, 255),
3)
print("LBUTTONUP")
elif (event == cv2.EVENT_MOUSEMOVE):
if self.flag_ract == True:
self.img = self.img2.copy()
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(255, 0, 0),
3)
print("MOUSEMOVE")self.img = cv2.imread('lena.png')
self.img2 = self.img.copy()
while (1):
cv2.imshow('input', self.img)
k = cv2.waitKey(100)
if (k == 27):
break(3)?调用GrabCut实现前景和背景的分离(总)
import cv2
import numpy as np
class App:
flag_ract = False
startX = 0
startY = 0
rect = (0, 0, 0, 0)
def onmouse(self, event, x, y, flags, param): # 对于鼠标事件的监听
# 主要要实现的三个功能(左键的按下,移动和抬起)
if (event == cv2.EVENT_LBUTTONDOWN):
self.flag_ract = True
self.startX = x
self.startY = y
print("LBUTTONDOWN")
elif (event == cv2.EVENT_LBUTTONUP):
self.flag_ract = False
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(0, 0, 255),
3)
self.rect = (min(self.startX, x), min(self.startY, y),
abs(self.startX - x), abs(self.startY - y))
print("LBUTTONUP")
elif (event == cv2.EVENT_MOUSEMOVE):
if self.flag_ract == True:
self.img = self.img2.copy()
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(255, 0, 0),
3)
print("MOUSEMOVE")
print("onmouse")
def run(self): # 主体函数
print("run……")
cv2.namedWindow('input')
cv2.setMouseCallback('input', self.onmouse)
self.img = cv2.imread('lena.png')
self.img2 = self.img.copy()
self.mask = np.zeros(self.img.shape[:2], dtype=np.uint8)
self.output = np.zeros(self.img.shape, np.uint8)
while (1):
cv2.imshow('input', self.img)
cv2.imshow('output', self.output)
k = cv2.waitKey(100)
if (k == 27):
break
# 进行分离
if k == ord('g'):
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
cv2.grabCut(self.img2, self.mask, self.rect,
bgdModel, fgdModel,
1,
cv2.GC_INIT_WITH_RECT)
# 分离后需要把截取的全景取出来
# 原始图像与上一个掩码 掩码需要的是最大值ff
mask2 = np.where((self.mask == 1) | (self.mask == 3), 255, 0).astype('uint8')
self.output = cv2.bitwise_and(self.img2, self.img2, mask=mask2)
App().run()
MeanShift法
?MeanShift 图像分割原理
(1)该方法并不是用于图像分割的,而是在彩色层面的平滑滤波
(2)会中和和色彩分布相近的颜色,平滑色彩细节,侵蚀掉面积较小的颜色区域
(3)以图像上让任意一点p为圆心,半径为sp,色彩幅值为sr进行不断的迭代
MeanShift 图像分割实战
MeanShift 的API
pyrMeanShiftFiltering(img,sp,sr,maxlevel=1,termcrit=TermCriteria……)
sp:半径
sr:色彩幅值
MeanShift 的实战
import cv2
import numpy as np
img = cv2.imread('flower.png')
mean_img = cv2.pyrMeanShiftFiltering(img, sp=20, sr=30)
canny_img = cv2.Canny(mean_img, 150, 300)
contours, hierarchy = cv2.findContours(canny_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (255, 0, 0), 2)
cv2.imshow('img', img)
cv2.imshow('mean_img', mean_img)
cv2.imshow('canny_img', canny_img)
cv2.waitKey(0)



视频前后背景分离
?视频背景扣除原理
(1)视频是有一组连续的帧组成的
(2)帧与帧之间关系密切(GOP)
(3)在GOP中,背景几乎是不变的
MOG去背景
MOG去背景的API
createBacgroundSubtractorMOG( history(默认值200),nmixtures(高斯范围值,默认5),backgroundRatio(背景比率,默认为0.7),noiseSigma(默认0,自动降噪)
MOG去背景的实战代码
import cv2
import numpy as np
cap = cv2.VideoCapture('vtest.avi')
mog = cv2.bgsegm.createBackgroundSubtractorMOG()
while (True):
ret, frame = cap.read()
fgmask = mog.apply(frame)
cv2.imshow('img', fgmask)
k = cv2.waitKey(30)
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
MOG2去背景?
MOG2去背景优缺点
优点:同MOG类似,不过对亮度产生的阴影有更好的识别
缺点:前后景分离时会产生很多噪点
MOG2去背景API
createBacgroundSubtractorMOG2( history(默认值500),……detecShadow(是否检测阴影,True))
MOG2去背景实战代码
import cv2
import numpy as np
cap = cv2.VideoCapture('vtest.avi')
# 好处,可以计算出阴影部分
# 缺点,会产生很多噪点
mog = cv2.createBackgroundSubtractorMOG2()
while (True):
ret, frame = cap.read()
fgmask = mog.apply(frame)
cv2.imshow('img', fgmask)
k = cv2.waitKey(30)
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
GMG去背景
GMG去背景优缺点
优点:静态背景图像估计和每个像素的贝叶斯分割抗噪性更强
缺点:默认值帧数很大,需要等待较长时间
MOG2去背景API
createBacgroundSubtractorGMG(initializaFranmes(初始帧数 120))
MOG2去背景实战代码
import cv2
import numpy as np
cap = cv2.VideoCapture('vtest.avi')
# 好处,可以算出阴影部分,同时减少噪点
# 缺点,如果采用默认值,开始很长时间没有任何显示
# 解决方法,调整初始参考帧数量
mog = cv2.bgsegm.createBackgroundSubtractorGMG(10) # 这个就是参考帧数量
while (True):
ret, frame = cap.read()
fgmask = mog.apply(frame)
cv2.imshow('img', fgmask)
k = cv2.waitKey(30)
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
图像修复实战
?
图像修复相关原理
图像修复API
inpaint(img,mask,inpaintRadius,flags)
img:原始图像
mask:与原始图像大小相同的黑底白色的残缺位置的图片(可以自己制作出来)
inpaintRadius:每个破损的点会画一个半径,根据半径内的值计算出破损区域的值并填入
flags:INPAINT_NS , INPAINT_TELEA
图像修复实战代码
import cv2
import numpy as np
img = cv2.imread('inpaint.png')
mask = cv2.imread('inpaint_mask.png', 0) # 0 使其变成8位
dst = cv2.inpaint(img, mask, 5, cv2.INPAINT_TELEA)
cv2.imshow('img', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)
原图 处理后的图
处理后的图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码随想录|贪心day2
- 布隆过滤器
- Axure的安装及界面基本功能介绍
- AI大模型引领未来智慧科研暨ChatGPT在地学、GIS、气象、农业、生态、环境等领域中的高级应用
- 【docker实战】安装tomcat并连接mysql数据库
- 微生态守护:新生儿益生菌补充的悉心呵护
- Zookeeper-Zookeeper应用场景实战
- 软件测试十大必问面试题(附答案和解析)
- U8 内嵌.Net UserControl,winform挂菜单
- Python数据处理048:Python读写pkl文件