基于YOLOv5全系列参数模型【n/s/m/l/x】开发构建道路交通场景下CCTSDB2021交通标识检测识别系统
交通标志检测是交通标志识别系统中的一项重要任务。与其他国家的交通标志相比,中国的交通标志有其独特的特点。卷积神经网络(CNN)在计算机视觉任务中取得了突破性进展,在交通标志分类方面取得了巨大的成功。CCTSDB 数据集是由长沙理工大学的相关学者及团队制作而成的,其有交通标志样本图片有近 20000 张,共含交通标志近 40000 个,但目前只公开了其中的 10000 张图片,标注了常见的指示标志、禁令标志及警告标志三大类交通标志。随着时间的更迭有了不同的版本数据集,本文的主要目的就是想要基于yolov5来开发构建CCTSDB2021数据集上的目标检测识别系统,首先看下实例效果:
?
在CCTSDB2021数据集中,训练集和正样本测试集中有17856幅图像。图像中的交通标志根据其含义分为强制性、禁止性和警示性。共有16356个训练集图像,编号为00000-18991。正样本测试集有1500张图像,编号为18992-20491。“XML”压缩包存储训练集和正样本测试集的XML格式注释文件。“train_img”压缩包存储训练集图像。“train_labels”压缩包存储训练集的TXT格式注释文件。“test_img”压缩包存储正样本测试集图像。“基于天气和环境的分类”压缩包存储了根据天气和照明条件分类的正样本测试集的XML格式注释文件。“基于交通标志大小的分类”压缩包存储了根据图像中交通标志大小分类的正样本测试集的XML格式注释文件。“负片样本”包含500张负片样本图像。
本文是选择的是YOLOv5算法模型来完成本文项目的开发构建。相较于前两代的算法模型,YOLOv5可谓是集大成者,达到了SOTA的水平,下面简单对v3-v5系列模型的演变进行简单介绍总结方便对比分析学习:
【YOLOv3】
YOLOv3(You Only Look Once version 3)是一种基于深度学习的快速目标检测算法,由Joseph Redmon等人于2018年提出。它的核心技术原理和亮点如下:
技术原理:
YOLOv3采用单个神经网络模型来完成目标检测任务。与传统的目标检测方法不同,YOLOv3将目标检测问题转化为一个回归问题,通过卷积神经网络输出图像中存在的目标的边界框坐标和类别概率。
YOLOv3使用Darknet-53作为骨干网络,用来提取图像特征。检测头(detection head)负责将提取的特征映射到目标边界框和类别预测。
亮点:
YOLOv3在保持较高的检测精度的同时,能够实现非常快的检测速度。相较于一些基于候选区域的目标检测算法(如Faster R-CNN、SSD等),YOLOv3具有更高的实时性能。
YOLOv3对小目标和密集目标的检测效果较好,同时在大目标的检测精度上也有不错的表现。
YOLOv3具有较好的通用性和适应性,适用于各种目标检测任务,包括车辆检测、行人检测等。
【YOLOv4】
YOLOv4是一种实时目标检测模型,它在速度和准确度上都有显著的提高。相比于其前一代模型YOLOv3,YOLOv4在保持较高的检测精度的同时,还提高了检测速度。这主要得益于其采用的CSPDarknet53网络结构,主要有三个方面的优点:增强CNN的学习能力,使得在轻量化的同时保持准确性;降低计算瓶颈;降低内存成本。YOLOv4的目标检测策略采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。这种方法不需要额外再设计一个区域提议网络(RPN),从而减少了训练的负担。然而,尽管YOLOv4在许多方面都表现出色,但它仍然存在一些不足。例如,小目标检测效果较差。此外,当需要在资源受限的设备上部署像YOLOv4这样的大模型时,模型压缩是研究人员重新调整较大模型所需资源消耗的有用工具。
优点:
速度:YOLOv4 保持了 YOLO 算法一贯的实时性,能够在检测速度和精度之间实现良好的平衡。
精度:YOLOv4 采用了 CSPDarknet 和 PANet 两种先进的技术,提高了检测精度,特别是在检测小型物体方面有显著提升。
通用性:YOLOv4 适用于多种任务,如行人检测、车辆检测、人脸检测等,具有较高的通用性。
模块化设计:YOLOv4 中的组件可以方便地更换和扩展,便于进一步优化和适应不同场景。
缺点:
内存占用:YOLOv4 模型参数较多,因此需要较大的内存来存储和运行模型,这对于部分硬件设备来说可能是一个限制因素。
训练成本:YOLOv4 模型需要大量的训练数据和计算资源才能达到理想的性能,这可能导致训练成本较高。
精确度与速度的权衡:虽然 YOLOv4 在速度和精度之间取得了较好的平衡,但在极端情况下,例如检测高速移动的物体或复杂背景下的物体时,性能可能会受到影响。
误检和漏检:由于 YOLOv4 采用单一网络对整个图像进行预测,可能会导致一些误检和漏检现象。
【YOLOv5】
YOLOv5是一种快速、准确的目标检测模型,由Glen Darby于2020年提出。相较于前两代模型,YOLOv5集成了众多的tricks达到了性能的SOTA:
技术原理:
YOLOv5同样采用单个神经网络模型来完成目标检测任务,但采用了新的神经网络架构,融合了领先的轻量级模型设计理念。YOLOv5使用较小的骨干网络和新的检测头设计,以实现更快的推断速度,并在不降低精度的前提下提高目标检测的准确性。
亮点:
YOLOv5在模型结构上进行了改进,引入了更先进的轻量级网络架构,因此在速度和精度上都有所提升。
YOLOv5支持更灵活的模型大小和预训练选项,可以根据任务需求选择不同大小的模型,同时提供丰富的数据增强扩展、模型集成等方法来提高检测精度。YOLOv5通过使用更简洁的代码实现,提高了模型的易用性和可扩展性。
训练数据配置文件如下:
# Dataset
path: ./dataset
train:
- images/train
val:
- images/test
test:
- images/test
# Classes
names:
0: mandatory
1: prohibitory
2: warning
接下来看下数据集:


实验截止目前,本文将YOLOv5系列五款不同参数量级的模型均进行了开发评测,接下来看下模型详情:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv5 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov5
# Parameters
nc: 3 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 1024]
l: [1.00, 1.00, 1024]
x: [1.33, 1.25, 1024]
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
]在实验训练开发阶段,所有的模型均保持完全相同的参数设置,等待训练完成后,来整体进行评测对比分析。
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能.F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。

【loss曲线】

【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。

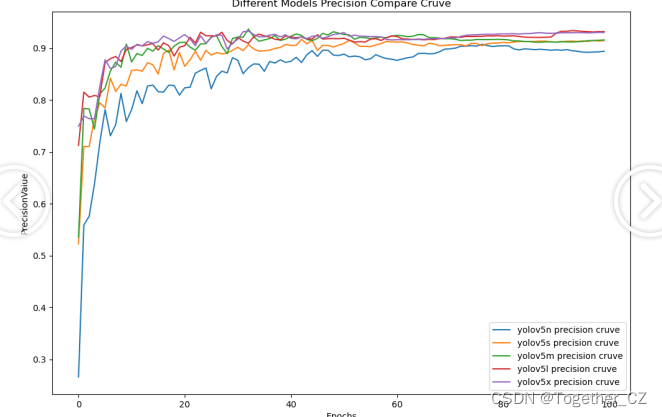
整体对比分析不难发现:纵向对比来看n系列的模型性能最差,s系列次之,而m、l和x三个系列的模型则达到了相近的水平,结合推理速度来考虑的话实际项目中,如果算力受限的话更加推荐使用s系列的模型,反之则更加倾向于优先选择使用m系列的模型。
这里以m系列模型为例看下结果详情:
【Batch实例】

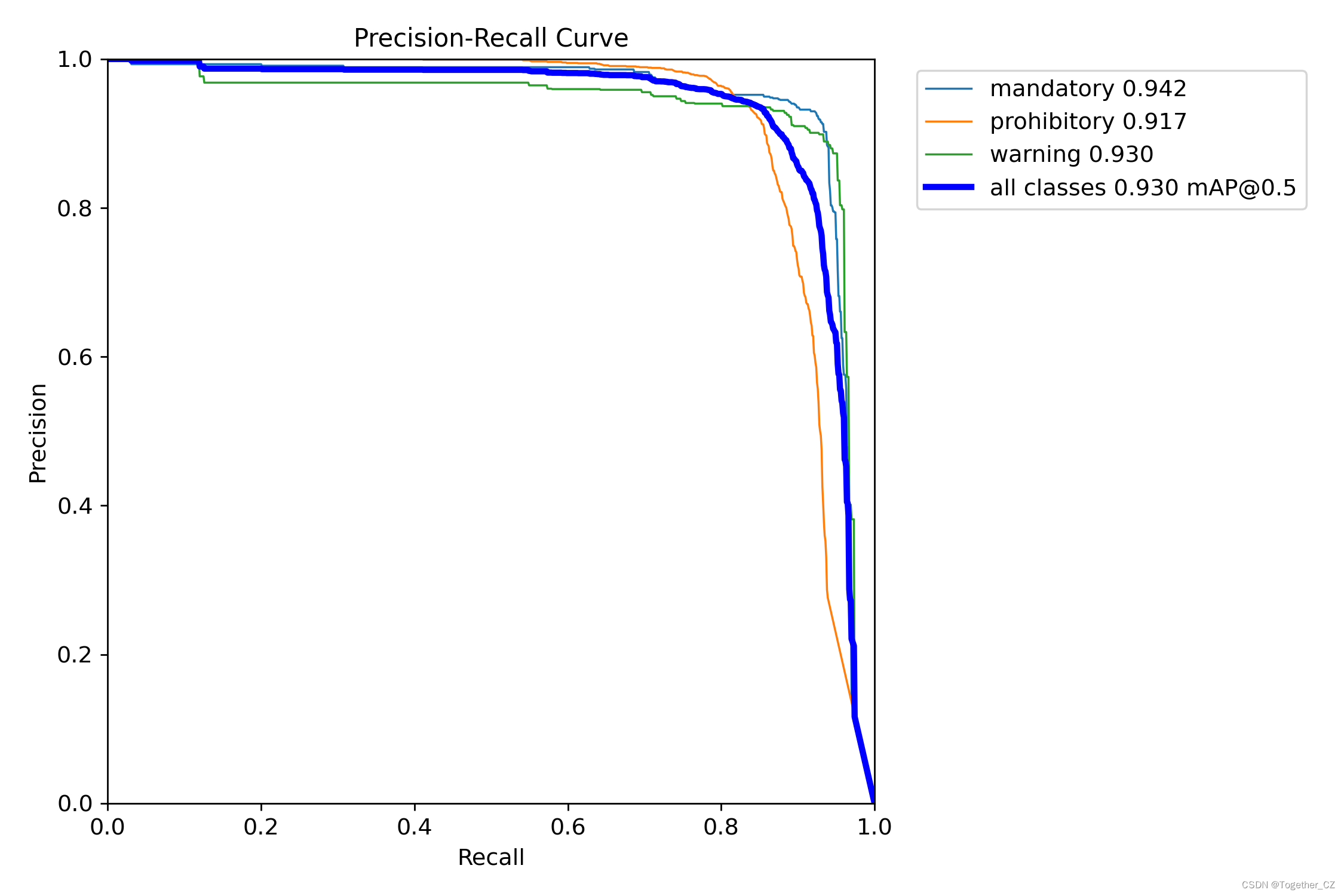
【PR曲线】
【数据分布可视化】

【混淆矩阵】

【离线推理实例】

因为本身数据量比较大,所以完整的实验耗费的资源还是很大的,感兴趣的话可以以轻量级的模型比如n或者s为例进行实验即可。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 04 HAL库下使用定时器产生一个中断
- 第十二讲_ArkUI相对布局(RelativeContainer)
- Java:将字符串重复多次串接起来输出
- 【PyTorch】记一次卷积神经网络优化过程
- 基于ssm的校园跑腿系统的设计与实现(源码+开题)
- 自定义指令Custom Directives
- ssm/php/node/python基于web的网络在线考试系统
- 华清远见作业第十五天
- 【XR806开发板试用】XR806无线OTA功能实验
- 中国人民大学与加拿大女王大学金融硕士项目:努力经营当下,以致未来明朗