爬虫系列--爬取B站小潮院长的作品列表
爬虫系列--爬取B站小潮院长的作品列表
1 知识小课堂
1.1 爬虫

-
Python爬虫是一种用于自动抓取互联网数据的程序。它们通过模拟用户浏览网页的行为,自动解析网页HTML代码并提取所需的数据。Python爬虫在数据挖掘、数据分析、API开发等领域有广泛的应用。
-
Python爬虫主要通过HTTP请求来获取网页内容,常见的库包括requests、BeautifulSoup和Scrapy等。其中,requests库用于发送HTTP请求,BeautifulSoup用于解析HTML代码,Scrapy则是一个完整的爬虫框架,提供了丰富的功能和工具。
-
Python爬虫的基本流程包括目标网站分析、请求处理、数据提取、数据清洗和数据存储等步骤。在实现爬虫时,需要对目标网站进行分析,了解其结构、URL格式和数据存放位置等信息。然后,通过发送HTTP请求来获取网页内容,使用BeautifulSoup或正则表达式等技术来提取所需的数据。最后,将提取到的数据清洗、去重和存储到数据库中。
需要注意的是,Python爬虫的使用需要遵守相关法律法规和网站的使用协议,尊重网站的数据安全和隐私保护,避免对目标网站造成不必要的负担或干扰。同时,在使用Python爬虫时,也需要考虑到数据的质量和可靠性,采取相应的策略和技术来确保数据的一致性和准确性。
1.2 json简介
-
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于ECMAScript(欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得JSON成为理想的数据交换语言,并有效地提升网络传输效率。
-
JSON对象是一个无序的“名称/值”对集合,以“{”(左括号)开始,“}”(右括号)结束。每个“名称”后跟一个“:”(冒号);“名称/值”对之间使用“,”(逗号)分隔。
-
JSON数组是一个有序的“值”集合,以“[”(左括号)开始,“]”(右括号)结束,值之间使用“,”(逗号)分隔。JSON对象、JSON数组可以嵌套。
-
JSON的语法规则包括:
- 数据结构:JSON是键值对的数据结构,每个键和值之间用冒号(:)分隔,不同的键值对之间用逗号(,)分隔。
- 键:键是字符串,必须用双引号(" ")括起来。
- 值:值可以是以下类型:数字、字符串、布尔值、null、数组或对象。
- 数组:数组是由一组有序的值组成,值之间用逗号分隔,并用方括号([])括起来。
- 对象:对象是由一组键值对组成,键和值之间用冒号分隔,不同的键值对之间用逗号分隔。
- 转义字符:如果字符串内部包含双引号,则使用反斜杠(\)进行转义。
- 注释:JSON不支持注释,但可以通过控制台或某些工具进行格式化或美化输出。
JSON在许多领域都有广泛的应用,例如数据交换、配置文件、API请求等。它比XML更加轻量级,易于阅读和编写,也易于机器解析和生成。同时,由于其基于JavaScript语言规范,使得JSON成为Web开发中的重要组成部分。
2 爬取过程
2.1 简介
小潮院长,B站知名UP,粉丝破千万,bilibili 2022百大UP主、2022年度弹幕人气奖UP主、知名UP主
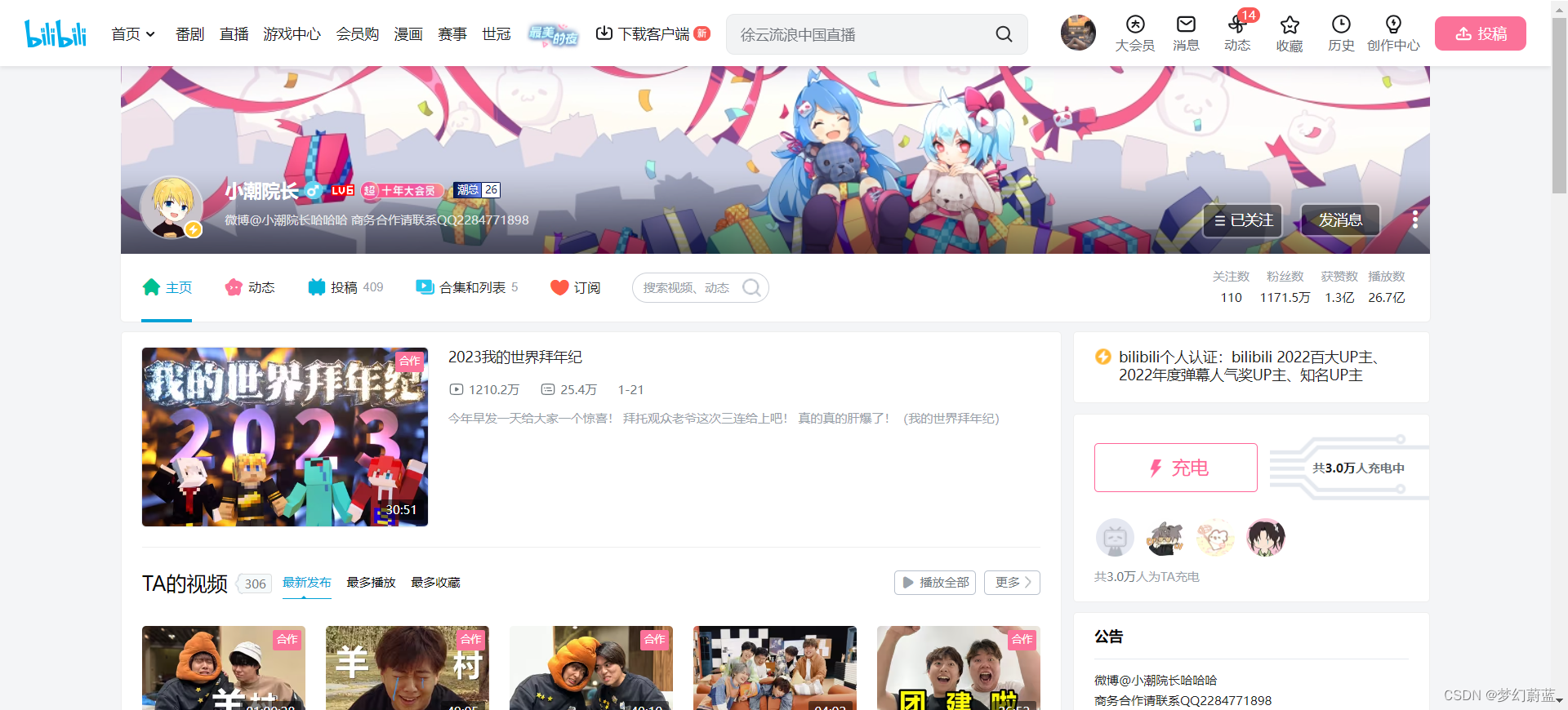
2.2 找到爬取的连接
打开:小潮院长主页
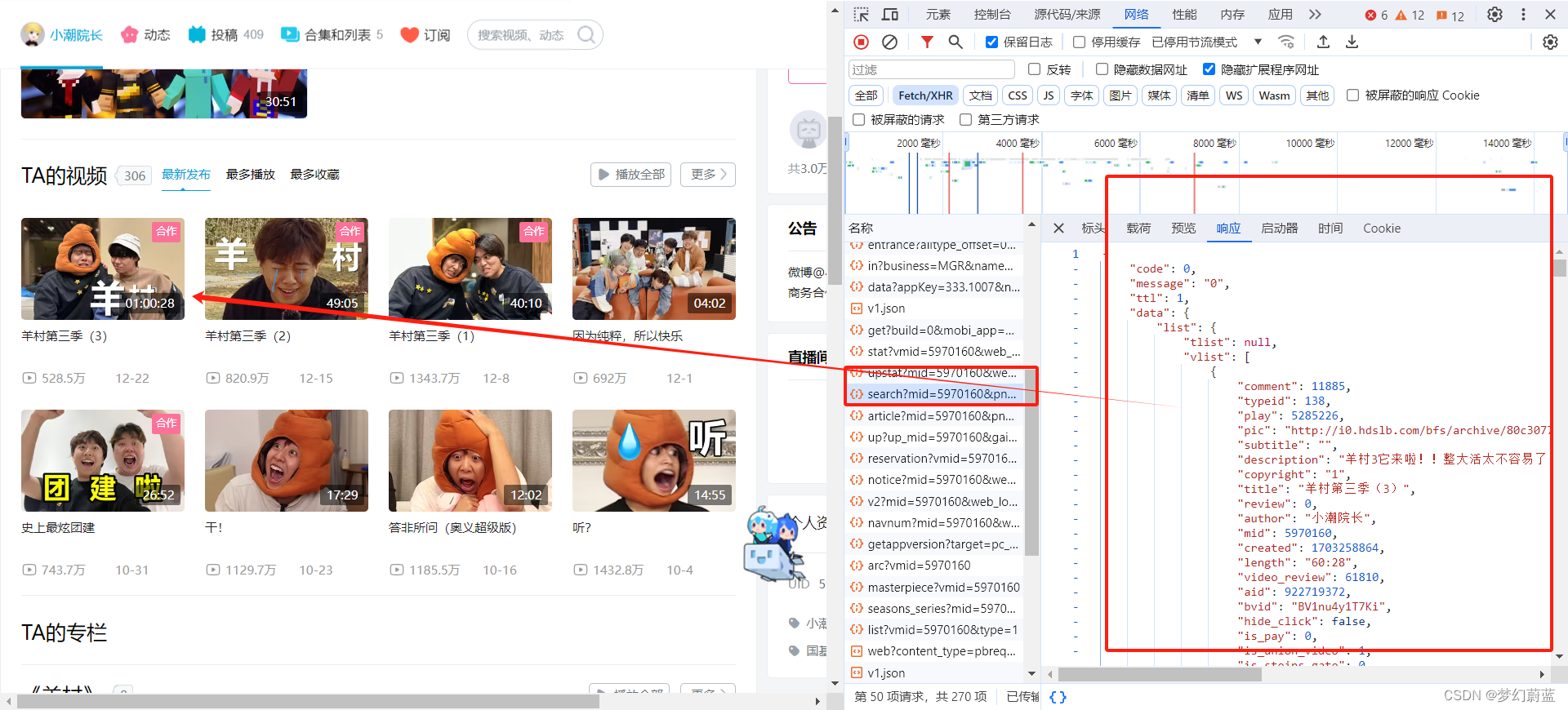
找个文件连接比较相近,因此打开看看,通过对比主页可知,二者相近。
https://api.bilibili.com/x/space/wbi/arc/search?mid=5970160&pn=1&ps=25&index=1&order=pubdate&order_avoided=true&platform=web&web_location=1550101&dm_img_list=[%7B%22x%22:2381,%22y%22:913,%22z%22:0,%22timestamp%22:189,%22type%22:0%7D,%7B%22x%22:3531,%22y%22:2723,%22z%22:21,%22timestamp%22:452,%22type%22:0%7D]&dm_img_str=V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ&dm_cover_img_str=QU5HTEUgKEludGVsLCBJbnRlbChSKSBIRCBHcmFwaGljcyA2MzAgKDB4MDAwMDU5MUIpIERpcmVjdDNEMTEgdnNfNV8wIHBzXzVfMCwgRDNEMTEpR29vZ2xlIEluYy4gKEludGVsKQ&w_rid=ce10f44fa085afd94f87f8723a5d93b1&wts=1703590453
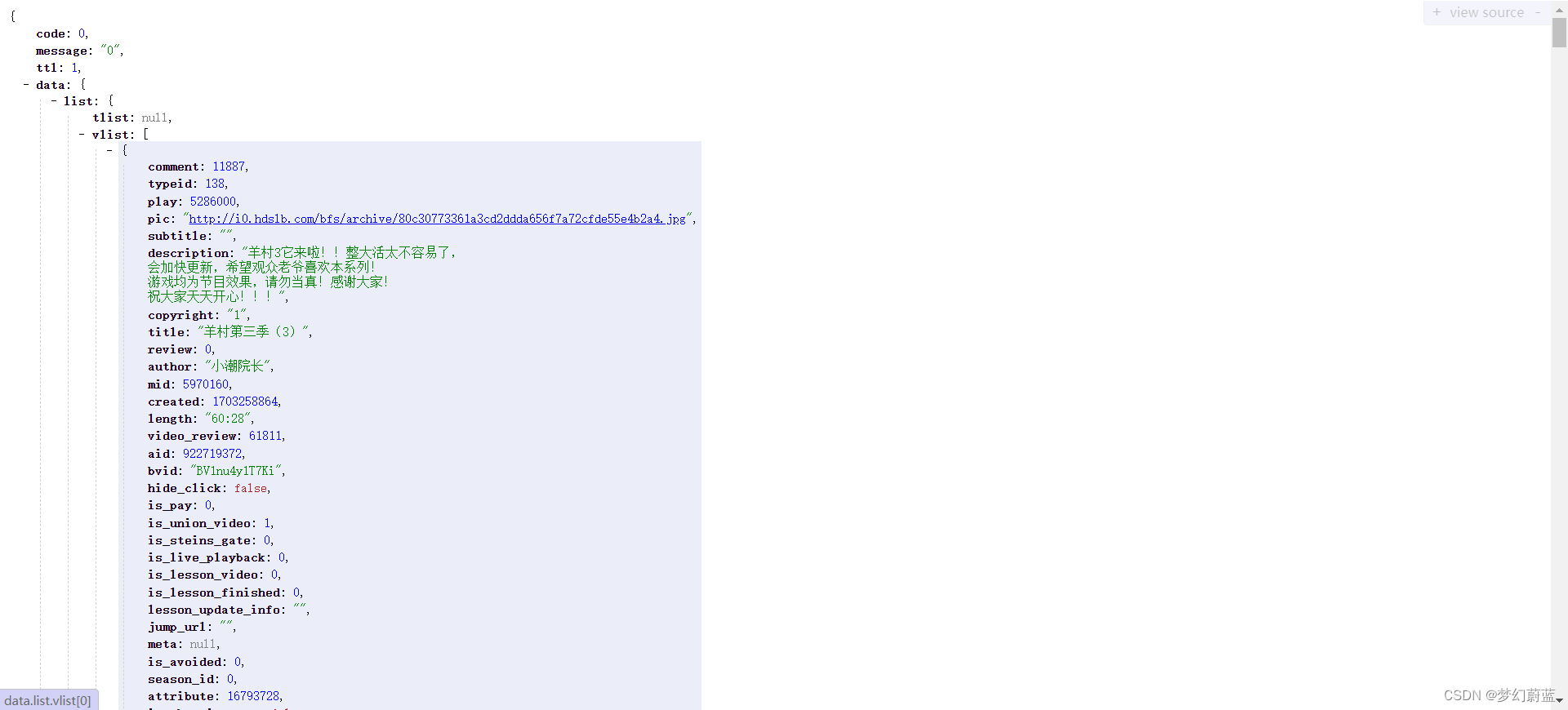
2.2 爬取json信息
import requests
import json
import time
import re
import datetime
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
url = 'https://api.bilibili.com/x/polymer/web-space/home/seasons_series?mid=5970160&page_num=1&page_size=10'
file = requests.get(url, headers=headers).json()
series_list = file['data']['items_lists']['series_list']
print(series_list)

2.3 循环爬取
for i in range(5):
dict = series_list[i]
meta = dict['meta']
archives = dict['archives']
recent_aids = dict['recent_aids']
name = meta['name']
print(name)
time.sleep(1)
for a in range(len(archives)):
arch = archives[a]
title = arch['title']
aid = arch['aid']
ctime = arch['ctime']
view = arch['stat']['view']
# view_new = num_to_chinese(view)
# timestape = time_date(ctime)
pic = arch['pic']
print('{} {} {} {}\n'.format(title,ctime, view,pic))
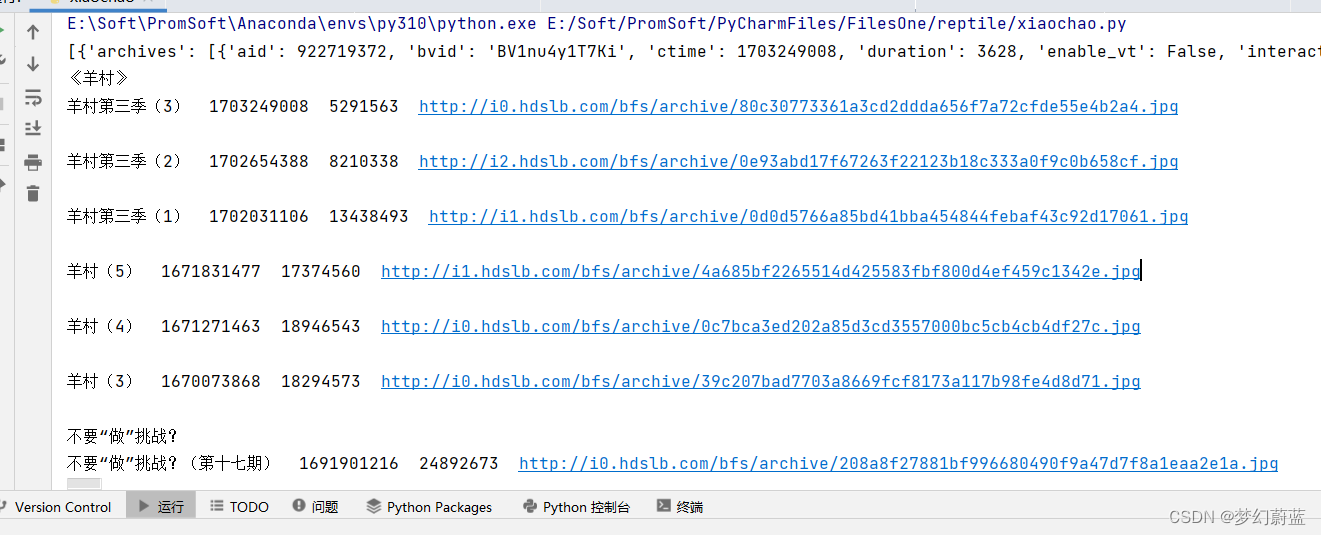
2.4 数据格式化
通过爬取发现,日期是时间戳,访问量也不是页面上看到的那样,因此需要格式化代码
封装两个函数即可,在需要的地方调用
# 转化为中文显示方式
def num_to_chinese(num):
num = (num/10000)
num_round = round(num,2)
num_new = str(num_round)+'万'
return num_new
# 时间戳转化为日期格式
def time_date(time):
# 假设你有一个时间戳,单位为秒
timestamp = time # 这是一个示例,你需要替换为你的实际时间戳
# 将时间戳转换为datetime对象
dt_object = datetime.datetime.fromtimestamp(timestamp)
# 将datetime对象格式化为所需的日期格式
# formatted_date = dt_object.strftime('%Y-%m-%d %H:%M:%S')
formatted_date = dt_object.strftime('%Y-%m-%d')
# print(formatted_date)
return formatted_date
再尝试代码输出:
是我们需要的样子了
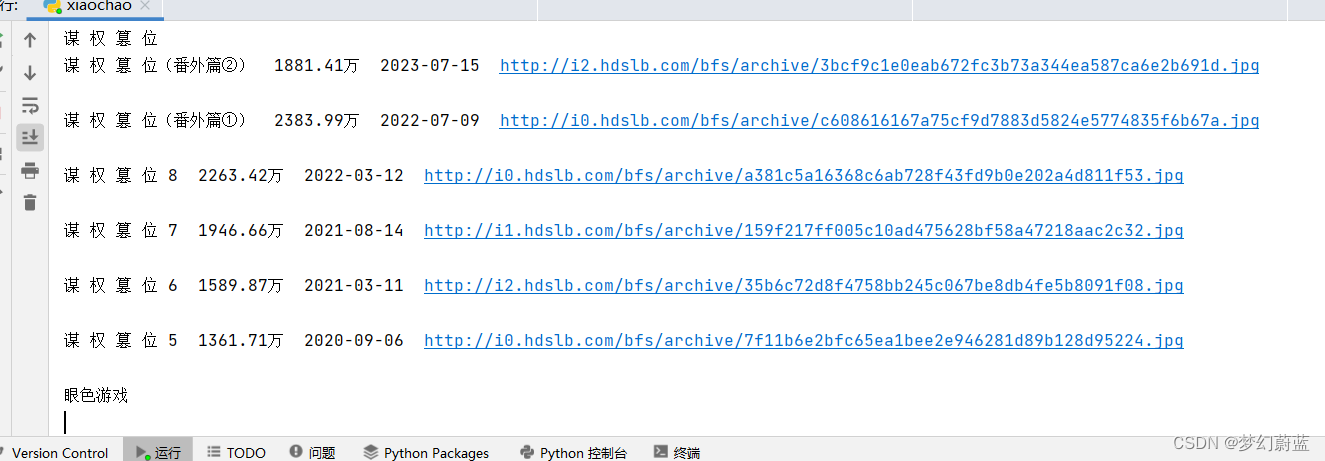
3 完整代码
import requests
import json
import time
import re
import datetime
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
url = 'https://api.bilibili.com/x/polymer/web-space/home/seasons_series?mid=5970160&page_num=1&page_size=10'
file = requests.get(url, headers=headers).json()
series_list = file['data']['items_lists']['series_list']
# 转化为中文显示方式
def num_to_chinese(num):
num = (num/10000)
num_round = round(num,2)
num_new = str(num_round)+'万'
return num_new
# 时间戳转化为日期格式
def time_date(time):
# 假设你有一个时间戳,单位为秒
timestamp = time # 这是一个示例,你需要替换为你的实际时间戳
# 将时间戳转换为datetime对象
dt_object = datetime.datetime.fromtimestamp(timestamp)
# 将datetime对象格式化为所需的日期格式
# formatted_date = dt_object.strftime('%Y-%m-%d %H:%M:%S')
formatted_date = dt_object.strftime('%Y-%m-%d')
# print(formatted_date)
return formatted_date
for i in range(5):
dict = series_list[i]
meta = dict['meta']
archives = dict['archives']
recent_aids = dict['recent_aids']
name = meta['name']
print(name)
time.sleep(1)
for a in range(len(archives)):
arch = archives[a]
title = arch['title']
aid = arch['aid']
ctime = arch['ctime']
view = arch['stat']['view']
view_new = num_to_chinese(view)
timestape = time_date(ctime)
pic = arch['pic']
print('{} {} {} {}\n'.format(title,view_new, timestape,pic))
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 新媒体营销的相关理论
- 1.8数算总复习PART2
- paddle 54 从PaddleClas2.5初始化模型用于迁移学习(LeViT、ReXNet、EfficientNet等)
- 使用Docker部署Apache Superset结合内网穿透实现远程访问本地服务
- 教师如何开发期末考试成绩的查询系统
- 探索SSL证书的应用场景,远不止网站,还有小程序、App Store等
- 分类预测 | Matlab实现CS-SVM布谷鸟算法优化支持向量机的数据分类预测
- Lunix的奇妙冒险————权限篇
- 《SPSS统计学基础与实证研究应用精解》视频讲解:SPSS运行环境设置
- 雪花算法生成ID【细糠】