go语言数组和切片
1. 数组Array
Golang Array和以往认知的数组有很大不同。
1. 数组:是同一种数据类型的固定长度的序列。
2. 数组定义:var a [len]int,比如:var a [5]int,数组长度必须是常量,且是类型的组成部分。一旦定义,长度不能变。
3. 长度是数组类型的一部分,因此,var a[5] int和var a[10]int是不同的类型。
4. 数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
for i := 0; i < len(a); i++ {
}
for index, v := range a {
}
5. 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
6. 数组是值类型,赋值和传参会复制整个数组,而不是指针。因此改变副本的值,不会改变本身的值。
7.支持 "=="、"!=" 操作符,因为内存总是被初始化过的。
8.指针数组 [n]*T,数组指针 *[n]T。
1.1. 数组初始化:
一维数组:
全局:
var arr0 [5]int = [5]int{1, 2, 3}
var arr1 = [5]int{1, 2, 3, 4, 5}
var arr2 = [...]int{1, 2, 3, 4, 5, 6}
var str = [5]string{3: "hello world", 4: "tom"}
局部:
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用索引号初始化元素。
d := [...]struct {
name string
age uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一行的逗号。
}
代码:
package main
import (
"fmt"
)
var arr0 [5]int = [5]int{1, 2, 3}
var arr1 = [5]int{1, 2, 3, 4, 5}
var arr2 = [...]int{1, 2, 3, 4, 5, 6}
var str = [5]string{3: "hello world", 4: "tom"}
func main() {
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用引号初始化元素。
d := [...]struct {
name string
age uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一行的逗号。
}
fmt.Println(arr0, arr1, arr2, str)
fmt.Println(a, b, c, d)
}
输出结果:
[1 2 3 0 0] [1 2 3 4 5] [1 2 3 4 5 6] [ hello world tom]
[1 2 0] [1 2 3 4] [0 0 100 0 200] [{user1 10} {user2 20}]
多维数组
全局
var arr0 [5][3]int
var arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
局部:
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。
代码:
package main
import (
"fmt"
)
var arr0 [5][3]int
var arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
func main() {
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。
fmt.Println(arr0, arr1)
fmt.Println(a, b)
}
输出结果:
[[0 0 0] [0 0 0] [0 0 0] [0 0 0] [0 0 0]] [[1 2 3] [7 8 9]]
[[1 2 3] [4 5 6]] [[1 1] [2 2] [3 3]]
值拷贝行为会造成性能问题,通常会建议使用 slice,或数组指针。
package main
import (
"fmt"
)
func test(x [2]int) {
fmt.Printf("x: %p\n", &x)
x[1] = 1000
}
func main() {
a := [2]int{}
fmt.Printf("a: %p\n", &a)
test(a)
fmt.Println(a)
}
输出结果:
a: 0xc42007c010
x: 0xc42007c030
[0 0]
内置函数 len 和 cap 都返回数组长度 (元素数量)。
package main
func main() {
a := [2]int{}
println(len(a), cap(a))
}
输出结果:
2 2
多维数组遍历:
package main
import (
"fmt"
)
func main() {
var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
for k1, v1 := range f {
for k2, v2 := range v1 {
fmt.Printf("(%d,%d)=%d ", k1, k2, v2)
}
fmt.Println()
}
}
输出结果:
(0,0)=1 (0,1)=2 (0,2)=3
(1,0)=7 (1,1)=8 (1,2)=9
1.2. 数组拷贝和传参
package main
import "fmt"
func printArr(arr *[5]int) {
arr[0] = 10
for i, v := range arr {
fmt.Println(i, v)
}
}
func main() {
var arr1 [5]int
printArr(&arr1)
fmt.Println(arr1)
arr2 := [...]int{2, 4, 6, 8, 10}
printArr(&arr2)
fmt.Println(arr2)
}
1.3. 数组练习
求数组所有元素之和
package main
import (
"fmt"
"math/rand"
"time"
)
// 求元素和
func sumArr(a [10]int) int {
var sum int = 0
for i := 0; i < len(a); i++ {
sum += a[i]
}
return sum
}
func main() {
// 若想做一个真正的随机数,要种子
// seed()种子默认是1
//rand.Seed(1)
rand.Seed(time.Now().Unix())
var b [10]int
for i := 0; i < len(b); i++ {
// 产生一个0到1000随机数
b[i] = rand.Intn(1000)
}
sum := sumArr(b)
fmt.Printf("sum=%d\n", sum)
}
找出数组中和为给定值的两个元素的下标,例如数组[1,3,5,8,7],找出两个元素之和等于8的下标分别是(0,4)和(1,2)
package main
import "fmt"
//? 找出数组中和为给定值的两个元素的下标,例如数组[1,3,5,8,7],
// 找出两个元素之和等于8的下标分别是(0,4)和(1,2)
// 求元素和,是给定的值
func myTest(a [5]int, target int) {
// 遍历数组
for i := 0; i < len(a); i++ {
other := target - a[i]
// 继续遍历
for j := i + 1; j < len(a); j++ {
if a[j] == other {
fmt.Printf("(%d,%d)\n", i, j)
}
}
}
}
func main() {
b := [5]int{1, 3, 5, 8, 7}
myTest(b, 8)
}2. 切片Slice
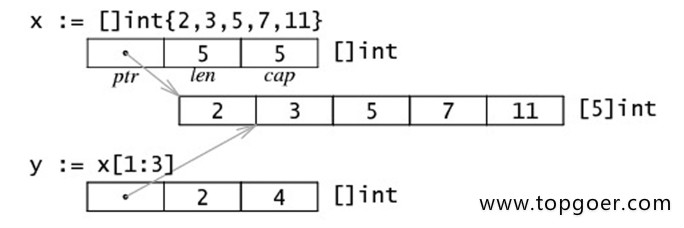
需要说明,slice 并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案。
1. 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。
2. 切片的长度可以改变,因此,切片是一个可变的数组。
3. 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。
4. cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。
5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。
6. 如果 slice == nil,那么 len、cap 结果都等于 0。
2.1. 创建切片的各种方式
package main
import "fmt"
func main() {
//1.声明切片
var s1 []int
if s1 == nil {
fmt.Println("是空")
} else {
fmt.Println("不是空")
}
// 2.:=
s2 := []int{}
// 3.make()
var s3 []int = make([]int, 0)
fmt.Println(s1, s2, s3)
// 4.初始化赋值
var s4 []int = make([]int, 0, 0)
fmt.Println(s4)
s5 := []int{1, 2, 3}
fmt.Println(s5)
// 5.从数组切片
arr := [5]int{1, 2, 3, 4, 5}
var s6 []int
// 前包后不包
s6 = arr[1:4]
fmt.Println(s6)
}
2.2. 切片初始化
全局:
var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice0 []int = arr[start:end]
var slice1 []int = arr[:end]
var slice2 []int = arr[start:]
var slice3 []int = arr[:]
var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素
局部:
arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
slice5 := arr[start:end]
slice6 := arr[:end]
slice7 := arr[start:]
slice8 := arr[:]
slice9 := arr[:len(arr)-1] //去掉切片的最后一个元素
代码:
package main
import (
"fmt"
)
var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice0 []int = arr[2:8]
var slice1 []int = arr[0:6] //可以简写为 var slice []int = arr[:end]
var slice2 []int = arr[5:10] //可以简写为 var slice[]int = arr[start:]
var slice3 []int = arr[0:len(arr)] //var slice []int = arr[:]
var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素
func main() {
fmt.Printf("全局变量:arr %v\n", arr)
fmt.Printf("全局变量:slice0 %v\n", slice0)
fmt.Printf("全局变量:slice1 %v\n", slice1)
fmt.Printf("全局变量:slice2 %v\n", slice2)
fmt.Printf("全局变量:slice3 %v\n", slice3)
fmt.Printf("全局变量:slice4 %v\n", slice4)
fmt.Printf("-----------------------------------\n")
arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
slice5 := arr[2:8]
slice6 := arr[0:6] //可以简写为 slice := arr[:end]
slice7 := arr[5:10] //可以简写为 slice := arr[start:]
slice8 := arr[0:len(arr)] //slice := arr[:]
slice9 := arr[:len(arr)-1] //去掉切片的最后一个元素
fmt.Printf("局部变量: arr2 %v\n", arr2)
fmt.Printf("局部变量: slice5 %v\n", slice5)
fmt.Printf("局部变量: slice6 %v\n", slice6)
fmt.Printf("局部变量: slice7 %v\n", slice7)
fmt.Printf("局部变量: slice8 %v\n", slice8)
fmt.Printf("局部变量: slice9 %v\n", slice9)
}
输出结果:
全局变量:arr [0 1 2 3 4 5 6 7 8 9]
全局变量:slice0 [2 3 4 5 6 7]
全局变量:slice1 [0 1 2 3 4 5]
全局变量:slice2 [5 6 7 8 9]
全局变量:slice3 [0 1 2 3 4 5 6 7 8 9]
全局变量:slice4 [0 1 2 3 4 5 6 7 8]
-----------------------------------
局部变量: arr2 [9 8 7 6 5 4 3 2 1 0]
局部变量: slice5 [2 3 4 5 6 7]
局部变量: slice6 [0 1 2 3 4 5]
局部变量: slice7 [5 6 7 8 9]
局部变量: slice8 [0 1 2 3 4 5 6 7 8 9]
局部变量: slice9 [0 1 2 3 4 5 6 7 8]
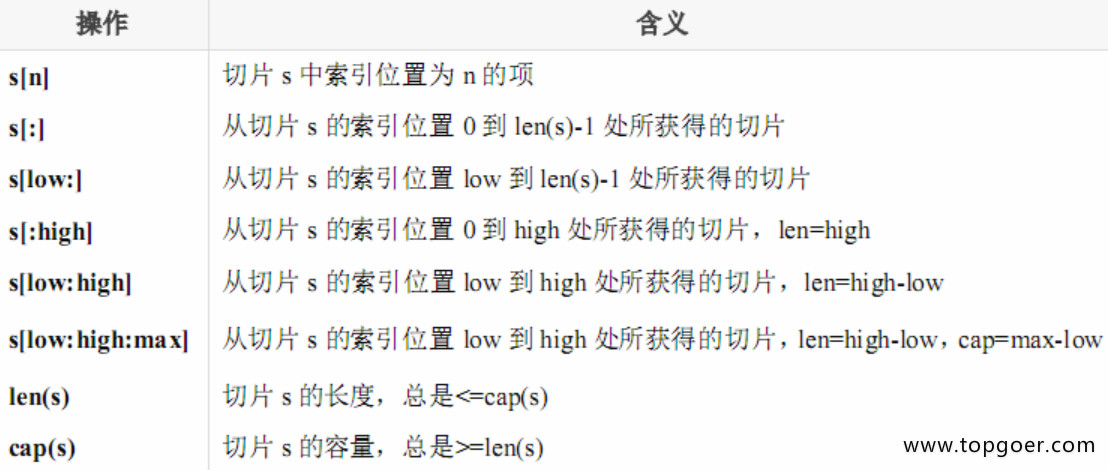
2.3. 通过make来创建切片
var slice []type = make([]type, len)
slice := make([]type, len)
slice := make([]type, len, cap)
代码:
package main
import (
"fmt"
)
var slice0 []int = make([]int, 10)
var slice1 = make([]int, 10)
var slice2 = make([]int, 10, 10)
func main() {
fmt.Printf("make全局slice0 :%v\n", slice0)
fmt.Printf("make全局slice1 :%v\n", slice1)
fmt.Printf("make全局slice2 :%v\n", slice2)
fmt.Println("--------------------------------------")
slice3 := make([]int, 10)
slice4 := make([]int, 10)
slice5 := make([]int, 10, 10)
fmt.Printf("make局部slice3 :%v\n", slice3)
fmt.Printf("make局部slice4 :%v\n", slice4)
fmt.Printf("make局部slice5 :%v\n", slice5)
}
输出结果:
make全局slice0 :[0 0 0 0 0 0 0 0 0 0]
make全局slice1 :[0 0 0 0 0 0 0 0 0 0]
make全局slice2 :[0 0 0 0 0 0 0 0 0 0]
--------------------------------------
make局部slice3 :[0 0 0 0 0 0 0 0 0 0]
make局部slice4 :[0 0 0 0 0 0 0 0 0 0]
make局部slice5 :[0 0 0 0 0 0 0 0 0 0]
切片的内存布局
读写操作实际目标是底层数组,只需注意索引号的差别。
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 5}
s := data[2:4]
s[0] += 100
s[1] += 200
fmt.Println(s)
fmt.Println(data)
}
输出:
[102 203]
[0 1 102 203 4 5]
可直接创建 slice 对象,自动分配底层数组。
package main
import "fmt"
func main() {
s1 := []int{0, 1, 2, 3, 8: 100} // 通过初始化表达式构造,可使用索引号。
fmt.Println(s1, len(s1), cap(s1))
s2 := make([]int, 6, 8) // 使用 make 创建,指定 len 和 cap 值。
fmt.Println(s2, len(s2), cap(s2))
s3 := make([]int, 6) // 省略 cap,相当于 cap = len。
fmt.Println(s3, len(s3), cap(s3))
}
输出结果:
[0 1 2 3 0 0 0 0 100] 9 9
[0 0 0 0 0 0] 6 8
[0 0 0 0 0 0] 6 6
使用 make 动态创建slice,避免了数组必须用常量做长度的麻烦。还可用指针直接访问底层数组,退化成普通数组操作。
package main
import "fmt"
func main() {
s := []int{0, 1, 2, 3}
p := &s[2] // *int, 获取底层数组元素指针。
*p += 100
fmt.Println(s)
}
输出结果:
[0 1 102 3]
至于 [][]T,是指元素类型为 []T 。
package main
import (
"fmt"
)
func main() {
data := [][]int{
[]int{1, 2, 3},
[]int{100, 200},
[]int{11, 22, 33, 44},
}
fmt.Println(data)
}
输出结果:
[[1 2 3] [100 200] [11 22 33 44]]
可直接修改 struct array/slice 成员。
package main
import (
"fmt"
)
func main() {
d := [5]struct {
x int
}{}
s := d[:]
d[1].x = 10
s[2].x = 20
fmt.Println(d)
fmt.Printf("%p, %p\n", &d, &d[0])
}
输出结果:
[{0} {10} {20} {0} {0}]
0xc4200160f0, 0xc4200160f0
2.4. 用append内置函数操作切片(切片追加)
package main
import (
"fmt"
)
func main() {
var a = []int{1, 2, 3}
fmt.Printf("slice a : %v\n", a)
var b = []int{4, 5, 6}
fmt.Printf("slice b : %v\n", b)
c := append(a, b...)
fmt.Printf("slice c : %v\n", c)
d := append(c, 7)
fmt.Printf("slice d : %v\n", d)
e := append(d, 8, 9, 10)
fmt.Printf("slice e : %v\n", e)
}
输出结果:
slice a : [1 2 3]
slice b : [4 5 6]
slice c : [1 2 3 4 5 6]
slice d : [1 2 3 4 5 6 7]
slice e : [1 2 3 4 5 6 7 8 9 10]
append :向 slice 尾部添加数据,返回新的 slice 对象。
package main
import (
"fmt"
)
func main() {
s1 := make([]int, 0, 5)
fmt.Printf("%p\n", &s1)
s2 := append(s1, 1)
fmt.Printf("%p\n", &s2)
fmt.Println(s1, s2)
}
输出结果:
0xc42000a060
0xc42000a080
[] [1]
2.5. 超出原 slice.cap 限制,就会重新分配底层数组,即便原数组并未填满。
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 10: 0}
s := data[:2:3]
s = append(s, 100, 200) // 一次 append 两个值,超出 s.cap 限制。
fmt.Println(s, data) // 重新分配底层数组,与原数组无关。
fmt.Println(&s[0], &data[0]) // 比对底层数组起始指针。
}
输出结果:
[0 1 100 200] [0 1 2 3 4 0 0 0 0 0 0]
0xc4200160f0 0xc420070060
从输出结果可以看出,append 后的 s 重新分配了底层数组,并复制数据。如果只追加一个值,则不会超过 s.cap 限制,也就不会重新分配。 通常以 2 倍容量重新分配底层数组。在大批量添加数据时,建议一次性分配足够大的空间,以减少内存分配和数据复制开销。或初始化足够长的 len 属性,改用索引号进行操作。及时释放不再使用的 slice 对象,避免持有过期数组,造成 GC 无法回收。
2.6. slice中cap重新分配规律:
package main
import (
"fmt"
)
func main() {
s := make([]int, 0, 1)
c := cap(s)
for i := 0; i < 50; i++ {
s = append(s, i)
if n := cap(s); n > c {
fmt.Printf("cap: %d -> %d\n", c, n)
c = n
}
}
}
输出结果:
cap: 1 -> 2
cap: 2 -> 4
cap: 4 -> 8
cap: 8 -> 16
cap: 16 -> 32
cap: 32 -> 64
2.7. 切片拷贝
package main
import (
"fmt"
)
func main() {
s1 := []int{1, 2, 3, 4, 5}
fmt.Printf("slice s1 : %v\n", s1)
s2 := make([]int, 10)
fmt.Printf("slice s2 : %v\n", s2)
copy(s2, s1)
fmt.Printf("copied slice s1 : %v\n", s1)
fmt.Printf("copied slice s2 : %v\n", s2)
s3 := []int{1, 2, 3}
fmt.Printf("slice s3 : %v\n", s3)
s3 = append(s3, s2...)
fmt.Printf("appended slice s3 : %v\n", s3)
s3 = append(s3, 4, 5, 6)
fmt.Printf("last slice s3 : %v\n", s3)
}
输出结果:
slice s1 : [1 2 3 4 5]
slice s2 : [0 0 0 0 0 0 0 0 0 0]
copied slice s1 : [1 2 3 4 5]
copied slice s2 : [1 2 3 4 5 0 0 0 0 0]
slice s3 : [1 2 3]
appended slice s3 : [1 2 3 1 2 3 4 5 0 0 0 0 0]
last slice s3 : [1 2 3 1 2 3 4 5 0 0 0 0 0 4 5 6]
copy :函数 copy 在两个 slice 间复制数据,复制长度以 len 小的为准。两个 slice 可指向同一底层数组,允许元素区间重叠。
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
fmt.Println("array data : ", data)
s1 := data[8:]
s2 := data[:5]
fmt.Printf("slice s1 : %v\n", s1)
fmt.Printf("slice s2 : %v\n", s2)
copy(s2, s1)
fmt.Printf("copied slice s1 : %v\n", s1)
fmt.Printf("copied slice s2 : %v\n", s2)
fmt.Println("last array data : ", data)
}
输出结果:
array data : [0 1 2 3 4 5 6 7 8 9]
slice s1 : [8 9]
slice s2 : [0 1 2 3 4]
copied slice s1 : [8 9]
copied slice s2 : [8 9 2 3 4]
last array data : [8 9 2 3 4 5 6 7 8 9]
应及时将所需数据 copy 到较小的 slice,以便释放超大号底层数组内存。
2.8. slice遍历:
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice := data[:]
for index, value := range slice {
fmt.Printf("inde : %v , value : %v\n", index, value)
}
}
输出结果:
inde : 0 , value : 0
inde : 1 , value : 1
inde : 2 , value : 2
inde : 3 , value : 3
inde : 4 , value : 4
inde : 5 , value : 5
inde : 6 , value : 6
inde : 7 , value : 7
inde : 8 , value : 8
inde : 9 , value : 9
2.9. 切片resize(调整大小)
package main
import (
"fmt"
)
func main() {
var a = []int{1, 3, 4, 5}
fmt.Printf("slice a : %v , len(a) : %v\n", a, len(a))
b := a[1:2]
fmt.Printf("slice b : %v , len(b) : %v\n", b, len(b))
c := b[0:3]
fmt.Printf("slice c : %v , len(c) : %v\n", c, len(c))
}
输出结果:
slice a : [1 3 4 5] , len(a) : 4
slice b : [3] , len(b) : 1
slice c : [3 4 5] , len(c) : 3
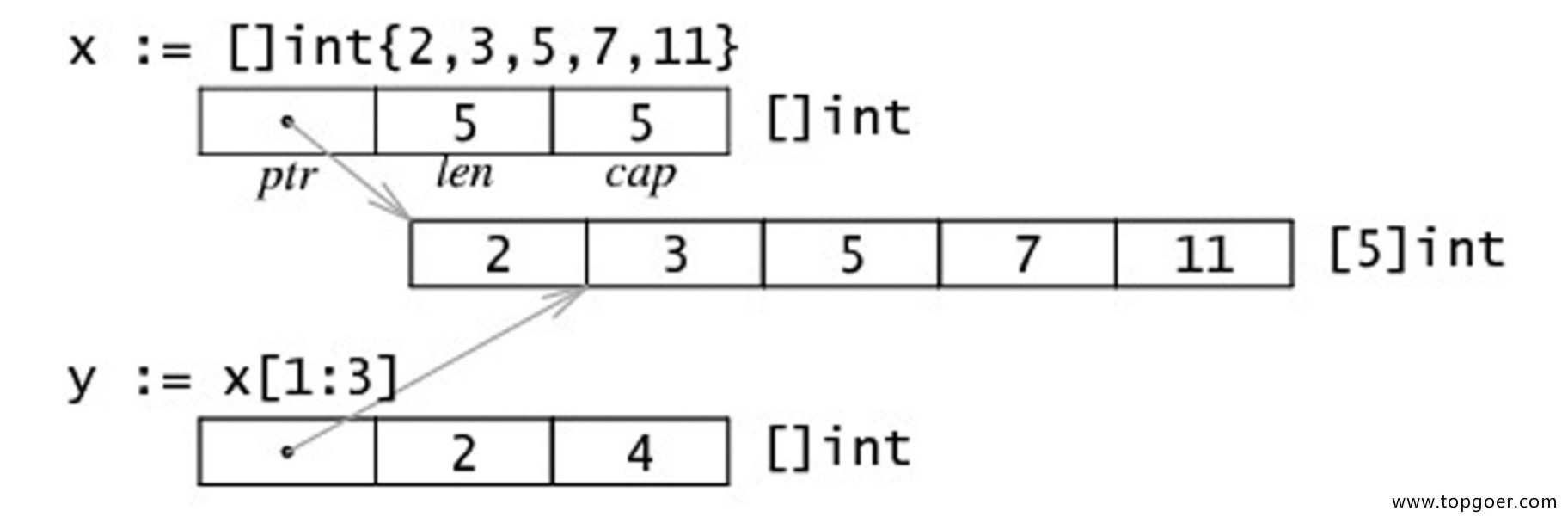
2.10. 数组和切片的内存布局
2.11. 字符串和切片(string and slice)
string底层就是一个byte的数组,因此,也可以进行切片操作。
package main
import (
"fmt"
)
func main() {
str := "hello world"
s1 := str[0:5]
fmt.Println(s1)
s2 := str[6:]
fmt.Println(s2)
}
输出结果:
hello
world
string本身是不可变的,因此要改变string中字符。需要如下操作: 英文字符串:
package main
import (
"fmt"
)
func main() {
str := "Hello world"
s := []byte(str) //中文字符需要用[]rune(str)
s[6] = 'G'
s = s[:8]
s = append(s, '!')
str = string(s)
fmt.Println(str)
}
输出结果:
Hello Go!
2.12. 含有中文字符串:
package main
import (
"fmt"
)
func main() {
str := "你好,世界!hello world!"
s := []rune(str)
s[3] = '够'
s[4] = '浪'
s[12] = 'g'
s = s[:14]
str = string(s)
fmt.Println(str)
}
输出结果:
你好,够浪!hello go
golang slice data[:6:8] 两个冒号的理解
常规slice , data[6:8],从第6位到第8位(返回6, 7),长度len为2, 最大可扩充长度cap为4(6-9)
另一种写法: data[:6:8] 每个数字前都有个冒号, slice内容为data从0到第6位,长度len为6,最大扩充项cap设置为8
a[x:y:z] 切片内容 [x:y] 切片长度: y-x 切片容量:z-x
package main
import (
"fmt"
)
func main() {
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
d1 := slice[6:8]
fmt.Println(d1, len(d1), cap(d1))
d2 := slice[:6:8]
fmt.Println(d2, len(d2), cap(d2))
}
数组or切片转字符串:
strings.Replace(strings.Trim(fmt.Sprint(array_or_slice), "[]"), " ", ",", -1)?
参考文章:
切片Slice · Go语言中文文档 (topgoer.com)
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- k8s--helm
- 手把手教你如何快速定位bug,如何编写测试用例,快来观摩......
- python基础教程二(列表相关知识)
- 一文读懂 $mash 通证 “Fair Launch” 规则(幸运池玩法解读篇)
- openGL API
- 【论文阅读 SIGMOD18】Query-based Workload Forecasting for Self-Driving
- .gitignore文件设置了忽略但不生效,git提交过程解析
- 实现间隔几秒number动态递增变化(整数小数)
- pytest-xdist 进行多进程并发测试!
- Windows无法安装edge 无法连接Internet