CPU 软中断触发的系统故障案例一则
??关键词
- linux、centos
- cpu 软中断、irqbalance、CPU亲和绑定
-
网卡多队列、网卡丢包RXdrop
一、问题现象
某天上班的早晨,业务高峰期,突发故障,现象为应用侧访问卡顿,数据库客户端连接数突增,平均处理耗时增长。
二、问题分析
故障发生后,业务涉及的相关方分头进行排查,操作系统侧从其中一个业务节点主机上发现如下可疑情况:
1、有syn flood的相关告警

2、网卡有RX drop的持续丢包情况

3、单核心CPU软中断持续100%占用

三、处理过程
当看到cpu有个核心持续100%的情况,当即启动了下irqbalance,让中断自动平衡下后,业务恢复了正常。罪魁祸首还是中断导致了在高访问下,业务的阻塞。
后对整个故障进行了复盘,主要是对一些故障现象做了深挖。
1、关于SYN flood
发生时间:故障主机曾多次出现过flood相关报错,分别在不同端口,故障的早上发生过6次。
发生根本原因:因业务出现异常后,业务客户端会不断重启尝试,服务端短时内收不到回包,导致大量重试发送很多数据包,占满半连接队列,超出系统最大承载能力。
#当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭。
net.ipv4.tcp_syncookies = 1
#表示系统允许SYN连接的重试次数。为了打开对端的连接,内核需要发送一个SYN并附带一个回应前面一个SYN的ACK包。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK包的数量。
net.ipv4.tcp_synack_retries = 2
#表示在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.tcp_syn_retries = 2
系统默认配置了syncookies,SYN等待队列溢出时,表示仍可以继续提供服务。
2、关于网卡丢包RX droped
现象:ens0网卡的丢包主要体现在rx dropped上。
原因:rx_dropped通常是由Linux中的缓冲区空间不足或cpu处理速度不够导致的丢包。主机上的丢包,是因为cpu1软中断过高,并且当时的流量很高导致。
在linux的enqueue_to_backlog函数中,会对CPU的softnet_data 实例中的接收队列(input_pkt_queue)进行判断,如果队列中的数据长度超过netdev_max_backlog ,那么数据包将直接丢弃,这就产生了丢包。netdev_max_backlog是由系统参数net.core.netdev_max_backlog指定的,默认大小是 1000。

检查/proc/net/softnet_stat内容
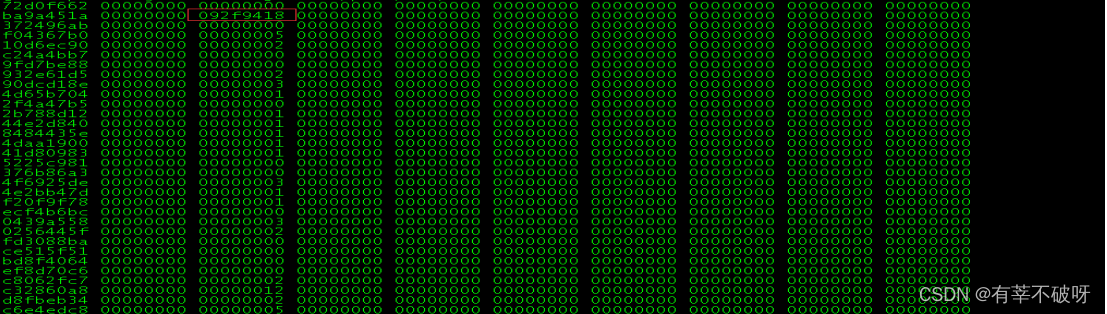
其中每行代表一个CPU,第一列是中断处理程序接收的帧数,第二列是由于超过 netdev_max_backlog 而丢弃的帧数。 第三列则是在 net_rx_action 函数中处理数据包超过 netdev_budget 指定数量或运行时间超过2个时间片的次数。从上面的输出可以看出,服务器统计中,并没有因为 netdev_max_backlog 导致的丢包。
3、关于CPU1软中断异常占用
现象:故障主机cpu1核使用率业务高峰期长期处于高水位运行
原因:故障主机cpu中断亲和绑定不均衡,处理网络收发中断的亲和cpu1在业务高峰期时使用率较高。
故障主机的网卡中和绑定情况:
cat /proc/interrupts | grep ens0- |cut -d: -f1 | while read i; do echo -ne irq ":$i\t bind_cpu: "; cat /proc/irq/$i/smp_affinity_list; done |sort -n -t ' ' -k3

因为开启过irqbalance,网卡涉及的irq亲和cpu不是故障时绑定情况。
故障主机的cpu中断情况:
cpu1的NET_TX中断值比其他cpu大很多。
?cat /proc/softirqs|column -t|cut -c-146

故障主机sa日志历史irq情况:
在近1个月记录中,cpu1的soft使用率过高的问题一直存在。
主机上各cpu软中断运行时间

Ens0网卡的中断统计中,cpu1的中断最多、最频繁。

四、知识拓展
1、中断的概念
1)理解中断
Linux中断是操作系统的自我保护机制,可以保证硬件的交互过程不被意外打断,所以短时间内的中断是正常的。
2)为什么要有中断
一个例子:你订了一份外卖,但是不确定外卖什么时候送到,也没有别的方法了解外卖的进度,但是,配送员送外卖是不等人的,到了你这儿没人取的话,就直接走人了。所以你只能苦苦等着,时不时去门口看看外卖送到没,而不能干其他事情。不过呢,如果在订外卖的时候,你就跟配送员约定好,让他送到后给你打个电话,那你就不用苦苦等待了,就可以去忙别的事情,直到电话一响,接电话、取外卖就可以了。这里的“打电话”,其实就是一个中断。没接到电话的时候,你可以做其他的事情;只有接到了电话(也就是发生中断),你才要进行另一个动作:取外卖。
这个例子你就可以发现,中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
3)中断丢失
由于中断处理程序会打断其他进程的运行,所以,为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。如果中断本身要做的事情不多,那么处理起来也不会有太大问题;但如果中断要处理的事情很多,中断服务程序就有可能要运行很长时间。
用外卖的例子来说明就是:你同时订了两份外卖,第一份外卖到了在打电话的过程中,第二份外卖也到了电话占线就会出现外卖丢失的情况。
4)软中断
如果你弄清楚了“取外卖”的模式,那对系统的中断机制就很容易理解了。事实上,为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。(也就是我们常说的硬中断,特点是快速执行)
下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。(也就是我们常说的软中断,特点是延迟执行)
备注:上半部会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。
软中断不只包括了刚刚硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和 RCU 锁(Read-Copy Update 的缩写,RCU 是 Linux 内核中最常用的锁之一)等。
2、查看软中断和内核线程
proc 文件系统。它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
/proc/softirqs 提供了软中断的运行情况;(类型+中断次数)
/proc/interrupts 提供了硬中断的运行情况。
ps aux | grep softirq ? 查看软中断内核线程。
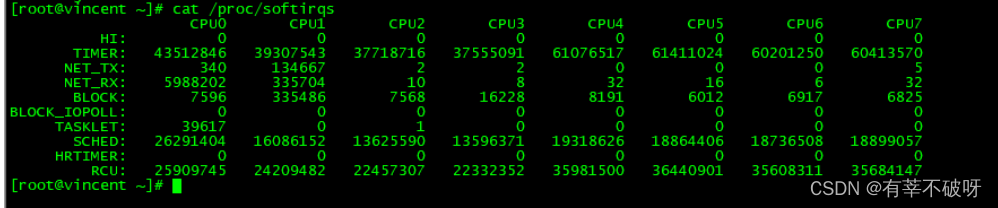
注意:
1、要注意软中断的类型,也就是这个界面中第一列的内容。从第一列你可以看到,软中断包括了 10 个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
2、注意同一种软中断在不同 CPU 上的分布情况,也就是同一行的内容。正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。
3、统计的运行情况数值是累加的,应关注一段时间的变化情况。
4、 软中断10个类别: ? ? ? ??
HI---高优先级的tasklet ?TIMER---内核定时器 ?NET_TX---网络发送 NET_RX—网络接收 ? ?BLOCK/BLOCK_IOPOLL--- 块设备软中断 ?TASKLET--普通的tasklet ?SCHED—内核调度 ? HRTIMER—高精度定时器 ? RCU—RCU锁
3、软中断问题常用排查工具
top--查看系统整体负载情况
关注si--软中断的百分比情况
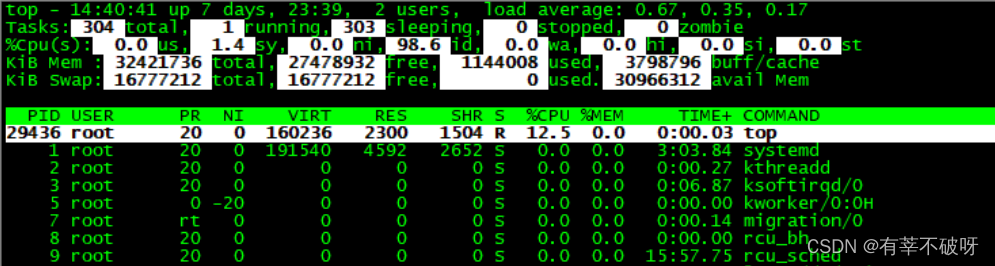
# 运行后按数字 1 切换到显示所有 CPU情况

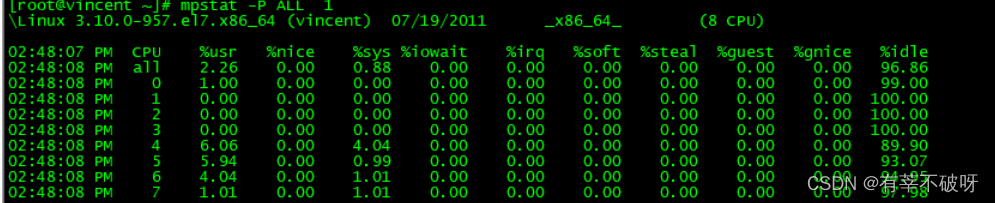
mpstat –P ALL 1 --定时刷新查看系统所有 CPU情况(关注%soft)
vmstat -n 1 --每秒刷新查看系统所有 CPU情况

SYSTEM中
--in:每秒产生的中断次数?
--cs:每秒产生的上下文切换次数?
上面2个值越大,会看到由内核消耗的CPU时间会越大?
pidstat -w 1 ?--每秒刷新输出系统上下文切换情况
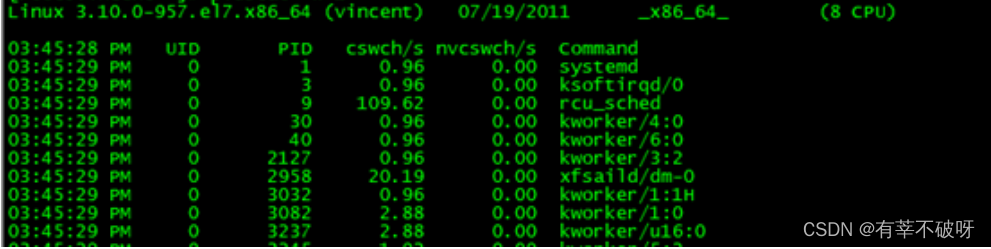
watch -d cat /proc/softirqs---查看 /proc/softirqs 变化速率,使用 watch 可以看到变化,明确变化最大的软中断或者中断不均的类型:
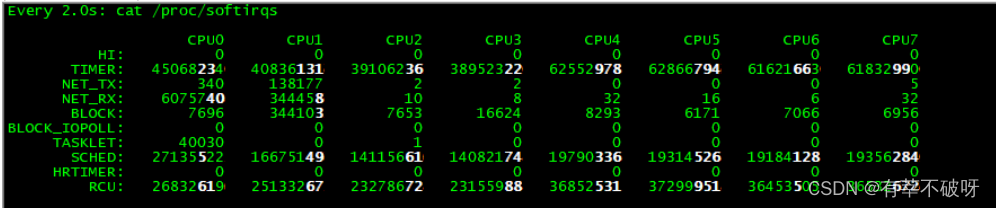
根据定位到的软中断的类别,再继续分析具体的原因。
常见情况下,通过 /proc/softirqs 文件内容的变化情况,可以发现, TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)等这几个软中断都在不停变化。其中,NET_RX,也就是网络数据包接收软中断的变化速率最快。而其他几种类型的软中断,是保证 Linux 调度、时钟和临界区保护这些正常工作所必需的,所以它们有一定的变化在正常范围内。
4、关于irqbalance的一些认识
Irqbalance每次均衡的效果是不是一样?怎样的处理逻辑?
1)irqbalance的工作原理:
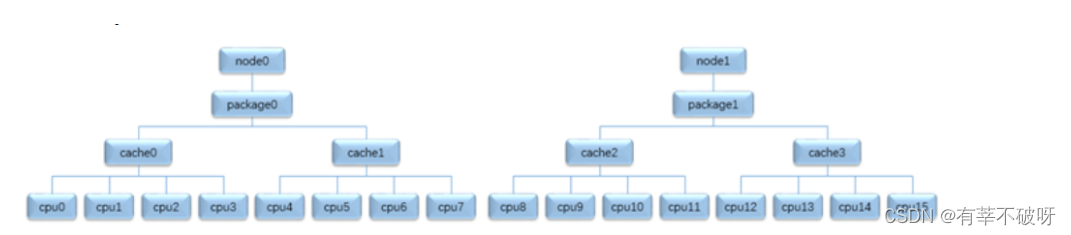
Irqbalance是用户空间用于优化中断的一个工具,通过周期性的(默认10s)统计各个cpu上的中断情况,重新对中断进行再分配,实现各个cpu上中断负载相对均衡。中断均衡是建立再“object tree”的基础之上的,object ? tree则是通过系统的拓扑结构建立的分层结构。根据系统结构属性NUMA node/packet/cache affinity可以将系统划分为自上而下的四层:node->package->cache->cpu。
object tree拓扑结构如图:
其中:
(1)每个节点为一个object,通过struct topo_obj描述。
(2)上下层之间的节点通过parent/child指针管理
(3)每一层都有一个全局链表头指针,用于组织管理处于同一层的所有节点。?
2)irqbalance处理流程
? Irqbalance会周期性的(10s)统计系统中断的情况,主要的处理流程图如下:?
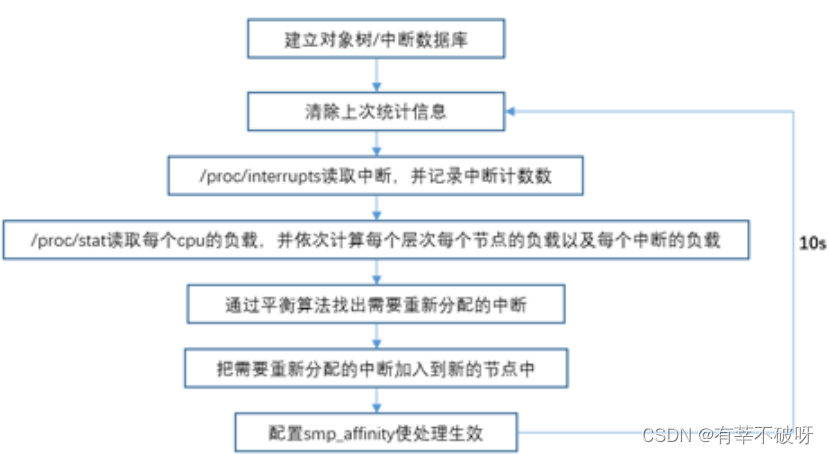
3)从以上可以得出的结论:
irqbalance每次均衡的结果是随着机器负载情况来设置,不会一成不变。
4)机器重启后,机器的中断irq绑定cpu对应关系会不会变?
? ?通过一台物理机测试验证,irq在平衡后,重启机器网卡的irq绑定情况会产生变化。系统分配的中断号会重新初始化,所以之前的绑定关系不适用于重启后的主机。手动绑定的情况也是一样。
5)、Irqbalance调整后的结果,在系统运行过程中,中断绑定情况后期会不会自动发生变化?
? 中断绑定,首先是要有中断号,硬件的中断号,在系统启动后,由操作系统自动分配固定中断号,后期系统使用过程中irq不会变化,irq对应的亲和cpu,不会自动发生变化。
6)、Irqbalance服务能不能一直运行?如何手动绑定irq?
LINUX 提供了自动平衡的工具服务,但这类方式可能会引发其他的影响,官方建议是实时不打开此服务。

手动绑定irq:
在 linux 系统的 /proc/irq 目录中,对于已经注册中断处理程序的硬件设备,都会在该目录下存在一个以该中断号命名的目录 IRQ# , IRQ# 目录下有一个 smp_affinity文件(SMP 体系结构才有该文件,为16进制),它是一个 CPU 的位掩码,可以用来设置该中断的亲和力, 默认值为 0xffffffff,表明把中断发送到所有的 CPU 上去处理。我们可以通过修改 smp_affinity 文件把中断绑定到特定的 CPU(逻辑 CPU)上去处理。也可以通过改smp_affinity_list (10进制文件)。smp_affinity_list和smp_affinity任意更改一个文件都会生效,两个文件相互影响,只不过是表示方法不一致。
修改方法:
echo CPU号 > /proc/irq/IRQ号/smp_affinity_list?
7)、关于irq绑定的最佳建议是?
? ?软中断的问题主要集中在网络收发的中断上,所以网卡多队列的中断亲和均衡尤为重要。如果存在多队列绑定在同一核上,当系统网络并发过高时,软中断会引发系统丢包、阻断等异常现象。所以,针对网络多队列的中断,我们应当在系统启动后,就应该配置成完全均衡状态。
? 从前面分析来看,首先irqbalance自动调整的方式,不能完全将网卡队列均衡开,它主要依据当时的负载情况做的调整。其次机器如若发生重启,所有中断绑定情况需要重新设置。
? 所以针对上云环境中的物理主机,irq网卡队列绑定的最佳建议是通过脚本自动均衡cpu的绑定,并加到主机启动脚本中,同时更新到物理机初始化加固脚本中。(注:一般情况下,绑定irq亲和时还应考虑numa的分布情况,因上云环境numa均做了关闭,忽略了这一因素的影响)
附件:自动均衡网卡队列绑定的脚本?
#!/bin/bash
##this script used for manaul-set irq for network(numa node is off)
DAT=`date +%Y%m%d%H%M`
##获取逻辑 cpu##############
cpu_irq=`cat /proc/cpuinfo | grep processor | awk -F ':' '{print $2}'`
cpu_irq_array=(`cat /proc/cpuinfo | grep processor | awk -F ':' '{print $2}'`)
##获取物理网卡名#############
ip a|grep "state UP"|grep -v cali|awk -F: '{print $2}'|grep -Ev "bond0|lo"|sed 's/[: ]//g' > ifname
cat ifname|while read name;
do
#获取网卡对应IRQ数组
net_irq=`cat /proc/interrupts |awk '/'$name'-/{print $1}'| sed 's/[: ]//g'`
net_irq_num=`cat /proc/interrupts |awk '/'$name'-/{print $1}'| sed 's/[: ]//g'|wc -l`
net_irq_array=(`cat /proc/interrupts |awk '/'$name'-/{print $1}'| sed 's/[: ]//g'`)
cat /dev/null > $name.log
# 手动绑定irq
for ((i=0; i<${#net_irq_array[@]};i++))
do
echo ${cpu_irq_array[i]} > /proc/irq/${net_irq_array[i]}/smp_affinity_list
cat /proc/irq/${net_irq_array[i]}/smp_affinity_list >> $name.log
done
#####检查irq手动调整结果
sortnum=`cat $name.log|sort -u|wc -l`
if [ $sortnum -eq $net_irq_num ];then
echo "网卡:$name CPU中断绑定已均衡"
else
echo "网卡:$name CPU中断绑定不均衡,请查看日志"
fi
######记录调整后irq绑定情况
echo "--------ifname $name irq----------------------------"
cat /proc/interrupts | grep $name- | cut -d: -f1 | while read i; do echo -ne irq":$i\t bind_cpu: "; cat /proc/irq/$i/smp_affinity_list; done | sort -n -t' ' -k3
done本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【LeetCode】每日一题 2023_12_19 寻找峰值 II(二分)
- 14-高并发-异步并发
- 基础算法-整数二分
- jquery获取子元素的一些方法
- Java—Throwing Exceptions
- transbigdata笔记:数据栅格化
- JavaScript-初识&开发常用语句
- 麻雀搜索算法解释和代码
- 企微消息群发工具:高效管理企业微信沟通的新宠
- 一条示例告诉你if else语句应该怎么用:马上快跨年了,想约异性出去玩该怎么办