Opus编解码器中音乐检测的奥秘
Opus是一个有损音频压缩的数字音频编码格式,由Xiph.Org基金会开发,之后由互联网工程任务组(IETF)进行标准化,目标是希望用单一格式包含声音和语音,取代Speex和Vorbis,且适用于网络上低延迟的即时声音传输,标准格式定义于RFC 6716文件。Opus格式是一个开放格式,使用上没有任何专利或限制。Opus编码不同声音编码格式的比特率、采样率与延迟性如下图所示:

Opus支持语音(SILK层)和音乐(CELT层)的单独或混合模式,它们对应的比特率范围如下所示:

Opus1.1 音乐检测算法
在比较早的版本需要开发者手动选择是音乐还是语音,但是在1.1这个版本,提出了根据输入音频内容自动选择对应的模式,其原理如下所示:
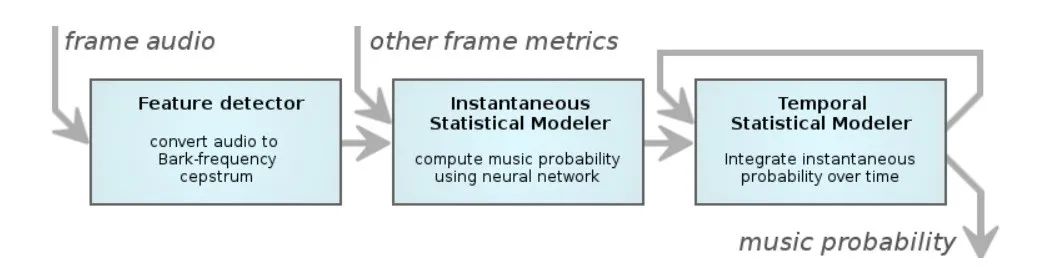
在这个版本首先提取对应音频的BFCC系数(就是RNNoise里的特征),并对系数进行一阶二阶差分,除此之外还使用了在可变比特率(VBR)计算中得出的音调估计,以及一些在编码过程中先前计算过的其他指标。然后将这些特征融合在一起送入多层感知机(multi-layer perceptron,MLP)。值得一提的是Xiph.Org基金会的开发者一开始有使用过基于高斯混合模型进行音乐检测,但其检测效果不佳,最终被神经网络替代。
神经网络输出仅仅是当前帧为音乐的概率。为了进一步引入时序的信息进行音乐判决Xiph.Org基金会的开发者引入了隐马尔科夫模型(可以参考从零实现机器学习算法(十七) 隐马尔可夫模型)。一般而言,输入信号短时间内在语音和音乐之间互转是个极小概率事件。因此我们将音频行为建模为一个隐马尔可夫模型,假设在给定的10毫秒内从语音过渡到音乐(反之亦然)的概率为0.00005,这相当于平均每200秒发生一次状态转移。
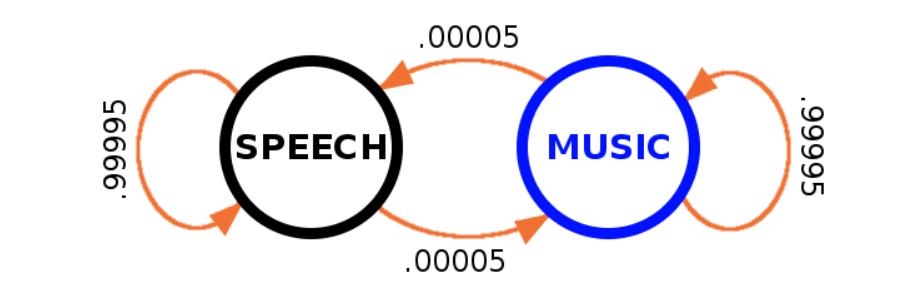
基于隐马尔可夫模型的时间统计模型,通过对神经网络的瞬时概率输出进行加权和积分。最终,编码器将计算的概率与一个取决于比特率、带宽、帧大小和应用的切换阈值进行比较,以确定编码模式。由于整体的检测没有lookahead(opus后续版本支持可设定lookahead),这会导致音乐检测结果没有那么准确,然而这点会使得整体音频听起来更柔和一点。
Opus1.3?音乐检测算法
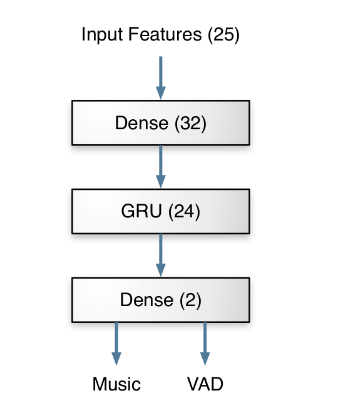
Xiph.Org基金会的开发者在Opus1.3的版本中提出了新一代的音乐检测器。使用门控循环单元(Gated Recurrent Unit,GRU)构建模型进行音乐检测,由于本质是个分类任务,因此模型构建的较为轻量,整体网络结构如下所示,只有4986个参数。由于是端到端的神经网络能介绍的不多,需要提一点的是,1.3版本在最终的决策上也有所优化。特别是当lookahead启用时,Opus能够在语音和音乐之间转换之前的静默期切换编码器的模式。
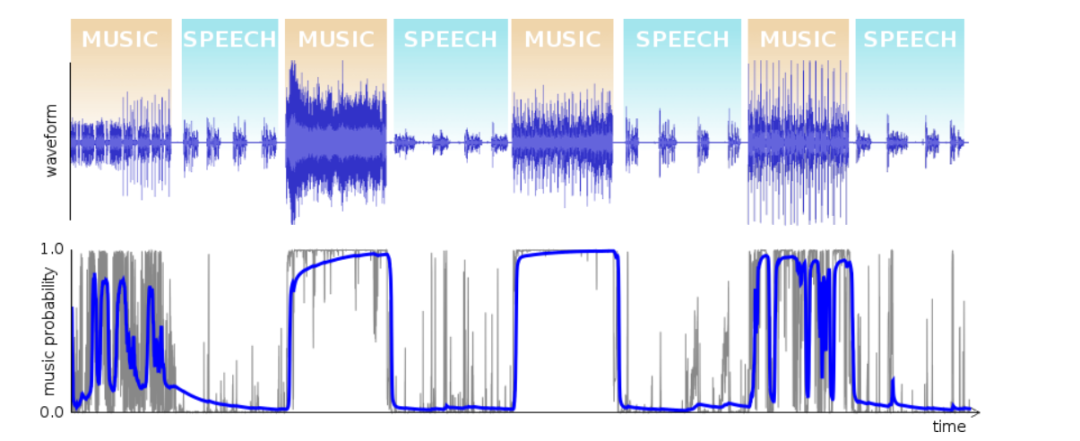
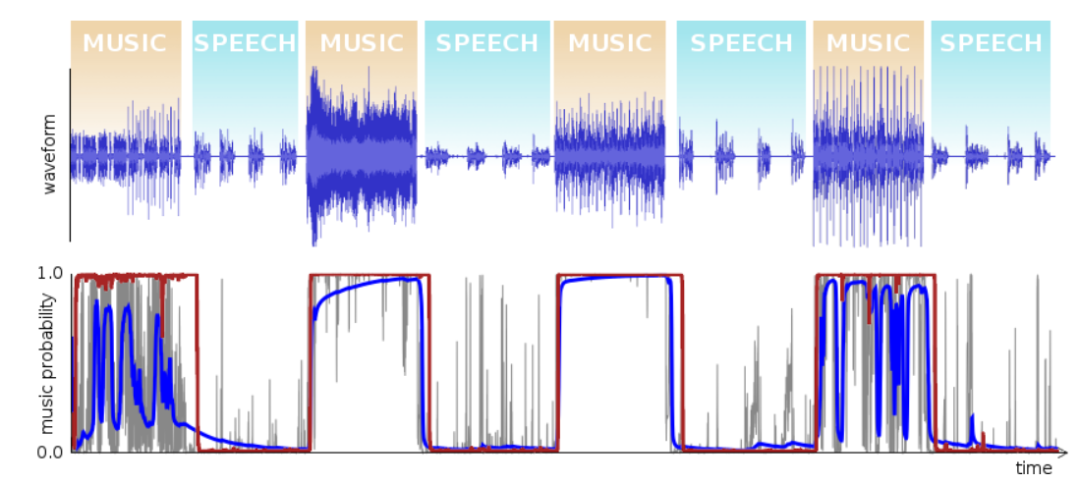
最后我们把两个版本结果对比一下,如图所示,其中蓝色的是1.1版本的检测结果,红色是1.3版本的检测结果。可以明细看出,使用GRU作为网络结构的检测结果要优于MLP+HMM的检测结果,在语音/音乐切换的边缘,决策也更为准确。
参考文献:
[1].?https://web.archive.org/web/20170430223047/https://people.xiph.org/~xiphmont/demo/opus/demo3.shtml
[2].?https://jmvalin.ca/opus/opus-1.3/
[3].?https://zh.wikipedia.org/wiki/Opus_(%E9%9F%B3%E9%A2%91%E6%A0%BC%E5%BC%8F)
[4].?https://jmvalin.ca/papers/aes135_opus_celt.pdf
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux id命令教程:如何有效地获取用户和组信息(附案例详解和注意事项)
- 无人机支持的空中无蜂窝大规模MIMO系统中上行链路分布式检测
- 创建型模式之抽象工厂模式
- imgaug库指南(31):从入门到精通的【图像增强】之旅
- HTML常见标签和属性
- 无线且列窄图片如何转excel?
- 字节8年经验之谈 —— 详解python自动化单元测试!
- 详细介绍如何使用T5实现文本摘要:微调和构建 Gradio 应用程序-含完整源码
- 如何通过ISPC使用Xe(核显)进行计算
- 75K star!让生产力起飞的超火开源CSS框架:tailwindcss