公共用例库计划--个人版(四)功能改造与性能优化
1、任务概述
??本次计划的核心任务是开发一个,个人版的公共用例库,旨在将各系统和各类测试场景下的通用、基础以及关键功能的测试用例进行系统性地归纳整理,并以提高用例的复用率为目标,力求最大限度地减少重复劳动,提升测试效率。
??计划内容:完成公共用例库的开发实施工作,包括需求分析、系统设计、开发、测试、打包、运行维护等工作。
1.1、 已完成:
??需求分析、数据库表的设计:公共用例库计划–个人版(一)
??主体界面与逻辑设计:公共用例库计划–个人版(二)主体界面设计
??导出Excel功能:公共用例库计划–个人版(三)导出Excel功能
1.2、 本次待完成:
?? 1. 用例信息页面,对模块查询功能进行改造。实现下拉框输入模块名称,几秒钟后自动查询模块信息,或者回车查询。
??2. 部分模块的性能优化。
??3. 库表码值改造。
2、功能改造
2.1 用例信息页面
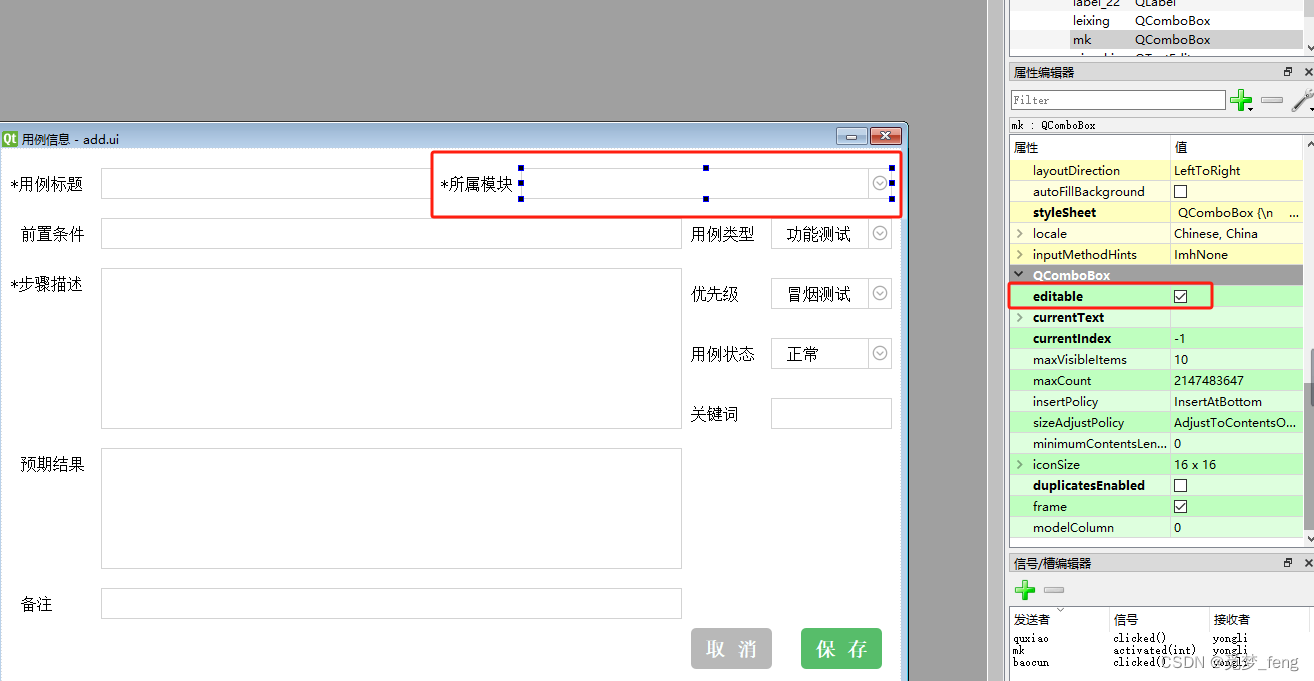
??现将模块显示框替换成下拉框,将可以编辑勾选上,就可以输入文本了。
2.2 逻辑修改
??要实现输入模块名称,查询返回模块名称与ID。先编写查询功能函数:
def mkcx_add(self):
"""用例页面,模块查询"""
vlue=['%' + self.addcase.mk.lineEdit().text() + '%'] # 获取输入文本
self.casedb.connect()
self.row=self.casedb.query_many(
"select modulename,moduleid from module where modulename like ? and status = 10", vlue)
self.casedb.over()
self.addcase.mk.clear() # 清空下拉框
if self.row:
self.mkid=self.row[0][1] # 默认选择的第一个模块ID
# 将模块名称、ID,写入下拉框选项
for result in self.row:
self.addcase.mk.addItem(result[0] + '—ID:' + str(result[1]))
else:
self.mkid=0
logging.info('用例页面,模块查询')
函数写好了,现在需要在输入模块后调用。在这里使用信号槽机制:
??增加信号,在mk的编辑控件编辑完成,回车后,触发函数:self.mkcx_add
self.addcase.mk.lineEdit().returnPressed.connect(self.mkcx_add) # 编辑,触发模块查询
2.3 实现情况
??现在输入名称,回车后可以查询模块信息,并显示到下拉框。

2.4 输入信息后,自动查询
??想法:增加编辑文本的信号,在编辑后3秒钟,自动查询
2.4.1 信号槽设置
??在下拉框文本编辑后,发送信号到:self.on_text_changed
self.addcase.mk.lineEdit().textEdited.connect(self.on_text_changed)
??编写self.on_text_changed函数:在文本信息改变后,计时3秒。如果没有后续变动信号,计时结束就出发查询。
def on_text_changed(self, text):
# 取消之前可能存在的计时器
if self.timer:
self.timer.stop()
self.timer.deleteLater()
# 创建一个新的计时器,在3秒后触发查询函数
self.timer=QTimer(self)
self.timer.setSingleShot(True) # 设置为单次触发
self.timer.timeout.connect(self.mkcx_add)
self.timer.start(3000) # 3秒后触发
2.4.2 问题1
??问题:现在已经实现了,回车查询、3秒自动查询。但是,回车后还是会触发3秒查询。
??解决方案:在查询函数增加计时器的清理操作。因为在文本编辑后,同时触发的两个槽函数,那么回车就将计时清空,使自动查询不能继续触发查询函数。
def mkcx_add(self):
"""用例页面,模块查询"""
if self.timer and self.timer.isActive(): # 关闭并删除计时器(确保不会触发3秒的定时事件)
self.timer.stop()
self.timer.deleteLater()
self.timer=None # 清空计时器引用
vlue=['%' + self.addcase.mk.lineEdit().text() + '%'] # 获取输入文本
self.casedb.connect()
self.row=self.casedb.query_many(
"select modulename,moduleid from module where modulename like ? and status = 10", vlue)
self.casedb.over()
self.addcase.mk.clear() # 清空下拉框
if self.row:
self.mkid=self.row[0][1]
for result in self.row: # 将模块名称、ID,写入下拉框选项
self.addcase.mk.addItem(result[0] + '—ID:' + str(result[1]))
else:
self.mkid=0
logging.info('用例页面,模块查询')
2.4.3 问题2
??问题:已经查询一次,然后再次输入。他会自动补齐文本,然后发现是下拉框已有的选项文本。因为下拉框是模块+ID,补齐的文本查询不出模块。
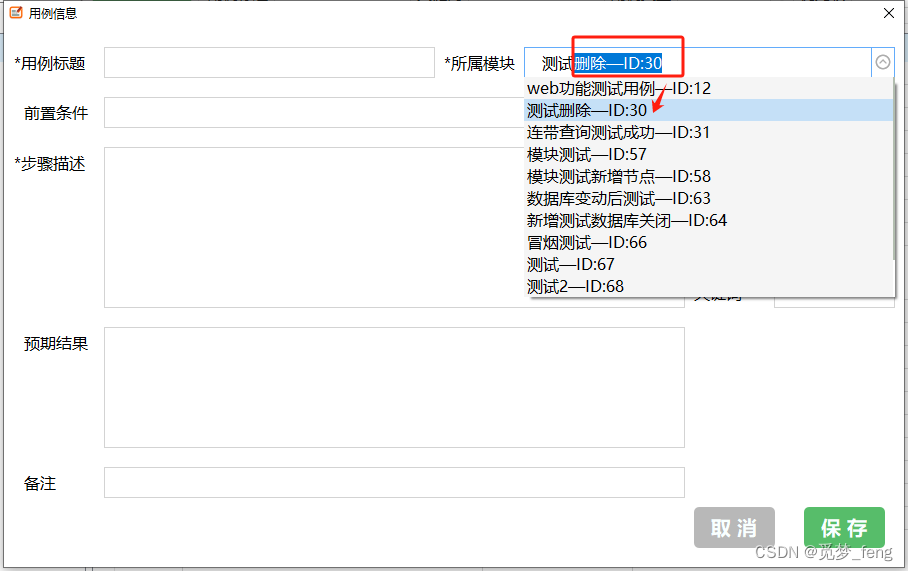
??解决方案:关闭自动补齐功能
self.addcase.mk.lineEdit().setCompleter(None) # 关闭自动补全功能
3、模块的性能优化
提升Python运行速度:
- 选择合适的数据结构
- 少用循环
- 用 列表推导式 代替循环
- 用 迭代器 代替循环
- 用 filter() 代替循环
- 减少循环次数,精确控制,不浪费CPU
- 避免循环重复计算
- 少用内存、少用全局变量
3.1 使用计时装饰器
??对查询,保存等函数使用计时器,针对性优化。
def timeshow(func):
"""计时函数"""
from time import time
def newfunc(*arg, **kw):
t1=time()
res=func(*arg, **kw)
t2=time()
print(f"{func.__name__: >10} : {t2 - t1:.6f} sec")
return res
return newfunc

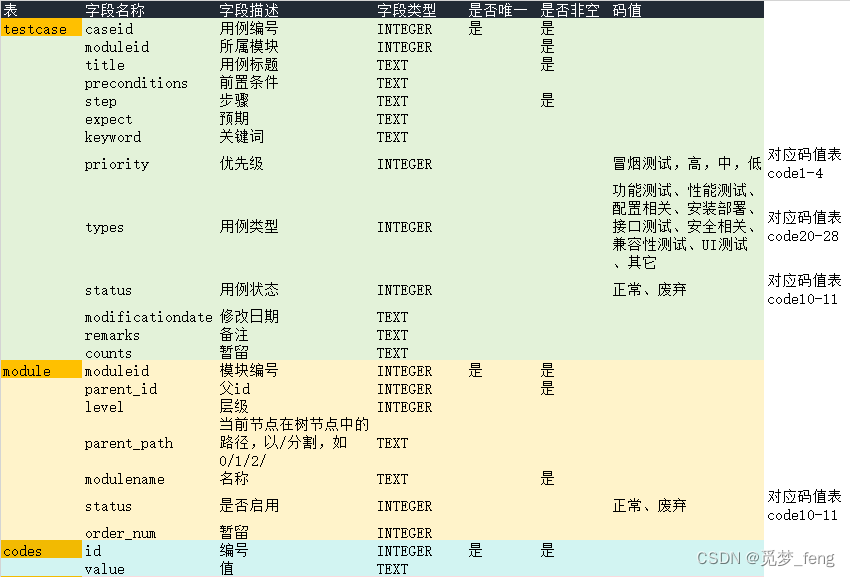
4、库表码值改造
通义千问说:
将SQLite数据库中原本为TEXT类型的四个字段更改为INTEGER类型后,会带来以下对性能和存储的影响:
- 性能影响:
-
查询速度提升:
对于整数字段进行比较、计算和索引操作通常比文本字段更快。尤其是当执行涉及这些字段的数学运算或者使用了索引进行查询时,性能差异更为显著。
-
排序效率提高:
整数排序的速度要快于文本排序,因为整数比较是直接在二进制层面完成的,而文本排序需要基于字符编码进行比较。
-
减少数据转换开销:
如果之前在应用程序中处理这些字段时,频繁地在文本和数值之间转换,那么现在可以直接处理整数,可能降低转换过程中的CPU开销。
- 存储影响:
-
空间占用减小:
INTEGER类型相比TEXT类型,在存储同样大小或范围内的数值时,通常会占用更少的空间。每个INTEGER值通常固定占用4个字节(取决于SQLite的具体实现和整数的大小),而TEXT则根据内容长度不同,可能占用更多空间。
-
索引优化:
如果这些字段被用作索引,那么将TEXT改为INTEGER可能会使得索引更紧凑,从而加速查询并减少磁盘I/O操作。
就现试看看,新增codes码值表,将模块表与用例表码值转换成对应的编码。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PostgreSQL学习笔记01
- Windows反调试技术学习
- 有赞微商城集成CRM:无代码电商平台优化用户运营
- 深入理解JVM虚拟机第三十九篇:JVM中新生代和老年代相关参数设置
- 【立创EDA-PCB设计基础完结】7.DRC设计规则检查+优化与丝印调整+打样与PCB生产进度跟踪
- 申请软件代码签名数字证书
- 【精简】Vue 一个@click时间绑定多个点击事件
- springboot对接WebSocket实现消息推送
- 2024最新前端React面试题:JSX是什么,它和JS有什么区别
- 软文投放注意事项,媒介盒子分享