Linux 快速构造大数据文件
????????
文章目录如下
????????
1. 如何生成数据文件
在Linux中,我们有很多生成数据文件的方式,比如
echo "a,b,c" > file.txt这种方式最为简单直接,缺点也相对明显,例如:生成多行数据非常繁琐
echo "a,b,c
a,b,c
a,b,c" > file.txt大部分需求是需要上万行数据,显然单纯的使用 echo 的不明智的,一般情况下需要在 echo 的基础上增加循环的方式
for i in {1..10000};do # 循环1w次
echo "a,b,c" >> file.txt
done使用循环可以将每行都修改为不同的数据,这对于构造一些特定场景的数据有着极大帮助,比如
for i in {1..10};do # 循环10次
str=$(echo $RANDOM |md5sum |head -c 10) # 随机字符
echo "${i},${str}"
done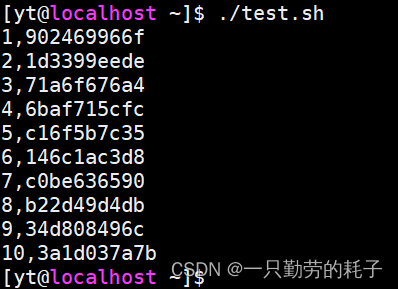
????????
使用 for 循环可以按照特定场景构造数据,但仍然存在一个缺点:效率低下。当然,也有的伙伴会认为:既然 for 循环太慢,那就使用 dd 构造数据吧。
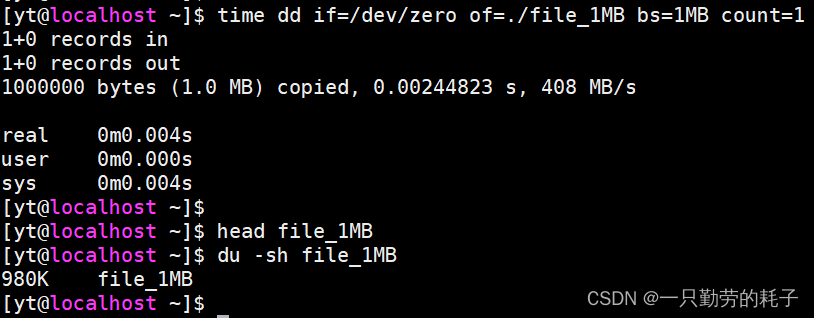
截图上可以看到 dd 构造数据的速度确实快,但它所构造的是二进制数据。对我们来说,这样的文件在大部分情况是用不上的,所以这篇文章主要介绍两个用于快速构造数据的命令:yes、awk。
????????
2. 使用 yes 命令构造数据
2.1. 基本用法
yes?命令通常用于在终端中重复输出指定的字符串,或者以默认值不断地向命令行发送“y”字符串,通常用于自动化脚本或者在需要自动确认输入的情况下。
直接执行 yes 的结果如下:
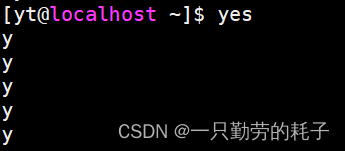
无限打印 y,通过 Ctrl + C 停止
????????
yes 命令也支持指定输出固定的字符
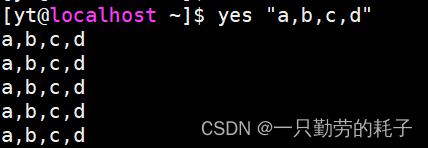
????????
2.2. 构造数据文件
由于 yes 的作用是无限重复打印指定字符串,这也意味着它无法修改字符串中的字符,仅适用于对数据没有特定需求的构造方式。
【案例一】构造10w行数据
yes "a,b,c,d,e" |head -100000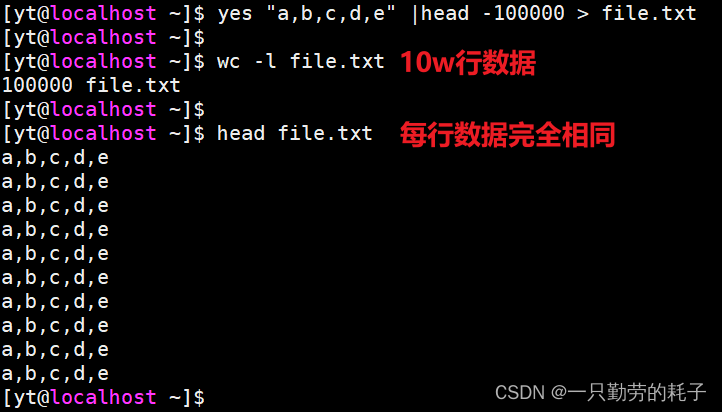
????????
【案例二】构造1GB数据
yes "a,b,c,d,e" |head -c 1G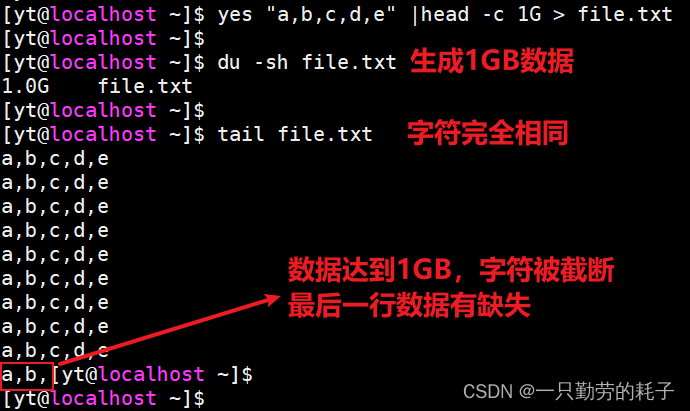
由于 head 是按大小截断字符,所以导致最后一行可能与其他行并不一致。
利用 sed 不输出最后1行
yes "a,b,c,d,e" |head -c 1G |sed -n '$!p'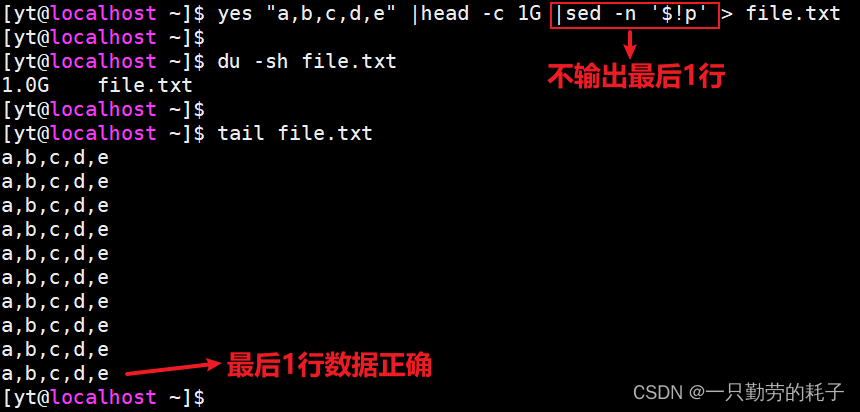
????????
3. 使用 awk 命令构造数据
3.1. 基本用法
awk 命令本身是用于提取、转换和格式化文本数据,但由于是使用高效的C语言实现,使得 awk 成为快速高效的文本处理工具。所以生成数据的效率是非常的高,这篇主要介绍如何生成数据,awk 的文本处理见另一篇文章:https://blog.csdn.net/m0_61066945/article/details/132557457
生成指定数据的语法如下:
awk 'BEGIN{print "a,b,c,d"}'
- BEGIN:表示在开始处理之前执行的操作,也就是说不需要指定某个文件。
- print:打印某个字符串
- "a,b,c,d":需要输出的字符串
????????
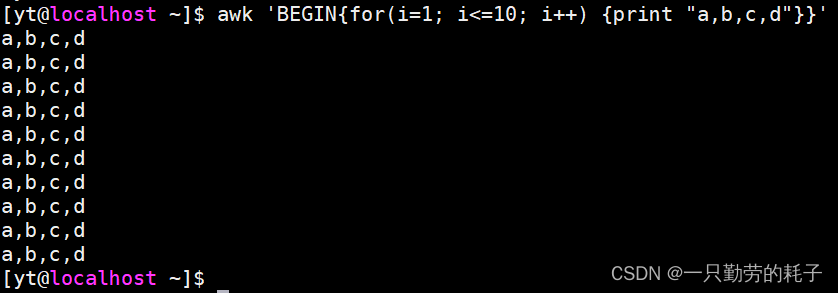
3.2. awk 循环输出
awk 同样支持 for 循环或 while 循环,语法如下
awk 'BEGIN{
for(i=1; i<=10; i++){
print "a,b,c,d"
}
}'
????????
使用循环也就可以使用变量
awk 'BEGIN{
for(i=1; i<=10; i++){
print i, "a,b,c,d"
}
}'
????????
3.3. awk 指定分隔符
awk 通过 OFS 来指定分隔符
awk 'BEGIN{OFS="、"; print "A", "OO", 123}'
????????
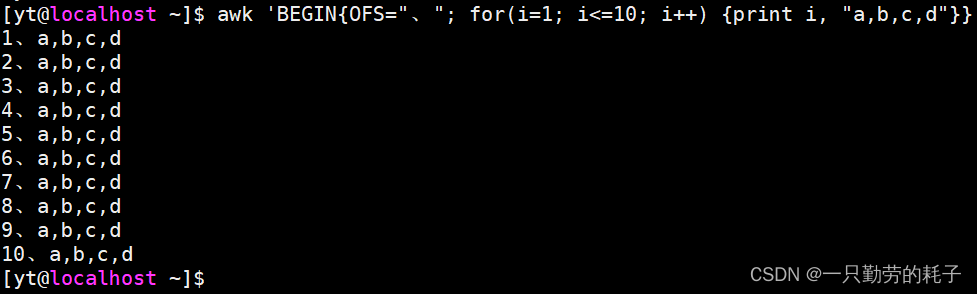
将方法带入循环中
awk 'BEGIN{
OFS="、"
for(i=1; i<=10; i++){
print i, "a,b,c,d"
}
}'
????????
3.4. awk 随机数
awk 通过?srand() 来生成随机数(范围:0~1)
awk 'BEGIN{srand(); print rand()}'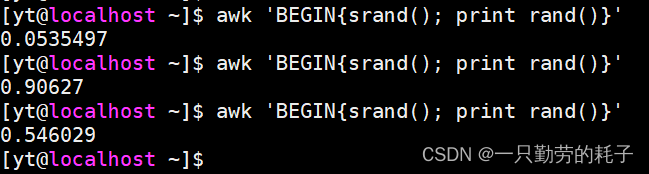
????????
取整,设定范围0~100
awk 'BEGIN{srand(); print int(rand() * 100)}'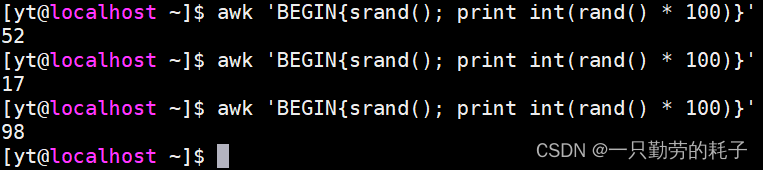
????????
将方法带入循环中
awk 'BEGIN{
?srand()
for(i=1; i<=10; i++){
print rand()*100, "a,b,c,d"
}
}'
awk 'BEGIN{srand(); for(i=1; i<=10; i++){print rand()*100, "a,b,c,d"}}'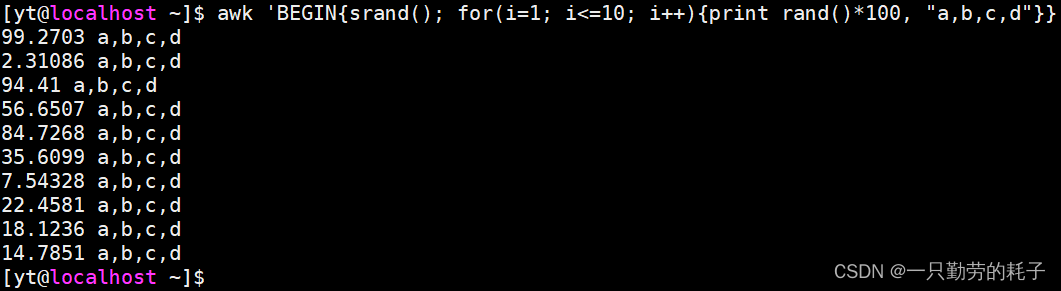
????????
3.5. awk 随机字符
awk 内置函数中没有随机字符串,所以通过随机数转换为ASCII码对应的字母
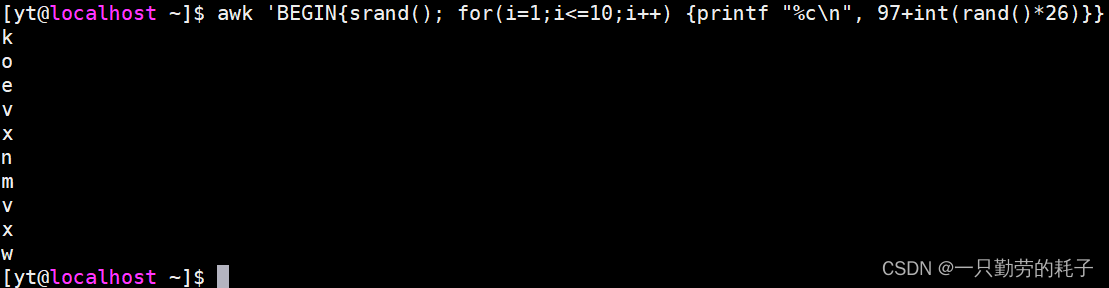
awk 'BEGIN{
srand()
for(i=1;i<=10;i++){
printf "%c\n", 97+int(rand()*26)
}
}'
????????
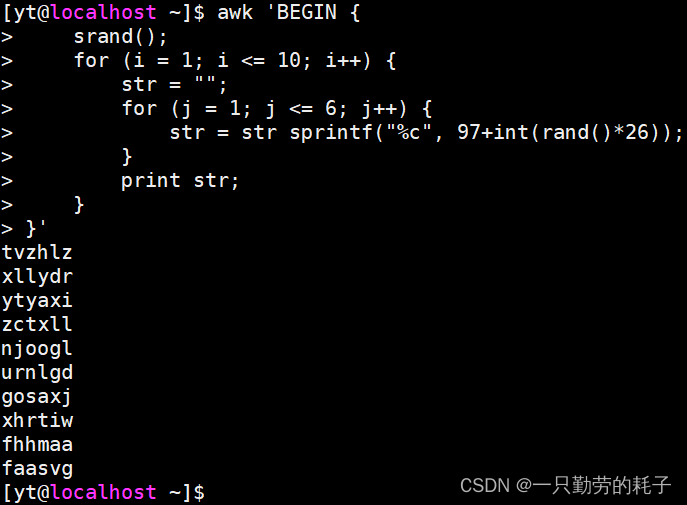
由于每次只能打印1个字符,这也就意味着打印单行n个字符,需要循环n次。
awk 'BEGIN {
srand();
for (i = 1; i <= 10; i++) {
str = "";
for (j = 1; j <= 6; j++) {
str = str sprintf("%c", 97+int(rand()*26));
}
print str;
}
}'
????????
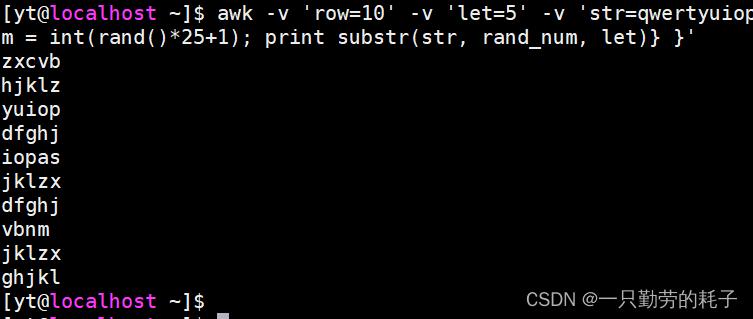
换一种方式输出,不需要循环多次
awk -v 'row=10' -v 'let=5' -v 'str=qwertyuiopasdfghjklzxcvbnm' 'BEGIN{
srand()
for (i=1; i<=row; i++){
rand_num = int(rand()*25+1)
print substr(str, rand_num, let)
}
}'
????????
来对比一下两种方式的效率(输出100w行数据)
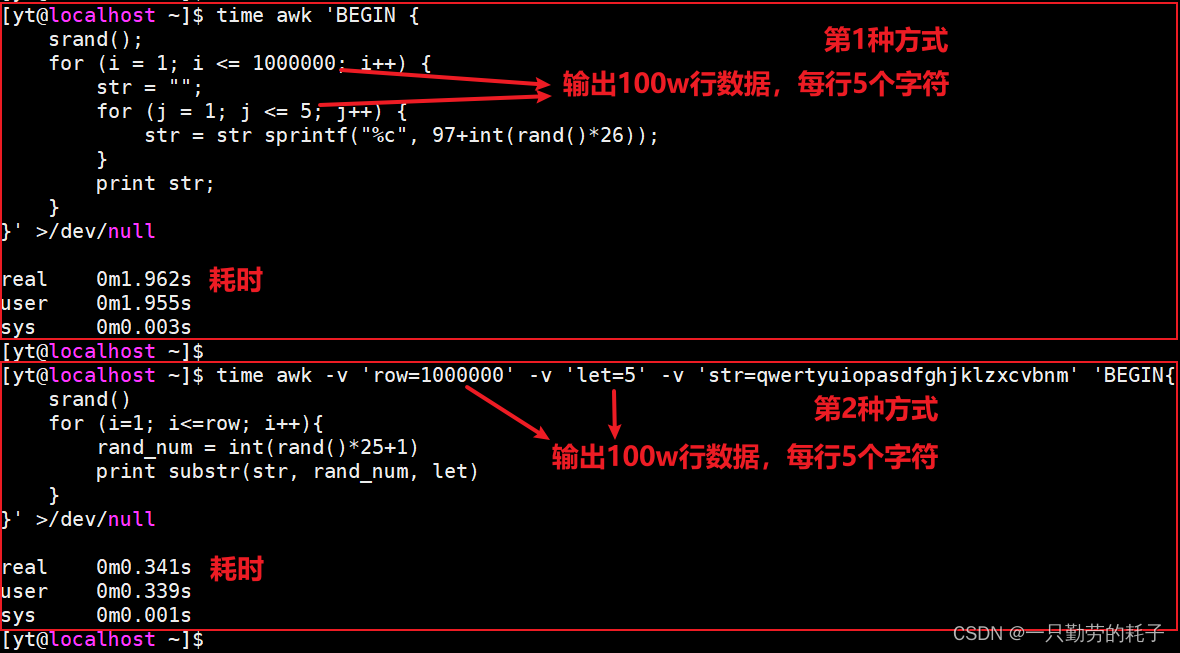
第1种方式在输出随机字符串长度时增加了循环的次数,所以第2种方式效率远高于第1种。
????????
3.6. awk 构造数据
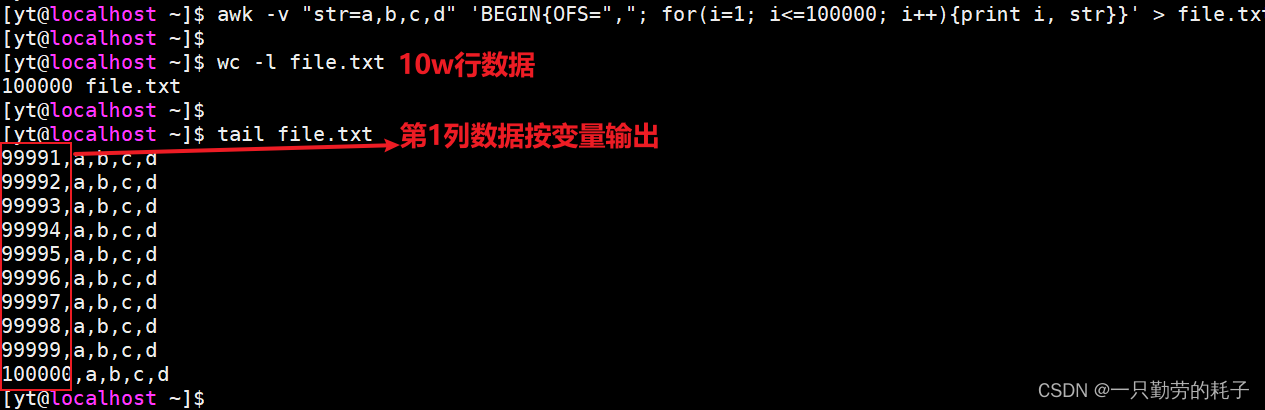
【案例一】构造10w行数据
awk -v "str=a,b,c,d" '
BEGIN{
OFS=","
for(i=1; i<=100000; i++){
print i, str
}
}'
????????
【案例二】构造1GB数据
awk -v 'str=a,b,c' '
BEGIN{
i=1
while (i > 0){
print i","str
i++
}
}' |head -c 1G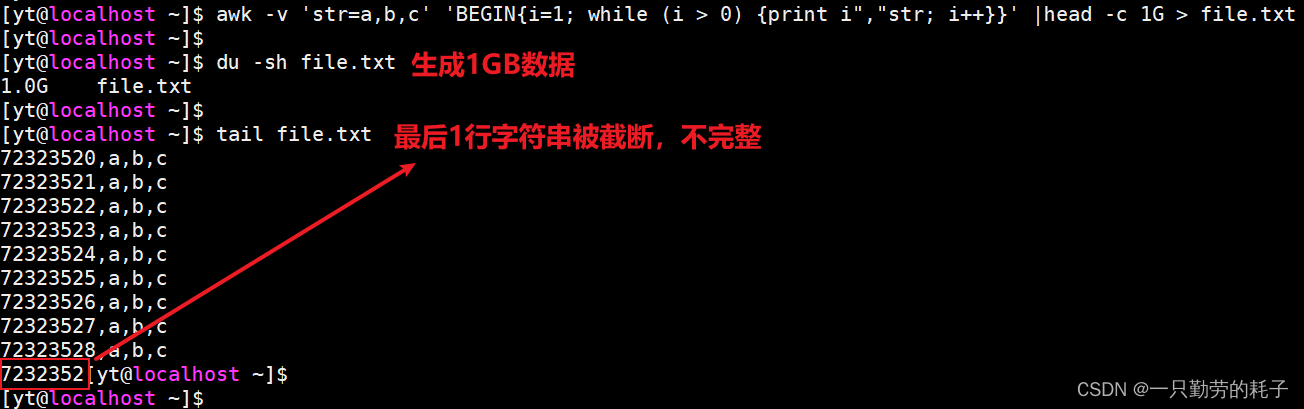
最后1行不完整,同样可以使用sed来处理
awk -v 'str=a,b,c' '
BEGIN{
i=1
while (i > 0){
print i","str
i++
}
}' |head -c 1G |sed -n '$!p'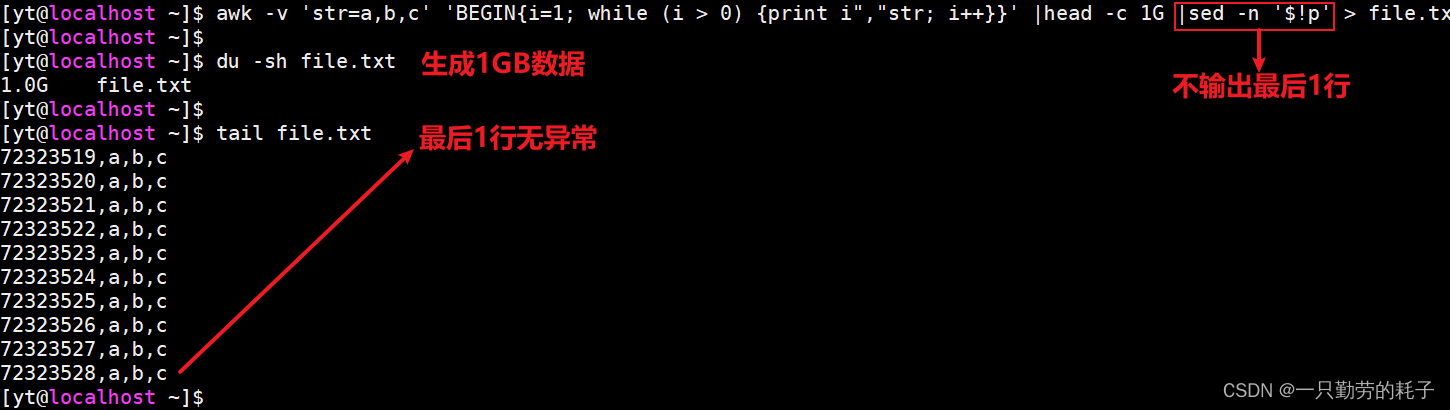
????????
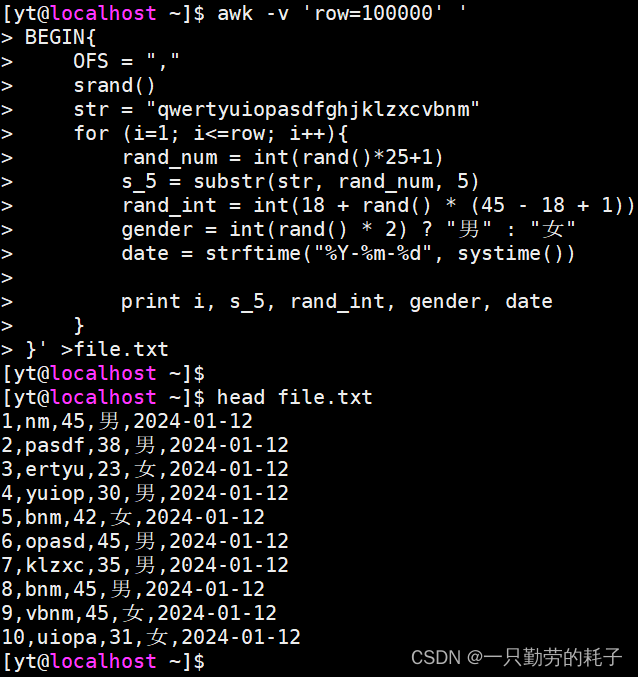
【案例三】构造复杂数据
- 生成10w行数据
- 第1列为1~100000
- 第2列为5个随机字符
- 第3列为18~45的整数
- 第4列为男或女
- 第5列为日期
awk -v 'row=100000' '
BEGIN{
OFS = ","
srand()
str = "qwertyuiopasdfghjklzxcvbnm"
for (i=1; i<=row; i++){
rand_num = int(rand()*25+1)
s_5 = substr(str, rand_num, 5)
rand_int = int(18 + rand() * (45 - 18 + 1))
gender = int(rand() * 2) ? "男" : "女"
date = strftime("%Y-%m-%d", systime())
print i, s_5, rand_int, gender, date
}
}'
????????
4. 总结
先看一下 shell 循环、dd、yes、awk 等命令的效率:
1、shell 循环生成100MB 数据(51.561秒)

2、awk?生成 100MB 数据(1.1秒)

3、yes?生成 100MB 数据(0.313秒)

?4、dd 生成 100MB 数据(0.123秒)
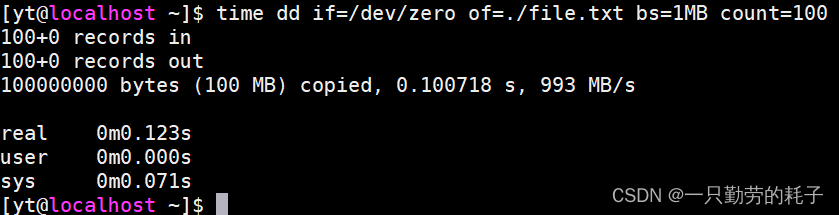
????????
| 构造数据方法 | 100MB 耗时 | 字符串类型 |
| shell 循环 | 51.561 秒 | 自定义各种类型 |
| awk 命令 | 1.100 秒 | 自定义各种类型 |
| yes 命令 | 0.313 秒 | 只能固定字符 |
| dd 命令 | 0.123 秒 | 二进制类型 |
- 从效率来看,最快的方法是 dd,其次 yes、awk,shell 相比于前几种方法效率太低。
- 从能力上看,shell和awk都支持自定义字符,而yes仅支持固定字符,dd仅支持二进制字符。
????????
总结
- 如果仅需要一个大文件,dd 效率最高。
- 如果需要一个固定字符的文件,yes 效率最高。
- 如果需要各种不同类型的字符,awk 最为合适。
- shell 效率太低,不建议。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 51单片机_简易自动电容测量仪&简易延时万用表
- AcWing.895.最长上升子序列
- java/php/node.js/python电影推荐网站【2024年毕设】
- 新零售模式:零售行业升级,自动售货机一招搞定!
- Linux常用命令02(解压、输出重定向、vim编辑、用户组、用户、权限,时间)
- 在Linux中tomcat出现乱码
- 数据库连接问题 - ChatGPT对自身的定位
- 灰度图存储 - 华为OD统一考试(C卷)
- Linux中必知必会的mount命令
- Mybatis Java API - 目录结构