Flume基础知识(五):Flume实战之实时监控目录下多个新文件
发布时间:2024年01月04日
1)案例需求:
使用 Flume 监听整个目录的文件,并上传至 HDFS
2)需求分析:

3)实现步骤:
(1)创建配置文件 flume-dir-hdfs.conf
创建一个文件
vim flume-dir-hdfs.conf 添加如下内容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
?
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp 结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
?
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop100:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
(2)启动监控文件夹命令
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf 说明:在使用 Spooling Directory Source 时,不要在监控目录中创建并持续修改文件;上传完成的文件会以.COMPLETED 结尾;被监控文件夹每 500 毫秒扫描一次文件变动。
(3)向 upload 文件夹中添加文件
在/opt/module/flume 目录下创建 upload 文件夹
[root@hadoop100 flume]$ mkdir upload向 upload 文件夹中添加文件
[root@hadoop100 upload]$ touch atguigu.txt
[root@hadoop100 upload]$ touch atguigu.tmp
[root@hadoop100 upload]$ touch atguigu.log(4)查看 HDFS 上的数据
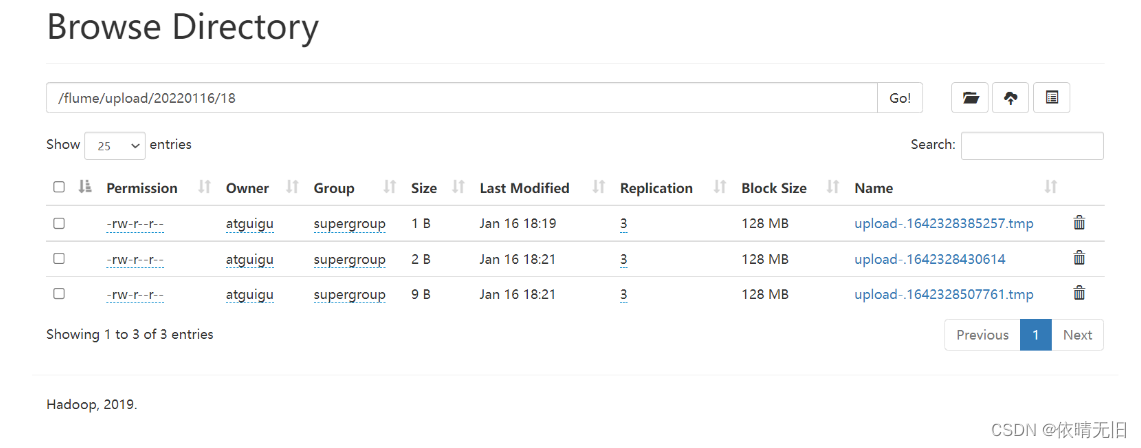
flume只会上传新目录,.tmp文件不会上传,自己加的.COMPLETED也不会上传。同时已经上传了的文件再修改upload文件里面的内容,hdfs是不会同步内容的。如果删除upload文件中的文件,在创建同名的,flume只会把它当作一个新文件上传到hdfs,不会覆盖原来同名的文件。
- Exec:不能断点续传
- spooldir:不能监控动态变化的文件
文章来源:https://blog.csdn.net/zuodingquan666/article/details/135377754
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 高级鉴权验签方式的实践,技术方案为注解+ASCII排序+多类型多层级动态拼接+RSA加密(或国密SM2)+Base64+Redis滑动窗口限流
- java基础知识②:多线程编程、IO流和网络编程、泛型、集合框架
- Python私教MongoDB快速入门教程
- 用webstorm学习Vue的时候提示未解析的变量或类型怎么办?
- 如何在Beta测试中进行版本管理和控制
- 数据采集来源有哪些?怎么做?
- 2024华数杯国际赛A题16页完整思路+五小问py代码数据集+后续高质量参考论文
- 自学(网络安全)黑客——高效学习2024
- Java项目:123SSM高校运动会信息管理系统
- git 使用场景 --amend 提交