不要再搞混标准化与归一化啦,数据标准化与数据归一化的区别!!
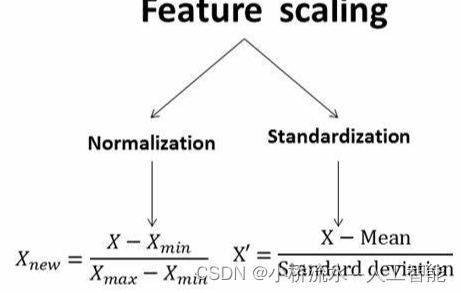
1. 数据的标准化(Standardization):
数据的标准化是将数据按照一定的数学规则进行转换,使得数据满足特定的标准,通常是使数据满足正态分布或标准差为1的标准。
标准化的常见方法包括最小-最大标准化和Z-score标准化。最小-最大标准化将数据映射到[0,1]的范围内,最小-最大标准化将数据映射到0-1区间,公式为(x-min)/(max-min)。而Z-score标准化则根据数据的均值和标准差进行转换。z-score标准化将数据映射到平均值为0、标准差为1的正态分布,公式为(x-μ)/σ
标准化主要用于消除不同变量之间的量纲和单位差异,使数据具有相同的规模和量纲,从而能够更好地进行比较和分析。标准化是线性变换,通过数学公式将原始数据转换为标准化的数据。
2. 数据的归一化(Normalization):
数据的归一化是将数据缩放到一个较小的区间内,通常是[0,1]或[-1,1]的区间。归一化主要关注的是将数据的值压缩到一个较小的范围,以便于处理和分析。归一化通常用于消除数据的尺度或单位差异,使不同变量的数据能够进行比较和分析。
归一化可以通过简单的除法或减法实现,即将原始数据除以某个特定的值或减去某个特定的值,使得结果落入指定的区间内。与标准化不同,归一化不关注数据的分布特性,只关注将数据的值压缩到一个较小的范围。
总结(数据标准化和数据归一化的不同之处和相同之处)
不同之处:
-
目的不同。数据标准化主要目的是消除量纲影响,数据归一化主要目的是加快模型收敛速度。 -
方法不同。数据标准化常用最小-最大标准化或z-score标准化,数据归一化常用线性转换到固定区间。 -
影响不同。数据标准化主要影响数据的比较,数据归一化主要影响模型训练效果。
相同之处:
-
都是数据预处理技术,目的是对原始数据进行转换。 -
都将数据映射到
固定范围内,数据标准化映射到平均值为0、标准差为1,数据归一化映射到0-1或-1-1区间。 -
都可以
消除大数小数问题,加强数据的可比性。 -
在机器学习模型训练前都常被作为标准步骤使用,目的是为后续模型训练提供
更好的数据分布。 -
转换后的数据维度和数量级
与原始数据一致,只是进行了线性转换,不会丢失原始数据信息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uniapp uview实现u-popup左侧弹起时铺满屏幕
- sprignboot电商书城源码
- js的打印(输出)方式有console.log(),console.dir(),console.table()
- Linux中静态库和动态库的使用
- Linux-keepalived的安装及应用
- C# Entity Framework 中不同的数据的加载方式
- 【Java 设计模式】设计原则之单一职责原则
- Java基础知识回顾
- 践行健康生活方式,积极应对严寒天气
- Simulink之Signal