【占用网络】FlashOcc:快速、易部署的占用预测模型
前言
FlashOcc是一个快速、节约内存、易部署的占用预测模型。
它首先采用2D卷积提取图形信息,生成BEV特征。然后通过通道到高度变换,将BEV特征提升到3D空间特征。
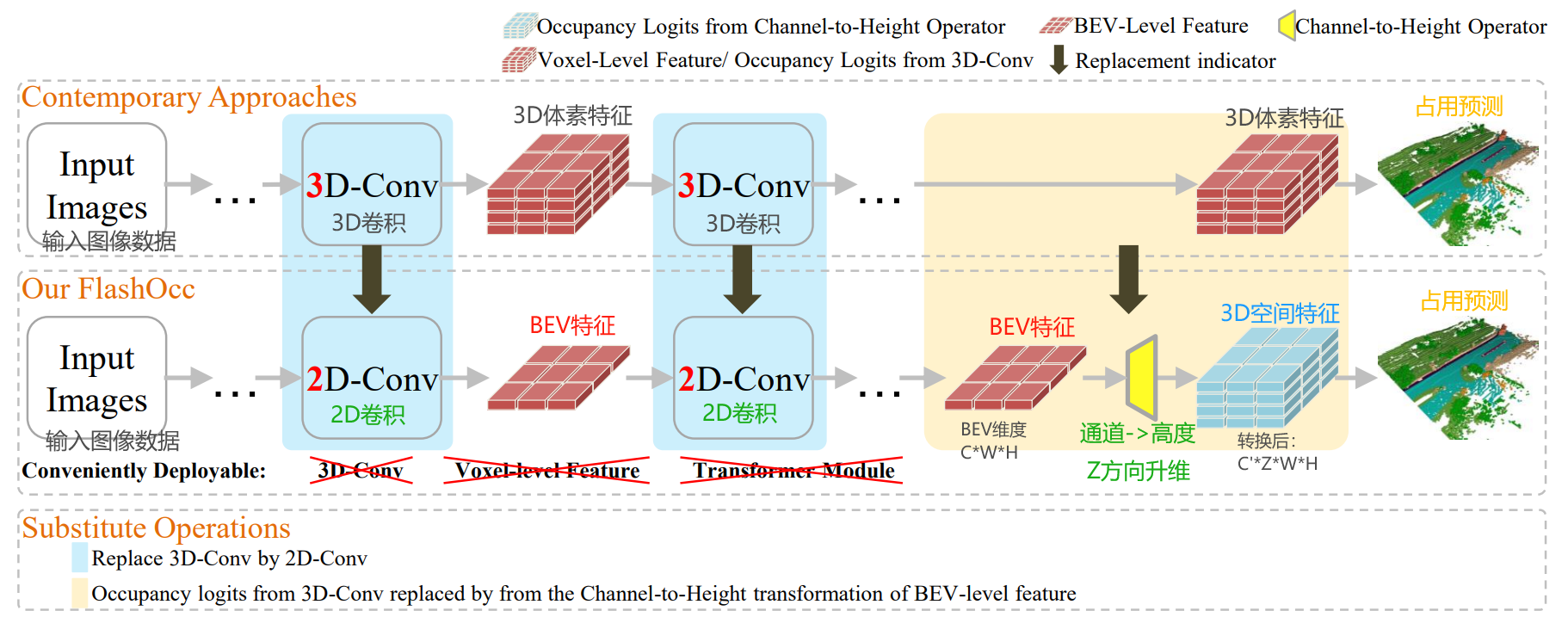
对于常规的占用预测模型,将3D卷积改为2D卷积,将三维体素特征改为BEV特征。而且不用Transformer注意力算子。
论文地址:FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
代码地址:https://github.com/Yzichen/FlashOCC

一、设计背景
占用预测,能解决3D感知中的三个问题:复杂形状缺失、长尾缺陷、无限类别。
- 复杂形状缺失: 有些物体的形状很复杂,无法描述细节和几何形状。比如,一辆挖掘机,由机械臂和车身组成,用3D目标检测只能框出这是一个矩形体,无法知道那部分是机械臂。
- 长尾缺陷问题: 在现实世界中,某些物体出现得很少,而另一些则很常见。比如,在路上,普通汽车和卡车很多,但冰淇淋车或救护车就比较少,识别那些不常见的物体就比较难。
- 无限类别问题:在真实世界中,存在数以万计的不同物体,常规训练任务中,只能识别的有限数量的类别。实际场景中会遇到预定义类之外的目标。

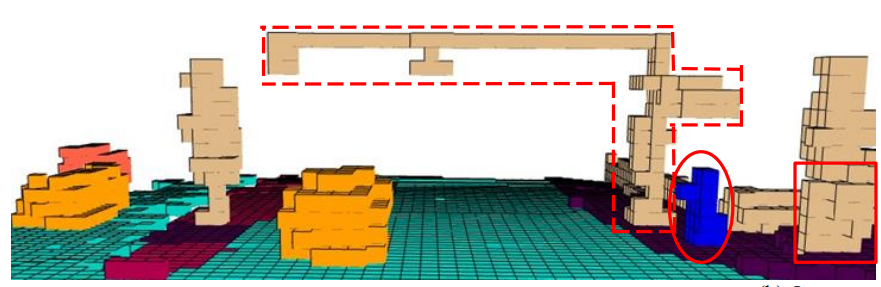
占用预测: 判断周围空间中哪些部分被物体占据,哪些是空的。
为了进行占用预测,一种常见的方法是使用三维体素来表示物体和环境。这种方法可以提供非常详细的三维信息,但问题在于它需要大量的内存和计算资源。
因为体素是以三维网格的形式存在的,所以当细节级别增加时,所需处理的数据量会呈指数级增长。
同时当前大多占用预测模型使用Transformer注意力等复杂算子,阻碍了占用预测部署。
二、设计思路
当前部分占用预测模型的思路是模型变得更大、更复杂,以获得高的精度。FlashOcc认为理想的框架,应该对不同的芯片进行部署友好,同时保持高精度。
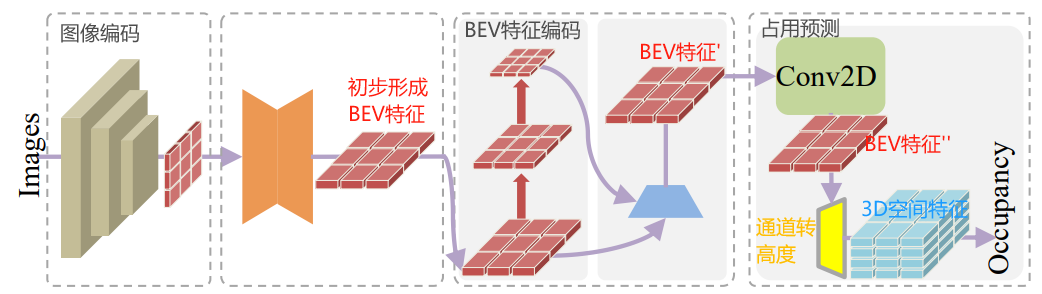
FlashOcc首先采用2D卷积提取图形信息,生成BEV特征。然后通过通道到高度变换,将BEV特征提升到3D空间特征。
其中,通道到高度变换是指。channel-to-height transformation。
算子改进:对于常规的占用预测模型,将3D卷积改为2D卷积,将三维体素特征改为BEV特征。而且不用Transformer注意力算子。
特点:快速、节约内存、易部署。
三、模型框架
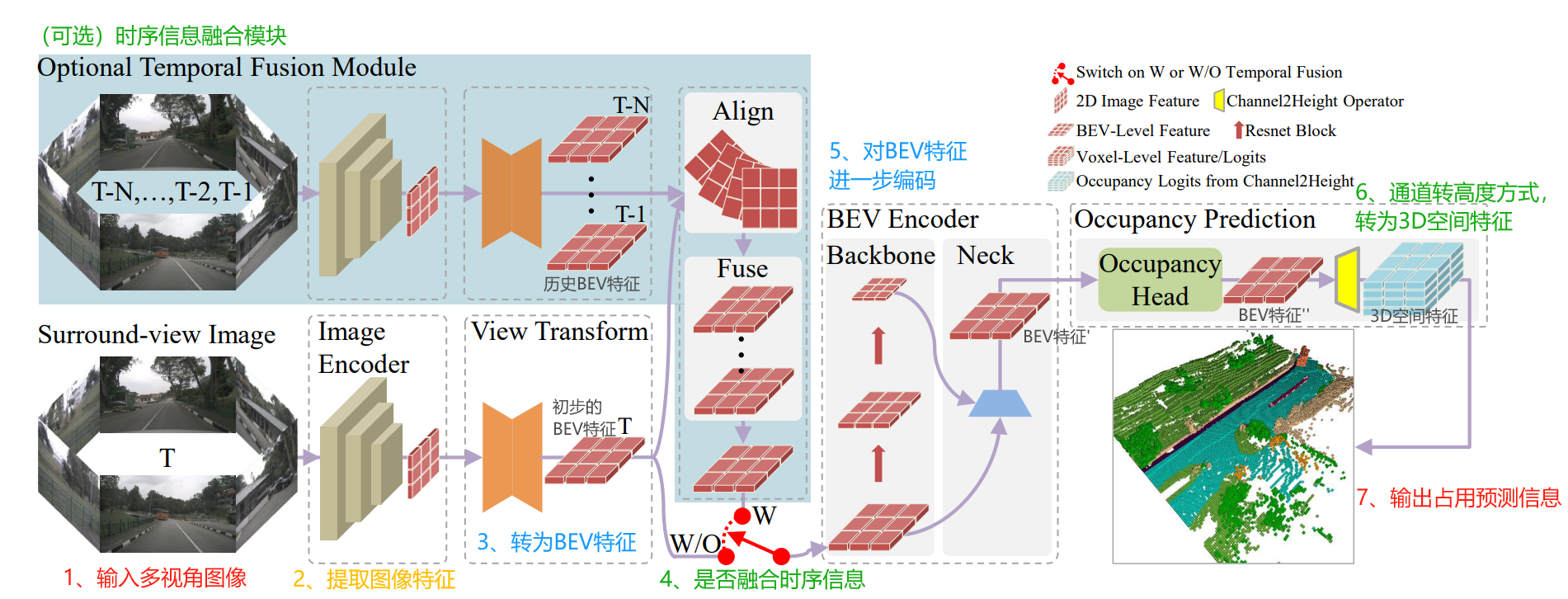
FlashOcc的模型框架如下图所示,核心步骤分为7步:
- 输入多视角图像数据,比如6个相机组成的,同时输入6张图像。
- 经过主干网络,提取图像信息,生成图像特征。
- 通过LSS(Lift-splat-shot)思路,将2D图像特征转为BEV特征,形成初步的BEV特征。
- 得到初步的BEV特征,可以选择是否使用“时序信息融合模块”。如果使用的,会融合历史的BEV特征信息。如果不用,进入直接下一步。
- 对BEV特征进一步编码,提取特征,形成BEV特征'。
- BEV特征'经过占用头的处理,得到BEV特征'';接着,通过通道到高度变换,将BEV特征''提升到3D空间特征。
- 输出占用预测信息。
其中,通道到高度变换,是指将BEV特征(BxCxWxH),转为3D空间特征(BxC'xZxWxH)。
这里的B是指batch size,C是指BEV的特征通道数量,C'是指3D空间特征通道(类别数量);C =?C' x?Z,对应通道到高度变换思想。
W,H,Z分别对应三维空间中x,y,z的维度。
它由5个关键模型组成:
- 2D图像编码器:这个模块的任务是从由多个摄像头捕获的图像中提取特征。这些特征可能包括物体的形状、大小、颜色等,对于理解图像内容至关重要。
- 视图转换模块:该模块负责将2D感知图像特征,转换到鸟瞰视图(BEV)空间表示。
- BEV编码器:在完成视图转换后,BEV编码器处理鸟瞰视图中的特征信息。这一步进一步加工特征,使其适应于三维空间分析。
- 占用预测模块:这个模块的核心任务是预测每个体素(三维空间中的一个小立方体,类似于二维图像中的像素)是否被占用。这是通过分析前面模块提供的数据来完成的。
- 时间融合模块(可选):这个模块不是必须的,但可以用来提高模型的性能。它通过融合历史信息(如之前的观察或预测)来提供更准确的占用预测。
?细节展开,下图是常规的占用预测模型,使用3D体素特征表示,并用到3D卷积和Transformer等算子。

下图是FlashOcc模型,使用BEV特征表示,只用到2D卷积算子。
补充介绍一下LSS,它全称是Lift-Splat-Shoot,它先从车辆周围的多个摄像头拍摄到的图像进行特征提取,在特征图中估计出每个点的深度,然后把这些点“提升”到3D空间中。
接着,这些3D信息被放置到一个网格上,最后将这些信息“拍扁”到一个平面视图上,形成BEV特征图。?
- Lift,是提升的意思,2D → 3D特征转换模块,将二维图像特征生成3D特征;即:对每个像素预测深度值,然后结合相机内外参,投影到3D空间中。
- Splat,是展开的意思,3D → BEV特征编码模块,把3D特征“拍扁”得到BEV特征图;由于一个BEV网格可能对应多个3D点,需要进行融合得到该网格的特征。
- Shooting,是指在BEV特征图上进行相关任务操作,比如检测、分割、轨迹预测等。(本文不用这一步,因为后面会将BEV特征转为3D空间特征,进行占用信息预测的)
详细信息,看我这篇博客:【BEV感知 LSS方案】Lift-Splat-Shoot 论文精读与代码实现-CSDN博客
四、实验测试与效果
在Occ3D-nuScenes评估数据集上,进行的3D占用预测性能测试。
表格中最后两行,将BEVDetOcc和UniOcc中组建替换为FlashOcc后,精度都得到了提升。

- 星号(*)表示这些模型在训练前已经在FCOS3D模型上进行了预训练。
- “FO”是FlashOcc的缩写,而“FO()”表示对应名为“”的模型进行插件替换。
下面表格展示了训练细节信息:
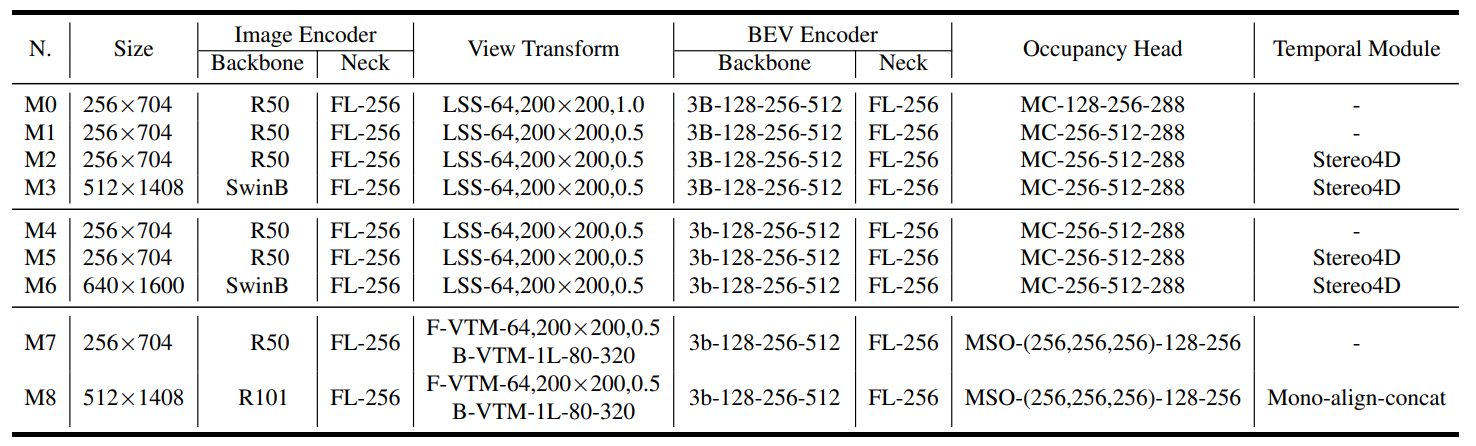
- “FL”是FPN LSS的缩写。
- “MC”代表多卷积头。
- MSO指的是指多尺度占用预测头。
- F-VTM和B-VTM分别表示前向投影和深度感知的后向投影。
- Stereo4D指的是使用立体声体积来增强LSS的深度预测,而不包括来自上一帧的BEV特征。
- Mono-align-concat表示使用单目深度预测用于LSS,其中历史帧的bev特征被对齐并沿通道连接。
在训练和部署期间,资源消耗分析。FPS是在单个RTX3090上通过tensorrt以fp16精度测试的。
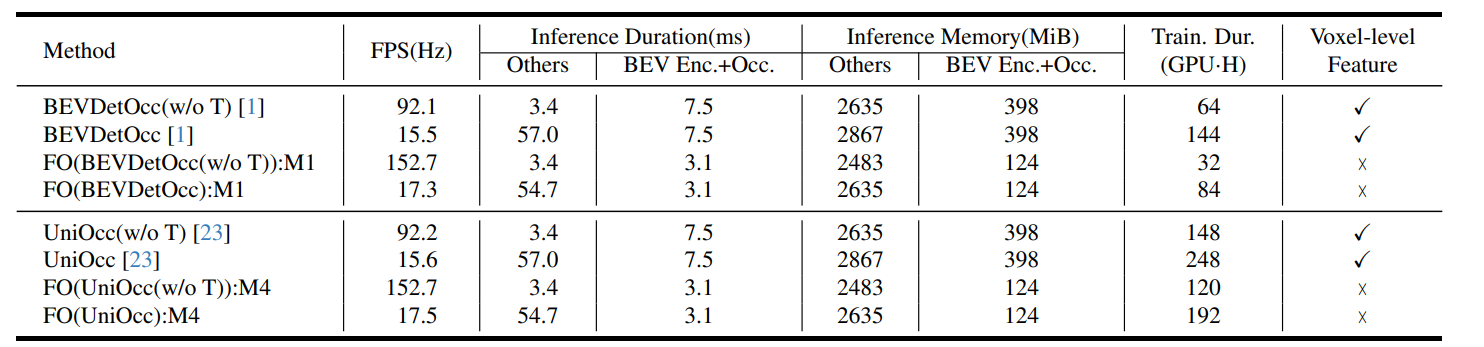
- “Train. Dur.”是训练持续时间的缩写。
- “Enc.”、“Occ.”和“Feat”分别代表编码器、占用预测和特征。
- “GPU·H”表示“1个GPU × 1小时”。
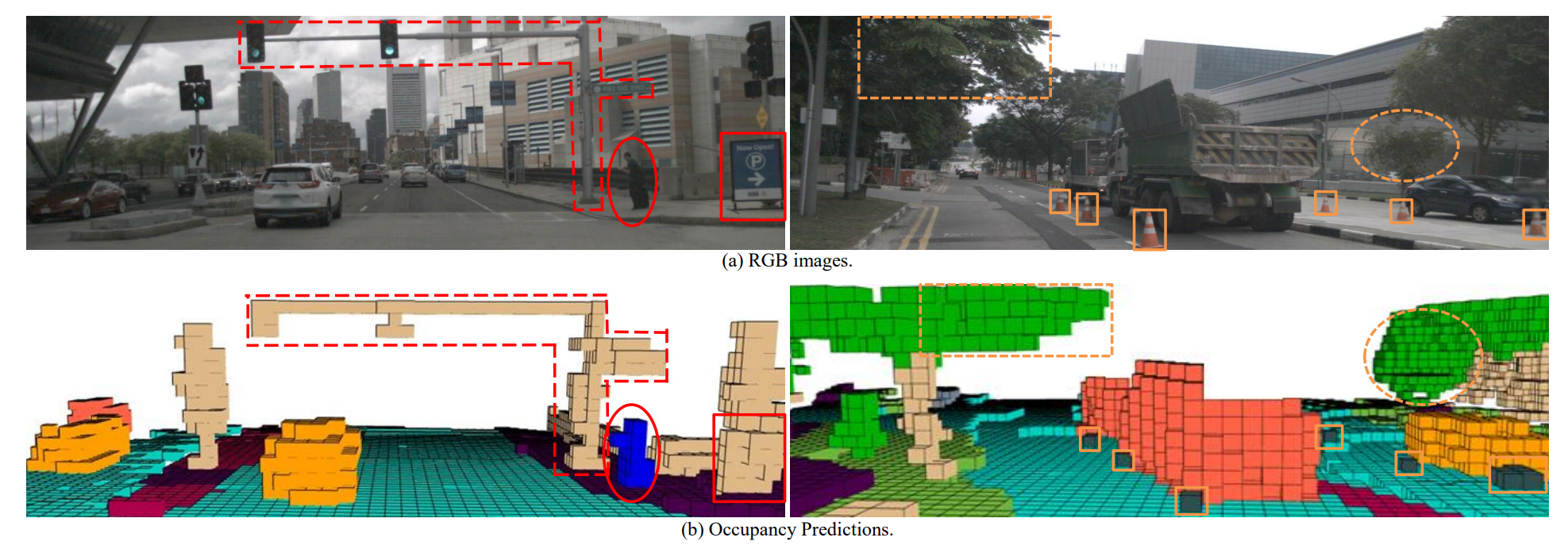
模型预测效果
分享完成~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《WebKit 技术内幕》之六(2): CSS解释器和样式布局
- unity C#中Array、Stack、Queue、Dictionary、HashSet优缺点和使用场景总结
- C/C++ 知识点:类静态成员初始化
- 一种用于解决子图同构问题的子图特定因子
- 【华为 ICT & HCIA & eNSP 习题汇总】——题目集2
- 《2023直播电商数字化引领者》&《2023最受欢迎直播电商消费品牌TOP100 》榜单征集正式启动!
- SAP ABAP搜索帮助F4
- TypeScript快速入门
- uni-table 固定表头与数据导出为xlsx
- K8S学习指南(57)-K8S核心组件Kube-Proxy简介