streamlit中文开发手册(详细版)
目录
一、安装与配置
1.1 安装 Streamlit
可以使用pip包管理器安装 Streamlit。在终端或命令提示符中运行以下命令:
pip install streamlit1.2 配置文件
在某些情况下,可能需要配置Streamlit,配置文件的位置是 ~/.streamlit/config.toml(windows系统中为:C:\Users\Administrator\.streamlit)。如果没有这个文件,你可以自己创建一个。
以下是一个config.toml示例:
[server]
port = 8501
enableCORS = false
[browser]
serverAddress = "localhost"
gatherUsageStats = false
[runner]
magicEnabled = false注意:在config.toml文件中,大小写是敏感的,确保配置文件中的各个部分和参数名的大小写一致。
参数:
1、port:Streamlit应用的端口号,默认为 8501。
2、enableCORS:是否启用跨域资源共享,默认为false。如果需要开放Streamlit应用,在非本机电脑也行访问,则需要设置为true。
3、serverAddress:Streamlit服务器的地址,默认为 "localhost"。
4、gatherUsageStats参数默认是true,表示允许streamlit收集使用统计信息。一般禁用就行。
5、magicEnabled参数的默认值是true,表示启用Streamlit的魔法命令功能。即:任何时候如果Streamlit看到一个变量或常量值, 它就会自动将其使用st.write写入应用。所以可能容易导致网页速度变慢、重复加载数据等等情况。
命令行查看streamlit配置信息:
streamlit config show1.3 运行Streamlit应用
运行streamlit演示项目:
streamlit hello上面有4个示例项目:

如果需要运行你自己的py文件,在终端或命令提示符中运行:
streamlit run your_app.py在运行上述命令后,你的默认浏览器将自动跳转Streamlit应用。
二、streamlit显示数据
首先,导入streamlit包:
import streamlit as st2.1 显示标题
st.title():用于创建页面的主要标题,通常是最大和最显眼的标题。它是在应用的顶部设置的,并且在整个页面中通常只使用一次,用于表示应用的主题或总体内容。
st.header():用于创建一个相对较小的标题,比st.title()稍微小一些。可以在应用中多次使用,用于将内容分成不同的部分或主题。
st.subheader():用于创建相对较小的标题,比st.header()还要小。可以在应用中多次使用,用于在小节内更细致地标识内容。
总体来说,这些函数可以根据文档结构和内容的层次结构来选择使用。使用st.title()来设置整个应用的主标题,使用st.header()和st.subheader()来划分和标识各个部分或小节的标题。这样可以使应用更易于阅读和理解。
import streamlit as st
st.title("这是一个标题")
st.header("这是一个较小的标题")
st.subheader("这是一个相对较小的标题")
2.2 显示文本
st.markdown():用于支持Markdown格式的文本,允许你使用Markdown语法来添加样式、链接、列表等元素。它提供更灵活的文本呈现选项,允许你使用Markdown标记来创建富文本内容。
st.text():不支持Markdown语法,只显示纯文本内容。
import streamlit as st
st.markdown('''
# 静夜思
床前**明月**光,疑是地上霜。
举头望**明月**,低头思故乡。
''')
st.text('''
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
''')
可以看到,Markdown打印方式更灵活,而text打印方式较为单一。
2.3 显示代码段
st.code()调用参数如下:
body:要显示的代码字符串。
language:代码所使用的开发语言,字符串,默认值:python。 如果省略的话,将没有语法高亮效果。
import streamlit as st
st.markdown('**以下为打印的代码:**')
st.code('''
def bubble_sort(arr):
n = len(arr)
# 遍历所有数组元素
for i in range(n):
# 最后 i 个元素已经排好序,不需要再比较
for j in range(0, n-i-1):
# 如果元素比下一个元素大,则交换它们
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
# 示例使用
if __name__ == "__main__":
# 测试数据
example_list = [64, 34, 25, 12, 22, 11, 90]
print("原始数组:", example_list)
# 调用冒泡排序函数
bubble_sort(example_list)
print("排序后的数组:", example_list)
''', language='python')效果如下:

2.4 通用显示方法
st.write():是Streamlit中用于在应用程序中展示文本和数据的通用函数。它是一个多功能的函数,可以接受多种类型的参数,包括Markdown格式的字符串、数字、DataFrame、图表等。
import streamlit as st
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 字符串
st.write("这是一段文本。")
# 数字
st.write(42)
# 列表
st.write([1, 2, 3])
# 字典
st.write({"key": "value"})
# 数据框(DataFrame)
df = pd.DataFrame({"Column 1": [1, 2, 3], "Column 2": ["A", "B", "C"]})
st.write(df)
#多参数用法
st.write("这是一个字符串", 42, [1, 2, 3], {"key": "value"})
#自定义渲染
fig, ax = plt.subplots()
x = np.linspace(0, 10, 100)
y = np.sin(x)
ax.plot(x, y)
st.write(fig)效果如下:


2.5 显示表格
st.dataframe():以表格的形式呈现数据,支持Pandas的特有功能,如排序、过滤等,并且会自动适应数据框的大小,如果数据框太大,它会自动启用滚动条。
参数如下:
①width:UI元素的期望宽度,单位为像素,类型为Int或None,如果是None的话,Streamlit将基于页面宽度计算元素宽度。
②height:UI元素的期望高度,单位为像素,类型为Int或None。
st.table():用于显示通用表格数据,不仅支持Pandas,还可以处理列表、元组等可迭代数据结构。但st.table仅用于显示数据,而不提供诸如排序和过滤等数据框专有功能。
import streamlit as st
import pandas as pd
import numpy as np
random_data = np.random.rand(100, 10)
df = pd.DataFrame(random_data, columns=[f'Col{i}' for i in range(1, 11)])
st.dataframe(df)
st.table(df)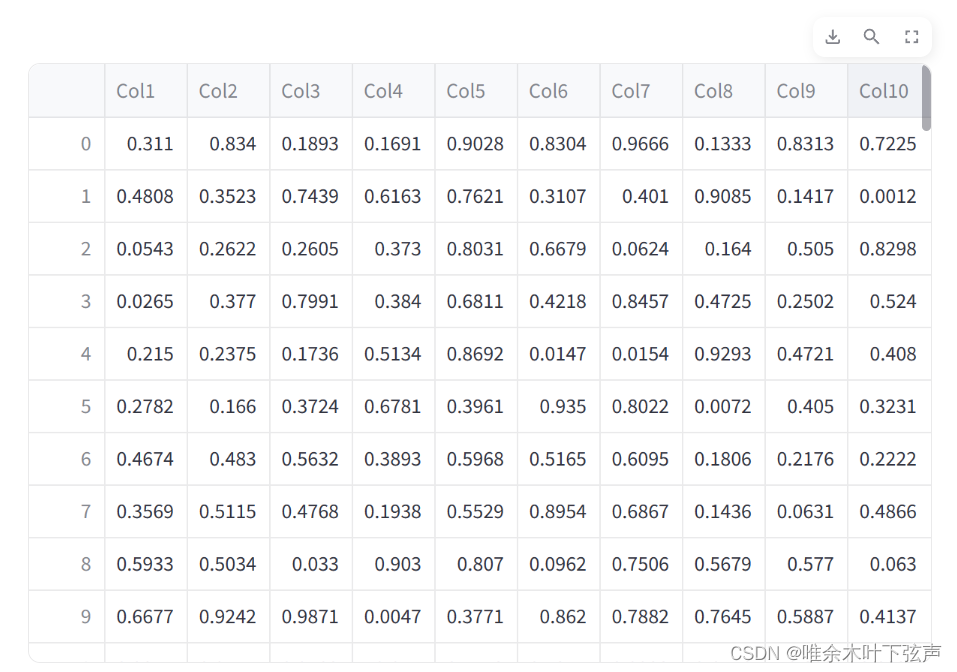
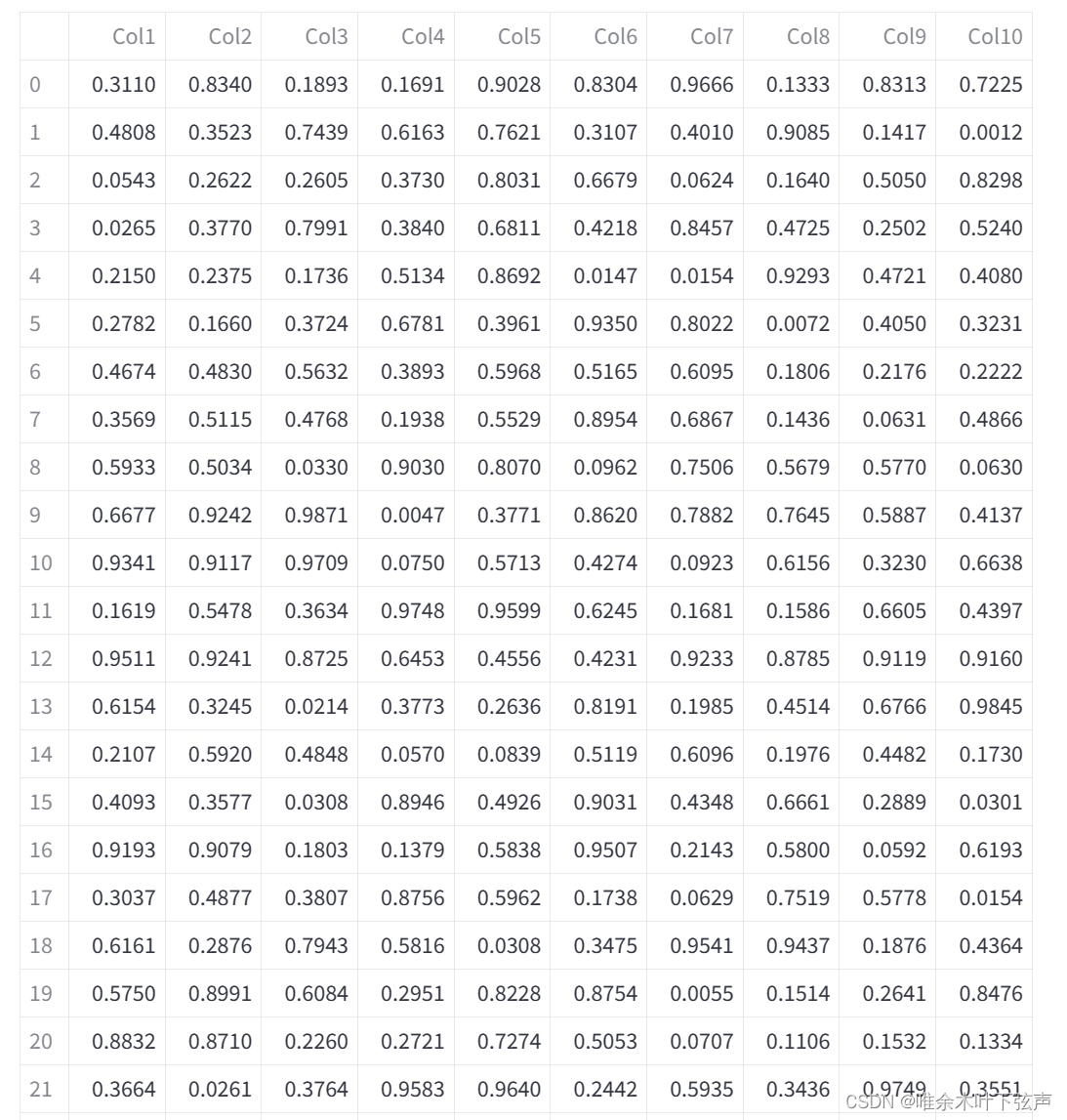
如上所示,st.dataframe打印出来的表格可以缩放、下载、滑动、查找等功能,而st.table是将所有数据行和列都打印出来,功能单一。
另外,st.dataframe还可以传入一个Pandas Styler对象来修改所渲染的DataFrame的样式,例如将每一列的最大值高亮显示:
st.dataframe(df.style.highlight_max(axis=0))
2.6 显示JSON
st.json():主要用于展示JSON格式的数据,会自动适应JSON数据的大小,如果数据较大会自动启用滚动条,并且可以处理包含嵌套结构的复杂JSON数据,以树状结构的形式展示。
import streamlit as st
st.json({
'foo': 'bar',
'baz': 'boz',
'stuff': [
'stuff 1',
'stuff 2',
'stuff 3',
'stuff 5',
],
})
2.7 显示pyplot图表
st.pyplot():用于显示指定的matplotlib.pyplot图表。
Matplotlib支持几种不同的后端。如果在Streamlit中使用Matplotlib出现问题, 可以尝试将后端设置为 “TkAgg”:
echo "backend: TkAgg" >> ~/.matplotlib/matplotlibrcimport streamlit as st
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
plt.plot(x, y1, label='sin(x)')
plt.plot(x, y2, label='cos(x)')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
st.pyplot()
2.8 显示地图
st.map():显示地图及叠加的数据点,支持自动居中与自动缩放。
参数:
data:要显示的数据,必须包含字段lat、lon、latitude或longitude,可以是DataFrame、Styler、数组以及其他可迭代对象等类型:
zoom:缩放等级。
use_container_width (bool): 是否使用容器的整个宽度。如果设置为True,地图将占据整个容器的宽度。
import streamlit as st
data = {
'latitude': [37.7749, 34.0522, 40.7128],
'longitude': [-122.4194, -118.2437, -74.0060],
'name': ['San Francisco', 'Los Angeles', 'New York']
}
st.map(data, zoom=4, use_container_width=True)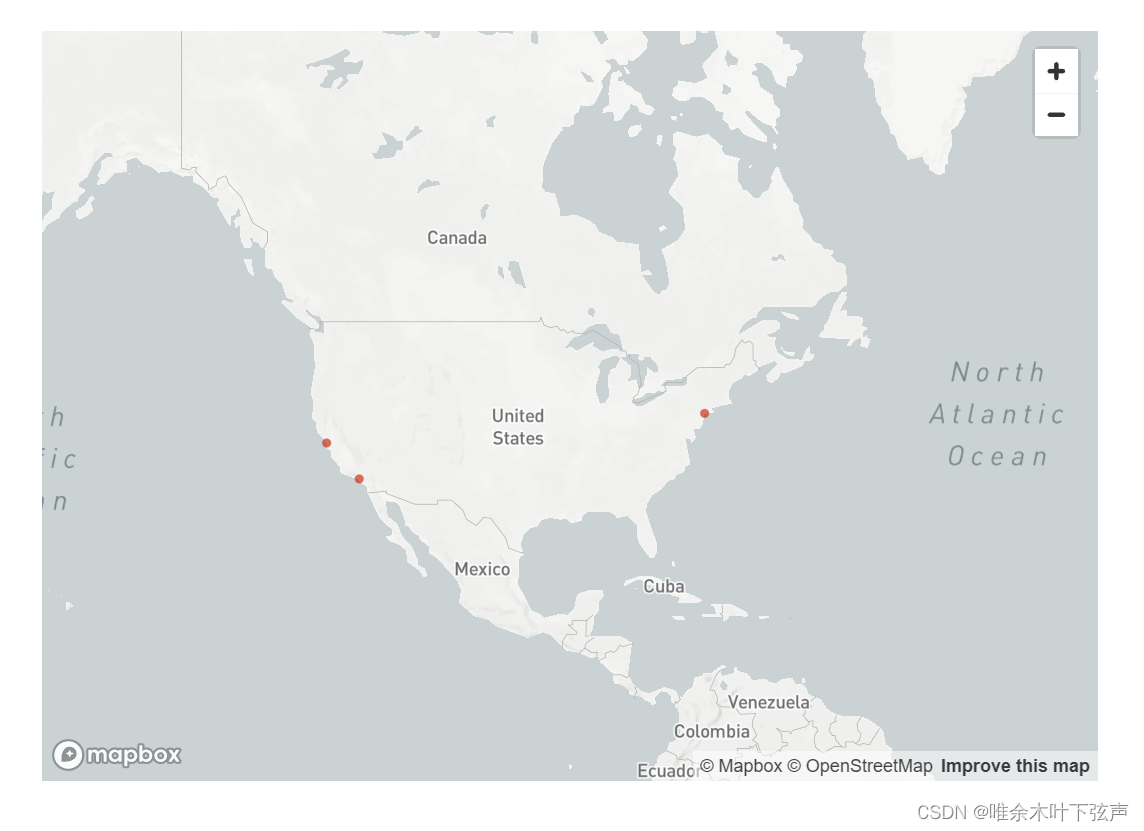
2.9 显示图像
st.image():是Streamlit中用于在应用程序中显示图像的函数。它可以接受多种输入格式,包括文件路径、URL、图像的字节数据等。
参数如下:
默认参数为st.image(image, caption=None, width=None, use_column_width=False, clamp=False, channels='RGB', format='JPEG')
image:要显示的图像,类型可以是numpy.ndarray,[numpy.ndarray],BytesIO,str,或[str])。单色图像为(w,h)或(w,h,1),彩色图像为(w,h,3),RGBA图像为(w,h,4),也可以指定一个图像url,或url列表
caption:图像标题,字符串。如果显示多幅图像,caption应当是字符串列表。
width:图像宽度,None表示使用图像自身宽度。
use_column_width:如果设置为True,则使用列宽作为图像宽度。
clamp:是否将图像的像素值压缩到有效域(0~255),仅对字节数组图像有效。
channels:图像通道类型,'RGB'或'BGR',默认值:RGB。
format:图像格式:'JPEG'或'PNG'),默认值:JPEG。
import streamlit as st
from PIL import Image
image = Image.open('test.jpg')
st.image(image,
caption='标题',
width = 500
)效果如下:

2.10 显示视频
st.video():是Streamlit中用于在应用程序中显示视频的函数。它支持多种视频来源,包括本地文件、URL和字节数据。
参数:
format(str or None):视频格式,可以是"mp4"、"webm"等。如果设置为None,Streamlit将尝试根据文件扩展名自动识别视频格式。
start_time(int):视频开始播放的时间(以秒为单位)。
import streamlit as st
video_file = open('test.mp4', 'rb')
video_bytes = video_file.read()
#本地视频
st.video(video_bytes,format="mp4",start_time=2)
#网络视频
st.video("http://www.w3school.com.cn/i/movie.mp4")
三、streamlit交互
3.1 按钮
st.button():是Streamlit中用于创建按钮的函数。
import streamlit as st
if st.button('点我'):
st.write('今天是个好日子!')
效果如下:

button方法返回一个布尔值,表示在上个应用周期按钮是否被点击。
3.2 复选框
st.checkbox():是Streamlit中用于创建复选框的函数
参数:
value默认为False,若设置为True,则复选框初始状态即为选中状态。
import streamlit as st
cb = st.checkbox('确认',value=False)
if cb:
st.write('确认成功')
else:
st.write('没有确认')效果如下:


可以根据需要更改复选框的标签,并根据复选框的状态执行不同的操作,使用户能够通过选择或取消选择来影响应用程序的行为。
3.3 单选框
st.radio():用于创建单选按钮组,使用户能够从一组选项中选择一个。
参数如下:
label(str):必需。单选框文本,将显示在按钮组上方,介绍单选框用途。
options(list,tuple,dict,orNone):必需。提供可供选择选项的列表、元组或字典。对于列表或元组,选项将按照它们在列表中的顺序显示。对于字典,将显示字典的键,并将字典的值用作用户选择的实际值。
index(int):可选。单选按钮组的初始选择索引,默认为0。即默认选中第一个选项。
format_func(function or None):可选。用于格式化选项的函数,以便在显示时进行自定义格式。
help(str or None):可选。为单选按钮组提供帮助文本,将在用户悬停在组件上时显示。
import streamlit as st
sex = st.radio(
label = '请输入您的性别',
options = ('男', '女', '保密'),
index = 2,
format_func = str,
help = '如果您不想透露,可以选择保密'
)
if sex == '男':
st.write('男士您好!')
elif sex == '女':
st.write('女士您好!')
else:
st.write('您好!')效果如下:
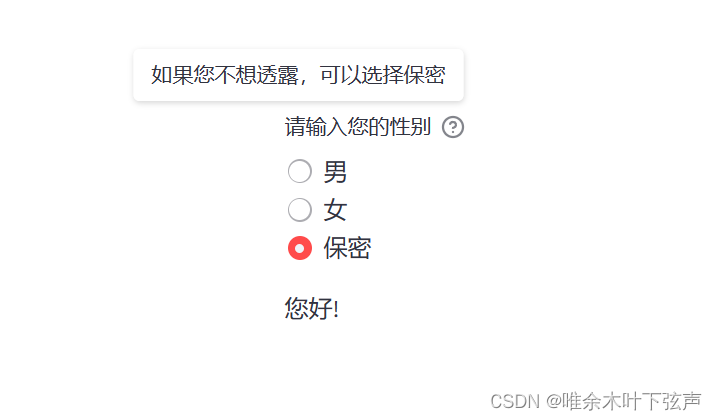


3.4 下拉框
st.selectbox():用于创建一个下拉选择框,使用户能够从一组选项中选择一个。
st.selectbox参数与st.radio一致。
import streamlit as st
sex = st.selectbox(
label = '请输入您的性别',
options = ('男', '女', '保密'),
index = 2,
format_func = str,
help = '如果您不想透露,可以选择保密'
)
if sex == '男':
st.write('男士您好!')
elif sex == '女':
st.write('女士您好!')
else:
st.write('您好!')效果如下:
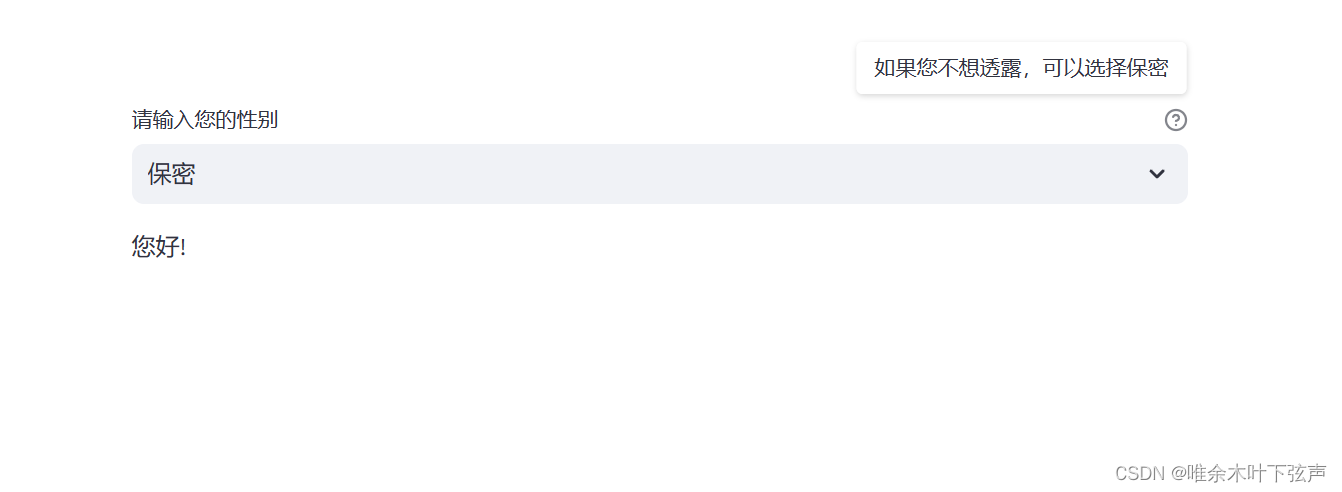

3.5 多选框
st.multiselect():用于创建一个多选框,允许用户从一组选项中选择多个。
参数如下:
label:必需。多选框的标签,将显示在多选框上方,用于标识多选框的用途。
options:必需。提供可供选择的选项的列表、元组或字典。对于列表或元组,选项将按照它们在列表中的顺序显示。对于字典,将显示字典的键,并将字典的值用作用户选择的实际值。
default(list, tuple, dict,or None):可选。多选框的初始选择,默认为None。如果提供了默认值,则多选框将在初始时显示这些选项。
format_func:可选。用于格式化选项的函数,以便在显示时进行自定义格式。
help:可选。为多选框提供帮助文本,将在用户悬停在组件上时显示。
import streamlit as st
options = st.multiselect(
label = '请问您喜欢吃什么水果',
options = ('橘子', '苹果', '香蕉', '草莓', '葡萄'),
default = None,
format_func = str,
help = '选择您喜欢吃的水果'
)
st.write('您喜欢吃的是', options)效果如下:
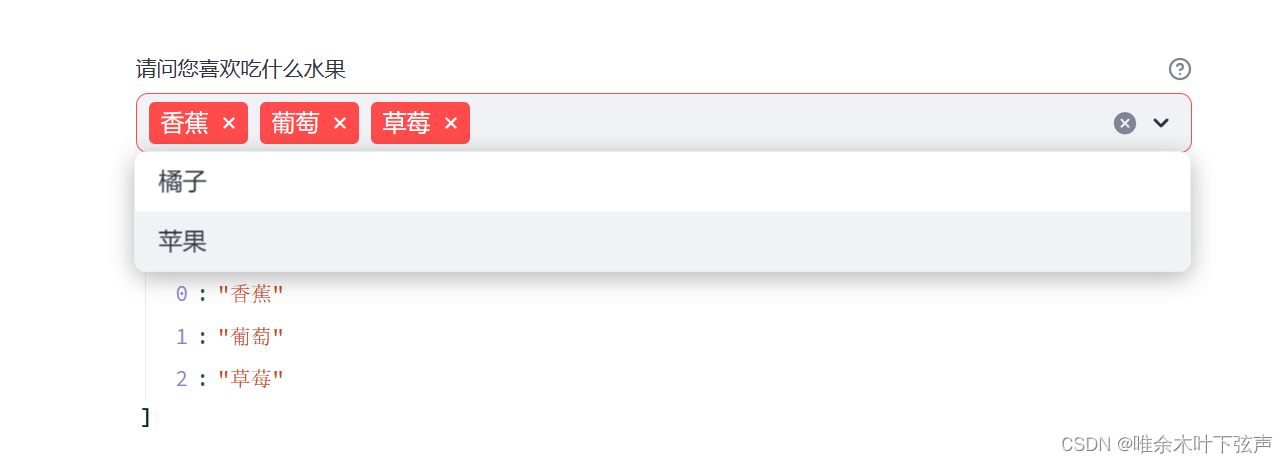
需要注意的是,st.multiselect函数返回的是一个dict,索引为选择的次序,值为对应选择值。每当选择一个选项之后,下拉框中该选项就会消失。
3.6 滑动拉杆
st.slider():用于创建一个滑块,允许用户在一个范围内选择一个数值。
参数如下:
label(str):必需。滑块的标签,将显示在滑块上方,用于标识滑块的用途。
min_value(int, float, datetime, or None):可选。滑块的最小值。可以是整数、浮点数或datetime对象。如果未提供,则默认为0。
max_value(int, float, datetime, or None):可选。滑块的最大值。可以是整数、浮点数或datetime对象。如果未提供,则默认为100。
value(int, float, datetime, or tuple):可选。滑块的初始值。可以是单个数值或表示范围的元组。如果提供了元组,用户将能够选择一个范围而不是单个值。
step(int, float, or None):可选。滑块上的步进值,用户可以通过拖动滑块选择。如果未提供,则默认为1。
format:可选。滑块的显示格式。可以是包含"{:.2f}"之类的格式字符串,用于控制显示的小数位数。
key:可选。为滑块分配的唯一键,用于识别和跟踪滑块的状态变化。通常用于确保组件的稳定性。
help:可选。为滑块提供帮助文本,将在用户悬停在组件上时显示。
import streamlit as st
age = st.slider(label='请输入您的年龄',
min_value=0,
max_value=100,
value=0,
step=1,
help="请输入您的年龄"
)
st.write('您的年龄是', age)效果如下:

3.7 单行文本输入框
streamlit.text_input函数用于创建文本输入框,允许用户输入文本信息。
参数如下:
label:必需。文本输入框的标签,将显示在输入框上方,用于标识输入框的用途。
value(str):可选。文本输入框的初始值,默认为空字符串。
max_chars(int or None):可选。文本输入框允许的最大字符数。如果未提供,则不设置字符数限制。
type(str):可选。输入框的类型,默认为'default'。其他选项包括'password'(密码输入框)和'number'(数字输入框)。
help:可选。为文本输入框提供帮助文本,将在用户悬停在组件上时显示。
import streamlit as st
name = st.text_input('请输入用户名', max_chars=100, help='最大长度为100字符')
# 根据用户输入进行操作
st.write('您的用户名是', name)效果如下:
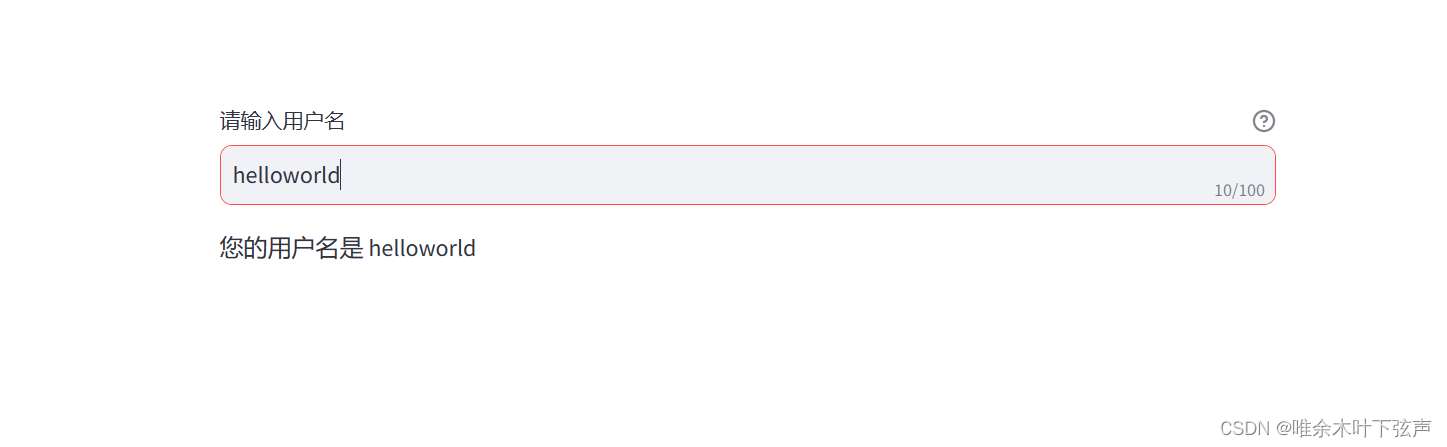
3.8 数字输入框
st.number_input():用于创建数字输入框,允许用户输入数字。
参数如下:
label、format、help与前文一致
min_value(int, float, or None):可选。数字输入框的最小值。如果未提供,则不设置最小值限制。
max_value(int, float, or None):可选。数字输入框的最大值。如果未提供,则不设置最大值限制。
value(int, float, or None):可选。数字输入框的初始值。如果未提供,则默认为None。
step(int, float, or None):可选。数字输入框上的步进值,用户可以通过点击按钮调整。如果未提供,则默认为1。
import streamlit as st
age = st.number_input(label = '请输入您的年龄',
min_value=0,
max_value=100,
value=0,
step=1,
help='请输入您的年龄'
)
st.write('您的年龄是', age)效果如下:

3.9 多行文本输入框
st.text_area():用于创建文本区域,允许用户输入多行文本信息。
参数如下:
label、help与前文一致。
value(str):可选。文本区域的初始值,默认为空字符串。
height(int or None):可选。文本区域的高度,表示显示的文本行数。如果未提供,则根据内容自动确定高度。
max_chars(int or None):可选。文本区域允许的最大字符数。如果未提供,则不设置字符数限制。
import streamlit as st
text = st.text_area(label = '请输入文本',
value='请输入...',
height=5,
max_chars=200,
help='最大长度限制为200')
st.write('您的输入是', text)效果如下:

3.10 日期输入框
st.date_input():用于创建日期输入框,允许用户选择日期。
参数如下:
label、help与前文一致
value(datetime.dateorNone):可选。日期输入框的初始值,应为datetime.date类型。如果未提供,则默认为None。
min_value(datetime.date or None):可选。日期输入框的最小值,用户不能选择早于该日期的日期。如果未提供,则不设置最小值限制。
max_value(datetime.date or None):可选。日期输入框的最大值,用户不能选择晚于该日期的日期。如果未提供,则不设置最大值限制。
import streamlit as st
import datetime
birthday = st.date_input(label = '请输入您的出生年月',
value=None,
min_value=None,
max_value=datetime.date.today(),
help='请输入您的出生年月')
st.write('您的生日是:', birthday)效果如下:
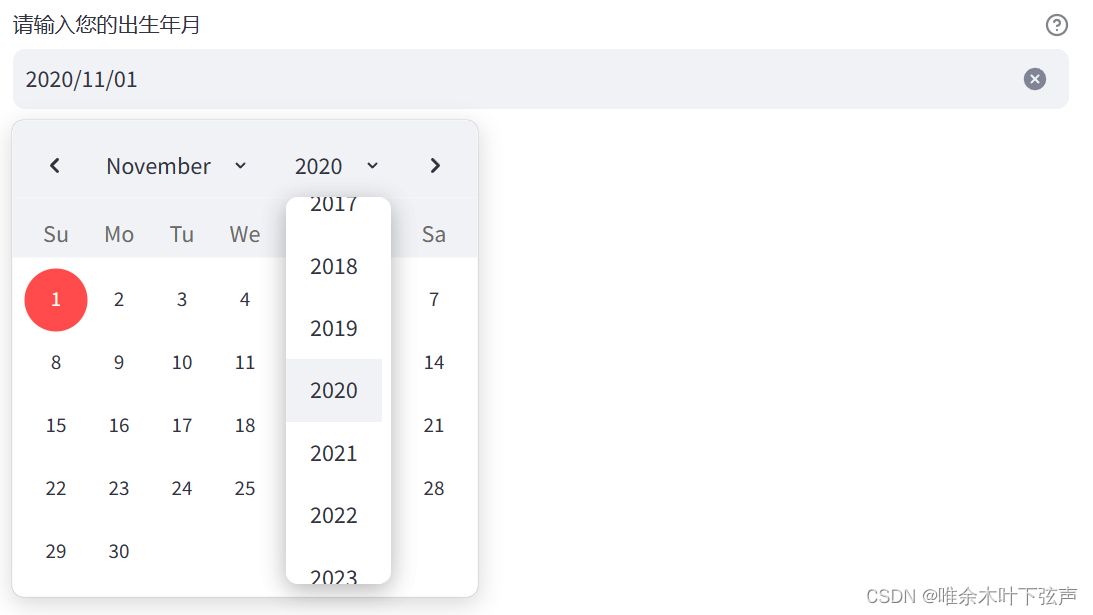
3.11 时间输入框
st.time_input():用于创建时间输入框,允许用户选择时间。
参数如下:
label、help与前文一致。
value(datetime.time or None):可选。时间输入框的初始值,应为datetime.time类型。如果未提供,则默认为None。
step(int or timedelta):可选。时间输入框的时间间隔。
import streamlit as st
from datetime import time
t = st.time_input(label = '请输入一个时间',
value=None,
help='请输入一个时间')
st.write('您输入的时间是:', t)效果如下:

四、其他函数
4.1 提示信息
streamlit提供了多种函数用于显示不同类型的消息,以呈现不同级别的通知和反馈。
st.error: 用于显示错误消息。通常用于向用户报告发生的错误或异常。
st.warning: 用于显示警告消息。通常用于向用户提供潜在的问题或需要注意的情况。
st.info: 用于显示一般信息消息。可以用于提供一般性的信息或指导。
st.success: 用于显示成功消息。通常用于向用户报告任务或操作成功完成。
st.exception: 用于显示异常消息。当发生异常时,可以使用此函数将异常信息呈现给用户。
这些函数提供了一种直观的方式来向用户传达不同类型的信息,并帮助改善用户体验。使用适当的消息类型能够更清晰地传达信息的重要性和紧急性。
import streamlit as st
st.error('错误信息')
st.warning('警告信息')
st.info('提示信息')
st.success('成功信息')
st.exception('异常信息')效果如下:

4.2 显示执行状态
st.progress:用于显示一个进度条,可以设置最小值、最大值和当前值。它通常用于表示长时间运行的非阻塞任务的进度。
st.spinner:用于显示一个旋转的加载器,表示任务正在执行。它通常用于表示短时间运行的任务的执行状态。当任务完成时,加载器将自动消失。
import streamlit as st
import time
progress_bar = st.empty()
for i in range(10):
progress_bar.progress(i / 10, '进度')
time.sleep(0.5)
with st.spinner('加载中...'):
time.sleep(2)
效果如下:

4.3 缓存修饰器
@st.cache_data装饰器用于记忆函数的历史执行。当使用@st.cache装饰一个函数时,Streamlit 会将该函数的结果存储在一个缓存中,以便在后续调用中直接返回缓存的结果,而不是重新计算。这可以提高应用程序的性能,特别是在处理大量数据或计算密集型任务时。
参数如下:
func:要缓存的函数。如果提供了函数,则会对该函数的计算结果进行缓存。如果为None,则返回一个可以接受函数作为参数的装饰器。
ttl(int or None):必需。缓存的生存时间,以秒为单位。在缓存的生存时间内,对函数的调用将返回缓存的结果而不是重新计算。如果设置为None,缓存将永不过期。
max_entries(int or None):可选。缓存的最大条目数。当达到指定的最大条目数时,新的计算结果将替换最早的计算结果。
show_spinner(bool):可选。当进行缓存计算时,是否显示加载指示器。默认为True。
persist(bool):可选。是否将缓存数据持久化到磁盘。如果为True,数据将在应用程序重新启动时仍然存在。默认为False。
experimental_allow_widgets(bool):可选。是否允许在被缓存的函数中使用Streamlit小部件。默认为False。启用此选项时,可以在被缓存的函数中使用小部件。
hash_funcs(dictorNone):可选。用于指定自定义哈希函数的字典。键是参数名称,值是哈希函数。如果为None,将使用默认哈希函数。
?
import streamlit as st
import time
import pandas as pd
@st.cache_data
def fetch_data(url):
time.sleep(5)
return pd.read_csv(url)
url1 = 'https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data'
d1 = fetch_data(url1)
st.write(d1)
url2 = 'https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data'
d2 = fetch_data(url2)
st.write(d2)
st.cache_data.clear()
url3 = 'https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data'
d3 = fetch_data(url3)
st.write(d3)在以上示例中,数据表d1需要从url读取数据,而在加载之后被缓存下来,当数据表d2获取数据时,输入的是相同的url参数,则不会再次执行该函数,而是直接从缓存中读取数据。使用st.cache_data.clear()清空缓存后,d3则需要重新从url读取。
五、总结
总的来说,Streamlit的主要设计目标是让数据科学家和分析师能够轻松快速地构建数据科学和机器学习应用。它专注于简单性和快速迭代,使用户能够使用几行代码即可创建交互性应用。即使不懂前端知识HTML、CSS等,也能通过Streamlit框架提供的函数构建一个漂亮的web页面。
Streamlit的优势在于:极简的语法,即时预览,交互性强,支持数据可视化,适用于快速原型设计和展示数据分析结果。但同时它的劣势也非常明显,相对于全栈框架,Streamlit能做到的事情不多,其适用范围更为有限,主要关注于构建数据应用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue 前端加密解密 CryptoJS
- C++中的性能分析与调优实践,不少于1000字
- 在Maven中设置JVM系统参数及Java应用调试实例
- 探索TVM:深度学习模型编译与部署的前沿与实践【文末送书-14】
- linux设置定时任务
- Fruit Market
- 2022、23年各需求提测后的总结,及典型bug缺陷
- Python模块、包与面向对象综合案例
- Java版企业电子招标采购系统源码Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
- 矩阵理论及其应用邱启荣习题3.5题解