MATLAB刷题:文本数据处理入门篇(第五章的课后习题)
题目分为三个部分:
-
基础篇:帮助大家再次复习基础的内容,题目的答案大部分都能直接在本章的知识点中找到。
-
提高篇:在本章课上练习题的基础上进行了一点变形,考验大家对于知识点的熟练程度。这部分的习题不算难,相信大多数的同学都能应对得了。
-
挑战篇:这部分的习题有一定的难度,主要训练大家编程的思维。这部分的习题如果你能独立地做出来,那就说明你非常有编程天赋,大家可以尝试挑战一下。
-
参考答案在本文的最后,有题目的讲解视频。
基础篇
Q1:填空题
- 本章介绍了两种对字符数据进行编码的方式,分别是_________编码和_________编码。
- 创建空的元胞数组可以使用_________函数。
- 引用元胞数组中的数据可以使用_________进行索引。
- 在处理元胞数组时,我们经常需要对数组中保存的每个数据应用相同的函数进行计算,MATLAB提供的_________函数可以帮我们快速实现这个目的。当我们在该函数中使用的函数句柄返回的不是标量值时,应该设置________________________参数。?????
- 要创建一个空的字符串数组,可以使用_________函数。
- 使用_________函数能够比较两个字符向量是否完全相同;如果不区分大小写则可以使用_________函数。
- 要获取字符串中字符的数量,可以使用_________函数。
- 连接两个字符串标量可以使用_________运算符。
- 要将字符串数组中的元素按特定分隔符进行连接,可以使用_________函数。
- 使用_________函数可以删除字符串数组中的子文本。
- 使用_________函数能够将数组转换为元胞数组,转换后的元胞数组中的数据大小相同。
- 将文本中的大写字母转换为小写字母的函数是_________;将文本中的小写字母转换为大写字母的函数是_________。
- 为字符串添加前导或尾随字符,以达到特定长度的函数是_________;使用_______函数可以调整字符数组中文本的对齐方式。
- 函数_________只会删除文本末尾的空白字符,不会删除开头的空白字符。
- 创建一个换行符的命令是_________。
- 判断字符串中是否包含特定模式的函数是_________。
- 判断两个元胞数组是否等效可以使用_________函数。
- 反转字符串中的字符顺序的函数是_________。
- 已知变量s="123",那么命令s{1}返回的结果是_________。
- 已知cc = {[1 2 3;4 5 6],'abc'},那么cc{2}(3) 返回的结果是_________;这种索引方式称为_________;使用这种索引方式进行索引时,需要注意__________________,如果不遵守的话会报错。
- 检查字符串是否以指定的文本开始可以使用函数_________。
- 有时候一行代码很长,为了便于阅读和理解,我们可以使用_____将这行代码分割到多行。
- 转义字符用于在文本中表示特定的字符,例如_______表示换行符。
- 使用_______函数可以显示工作区各变量的详细信息,包括变量的名称、大小、占用的内存大小和数据的属性。
- 统计字符串中特定模式出现的次数的函数是_______。
- 根据指定分隔符拆分字符串数组的函数是_______。
- 使用_______函数可以将包含数值的文本数据类型转换回数值数组,它支持字符数组、字符向量元胞数组和字符串数组三种类型。
- 在指定的起点和终点之间替换子字符串可以使用_______函数;如果是提取起点和终点之间的子字符串可以使用_______函数。
- 将旧文本替换成新的文本有两个不同的函数,分别是_______和_______。
- ?将输入变量分发给输出变量的函数是_______。
Q2:代码练习题
下面给出了一个任务表,表中每个编号对应一个特定的数据处理任务。你需要根据所给的输入数据,编写相应的代码来生成对应的输出数据。例如:任务1的答案为:cc = upper(c)
| 编号 | 任务说明 | 输入的数据 | 输出的数据 |
| 1 | 将c中的小写字母变成大写 | c = 'abcDEF123' | cc =? 'ABCDEF123' |
| 2 | 将c转换成数值向量d | c = '1.5 4.3 6.5' | d = [1.5? 4.3? 6.5] |
| 3 | 删除s中由<>构成的html标签 | s = "<a><div>abcd</div></a>" | ss = "abcd" |
| 4 | 将cc转换成字符串数组 | cc = {'ab','cde'} | ss = [ "ab", "cde"] |
| 5 | 判断c中是否存在小写英文字母 | c = 'AB123456CD' | flag = logical 0 |
| c = 'AB123456cd' | flag = logical 1 | ||
| 6 | 删除s中的所有数字 | s = "a325ds0d4s5a4s7" | ss = "adsdsas" |
| 7 | 删除s中的空字符串 | s = ["", "ab", "c", "", "d"] | s = ["ab", "c", "d"] |
| 8 | 将x分割为四个子块,并将结果保存到元胞数组c中 | x = [1 2; 3 4; 5 6] | c = ??2×2 cell 数组 {[1]}?? {[2] } {[3;5]} {[4;6]} |
| 9 | 统计s中大写字母出现的次数 | s = "aAdE55G6F" | num = 4 |
| s = "abcdefg" | num = 0 | ||
| 10 | 在空格处拆分字符串 | s = "ab? de f??? g" | ss = ["ab", "de", "f", "g"] |
| 11 | 删除s中各元素开头的空白字符 | s = [" abc? ", "def ", "? g"] | ss = ["abc? ", "def ", "g"] |
| 12 | 计算s中各元素的频数表 | s = ["22", "21", "21", "22", "11"] | c = 3×3 cell 数组 ??? {'22'}??? {[2]}??? {[40]} ??? {'21'}??? {[2]}??? {[40]} ??? {'11'}??? {[1]}??? {[20]} |
| 13 | 确定c中的哪些字符属于数字 | c = 'ad25me0' | ind = 1×7 logical 数组 ?? 0?? 0?? 1?? 1?? 0?? 0?? 1 |
| 14 | 判断s中的元素是否以数字开头 | s = ["1abc", "5ac", "cc12"; ??????? "css", "9df88", "43"] | ind = 2×3 logical 数组 ?? 1?? 1?? 0 ?? 0?? 1?? 1 |
| 15 | 删除元胞数组C的第二行元素 | C = {'apple', 'banana'; ???????? 'pear', 'cherry'} | C = {'apple', 'banana'} |
| 16 | 将C的第一列数据换成'xyz' | C = {'apple', 'banana'; ???????? 'pear', 'cherry'} | C = {'xyz', 'banana'; ???????? 'xyz', 'cherry'} |
| 17 | 计算C中每个向量的最大值 | C = {[1 5], [6 7 1], [4 0 9 2]} | mc = [5 7 9] |
| 18 | 对C中的每个向量分别升序排列 | C = {[6 7 1], [4 0 9 2]} | sc = {[1 6 7], [0 2 4 9]} |
| 19 | 将C中的数据拼接成一个向量 | C = {[1 5], [6 7 1], [4 0 9 2]} | d = [1? 5? 6? 7? 1? 4? 0? 9? 2] |
| 20 | 删除C中元素和小于10的向量 | C = {[1 5], [6 8], [2 3], [4 6]}; | C = { [6 8], [4 6]}; |
导入题目中的数据
由于本章没有介绍如何导入和导出文本数据(下一章中会讲解),因此我提前准备了一些数据,大家做课后习题之前请先使用下面的代码导入对应的数据:
load? homework5.mat(导入数据前,确保MATLAB的当前文件夹下存在homework5.mat这个文件。
不会导入的同学可以参考本章5.3.3节或者看配套的讲解视频
?homework5.mat这个文件可以看配套的讲解视频下载,在第五章的配套代码中)
导入成功后你将在MATLAB的工作区看到一些变量:
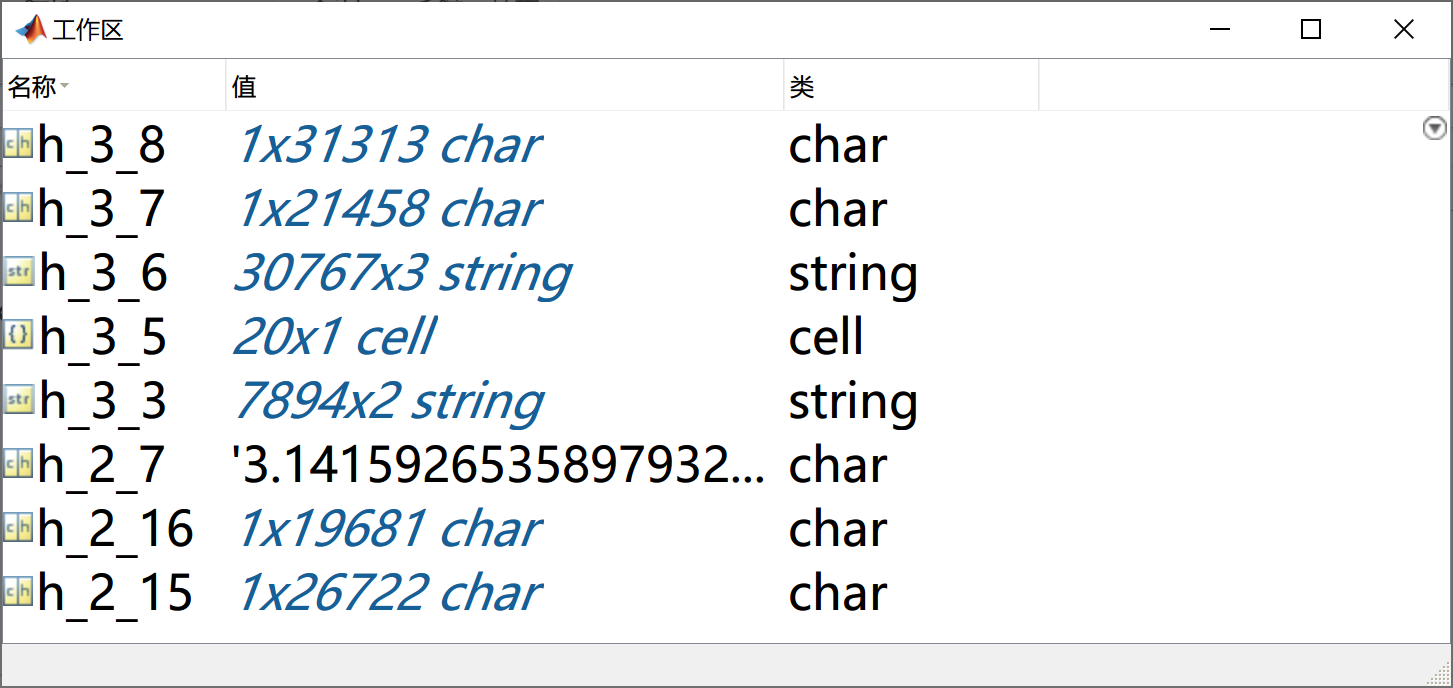
变量的命名规则如下所示:h_i_j。其中:h是homework的缩写、i表示题目类别(i=1,2,3分别对应基础篇、提高篇和挑战篇)、j表示题号,例如h_2_7表示提高篇第七题的数据。
提高篇
Q1:DNA序列分析
A, T, C, G(腺嘌呤、胸腺嘧啶、鸟嘌呤和胞嘧啶)是生物DNA中的四种碱基,它们是构成DNA的四种基本单位,通过不同的排列组合编码着生物的遗传信息。请完成以下问题:
(1)随机生成长度为9000的一段DNA序列,例如'TCGGTTCAG…',保存为变量dna(注意,随机生成DNA序列在生物学中并不科学,本题仅供练习MATLAB的语法)。
(2)计算每种碱基(A、T、C、G)在dna中出现的次数,将结果保存为长度为4的向量P中。
(3)假设序列中的 'T' 碱基可以被 'U' 替代(U为尿嘧啶),返回转换后的结果rna。
(4)DNA序列中每3个连续的碱基表示一个密码子,因此变量dna中应存在3000个密码子,请将这3000个密码子保存到字符串向量S中,并统计有多少种不同的密码子。
(5)假设S中有k种不同的密码子,计算一个大小为k×3的元胞数组C_DNA,C_DNA的第一列表示这k种不同的密码子,第2列表示它们出现的次数,第三列表示它们出现的频率(你能不使用tabulate函数得到C_DNA吗?)。
Q2:优化5.3.3节案例2(计算共有的兴趣爱好数量)的代码
课堂上给出的的代码中,每次比较两名同学的兴趣爱好时,都会重复执行strsplit函数来获取兴趣列表。你能否优化代码来提高程序的运行效率?比较代码优化前后的运行时间。
Q3:统计文本中各字符出现的频次
s是一个字符串标量,请统计s中各字符出现的频次,并生成一段描述结果的文本T。T是一个带有换行符的字符串标量,具体格式请见下表(按照字符出现的频次从高到低排序):

Q4:将十进制正整数转换为十六进制数
本章5.2.2节中,我们有一道将十进制正整数转换为二进制数的例题。请仿照这个例题,写一段代码将十进制正整数转换为对应的十六进制数。提示:十六进制数由0 1 2 3 4 5 6 7 8 9 A B C D E F组成。它与十进制的对应关系是:0-9对应0-9、A-F对应10-15。
例如:十进制数666对应的十六进制数为'29A' 、十进制数7788对应的十六进制数为'1E6C' .
Q5:找出所有能被deblank函数去除的空白字符
deblank函数能够去除文本末尾的空白字符,请你写一段程序,找出它能识别的所有空白字符对应的Unicode编码,并将结果保存到一个向量中。(在Unicode字符集中,十进制0 到 2^16-1(十六进制0000-FFFF)涵盖了绝大多数常用字符,包括各种语言的文字、符号以及特殊字符,因此识别的字符范围可以限定在这个区间内)
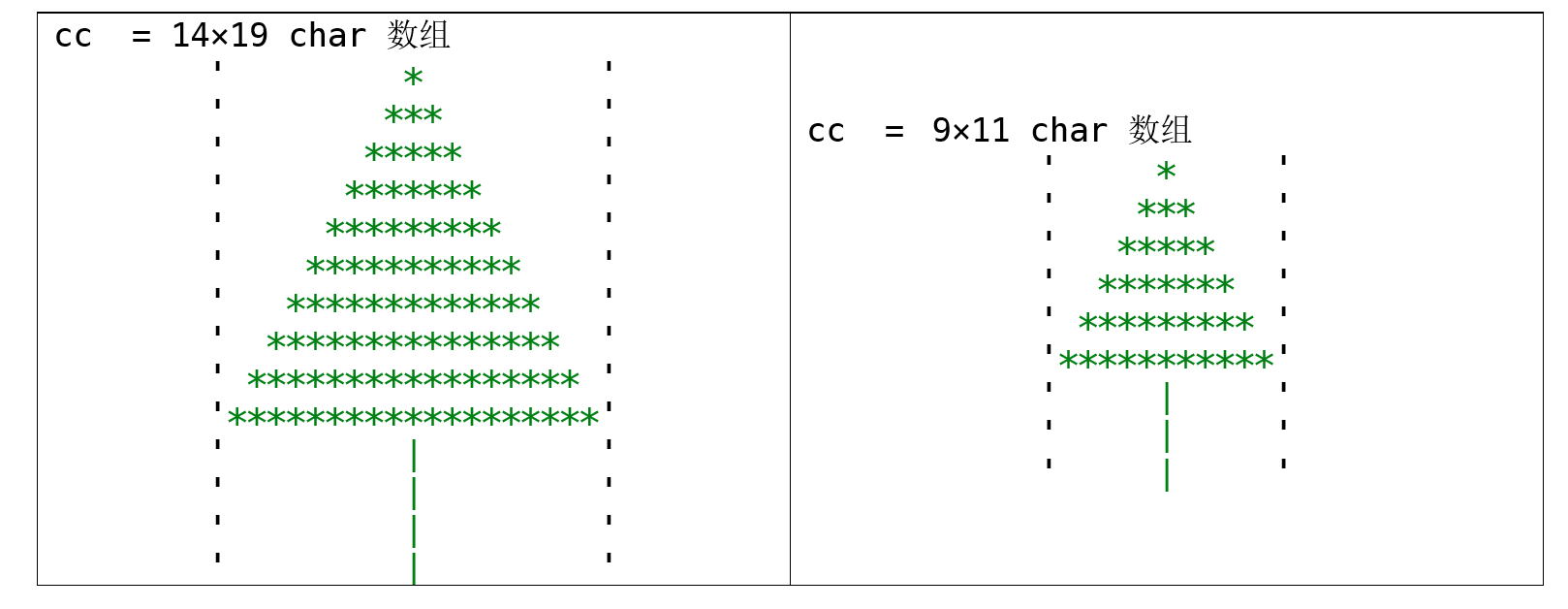
Q6:使用字符构建一颗圣诞树
如下表所示,表格左侧有一个14行19列的字符数组cc,它仅由字符'*'和'|'构成,为了美观我使用了绿色表示里面的字符元素,这样看起来有点像一颗圣诞树。其中,'*'构成了树叶(有10行),'|'构成了下面的树干(有4行)。
类似的,表格右侧有一个更小的圣诞树,它的树叶有6行,树干有3行。
现在给定树叶的行数n和树干的行数m(n和m均为正整数),请你构造一个表示圣诞树的字符数组cc,并使用disp(cc)输出结果。(你也可以使用字符串数组类型表示这颗圣诞树)
Q7:有趣的圆周率π(本题数据为h_2_7)
请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_2_7,它是一个字符向量,保存着小数点后10000位的圆周率π('3.141592653589793238…')。
- 验证π的小数点后144位数字相加的和(1+4+1+5+9+2+…)等于666。
- 统计π的小数点后10000位中各个数字出现的频数和频率。
- 假设你的生日为4月6日,将其转换为字符向量为'0406',验证能否在π的小数点后10000位中找到这个子文本。将'0406'换成你自己的真实生日,能找到吗?
- 构造所有可能的生日(366种可能),将其保存在一个字符串数组中。判断哪些生日能在π的小数点后10000位中找到,若能找到返回其第一次出现的小数点位数。
Q8:判断字符向量能否作为MATLAB中的变量名
在第二章中,我们介绍过MATLAB中变量的命名规则:
- 变量名必须以字母开头,之后可以是任意的字母、数字或下划线_。
- 变量名不超过63个字符
- 不能定义与MATLAB关键字同名的变量(例如 if 或 end)。要获取关键字的完整列表,可以使用iskeyword函数。
给你一个字符向量c,判断它能否作为MATLAB中的变量名。
Q9:探索无限非循环小数中特定数字序列的位置
已知小数0.1234567891011121314...是一个由连续自然数拼接组成的无限不循环小数,问小数点后面出现的第一个2019中的2是小数点后面的第几位?(本题选自知乎,答案是6572)
Q10:循环移位字符向量生成字符串数组
给定一个字符向量c,请编写代码生成一个字符串数组 s,其中 s 的每个元素都是 c 的循环移位。下面举两个例子帮助大家理解:

Q11:字符组合的全排列生成
给定n个两两互不相同的字符,返回所有可能的排列,将结果保存到一个字符串向量s中,并进行排序。例如'a'、'b'、'c'这三个字符的全排列有六种情况,对应的s为:

(提示:你可能需要用到第三章课后习题挑战篇Q19中介绍的一个函数)
Q12:模拟生成高考数学单选题的随机答案
在高考数学考试中,有八道单选题,每题的标准答案分别为DCCAABBC。一名考生对考试内容一无所知,因此不得不随机猜测每道题的答案。这名考生有一种倾向:他更可能选择C选项。具体来说,他有 40% 的几率选择C,而选择ABD 的几率各为 20%。
(1)请根据这个概率分布帮助这名考生随机生成一组八道题的答案,并计算出他正确答对的题目数量。
(2)进行十万次模拟,计算出在这种答题策略下,他平均能正确答对多少道题。
Q13:数字之和与整除条件的数字分析任务
编写程序依次完成以下三个任务:
(1)计算数字之和满足特定条件的整数:
对于1至10000范围内的每个整数,计算它们每一位数字之和(例如135这个整数的数字之和为8 = 1+3+5)。
创建一个10×1的元胞数组 x。对于每个 k(1到10之间的整数),x{k} 应包含那些其数字之和能被 k 整除的整数列表。例如:
x{10} 包含的整数是每位数字之和能被10整除的,比如19(1+9=10)或9993(9+9+9+3=30)。
(2)统计元胞内各数据的元素数量:
统计 x{k} 中包含的元素数量,并将这些计数结果保存在一个长度为10的向量 y 中。
例如,y 的第一个元素应为10000,因为1到10000中的每个数的数字之和都能被1整除。
(3)统计数字出现次数和频率:
统计1至10000中每个数在 x 中出现的次数和频率,并按次数降序排列结果。
Q14:数独辅助解题器:提示每个位置可填入的数字
本章5.3.1.8节介绍mat2cell函数时,我们讲过一个数独的例题。本题需要大家编写一段程序来辅助解决数独谜题。
数独是一个9x9的网格,其中部分单元格已填入数字,剩余的单元格需要根据数独的规则来填写。数独的规则要求每行、每列以及每个3x3的小网格(宫)中的数字1到9各出现一次。
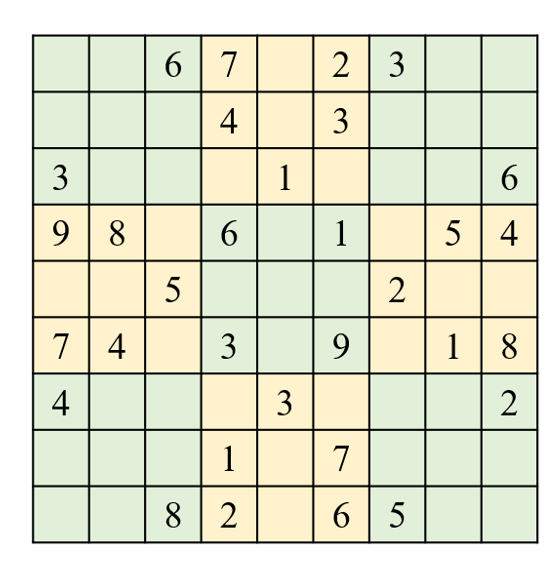
% 用0表示要填充的空单元格
sd = [0 0 6 7 0 2 3 0 0;
0 0 0 4 0 3 0 0 0;
3 0 0 0 1 0 0 0 6;
9 8 0 6 0 1 0 5 4;
0 0 5 0 0 0 2 0 0;
7 4 0 3 0 9 0 1 8;
4 0 0 0 3 0 0 0 2;
0 0 0 1 0 7 0 0 0;
0 0 8 2 0 6 5 0 0];
给定上面这个部分填写的数独盘面,将每个空单元格可以填入的数字列表保存在一个9x9的元胞数组 C 中。如果某个单元格已有确定数字,则该单元格在 C 中对应的位置保持原始数字。例如C中第一行第一列的数据为[1,5,8],代表该位置只可能填写1、5和8。
完整的答案如下所示,供大家参考:
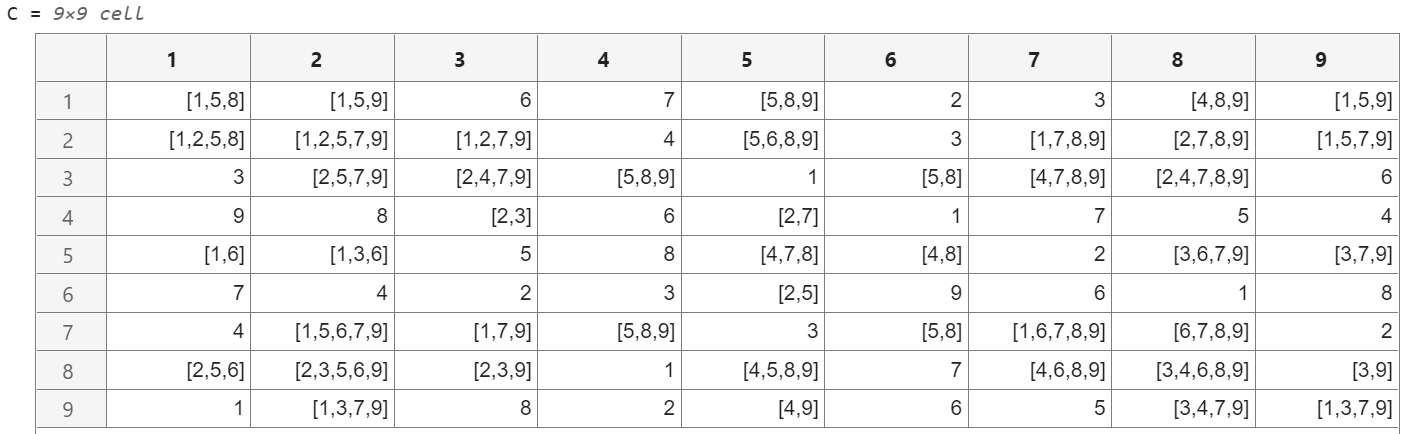
接下来,请将变量C保存在名为“我的第一个数据C.mat”的MATLAB数据文件中,然后重启MATLAB软件并重新导入这个数据。
Q15:提取古诗名称和诗人(本题数据为h_2_15)
请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_2_15,它是一个字符向量,来自某个古诗词网站,h_2_15的开头如下所示:

(1)请从h_2_15中提取出所有的古诗名称和对应的诗人,并将结果保存在一个两列的字符串数组S中。S中应有320行,结果供大家参考:

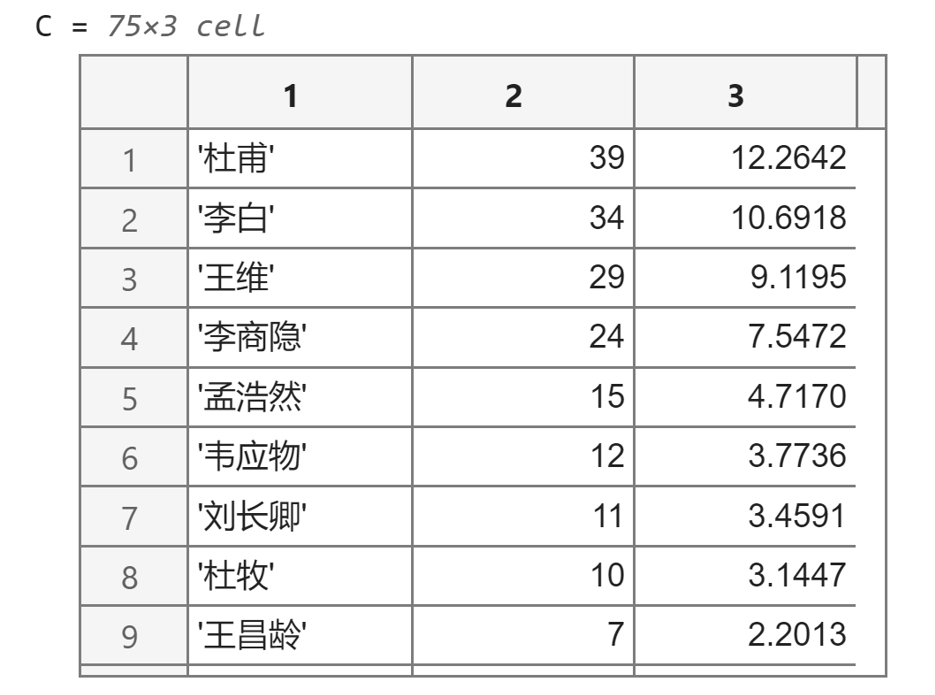
(2)请统计S中有多少个不同的诗人,计算这些诗人古诗的数量和频率,你可以将结果保存到元胞数组C中,并按照古诗的数量降序排列。C中应有75行,结果供大家参考:
Q16:提取王者荣耀游戏中英雄的名称(本题数据为h_2_16)
请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_2_16,它是一个字符向量,来自王者荣耀官网,h_2_16的开头如下所示:

(1)请从h_2_16中提取出所有英雄的名称(参考上图箭头指示的位置),并将结果保存到字符串向量S中。S中应有117行,结果供大家参考:

(2)统计每个英雄名称的长度,并将相同长度的英雄名称归为一组,每组之间用中文的顿号(、)分隔。你可以将结果保存到一个两列的元胞数组 C 中,第一列是英雄名称的长度,第二列是对应长度的英雄名称列表。C中应有4行,结果供大家参考:

挑战篇
Q1:密码安全性评估与得分系统设计
为了保障账户的安全,我们需要设计一个密码验证系统来确保用户设置的密码符合特定的规则。一个合格的密码必须满足以下两点规则:
规则一:密码长度不低于8位,最多16位;
规则二:密码中只能包含英文字母(大小写的英文字母都可以)、数字或者以下标点符号:,.!;?#%&:<>+-*/ ,不能包含其他字符。
请解决以下两个问题:
- 任意给定一个字符串标量,代表用户设置的密码,请判断该密码是否符合上述两点规则,你的输出结果应为逻辑值1或逻辑值0。
- 假设用户设置的密码符合上述两点规则,现在要对该密码的强度进行评分,评分标准和细则如下表所示:
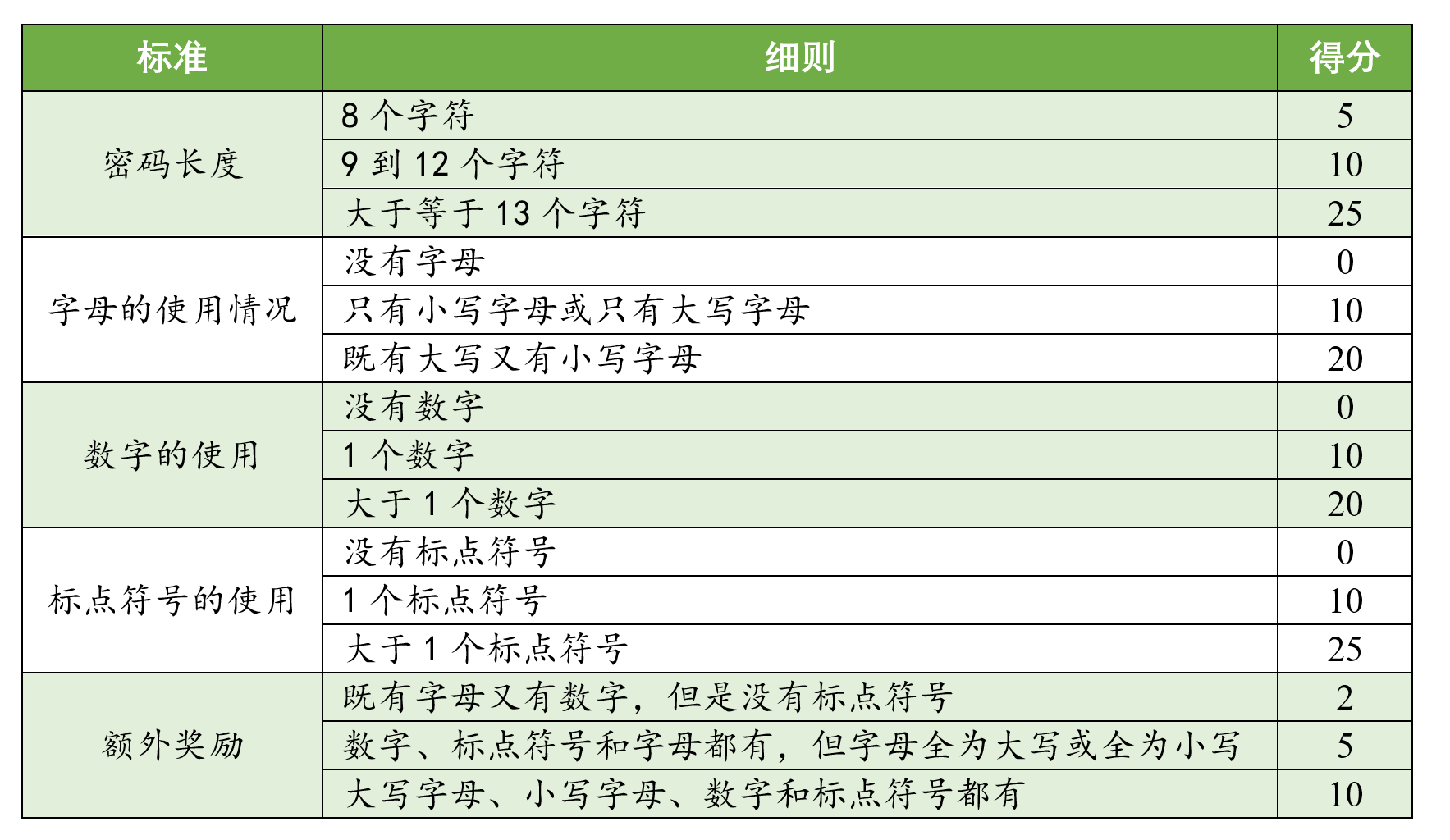
请根据上表计算用户设置的密码的得分。
例如密码"abcd123456"的得分为10+10+20+0+2 = 42;密码"Abc528963.." 的得分为10+20+20+25+10 = 85。
Q2:创建并显示杨辉三角
杨辉三角是组合数学中的经典结构,它与二项式系数紧密相关。其独特的形状和规律性的数字排列使其在数学、物理、计算机科学和其他领域中都有广泛的应用。
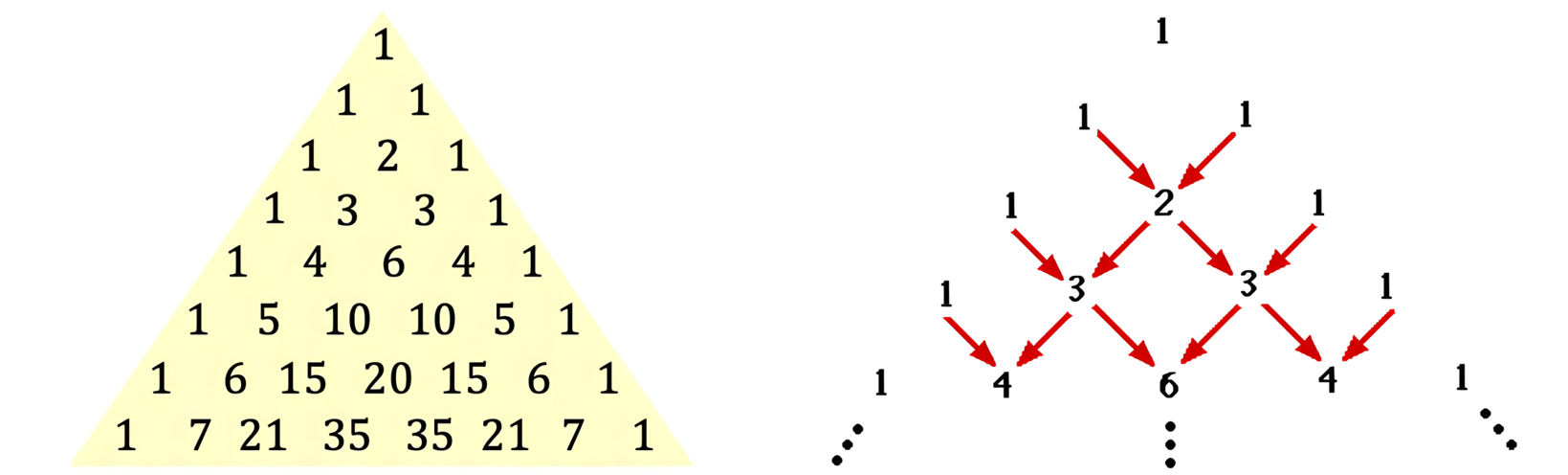
本题的任务就是生成一个类似的杨辉三角,你可以按照以下步骤生成:
(1)生成一个n行杨辉三角矩阵
定义一个变量 n,表示杨辉三角的行数,例如n等于9表示有九行。初始化一个 n×n 大小的矩阵 yh,用于存储杨辉三角的值,你可以初始值里面的元素全为0。
接下来,你需要根据杨辉三角的规则填充杨辉三角矩阵yh。规则如下:
- 第 i 行有 i 个杨辉三角数字(不含0),其中 i = 1, 2, ... , n。
- 每一行的开始和结尾的杨辉三角都是1(不含0)。
- 从第三行开始,每个杨辉三角数字是其正上方和左上方两个元素之和。
例如:当n等于9时,对应的yh矩阵为:

(2)格式化显示杨辉三角
将 yh 矩阵中的杨辉三角数字(不含0)转换为字符形式。将每行的数字以三个空格隔开,形成一个字符数组 cc。确保 cc 中的每一行数字都居中对齐,以模拟杨辉三角的视觉效果。
例如下面是一个9行38列的字符数组cc,它表示一个9行的杨辉三角:

Q3:汉字拼音转换器(本题数据为h_3_3)
在中文文本处理中,将汉字转换为对应的拼音是一项常见的任务,尤其是在处理语音合成、文本到语音转换等应用中。请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_3_3,它是一个7894行2列的字符串数组,例如它的前12行如下所示:

数组中每一行代表一个汉字及其拼音。对于多音字,不同的拼音通过 | 分隔。
现在给你一个字符串标量ss,请将里面的汉字转换成对应的拼音p,无法在h_3_3中找到的汉字和其余非汉字字符请保持原样。(注意:实际的语境中,我们需要根据不同的上下文选择正确的多音字拼音。本题不需要大家考虑这样复杂的情况,如果遇到多音字则只使用它的第一个拼音)
下面举几个例子帮大家理解:

Q4:返回给定汉字的所有同音字(本题数据和Q3一样)
在中文文本处理中,识别和处理同音字是一项有趣且重要的任务。同音字指的是发音相同(或相似)但书写形式不同的汉字。这在语言学习、诗歌创作、语音识别系统中都非常实用。
本题使用的数据集 h_3_3 与上一题完全相同。它是一个包含 7894 个汉字及其拼音的字符串数组。对于多音字,不同的拼音通过 | 分隔。
你需要完成以下任务:给定一个字符串标量s,s中保存着某个汉字。请找出该汉字的所有同音字。如果一个汉字有多种发音(多音字),则需要找出每种发音的同音字。
请将结果保存到一个n行2列的字符串数组Q中,其中n是该汉字的拼音数量。第一列表示拼音,第二列表示对应的同音字。
举几个例子供大家理解:
s等于"饿",它有一个读音:è,那么你需要得到的Q为:

s等于"校",它有两个读音:xiào和jiào,那么你需要得到的Q为:

s等于"着",它有四个读音:zhe、zhuó、zháo和zhāo,那么你需要得到的Q为:

进一步思考,如果将不同的声调(轻声、一声、二声、三声和四声)的拼音也视为同音字,结果有何变化(例如:消、淆、小和笑这四个字都属于xiao的读音)?
Q5:从网页源码中提取成语(本题数据为h_3_5)
请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_3_5,它是一个20行1列的字符向量元胞数组,这20个字符向量中保存着20个网页的源代码。这些网页源代码来自于某个介绍成语故事的网站,每个网页中都有100个成语。
例如h_3_5中保存的第一个网页源代码(即h_3_5{1})的开头如下所示:
这个网页的源代码非常长,大家可以先将这个字符向量中的内容复制到记事本中,然后往下翻,在下方区域中可以看到我们要提取的成语:

请从这20个网页的源码中提取出所有的成语,并将结果保存到一个长度为2000的字符串向量cy中。
Q6:成语世界探秘和接龙游戏(本题数据为h_3_6)
请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_3_6,它是一个30767行3列的字符串数组,里面保存着某网站提供的30767个成语和拼音:

根据上面的数据完成以下四个任务(各任务是独立的,没有先后顺序):
(1)查找指定结构形式的成语
在博大精深的中文成语世界里,不同的字排列组合形成了丰富多样的表达形式。其中,有一些成语的结构形式特别规整,如AABB式、AABC式和ABAB式等,它们以其独特的形式展现了成语的韵律之美。
以AABB式为例,这种形式的成语要求第一个字与第二个字相同,第三个字与第四个字相同,同时第一个字与第三个字不同。例如,“世世代代”、“严严实实”和“家家户户”都是典型的AABB式成语。
现在,请你从给定的数据中,探寻这些具有特定结构形式的成语。你的任务是分别提取出满足AABB式、AABC式和ABAB式的四字成语,并将它们分类保存到三个不同的字符串向量中。
(2)提取生肖成语
中国的传统文化中,十二生肖(鼠、牛、虎、兔、龙、蛇、马、羊、猴、鸡、狗、猪)是非常重要的一部分,每个生肖都有其独特的象征意义和特点。这些生肖也经常出现在我们的成语中,丰富了成语的表达方式和文化内涵。
请从给定的数据中,提取出包含十二生肖的成语(不需要考虑生肖的别称,例如狗的成语中不需要包括“犬牙交错”),并将结果保存到一个12行1列的字符向量元胞数组中,元胞数组中每个位置的数据保存一个生肖的成语,同一生肖内不同的成语之间使用换行符隔开。
(3)探索高频汉字与拼音
在成语中,某些汉字和拼音的出现频率高于其他。这些高频的汉字和拼音往往揭示了我们在日常使用成语时的偏好和习惯。
请你对给定的成语数据进行深入探索:首先,提取所有成语中的汉字,并找出出现频率最高的前10个汉字。将这10个汉字合并为一个字符串标量,中间用中文顿号“、”隔开;其次,提取所有成语的无声调拼音(h_3_6的第三列),并找出出现频率最高的前10个拼音。同样地,将这10个拼音合并为一个字符串标量,中间用中文顿号“、”隔开。
参考答案: "不、之、一、无、人、心、天、风、大、如" 以及 "yi、bu、zhi、shi、wu、ji、yu、qi、li、yan"。
(4)成语接龙游戏
在本任务中,你需要设计一个成语接龙游戏,具体的游戏规则如下:
开始游戏:游戏开始时,你可以任意输入一个成语,或输入“提示”来获取随机的成语。
接龙规则:每个成语的最后一个字必须是下一个成语的第一个字。
提示功能:在你的回合中,你可以输入“提示”来获取可以接的成语建议(如果可以接的成语较多的话,只需要给出最多五个成语进行提示)。
退出游戏:你可以输入“退出”来结束游戏。
游戏结束条件:如果你或者电脑找不到可以接的成语时,游戏结束。
游戏结束后:输出这一轮游戏中出现的所有成语。
注意事项:游戏中出现的所有成语都必须包含在h_3_6中,且已经使用过的成语不能再次使用。如果用户输入了一个不在h_3_6中的成语,或者输入了一个已经被使用过的成语,程序中应给出相应的提示。
下面是供大家参考的两次游戏过程,程序中通过input函数获得用户的输入内容
| 请输入一个成语开始游戏(退出游戏请输入退出、如需提示请输入提示):三心二意 你的成语是三心二意,我接的是:意合情投 --------------------------------分割线-------------------------------- 你需要输入以“投”开头的成语 请输入你的答案(退出游戏请输入退出、如需提示请输入提示):提示 提示:你可以接的成语有:投井下石、投其所好、投卵击石、投怀送抱、投机倒把 --------------------------------分割线-------------------------------- 你需要输入以“投”开头的成语 请输入你的答案(退出游戏请输入退出、如需提示请输入提示):投怀送抱 你的成语是投怀送抱,我接的是:抱瓮灌园 --------------------------------分割线-------------------------------- 你没有可以接的成语了,游戏结束! --------------------------------分割线-------------------------------- 本局游戏的成语如下: ??? "三心二意" ??? "意合情投" ??? "投怀送抱" ??? "抱瓮灌园" ? |
| 请输入一个成语开始游戏(退出游戏请输入退出、如需提示请输入提示):高高兴兴 你的成语是高高兴兴,我接的是:兴妖作怪 --------------------------------分割线-------------------------------- 你需要输入以“怪”开头的成语 请输入你的答案(退出游戏请输入退出、如需提示请输入提示):怪我太傻 你输入的可能不是成语,请重新输入! --------------------------------分割线-------------------------------- 你需要输入以“怪”开头的成语 请输入你的答案(退出游戏请输入退出、如需提示请输入提示):提示 提示:你可以接的成语有:怪事咄咄、怪声怪气、怪形怪状、怪模怪样、怪腔怪调 --------------------------------分割线-------------------------------- 你需要输入以“怪”开头的成语 请输入你的答案(退出游戏请输入退出、如需提示请输入提示):怪声怪气 你的成语是怪声怪气,我接的是:气喘吁吁 --------------------------------分割线-------------------------------- 你没有可以接的成语了,游戏结束! --------------------------------分割线-------------------------------- 本局游戏的成语如下: ??? "高高兴兴" ??? "兴妖作怪" ??? "怪声怪气" ??? "气喘吁吁" |
Q7:整理王者荣耀英雄数据(本题数据为h_3_7)
请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_3_7,它是一个长度为21458的字符向量,其中保存了王者荣耀中117名英雄角色的相关数据,数据开头如下:

你的任务是提取每位英雄的cname(英雄名称)、title(英雄雅称)和skin_name(皮肤名称)。需要注意的是,某些英雄可能没有皮肤数据,对于这些英雄,请使用空字符串来表示他们的皮肤名称。
最终,你需要将结果保存到一个117行3列的字符串数组D中,其中每一行对应一个英雄,三列分别对应英雄的名称、雅称和皮肤名称。
参考答案如下:

Q8:整理王者荣耀装备数据(本题数据为h_3_8)
请按照本小节开头的提示导入好作业的数据,本题用到的数据为h_3_8,它是一个长度为31313的字符向量,其中保存了王者荣耀中136件装备的相关数据,部分数据如下所示:

你需要从数据中提取以下信息:装备的名称 (item_name)、装备的价格 (price)、装备的总价(total_price)以及装备的描述 (des1,如果存在 des2 也需要一并提取)。
注意:装备描述中可能包含 HTML 标签(如 <p> 和 <br>),在提取描述时,请确保去除这些标签,只保留纯文本信息。另外,装备名称和描述信息请使用字符串向量保存,价格和总价请使用数值向量保存。
参考答案如下:
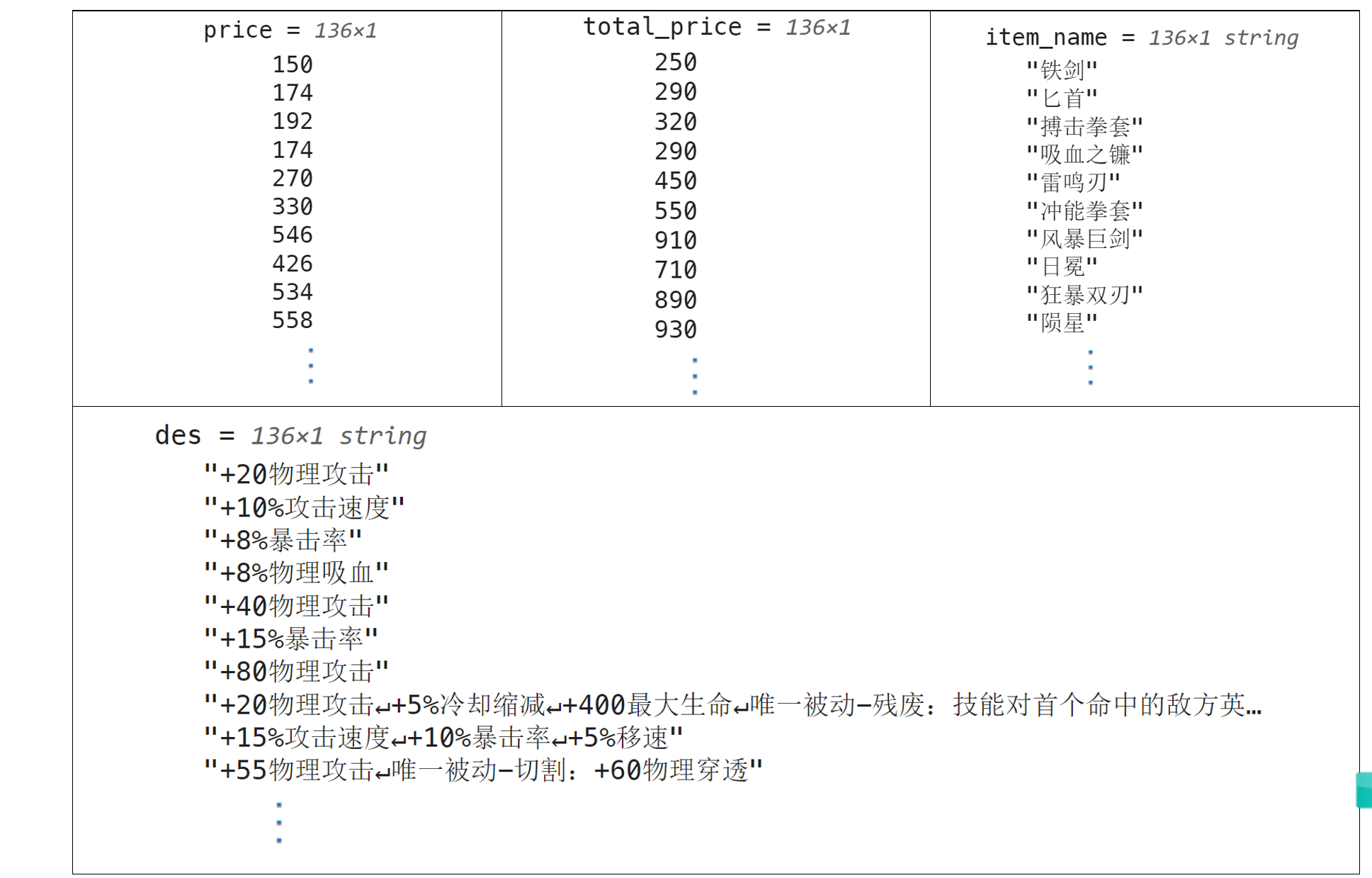
参考答案:
??点击下方的CSDN专栏阅读下一篇文章:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 单例设计模式
- [问题随记]-如何修改网页中input type=file按钮名字
- 迪文串口屏开发环境搭建
- 【精通C语言】:深入解析for循环,从基础到进阶应用
- 分享Python采集40个NET整站程序源码,总有一款适合您
- 解决Qt UI界面卡顿的优化方法
- 特征工程-特征处理(三)
- 13、Kafka ------ kafka 消费者API用法(消费者消费消息代码演示)
- docker干货分享-安装redis-只需四个命令即可
- HarmonyOS的第一个project