利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
Neo4j 在5.11版本中将向量搜索功能完全集成到 Neo4j AuraDB 和 Neo4j 图数据库中。随后对 Neo4j 向量检索的全面支持也被集成到了 LangChain 库中。
Neo4j 向量检索已成为检索增强生成 (RAG) 应用程序领域的关键工具,特别是在处理结构化和非结构化数据方面。LangChain 库是构建大型语言模型 (LLM) 应用程序的重要框架。
这种集成有助于将数据有效地摄取到 Neo4j Vector Index 中,简化了 RAG 应用程序中的数据摄取和查询,并能够构建有效的 RAG 应用程序,通过利用结构化和非结构化数据提供实时、准确且与上下文相关的答案。它支持数据摄取和读取工作流程,对于使用 RAG 架构开发问答聊天机器人特别有用。
这篇文章将演示如何利用 LangChain 将数据有效摄取到 Neo4j 向量索引中,然后构建一个简单而有效的 RAG 应用程序。
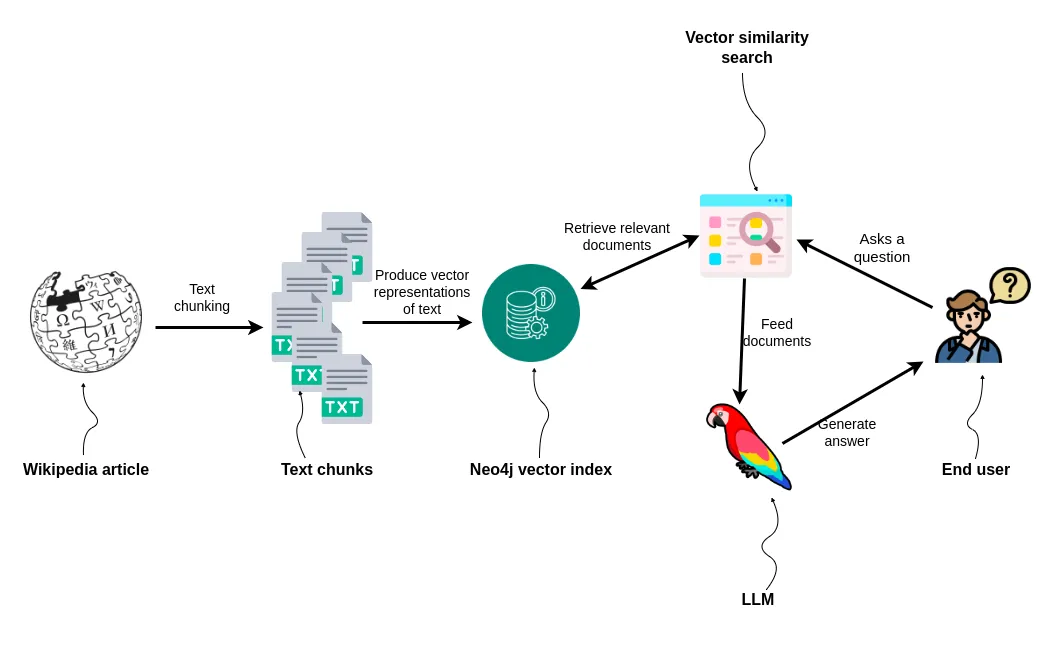
本教程将包含以下步骤:
-
使用 LangChain 文档阅读器阅读维基百科文章
-
将文本分块
-
将文本存储在 Neo4j 中并使用新添加的向量索引对其进行索引
-
实施问答工作流程以支持 RAG 应用程序。
用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了NLP面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

01 Neo4j 环境设置
我们需要设置 Neo4j 5.11 或更高版本才能完成本文章中的示例。最简单的方法是在 Neo4j Aura 上启动一个免费实例,它提供 Neo4j 数据库的云实例。或者,我们还可以通过下载 Neo4j Desktop 应用程序并创建本地数据库实例来设置 Neo4j 数据库的本地实例。
首先安装 langchain openai wikipedia tiktoken neo4j 包
pip install langchain openai wikipedia tiktoken neo4j
然后导入配置
import os
from langchain.vectorstores.neo4j_vector import Neo4jVector
from langchain.document_loaders import WikipediaLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
os.environ['OPENAI_API_KEY'] = "API_KEY"
02 阅读和分块维基百科文章
我们将从阅读和分块维基百科文章开始。这个过程非常简单,因为 LangChain 集成了维基百科文档加载器以及文本分块模块。
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import CharacterTextSplitter
# Read the wikipedia article
raw_documents = WikipediaLoader(query="Leonhard Euler").load()
# Define chunking strategy
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=20
)
# Chunk the document
documents = text_splitter.split_documents(raw_documents)
# Remove summary from metadata
for d in documents:
del d.metadata['summary']
由于 Neo4j 是一个图形数据库,使用有关 Leonhard Euler 的维基百科文章作为示例是比较合适的。接下来,我们使用 tiktoken 文本分块模块,该模块使用 OpenAI 制作的分词器,将文章分成具有1000个标记的块。我们可以在本文中了解有关文本分块策略的更多信息。
LangChain WikipediaLoader 默认为每个块添加一个摘要。我认为添加的摘要有点多余。例如,如果我们使用向量相似性搜索来检索前三个结果,则摘要将重复三次。因此,我决定将其从数据集中删除。
03 使用 Neo4j 存储文本并为其建立索引
LangChain 可以轻松地将文档导入 Neo4j 并使用新添加的向量索引对其进行索引,官方尽可能地使其用户友好,这意味着我们无需了解有关 Neo4j 或图形的任何知识即可使用它。另一方面,官方为更有经验的用户提供了几个自定义选项,这些选项官方都会出单独的文章进行介绍。
Neo4j 向量索引被包装为 LangChain 向量存储,因此遵循用于与其他向量数据库交互的语法。
from langchain.vectorstores import Neo4jVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Neo4j Aura credentials
url="neo4j+s://.databases.neo4j.io"
username="neo4j"
pd="<insert password>"
# Instantiate Neo4j vector from documents
neo4j_vector = Neo4jVector.from_documents(
documents,
OpenAIEmbeddings(),
url=url,
username=username,
password=pd
)
该 from_documents 方法连接到 Neo4j 数据库,导入并嵌入文档,并创建向量索引。默认情况下,数据将表示为“Chunk”节点。如前所述,我们可以自定义数据的存储方式以及返回哪些数据。不过,这将在下面的文章中讨论。
如果我们已有包含填充数据的现有向量索引,则可以使用该 from_existing_index 方法。
04 向量相似度搜索
我们将从简单的向量相似性搜索开始,以验证一切是否按预期工作。
query = "Where did Euler grow up?"
results = neo4j_vector.similarity_search(query, k=1)
print(results[0].page_content)
结果如下:

LangChain 模块使用指定的嵌入函数(本例中为 OpenAI)嵌入问题,然后通过比较用户问题和索引文档之间的余弦相似度来找到最相似的文档。
Neo4j 向量索引还支持欧几里得相似度度量以及余弦相似度。
05 LangChain 问答工作流程
LangChain 的好处是它支持仅使用一两行代码的问答工作流程。例如,如果我们想要创建一个问答系统,根据提供的上下文生成答案,同时还提供它用作上下文的文档,我们可以使用以下代码。
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQAWithSourcesChain
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=neo4j_vector.as_retriever()
)
query = "What is Euler credited for popularizing?"
chain(
{"question": query},
return_only_outputs=True,
)
结果如下:

正如我们所看到的,LLM 根据提供的维基百科文章构建了准确的答案,但也返回了它使用的源文档。我们只需要一行代码就可以实现这一点。
在测试代码时,我注意到并不总是返回源代码。这里的问题不是 Neo4j Vector 实现,而是 GPT-3.5-turbo。有时,它不听指令返回源文档。但是,如果我们使用 GPT-4,问题就会消失。
最后,为了复制 ChatGPT 界面,我们可以添加一个内存模块,该模块还为 LLM 提供对话历史记录,以便我们可以提出后续问题。同样,我们只需要两行代码。
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
qa = ConversationalRetrievalChain.from_llm(
ChatOpenAI(temperature=0), neo4j_vector.as_retriever(), memory=memory)
现在我们来测试一下。
print(qa({"question": "What is Euler credited for popularizing?"})["answer"])
结果如下:

现在是一个后续问题。
print(qa({"question": "Where did he grow up?"})["answer"])
结果如下:

总结
向量索引是 Neo4j 的一个重要补充,使其成为处理 RAG 应用程序的结构化和非结构化数据的出色解决方案。希望 LangChain 集成能够简化将向量索引集成到现有或新的 RAG 应用程序中的过程,这样我们就不必担心细节。请记住,LangChain 已经支持生成 Cypher 语句并使用它们来检索上下文,因此我们现在可以使用它来检索结构化和非结构化信息。
参考文献
https://medium.com/neo4j/langchain-library-adds-full-support-for-neo4j-vector-index-fa94b8eab334
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux中用户及用户组信息
- 如何在 NestJS 项目中优雅的使用发布订阅工具 Event Emitter
- superset利用mysql物化视图解决不同数据授权需要写好几次中文别名的问题
- GEE——使用cart机器学习方法对Landsat影像条带修复以NDVI和NDWI为例(全代码)
- Qt通用属性工具:随心定义,随时可见(一)
- element中el-cascader级联选择器只有最后一级可以多选
- 力扣15 三数之和(Java版本)
- 虚拟机架构介绍
- 深度解析 Compose 的 Modifier 原理 -- Modifier.composed()、ComposedModifier
- 用js做个转盘