linux网络版计算机
前言
一、网络版计算机
1.序列化与反序列化
协议是一种 “约定”. socket api的接口, 在读写数据时, 都是按 “字符串” 的方式来发送接收的. 如果我们要传输一些"结构化的数据" 怎么办呢?
例如, 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器进行计算, 最后再把结果返回给客户端。
约定方案一:
客户端发送一个形如"1+1"的字符串;
这个字符串中有两个操作数, 都是整形;
两个数字之间会有一个字符是运算符, 运算符只能是 + ;
数字和运算符之间没有空格;
约定方案二:
定义结构体来表示我们需要交互的信息;
发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;
这个过程叫做 “序列化” 和 “反序列化”
2.网络版计算机实现
下面我们就采用约定方案二来指定一个网络版计算机传输数据的协议。
我们先来实现一个Sock套接字类,该类封装了创建套接字,绑定套接字等一些接口,以方便构建服务器使用。
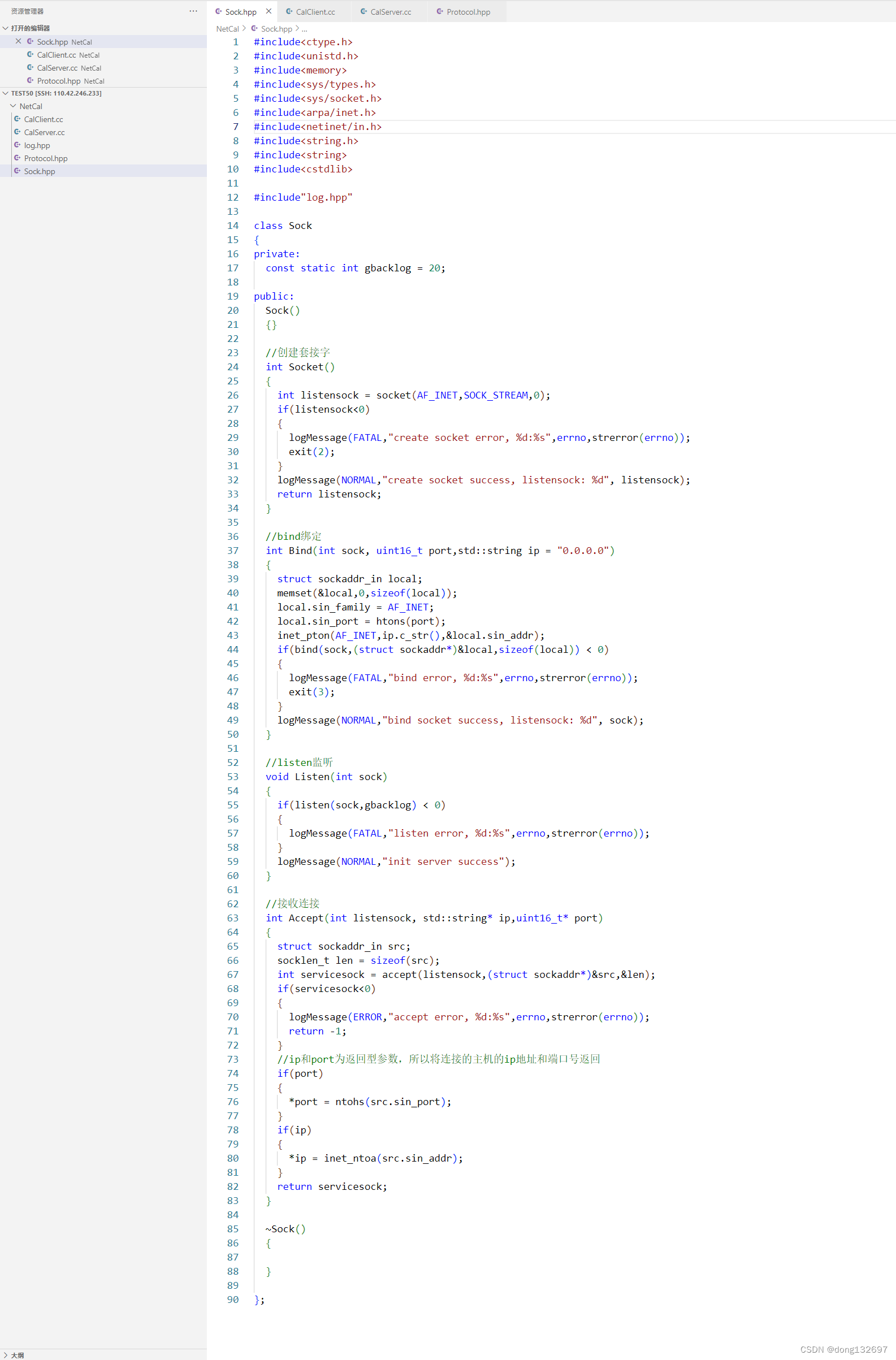
然后我们使用刚刚封装的Sock接口来创建一个TcpServer。在TcpServer中每当有一个连接时,我们就创建一个线程来处理这个连接请求。我们应该在线程回调函数ThreadRoutine中调用用户向该服务器传入的需要执行的函数func_。但是因为ThreadRoutine函数为静态成员函数,不能访问非静态成员变量,所以我们无法在ThreadRoutine函数中调用func_。
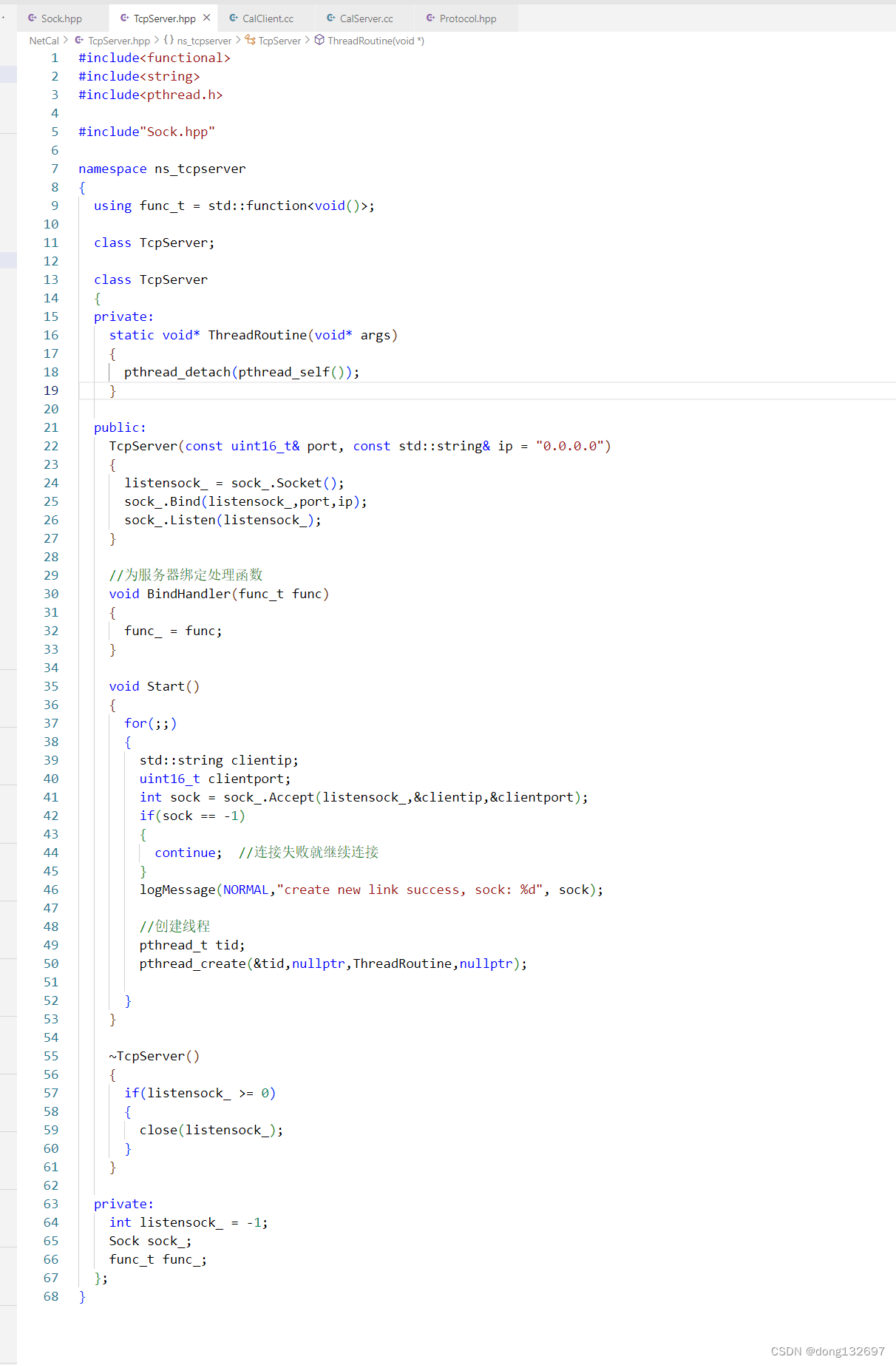
我们可以采用下面的解决办法,我们在要传递给线程回调函数的参数类型ThreadData中封装一个TcpServer * 类型的指针,然后当ThreadRoutine函数收到参数后,根据传进来的TcpServer * 类型的指针来调用TcpServer对象的成员函数就可以了。这样我们就解决了静态成员函数ThreadRoutine调用TcpServer对象的非静态成员函数的问题。可以看到,我们在Excute函数中调用了TcpServer对象的func_函数,这样在ThreadRoutine函数中,每个线程就可以通过TcpServer * 指针来调用Excute函数来执行func_函数了。
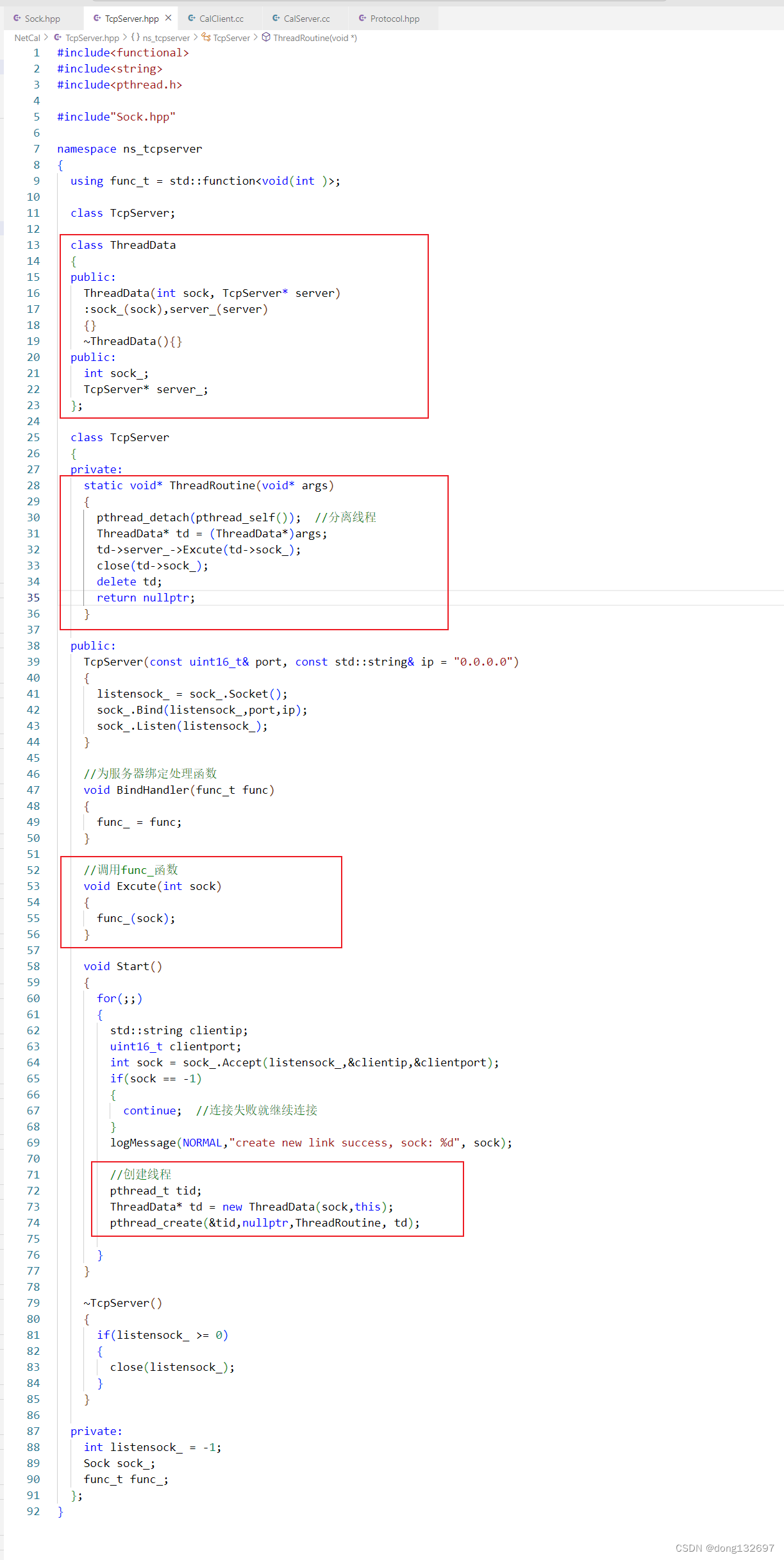
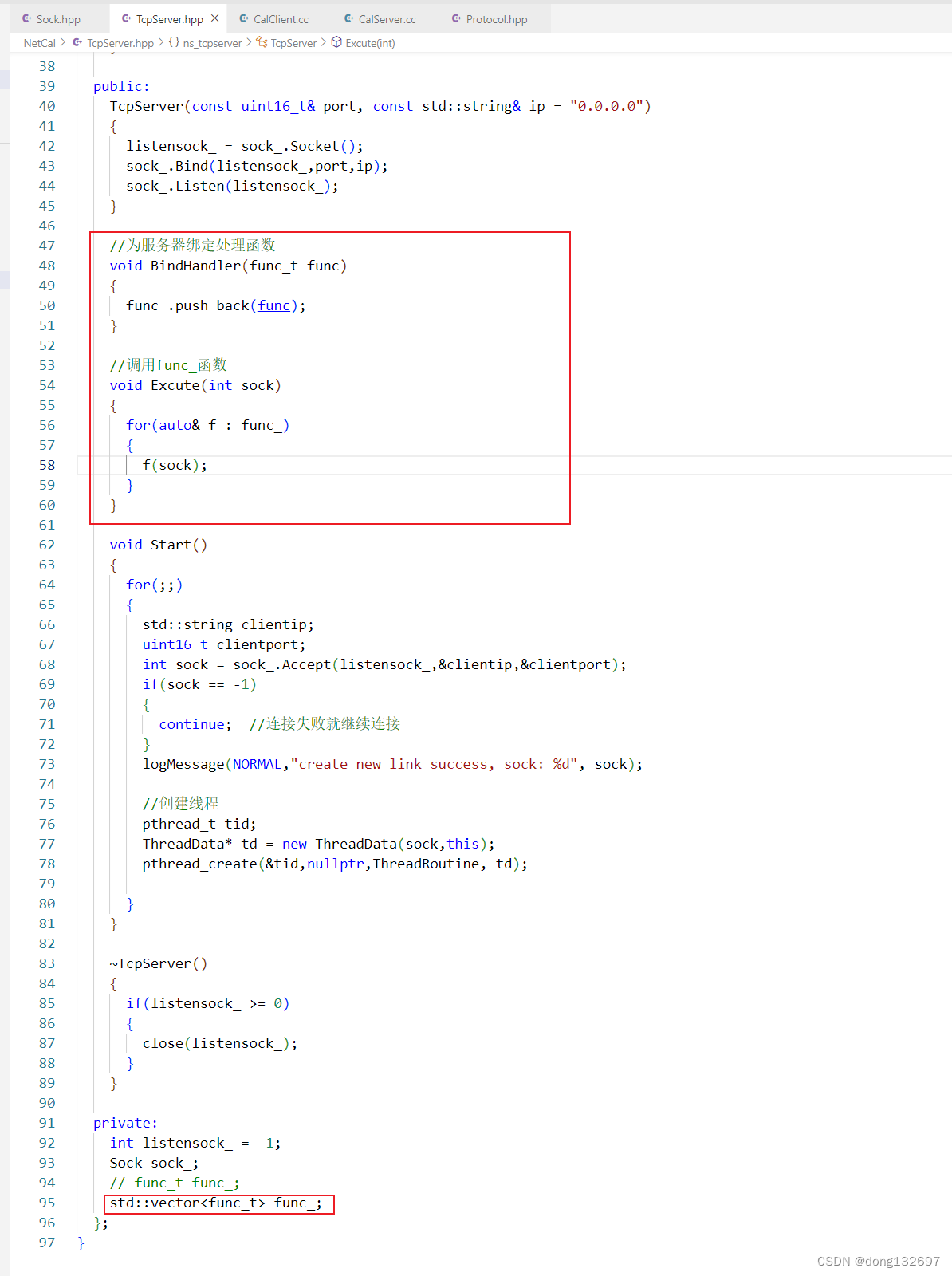
如果我们向让TcpServer做一系列操作的话,那么我们可以创建一个vector容器,然后将函数都添加到vector容器中,然后可以调用TcpServer对象的BindHandler函数来添加一个函数,也可以调用TcpServer对象的Excute函数来执行vector容器中的所有函数。我们还可以将每个操作都进行命名,那么我们就需要使用map容器来存储操作名和对应的操作函数了,在调用TcpServer对象的BindHandler函数添加函数时需要为这个操作传入一个名称。
然后我们基于TcpServer再来搭建计算器服务器。我们先在TcpServer服务器中添加一个debug函数来测试服务器是否可以成功执行添加的debug函数。
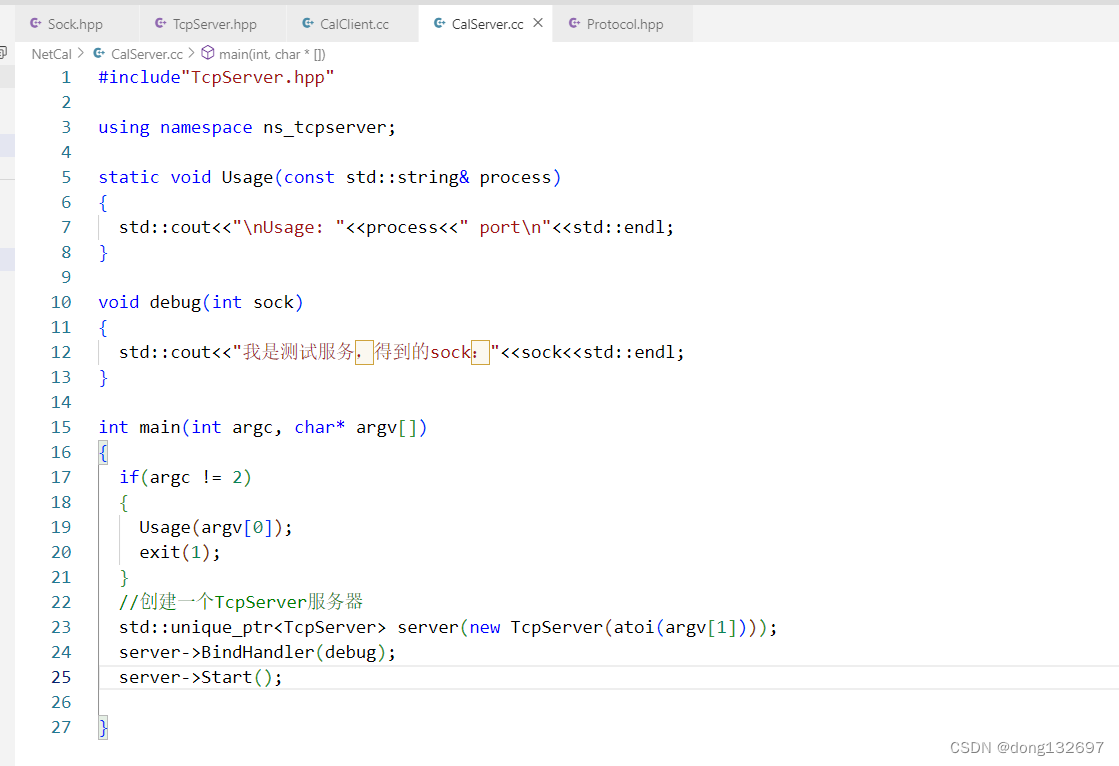
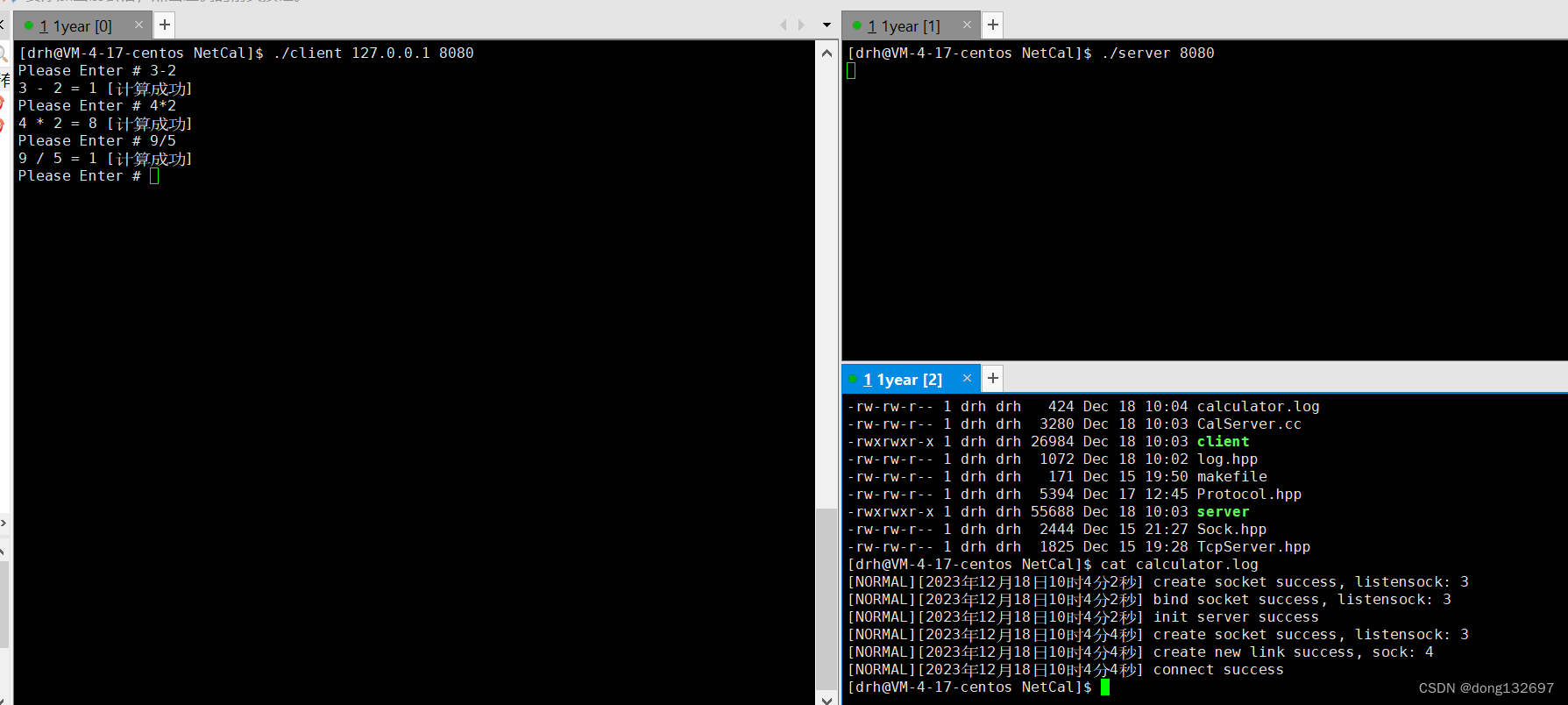
然后我们编写makefile文件后开始进行测试。
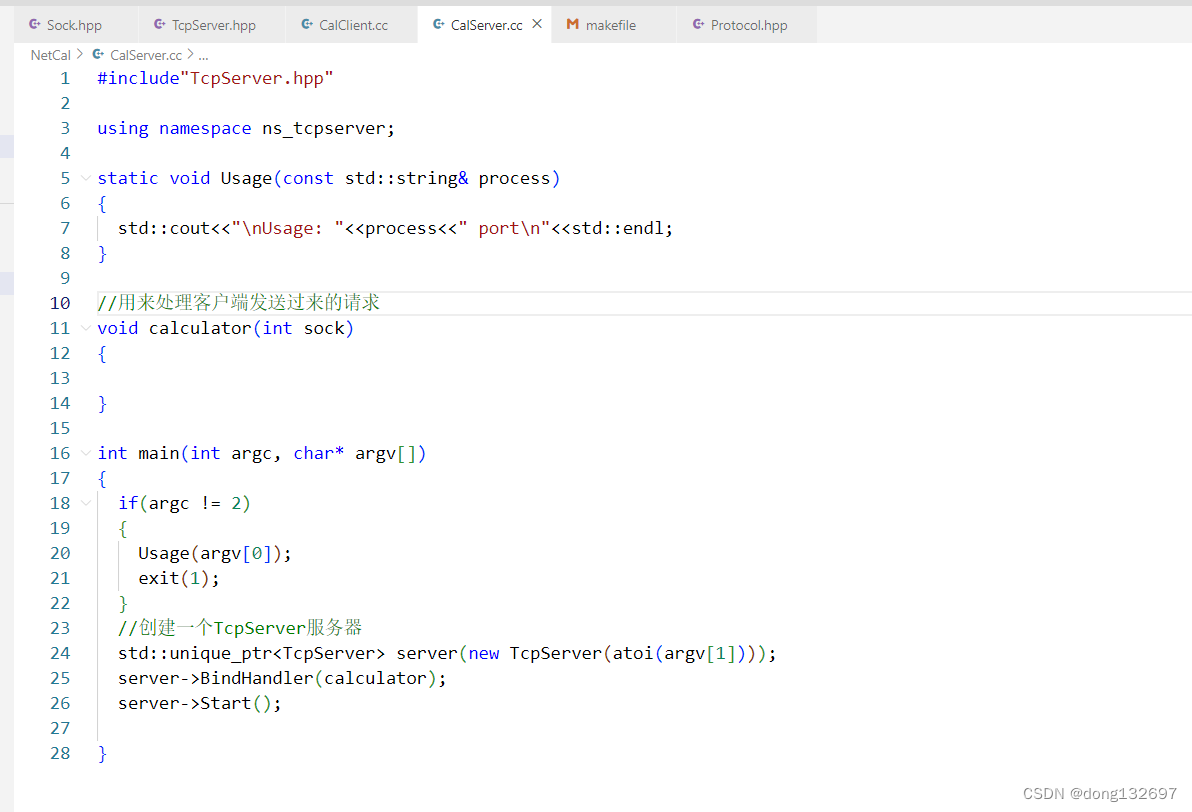
我们看到CalServer服务器收到了客户端发来的消息,即TcpServer服务器执行了CalServer中的debug函数,因为debug函数只是打印一个字符串,所以当这个debug执行完后就关闭了这次连接。

下面我们将calculator函数添加到TcpServer函数中,calculator函数以后就用来处理客户端发送过来的计算请求。
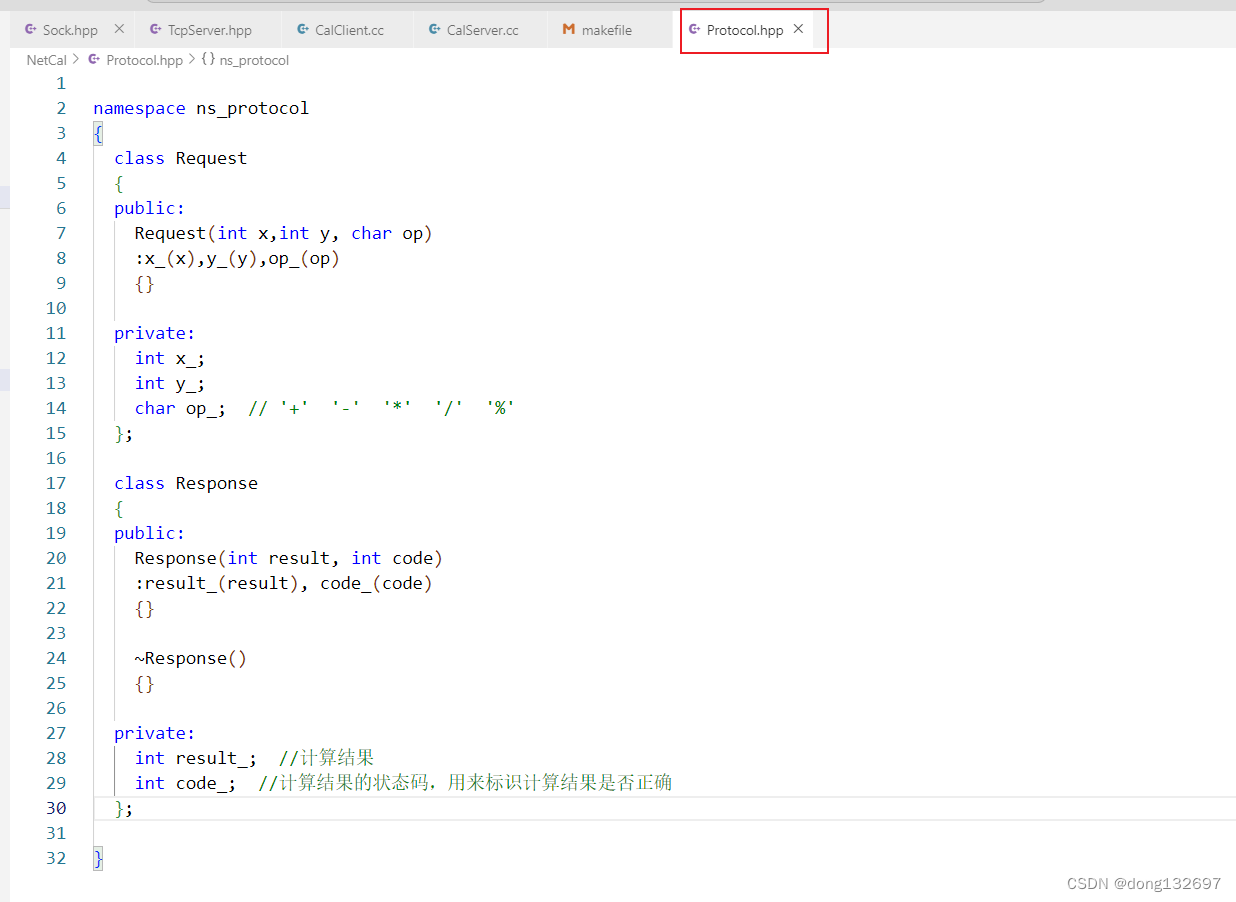
下面我们再来手动进行协议定制,我们在Protocol中进行协议的定制,我们规定客户端的计算请求由一个Request类对象来描述,该对象的x_ 和 y_成员变量表示计算的两个操作数,op_成员变量表示计算的操作符。服务器返回一个Response类对象来表示计算结果,该对象的result_成员变量就是计算结果,code_成员变量标识这次计算是否出现了错误。
通过上面的描述我们知道了客户端发送的请求为一个Request类类型对象,二服务器返回的结果是一个Response类类型的对象。我们在前面只学习了通过套接字传递字符串,所以我们可以先在客户端将Request类类型对象转换为字符串,然后再通过套接字传递给服务器这个字符串。将Request类类型对象转换为字符串的过程就可以称为序列化。服务器收到客户端发送的字符串后,再通过某种规则将这个字符串解析还原为Request对象,即将字符串转换为Request对象,这个过程就是反序列化。服务器拿到Request对象后进行计算,然后将计算结果封装到一个Response对象中,当服务器将Response对象传递给客户端时,也需要先将Response对象转换为字符串然后放到套接字中进行传递,即先将Response对象进行序列化。然后客户端从套接字中收到服务器返回的字符串后,需要先根据定制好的规则将这个字符串解析为Response对象,然后拿到该对象中保存的运算结果和运算结果状态码,这个过程就是反序列化。
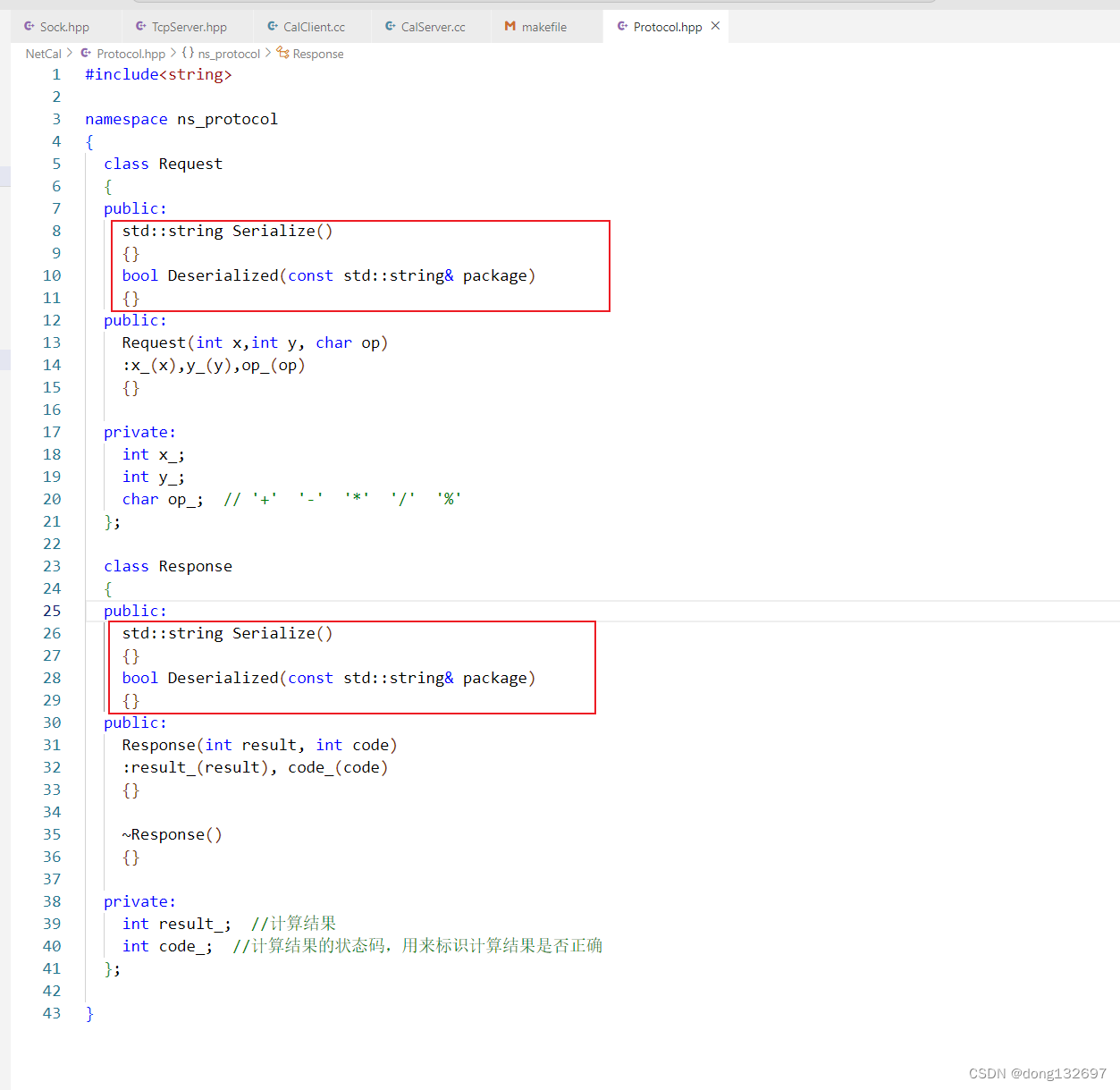
下面我们先实现Request类的序列化函数Serialize函数。下面的实现使用条件编译的原因是因为我们先实现自己定制的序列化和反序列化函数,但是后面我们还会使用其它已经写好的序列化和反序列化函数,条件编译方便了以后序列化使用自己写的函数还是使用其它已经写好的函数。我们自己定义的序列化函数是将操作数x_与操作符中间添加一个空格,然后将操作符与操作数y_之间添加一个空格,然后将这个string对象返回即可。需要注意的是因为op_已经为一个字符了,所以我们不需要使用to_string来将这个字符转换为字符串,因为to_string会将字符op_的ASCII码转换为字符串。例如字符op_如果为+号,+号的ASCII码为43,那么to_string(op_)就会将43转换为字符串。
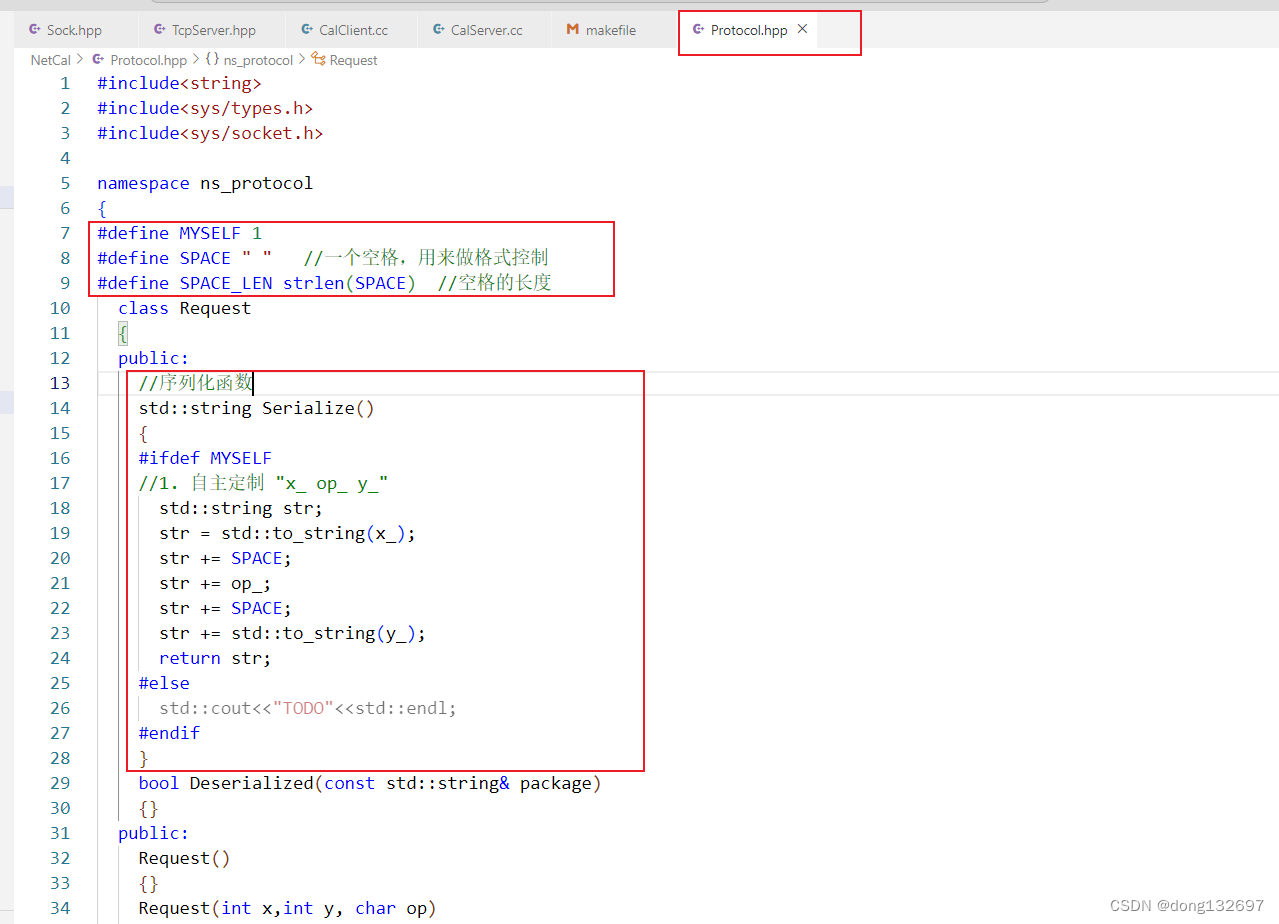
下面我们再来实现Request类的反序列化函数Deserialized函数,我们以空格为分隔符,将字符串中包含的x_、y_、op_都解析出来。
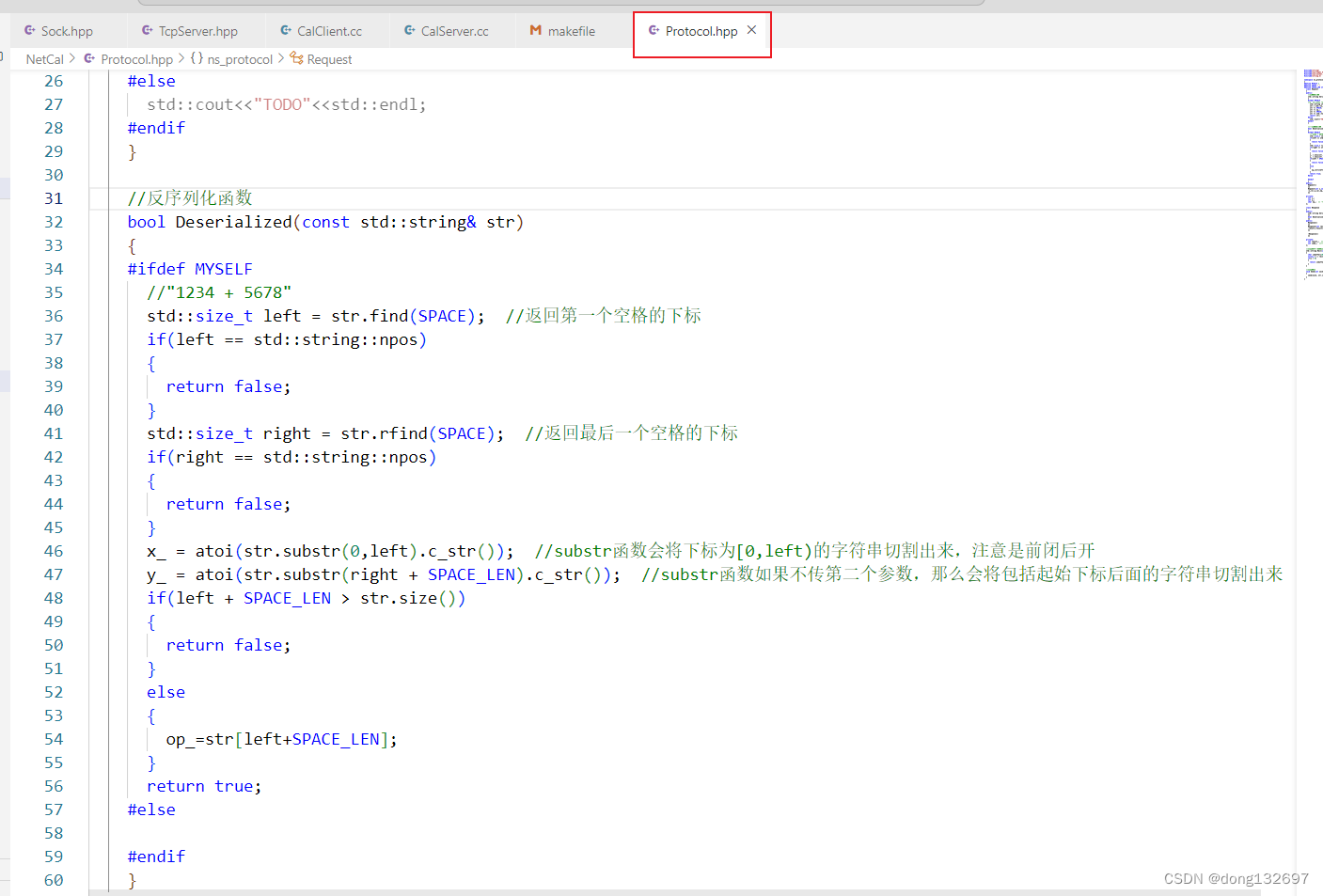
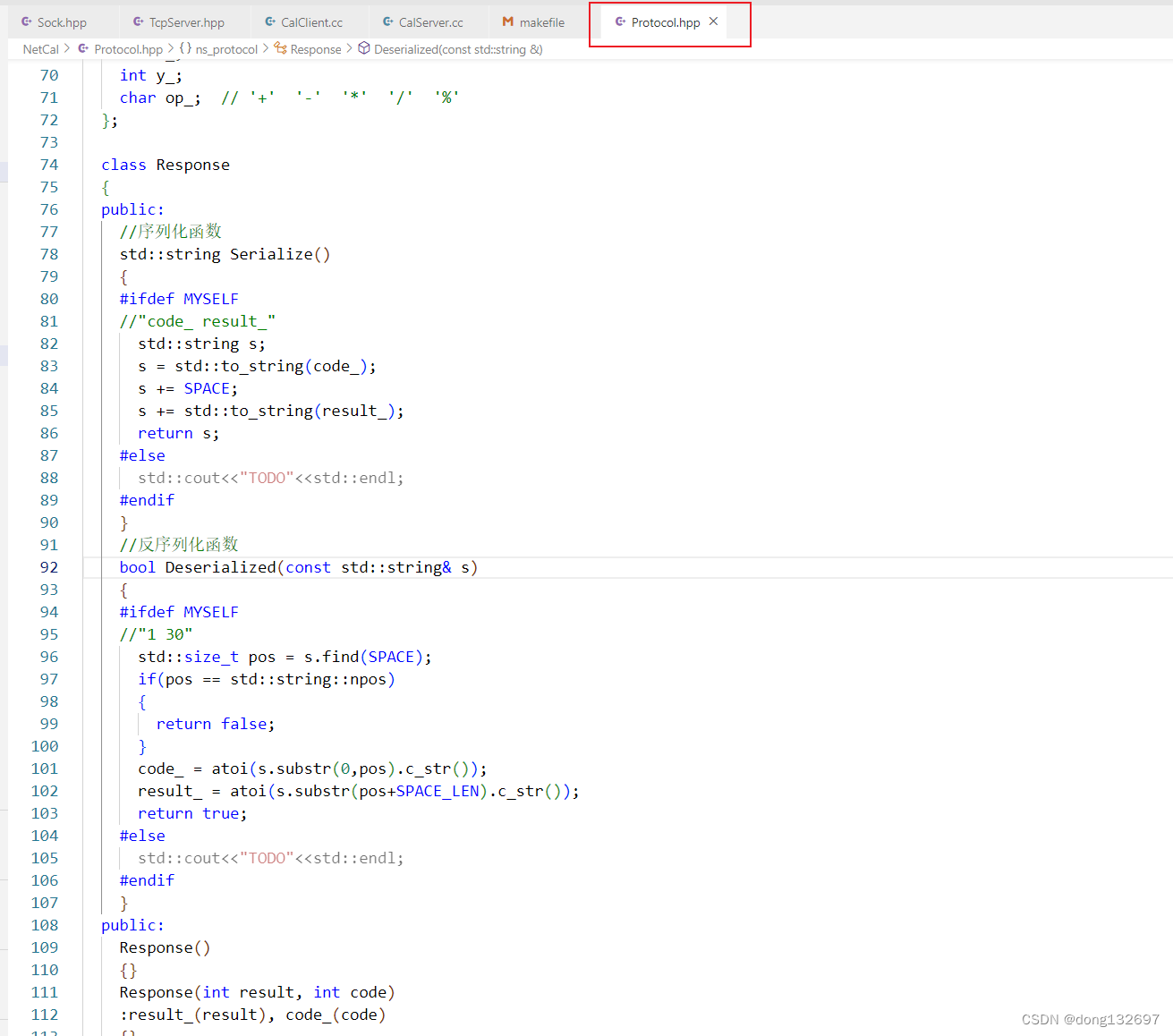
然后我们再来使用Response类的序列化和反序列化函数。
然后我们再实现Recv函数和Send函数,Recv函数会从套接字文件中读取数据并返回。Send函数会将数据写到套接字文件中。
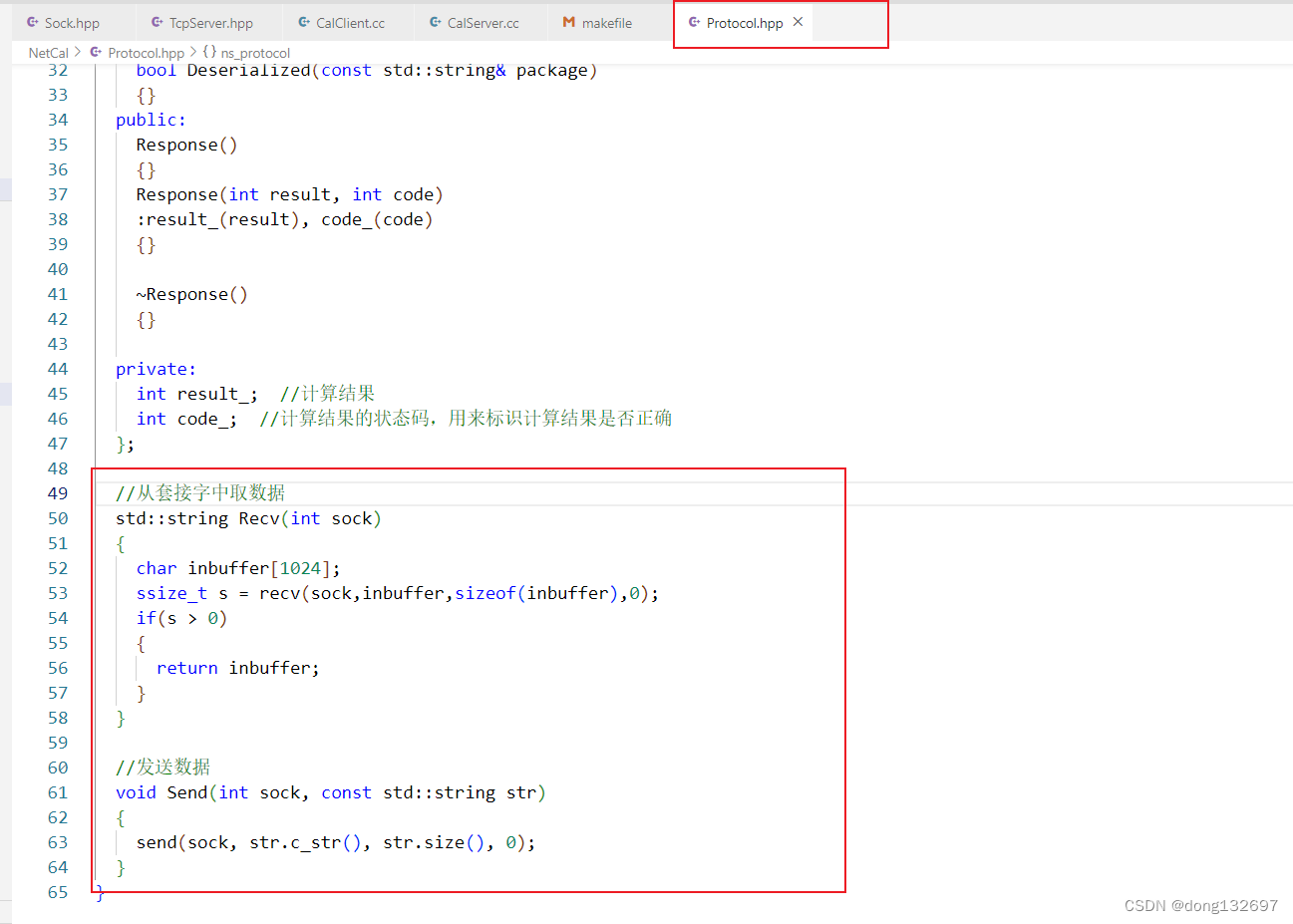
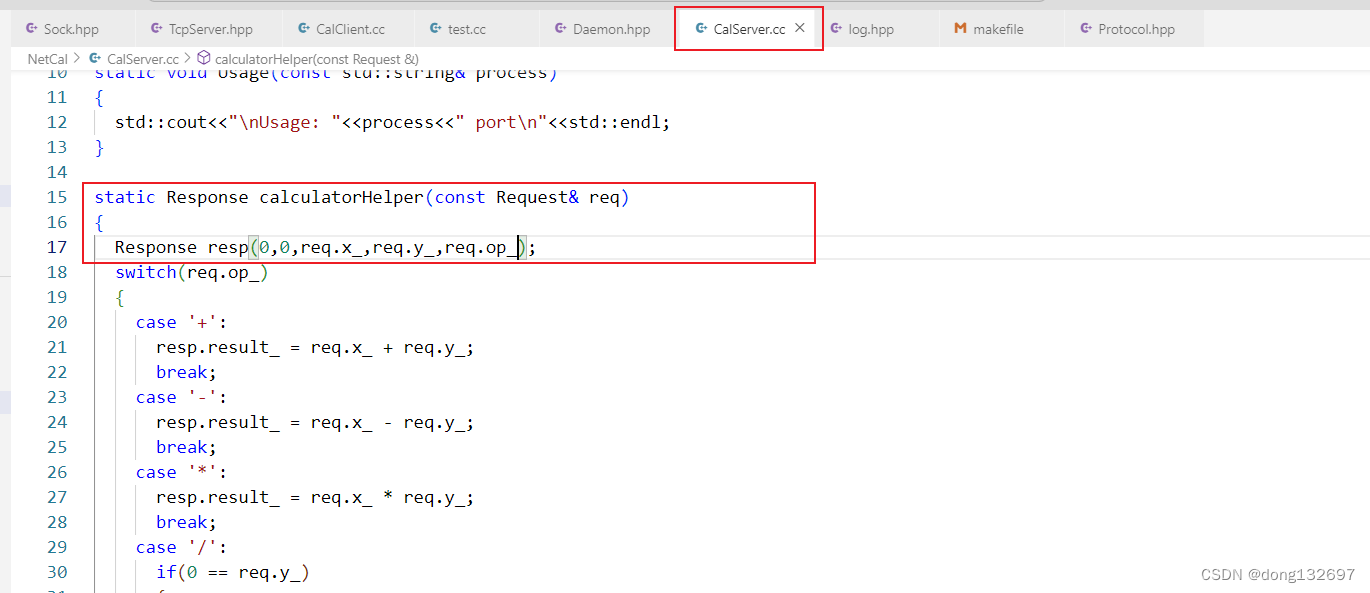
然后我们再来实现CalServer服务器中的处理计算的函数calculator。在calculator函数中通过calculatorHelper函数来进行计算。
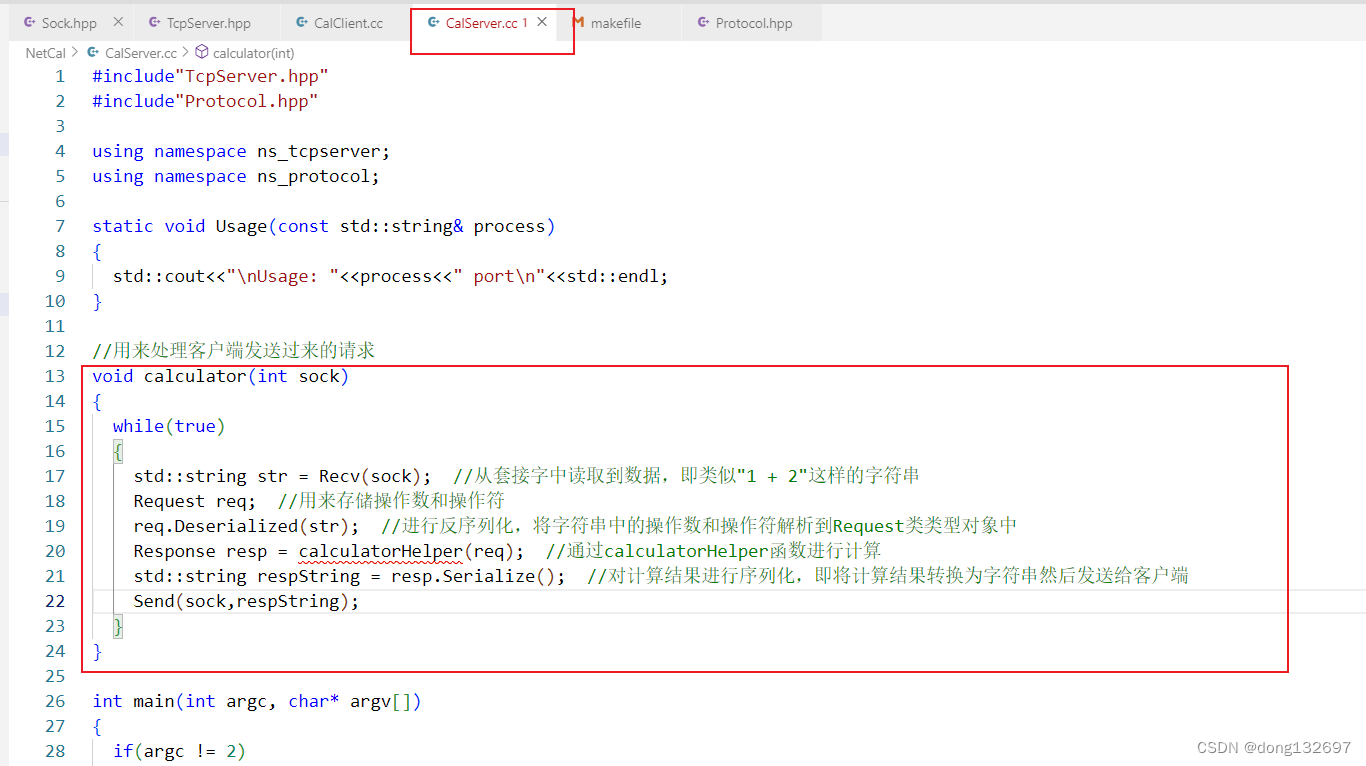
下面我们来实现calculatorHelper函数。
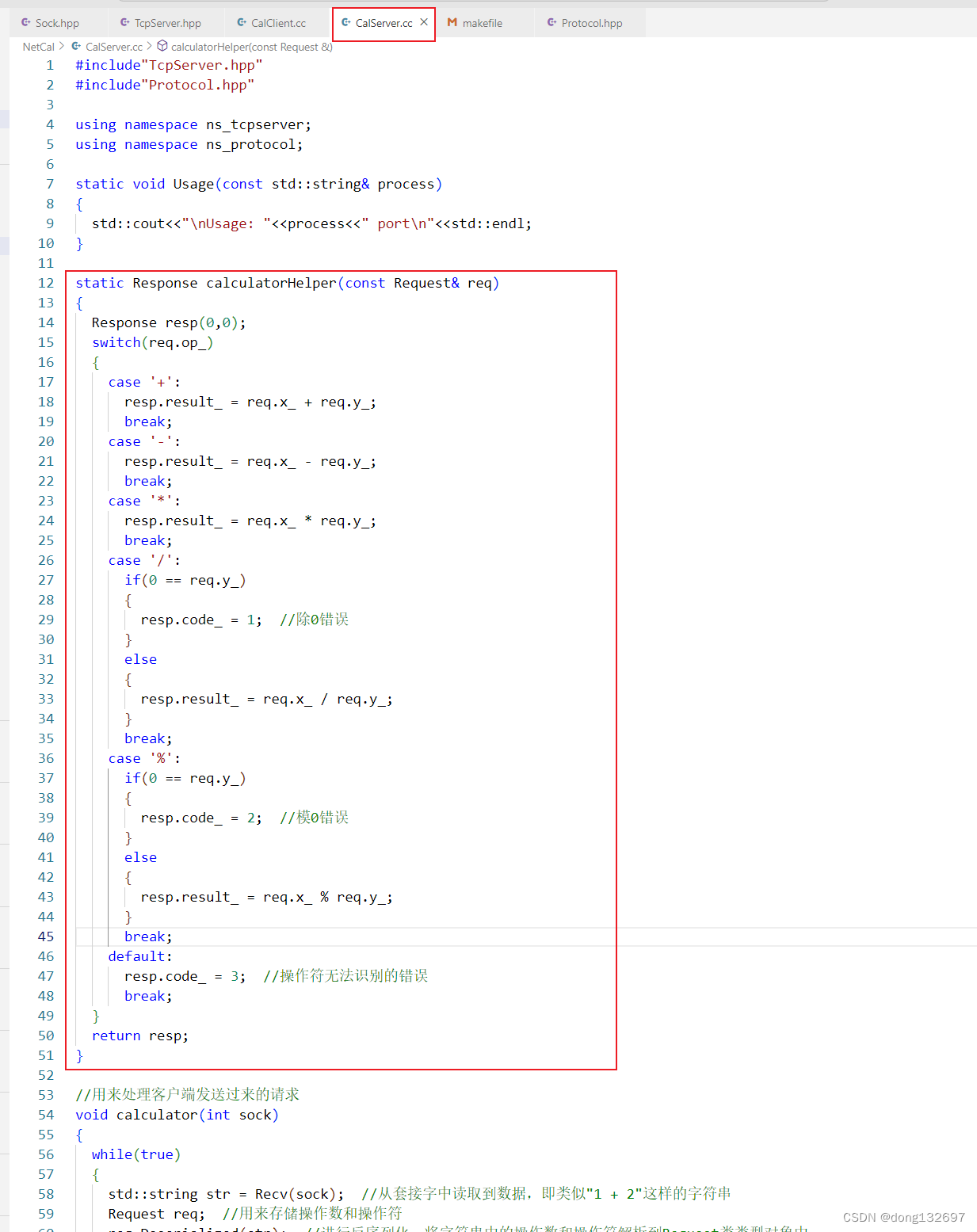
这样我们就简单的实现了CalServer,下面我们来实现CalClient客户端程序。
客户端不需要bind绑定,但是需要连接到服务器,所以我们还需要在Sock类中添加一个Connect连接服务器的接口。
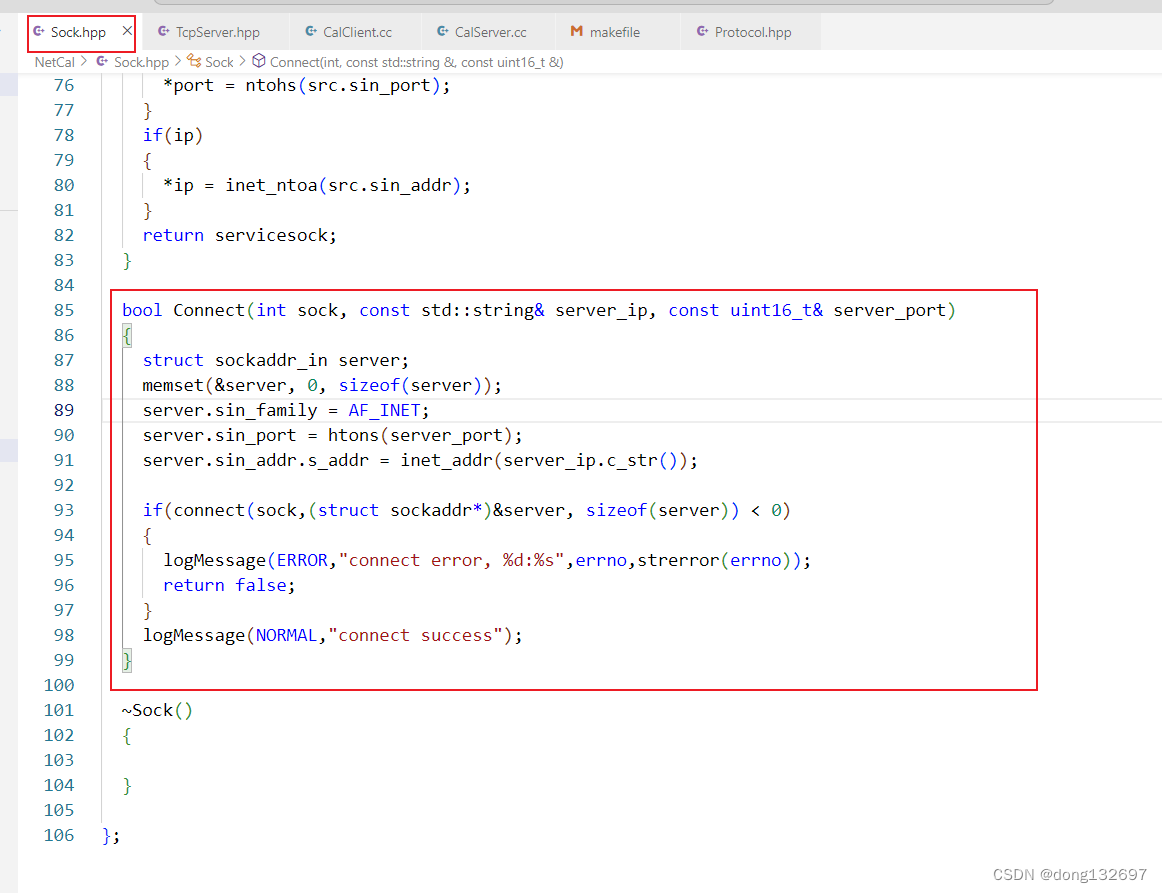
然后我们来实现客户端,我们让客户端每1秒将一个计算式发过去,然后打印出来服务器发送回来的计算结果。
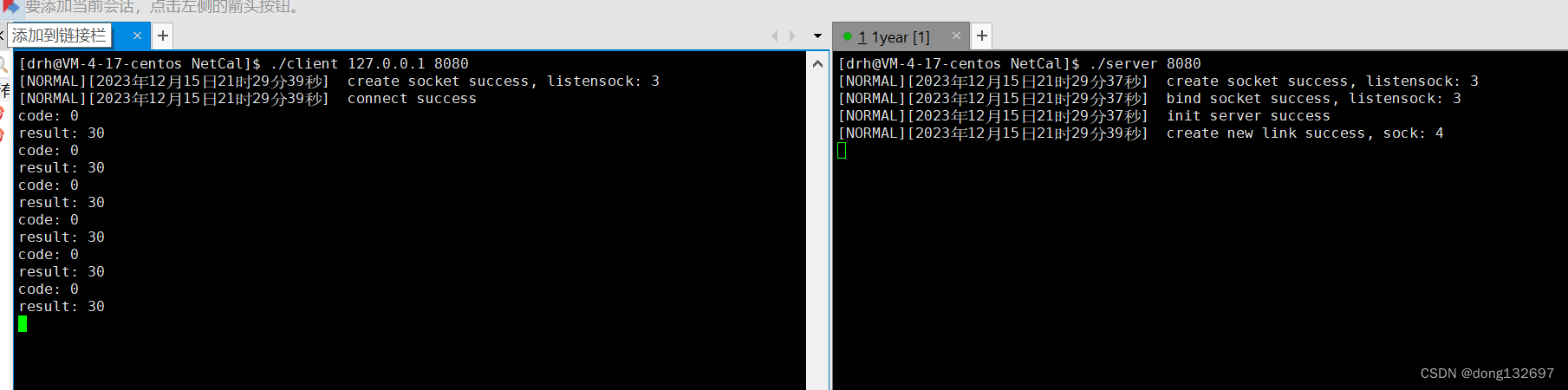
我们看到测试的结果和我们预期的一样。
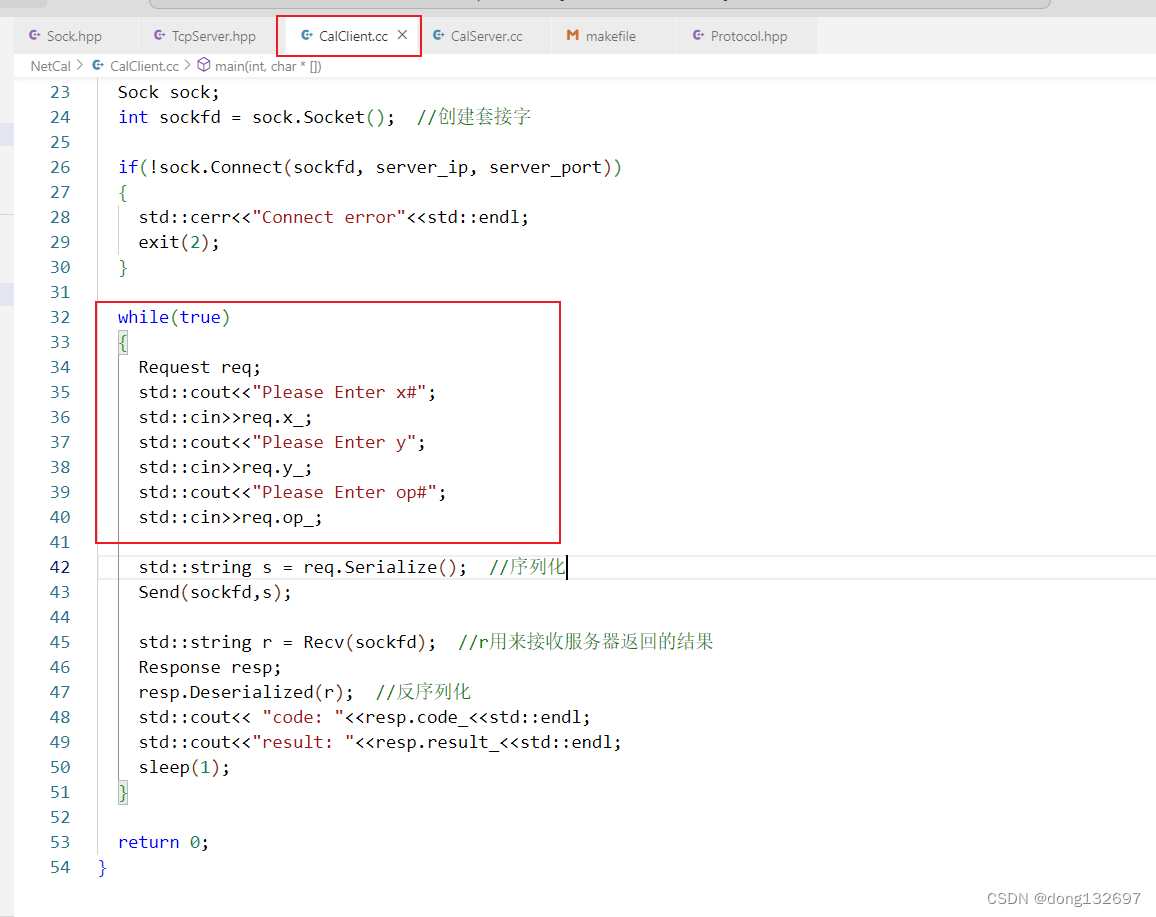
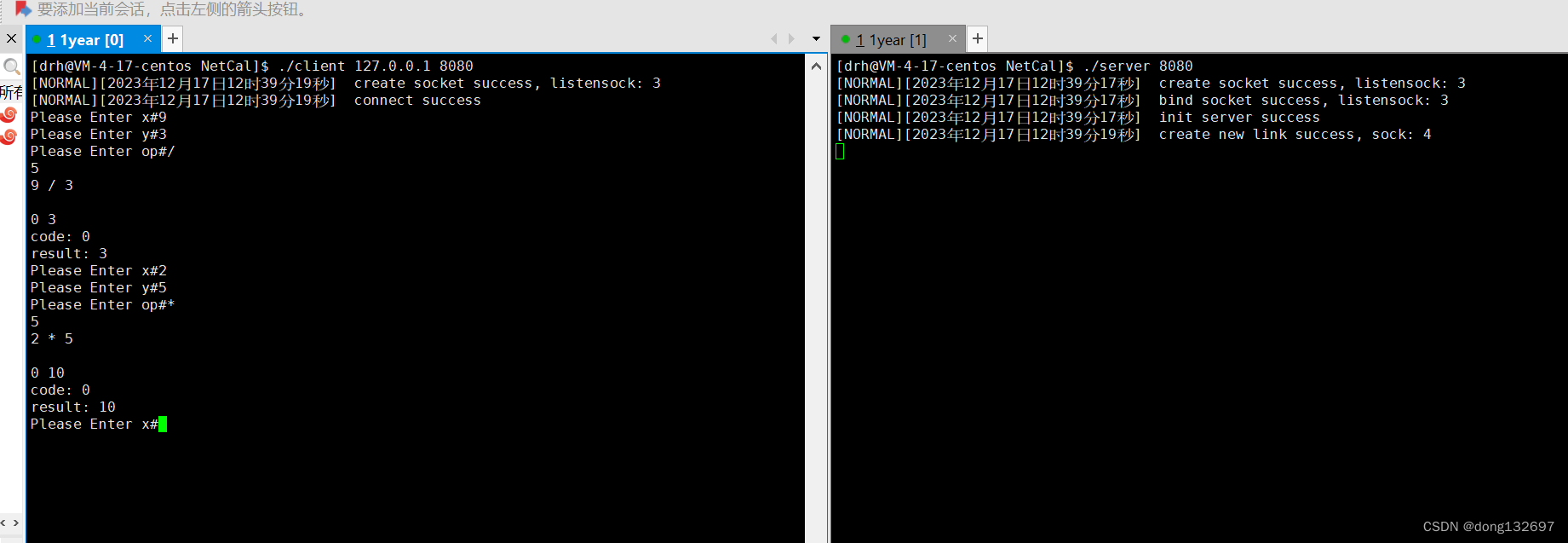
下面我们将客户端改为用户输入,然后让服务器计算用户输入的算式,将答案返回给用户。
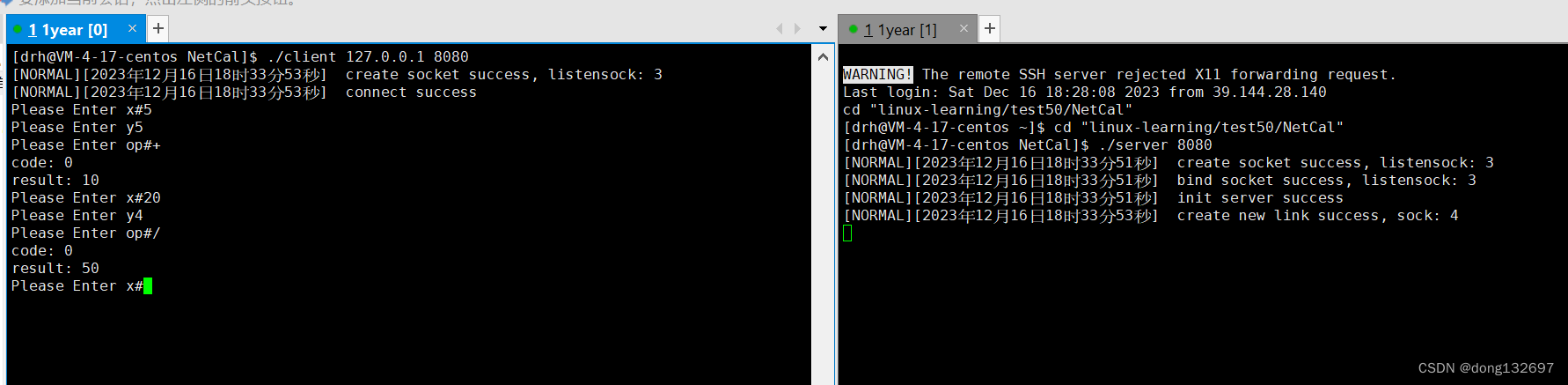
但是我们的服务器还存在bug,当我们将客户端退出后,服务器也出错并且退出了,这是肯定不行的。这是因为当我们将客户端退出后,此时客户端就断开连接并且不会向sock套接字中写入数据了,并且也不会读取数据了,而在CalServer服务器中还会调用Recv函数从套接字文件中读取数据,因为此时套接字文件的写端客户端已经关闭了,所以Recv会读到空字符串并且返回给服务器,然后服务器将空字符串解析出来计算结果,此时虽然没有解析出来Request对象,但是Request对象的x_和y_都为随机值,所以也会计算出来一个结果,然后将这个结果写入到套接字中,但是这一步就会出错,因为此时套接字文件的读端客户端已经关闭了,而服务器还向这个套接字文件中写入数据就会产生SIGPIPE信号了,即操作系统不允许这样的情况出现,所以服务器就出错了。
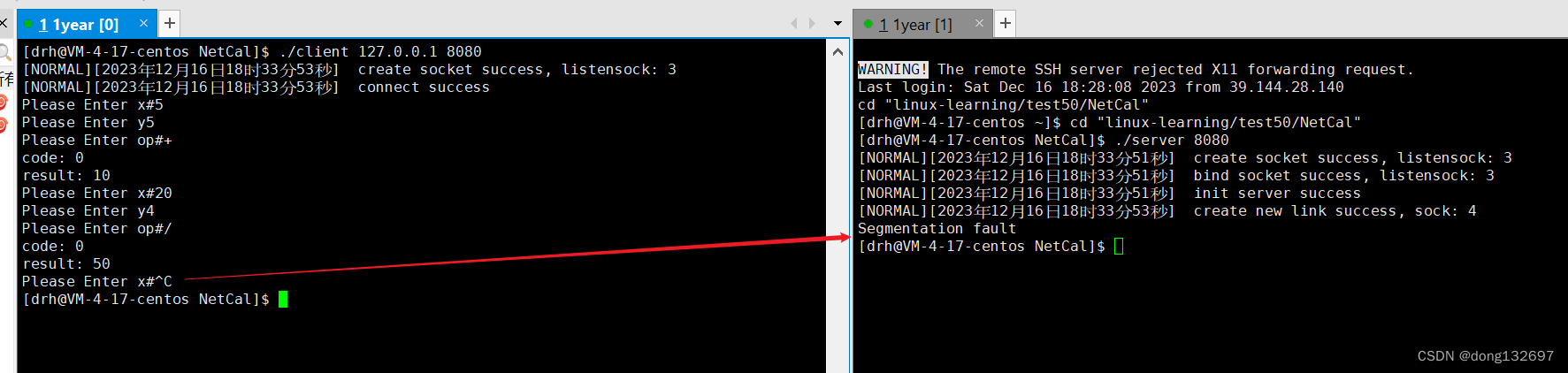
下面我们来解决这个问题,我们先在服务器中判断从Recv函数中是否读取到了数据,如果读取到了数据就向下执行计算的操作,如果没有读取到数据就不再进行数据读取。因为此时客户端已经退出了,所以将服务器的处理请求的线程也退出。然后我们看到此时服务器就不会出现错误了。
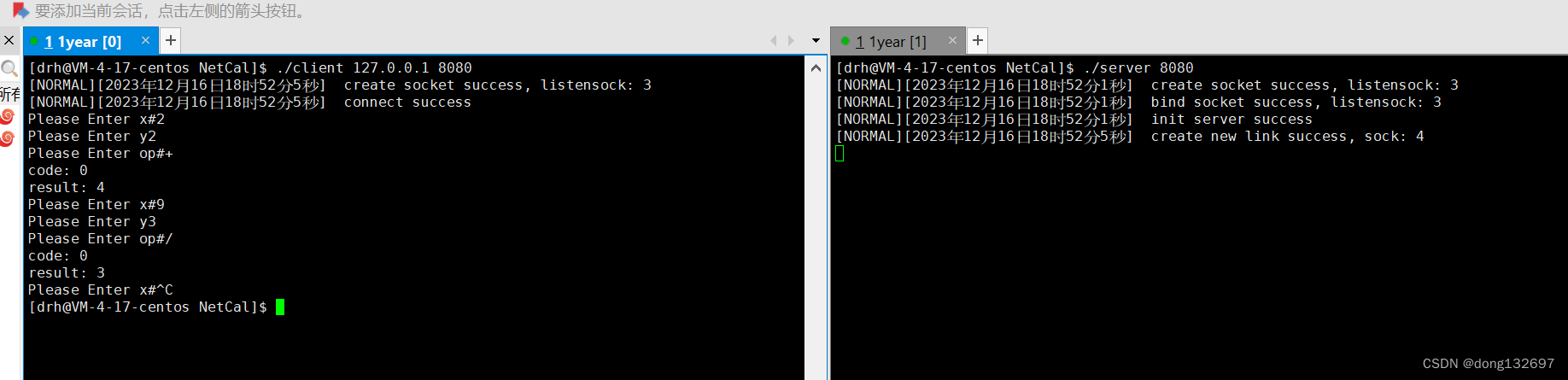
但是我们上述还没有彻底解决问题,因为以后可能会出现这样的情况,当服务器想要给客户端send返回数据时,而此时客户端退出了,那么服务器就会产生非法写入的问题,即文件的读端已经关闭,写端还要写入数据那么就会发生非法写入的问题。所以我们一般都要让服务器忽略SIGPIPE信号,这样当产生上面的情况时,服务器并不会崩溃。这样的情况是我们在写服务器时经常遇到的情况,所以需要特别注意。
我们的程序还会存在一个问题,即我们不能保证Recv函数每次读取的就是一条完整的计算式字符串。因为TCP通信是面向字节流的,即什么样的字符串组合都有可能被读取到。例如读取到" 1234 + 5678 / 334 * "这样的字符串,这样的字符串在进行反序列化时就会出现错误。所以我们的Recv函数中并不能保证每次读取的都是一个完整完善的请求。
下面是面向字节流通信,send等系统调用接口其实就是将buffer里面的数据拷贝到客户端的发送缓存区中,然后由发送缓冲区来将数据发送到网络中。在服务器中有一个接收缓冲区,该缓冲区中存放的是服务器从网络中读取的数据,recv等系统调用接口其实就是将接收缓冲区里面的数据拷贝到服务器的buffer中。发送缓冲区和接收缓冲区是面向字节流通信的,即通信的数据并不是每次都是一个请求,有可能客户端发送了很多个请求,然后发送缓冲区等满了之后才发送,读取缓冲区也并不是每次读取一个请求,而是读取一大串字节流数据。所以我们就不能保证读取时每次都读取到一个完善完整的请求。所以我们需要对协议进行进一步的定制。
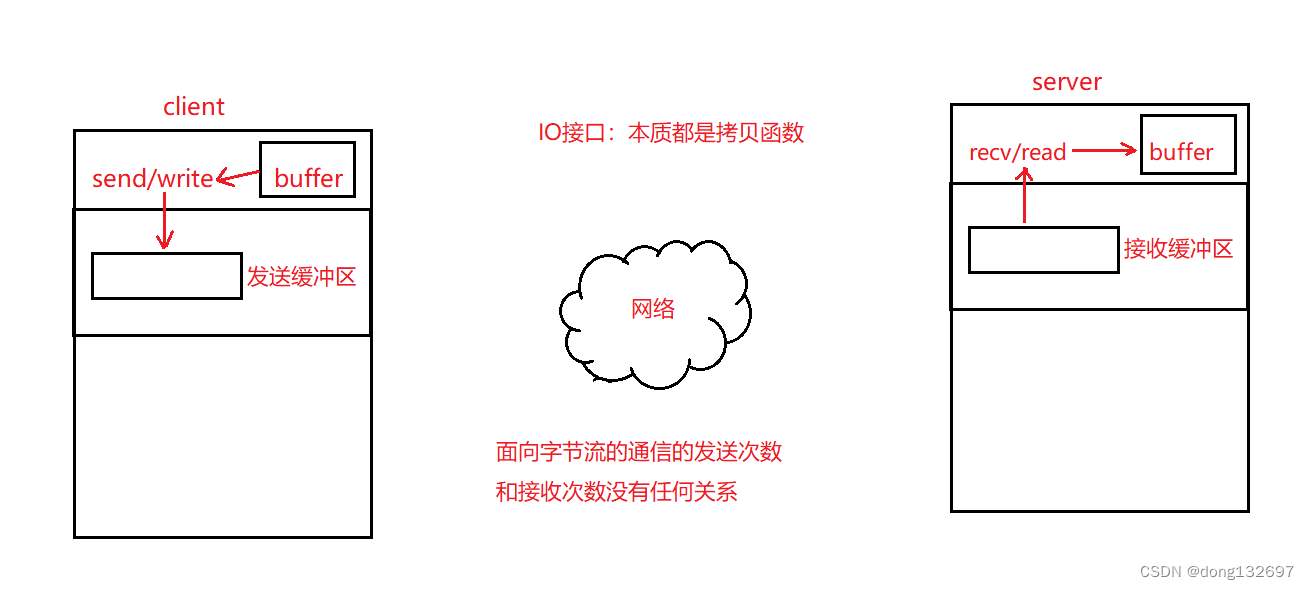
我们首先需要在客户端发送的序列化好的数据中做改动,即不能让客户端只发送计算式组成的字符串,应该在这个字符串的前面和后面加一些分隔符来区分这个计算式字符串,然后在前面加上计算式字符串的长度,这样来表示一次请求,这样进行封装的话可以更好的区分客户端发来的一个请求。

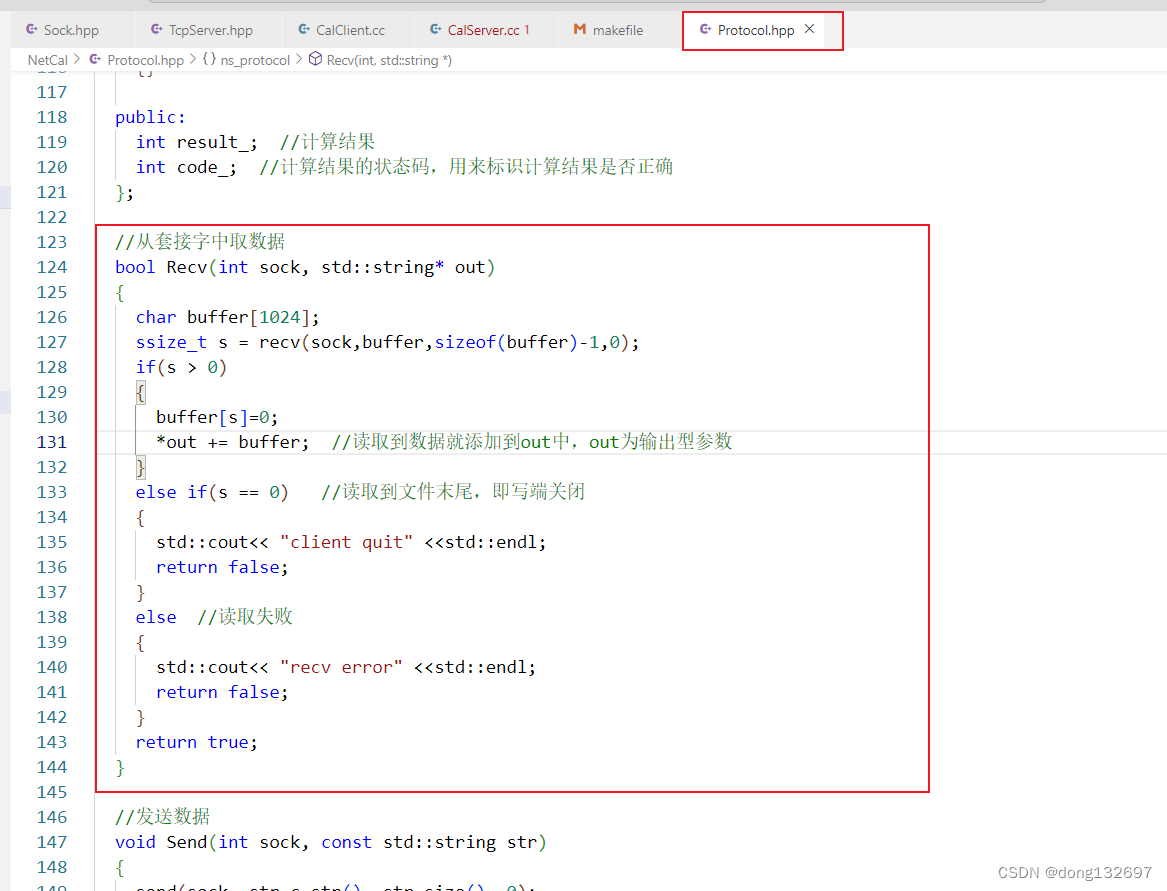
然后我们改变Recv函数,判断Recv函数调用recv系统调用的执行结果,如果读取到了数据就返回true表示这次读取到了数据,如果没有读取到数据或者写端已经关闭就返回false,表示这次没有读取到数据。如果读取到了数据就会追加到输出型参数out中。即Recv函数就用来处理读取数据和对写端进行判断,如果文件中还有数据并且写端没有关闭,那么就读取数据并且将数据追加到out中然后返回true,如果写端关闭或者读取失败就返回false。
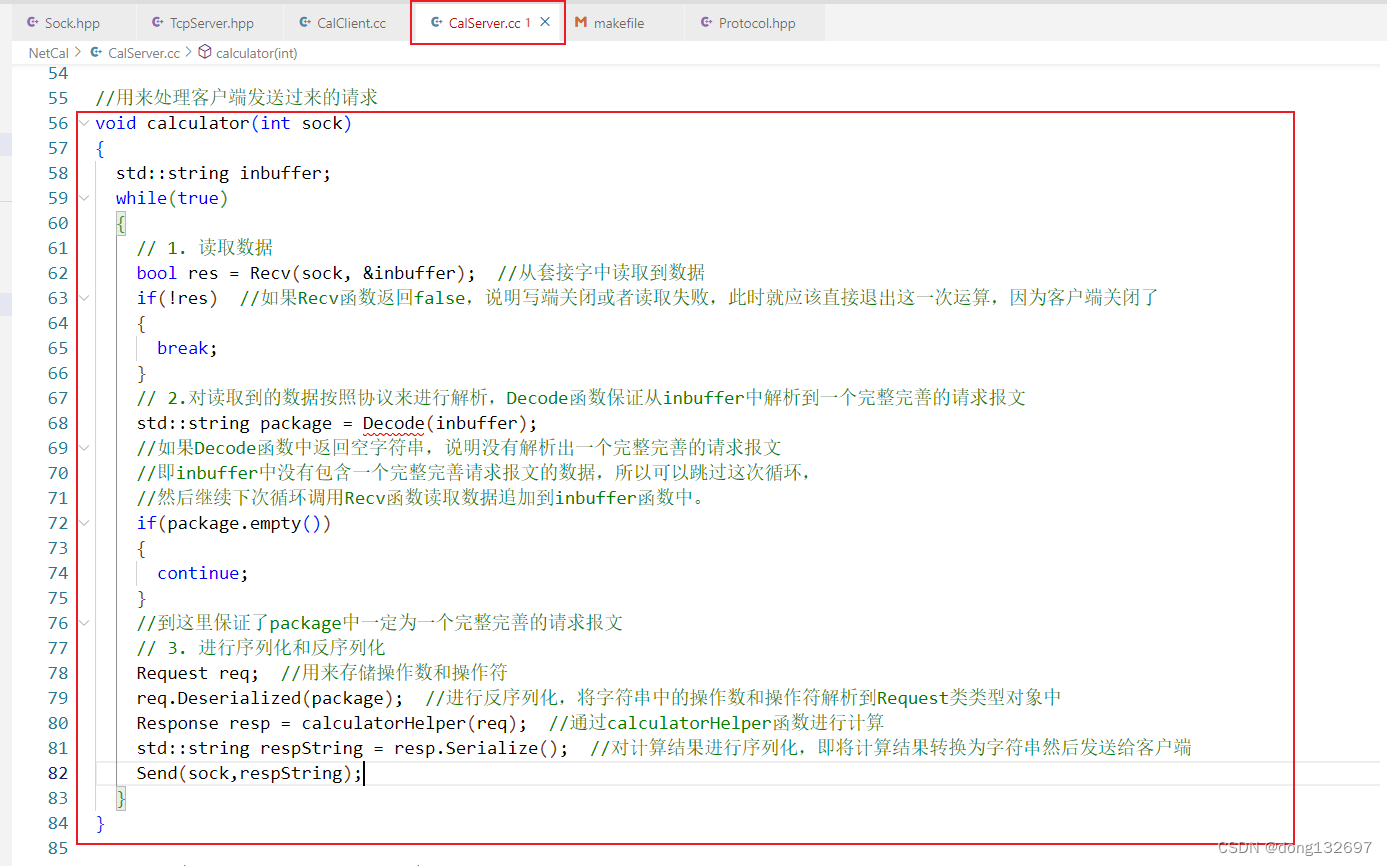
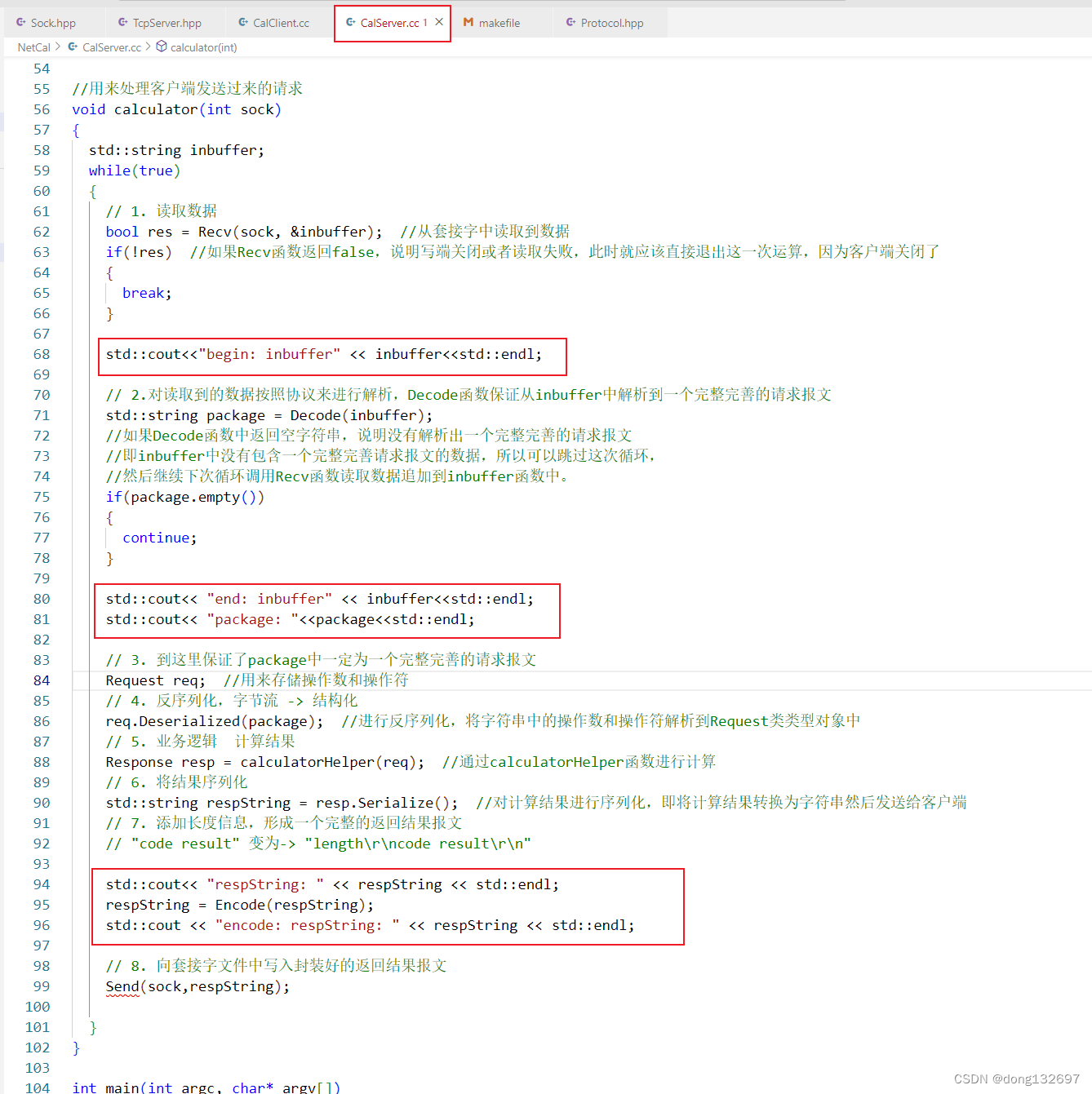
然后我们在CalServer服务器的处理请求的calculator函数中先调用Recv函数进行读取数据,如果从套接字文件中读取数据都失败了,那么说明客户端已经关闭了,所以服务器就可以直接退出这一次处理函数了。如果Recv函数读取到了数据,那么就调用Decode函数来从inbuffer读取的数据中解析一个完整完善的请求报文,如果没有解析出来就说明inbuffer中没有包含完整完善请求报文的数据,那么可以继续从套接字文件中进行数据读取。如果Decode函数返回的package不为空,那么就说明package中此时已经有且仅有一个完整完善的请求报文,然后下面就可以对这个请求报文进行处理了。
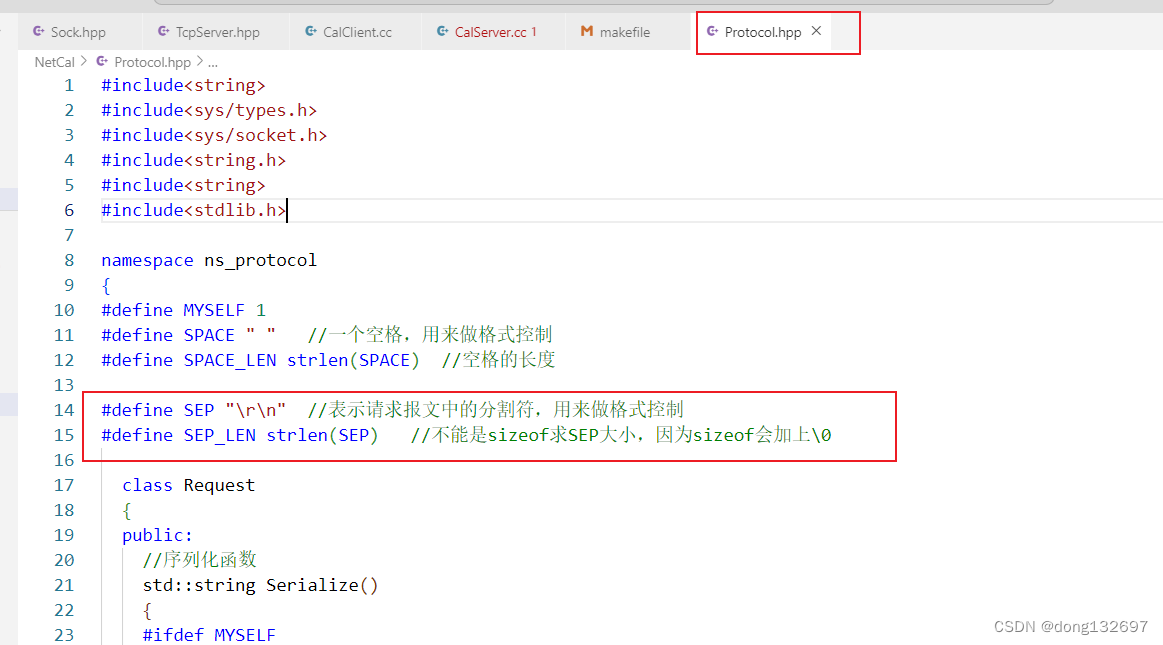
然后我们来实现Decode函数,我们控制Decode函数只有分析到一个完整完善的请求报文时才进行数据返回,如果没有分享到完整完善的报文,那么就返回空字符串。
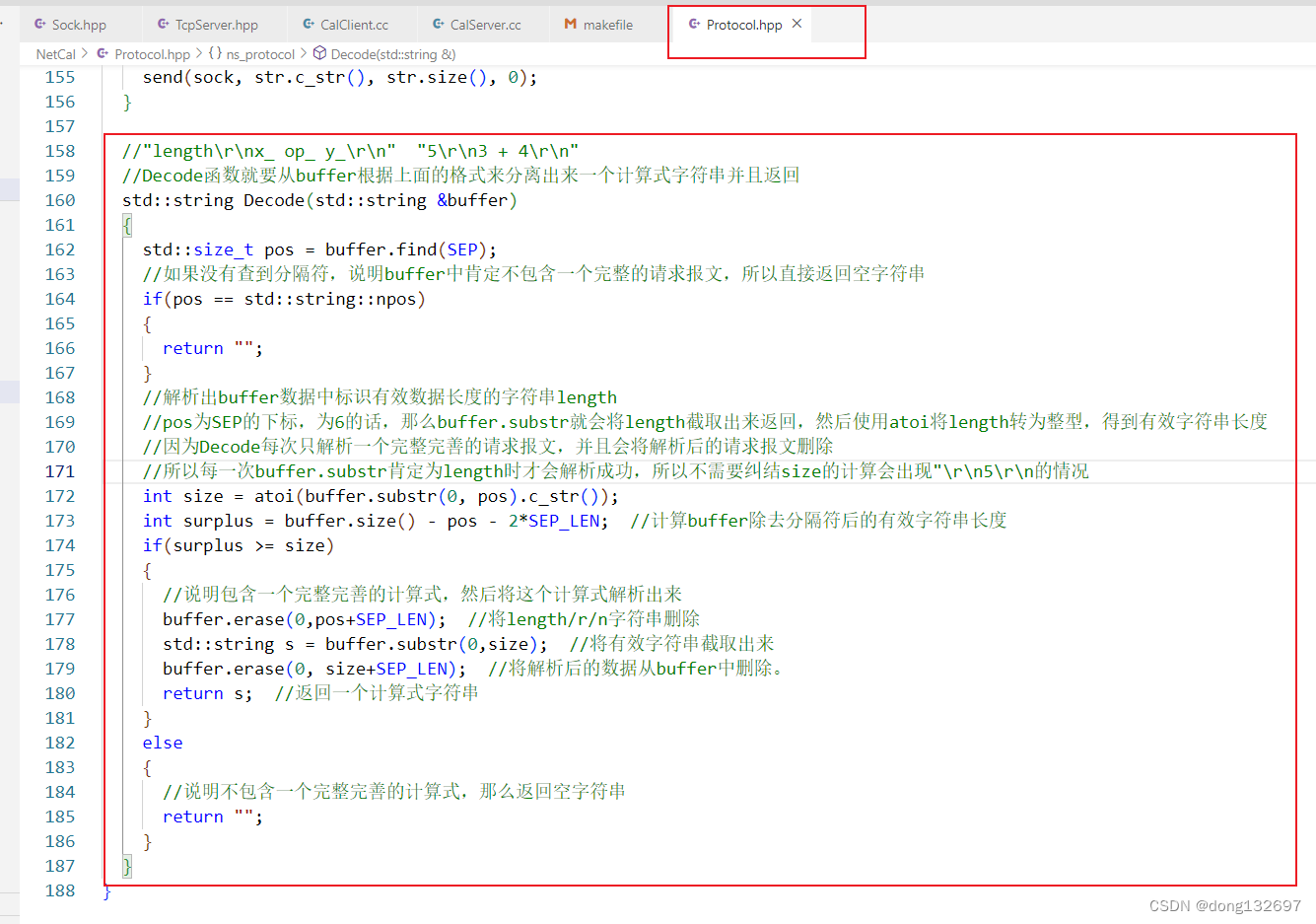
这样我们就保证了服务器获取请求报文并进行计算时不会出现问题,但是当服务器返回处理好的结果时,我们也需要将这个结果进行序列化,然后将序列化好的字符串调用Encode函数进行封装,Encode会返回一个完整的返回报文。然后再调用Send函数将这个完整完善的返回报文写到套接字文件中。
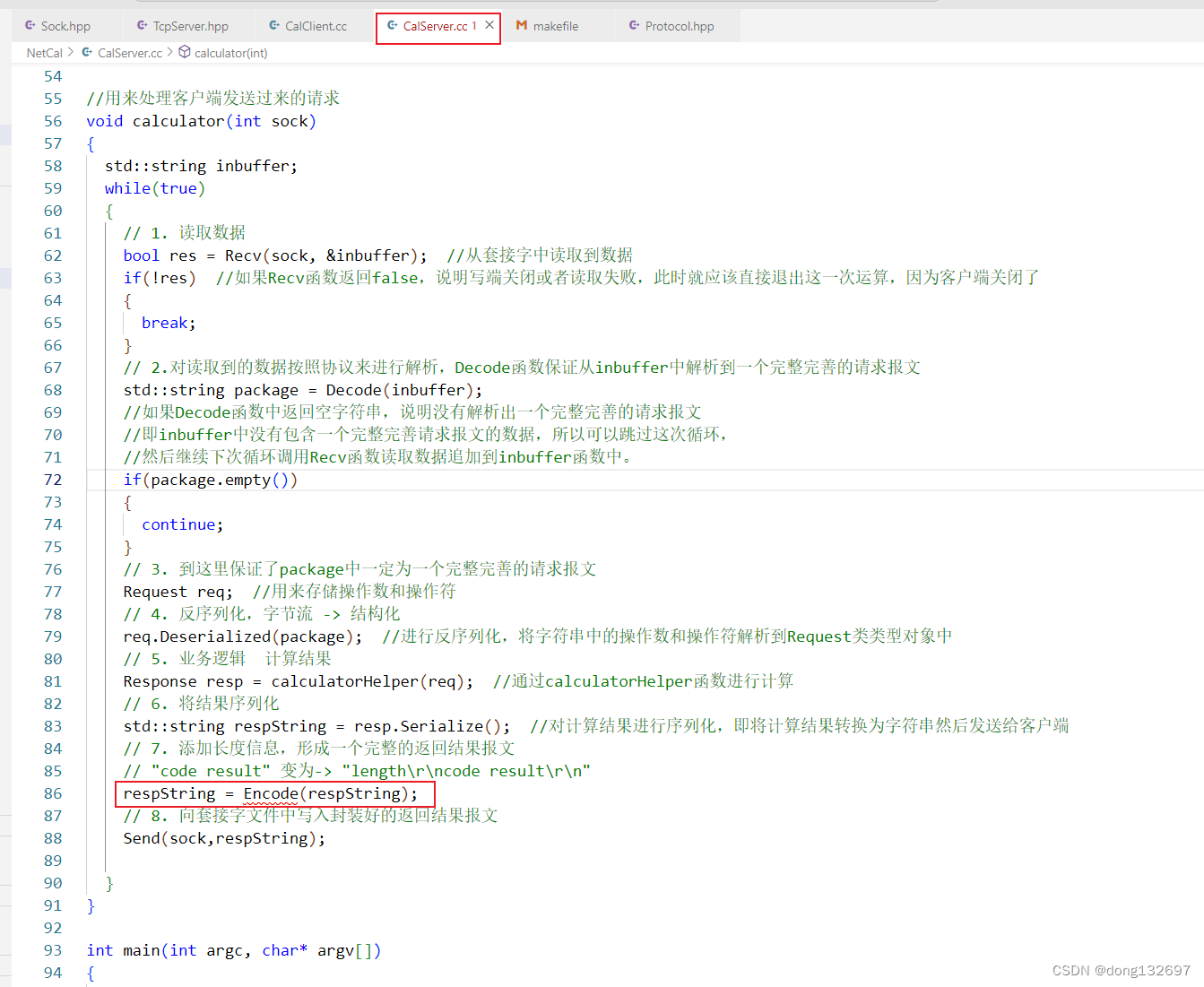
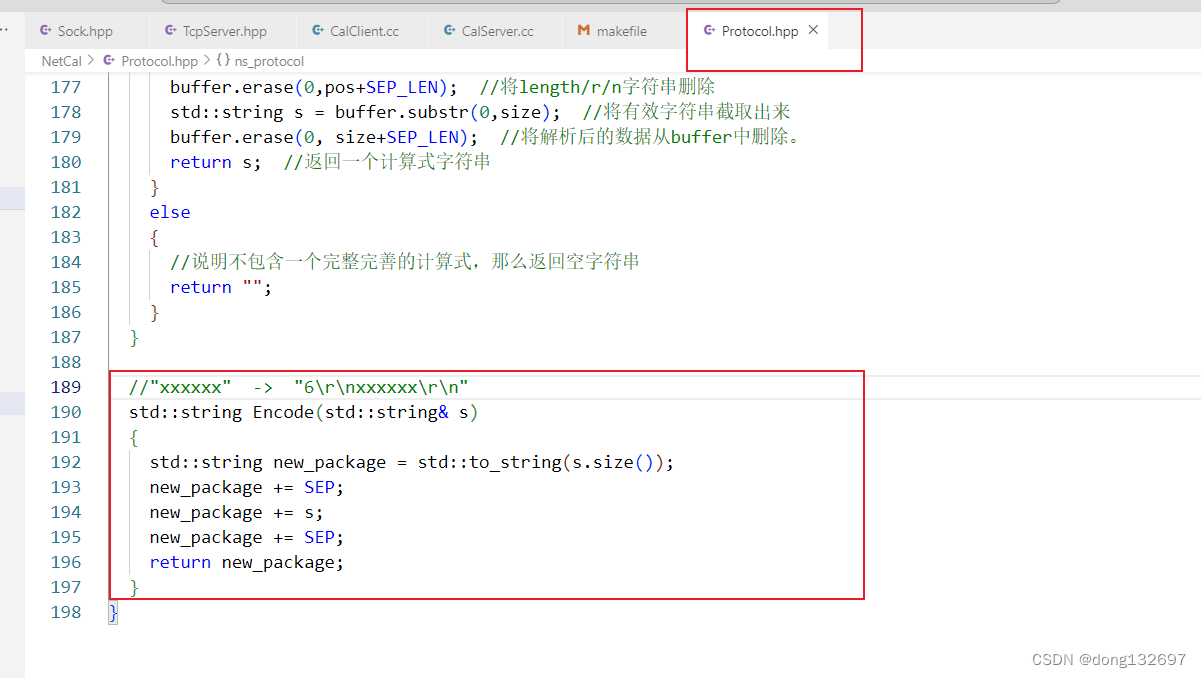
下面我们来实现Encode函数,Encode函数就是将有效字符串的前面加上长度信息,然后通过SEP分隔符来将有效字符串分割开。需要注意的是请求报文和返回报文都可以使用Decode函数来进行解析有效字符串,都可以使用Encode函数来进行封装有效字符串。
下面我们再来将客户端发送请求报文和接收返回报文的处理也进行修改。其中quit变量用来控制客户端是否关闭,当服务器关闭时,客户端读取返回数据就会失败,然后改变quit为true,那么就不会进入下一次循环来让用户输入计算式了,即客户端就关闭了。
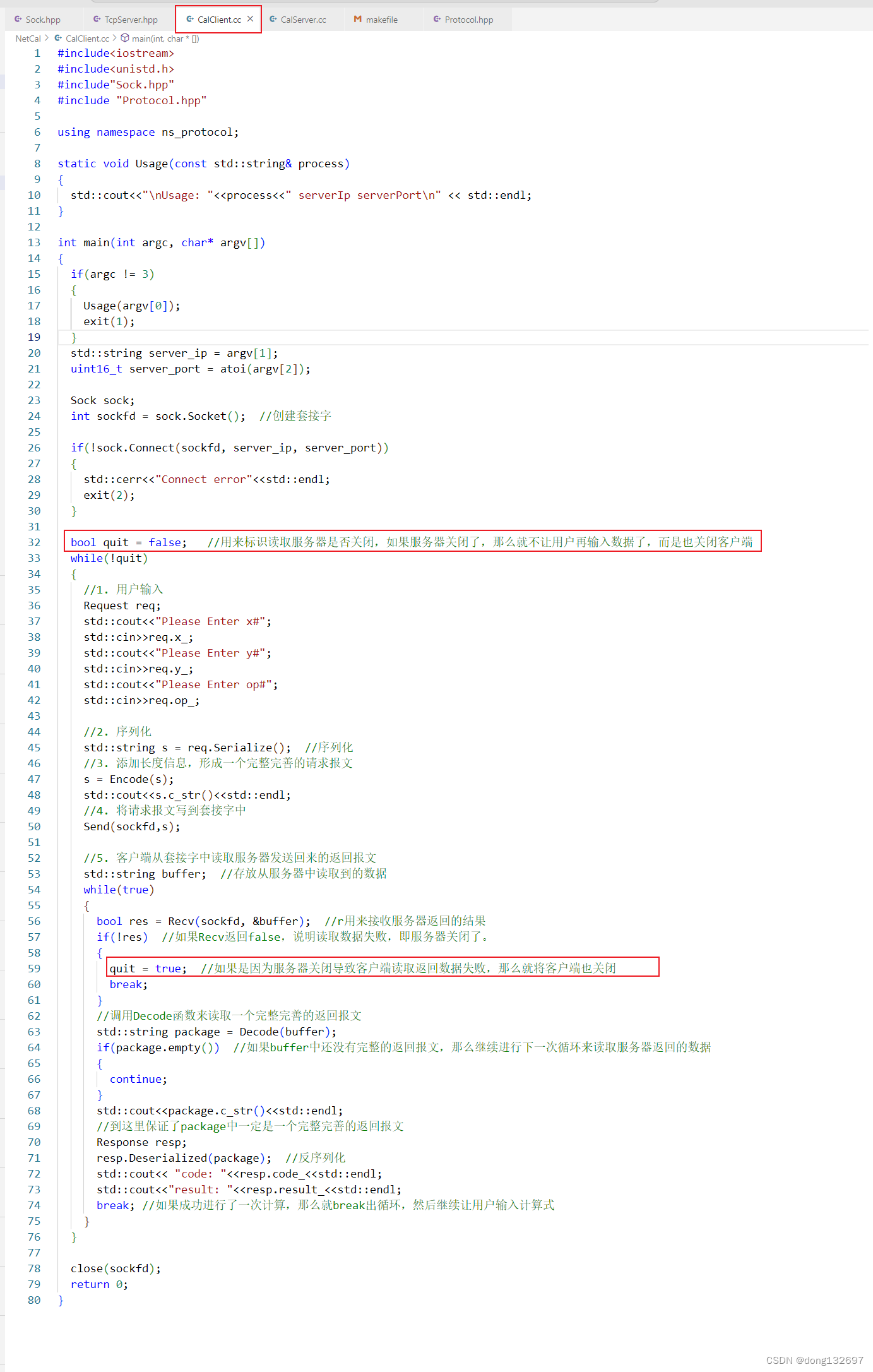
经过测试我们看到客户端和服务器可以正常运行并且进行通信。
下面我们在服务器中打印出来封装前和封装后,解析前和解析后的数据来进行观察。
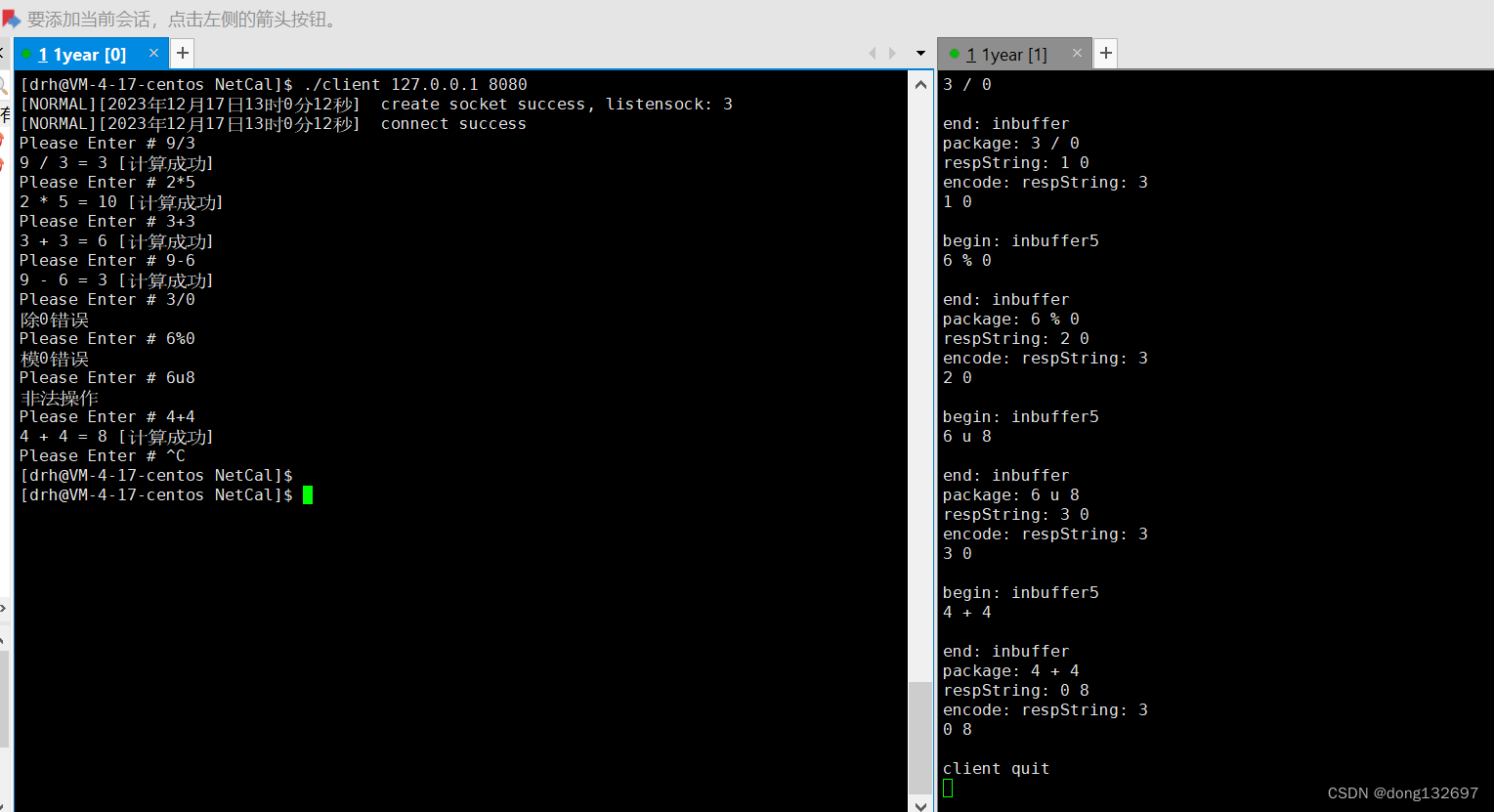
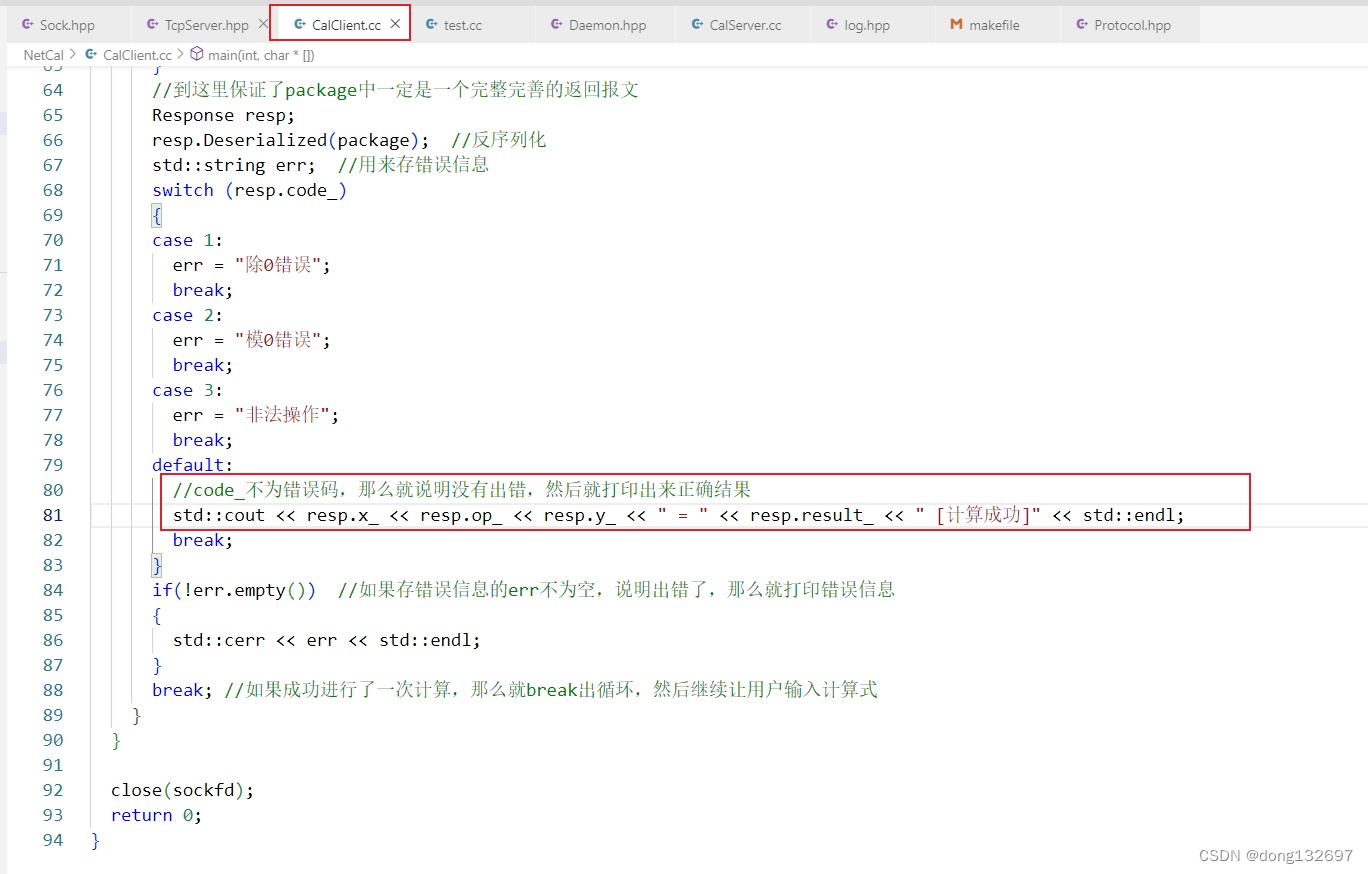
然后我们在客户端中将用户输入的格式改变,然后再判断服务器返回的结果中的code_错误码来打印出对应的错误信息,如果没有错误就打印出计算的结果。

通过测试我们就可以看到客户端和服务器更加完善了。
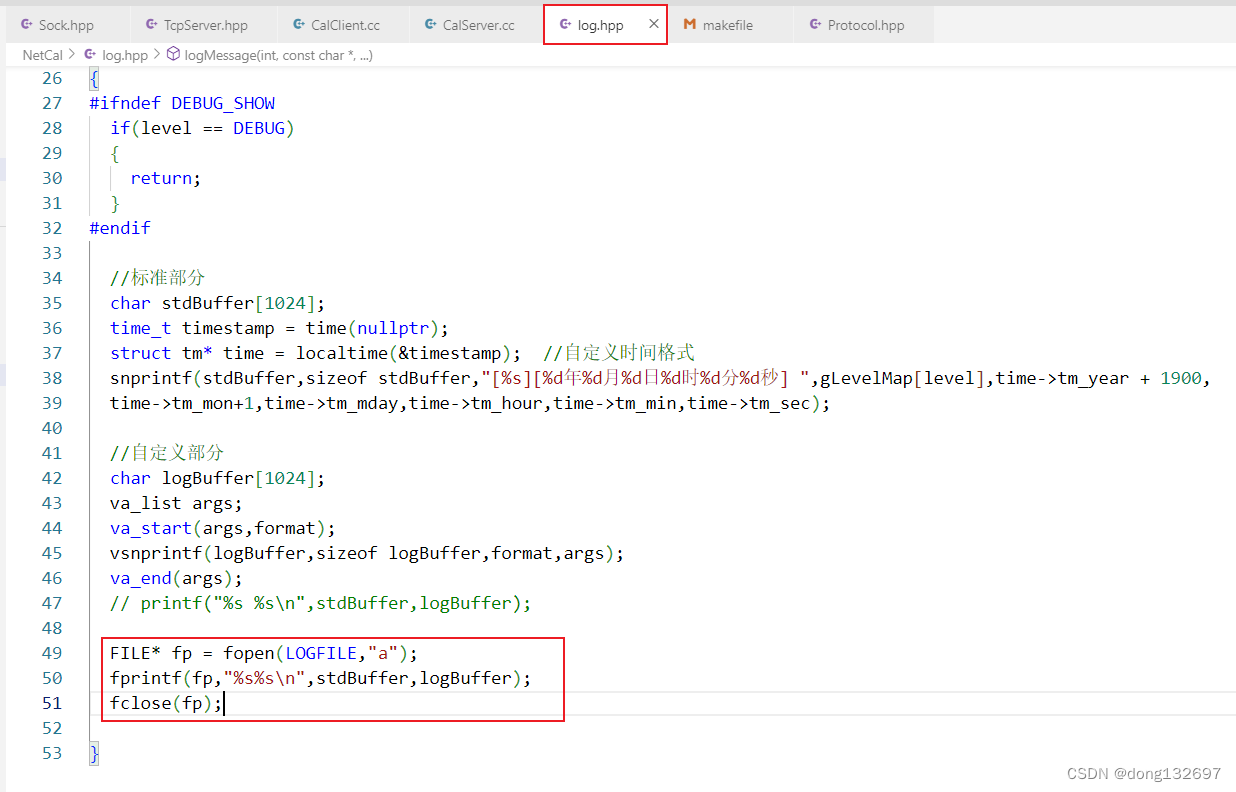
下面我们再来将服务器输出到显示器中的信息改为输出到日志文件中。我们看到服务器的一些输出信息都在日志文件中了。
3.守护进程
现在我们的服务器进程为一个前台进程,即该进程和终端关联,当运行这个进程时,在命令行输入其它命令时是无效的。但是这样的前台进程当我们退出这一次登录时,这个进程也会关闭,那么我们的服务器进程运行时也会被退出,这肯定是不行的,因为服务器进程只要运行了就不能再退出的。所以此时我们就需要将服务器进程变为一个守护进程。
1.前台进程:和终端进程关联的进程。
2. 任何xshell登录,只允许一个前台进程和多个后台进程。
3. 进程除了有自己的pid,ppid,还有一个组ID。
4. 在命令行中,同时用管道启动多个进程,这多个进程是兄弟关系,父进程都是bash->可以用匿名管道来进行通信。
5. 而同时被创建的多个进程可以成为一个进程组的概念,这个进程组的组长一般是第一个进程。
6. 任何一次登录的用户,需要有多个进程组来给这个用户提供服务的(bash),用户自己也可以启动很多进程或者进程组,我们把给用户提供服务的进程或者用户自己启动的所有的进程或者进程组整体属于一个叫做会话的机制中。
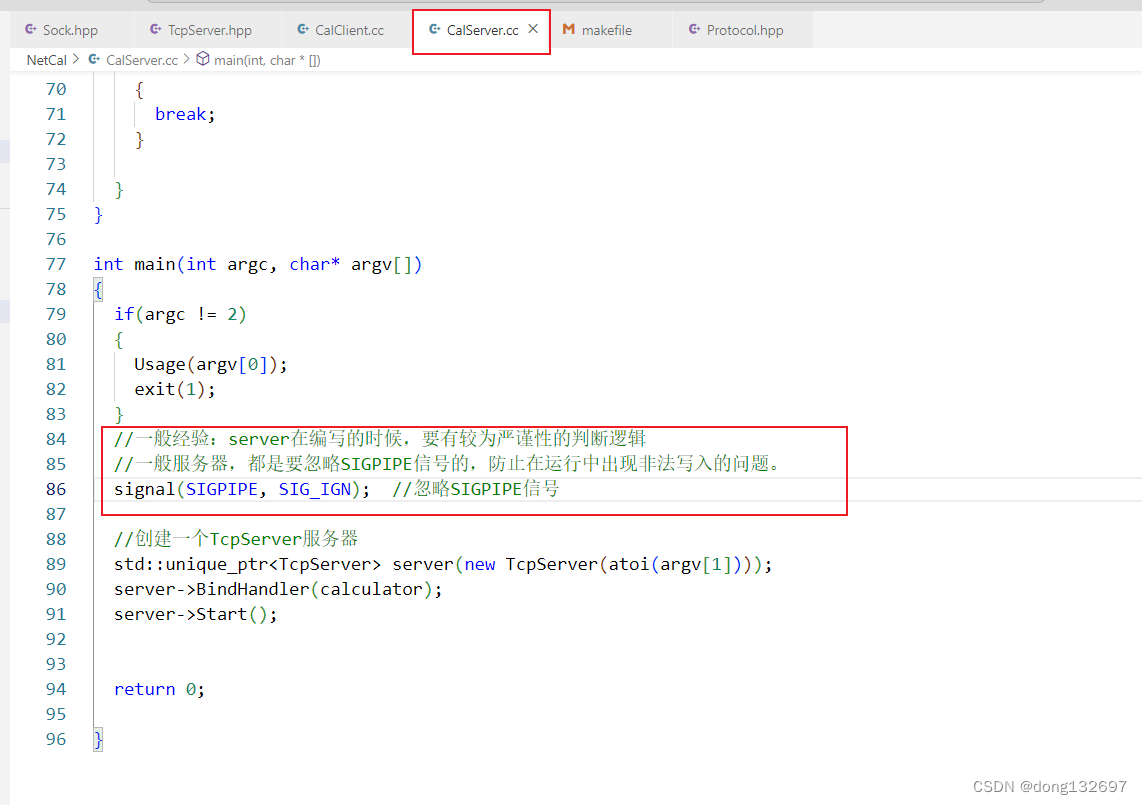
7. 那么我们在bash命令行中启动的服务器进程也属于这个会话,如果我们将这次登录退出,那么这个会话中的所有进程都会被退出,即服务器进程也会被退出。所以我们需要将服务器进程自成一个会话,变为守护进程,那么当我们退出这一次登录时,自成一个会话的服务器进程就不会退出了,这就是守护进程。
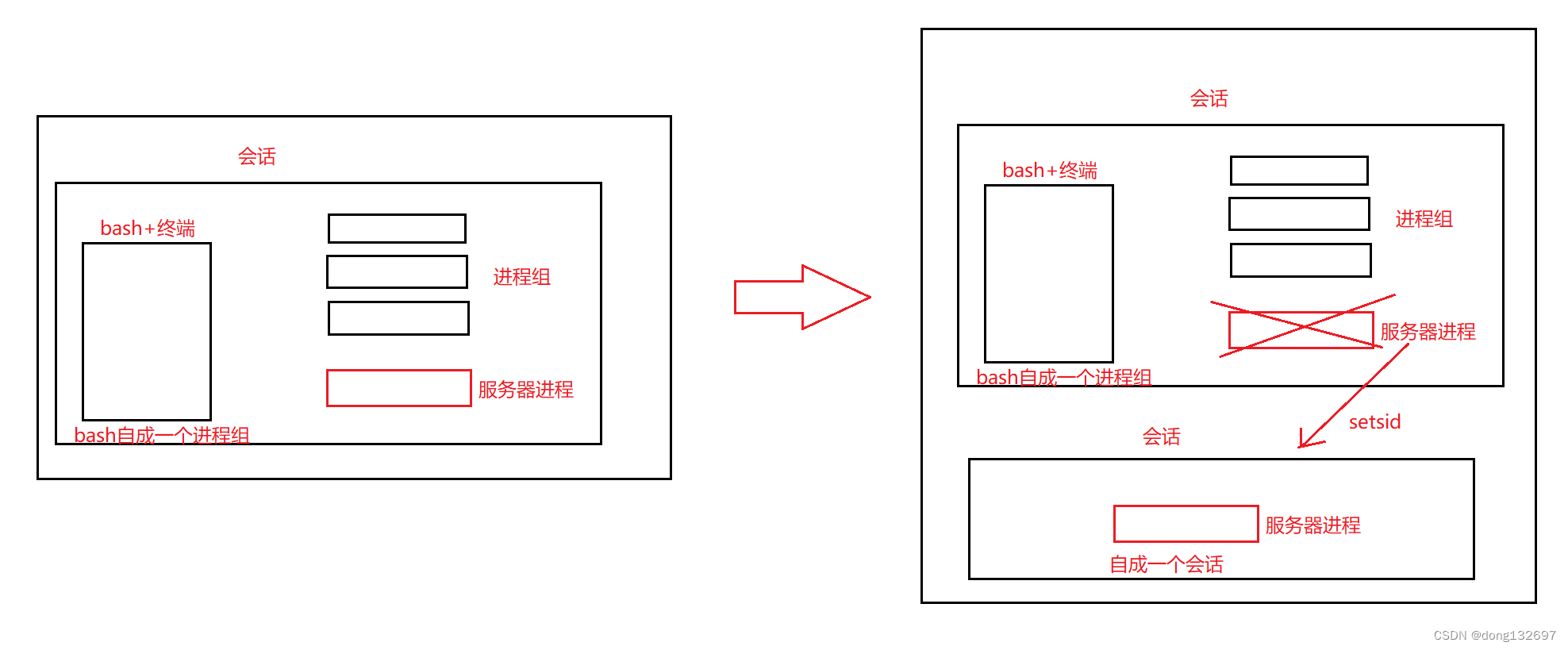
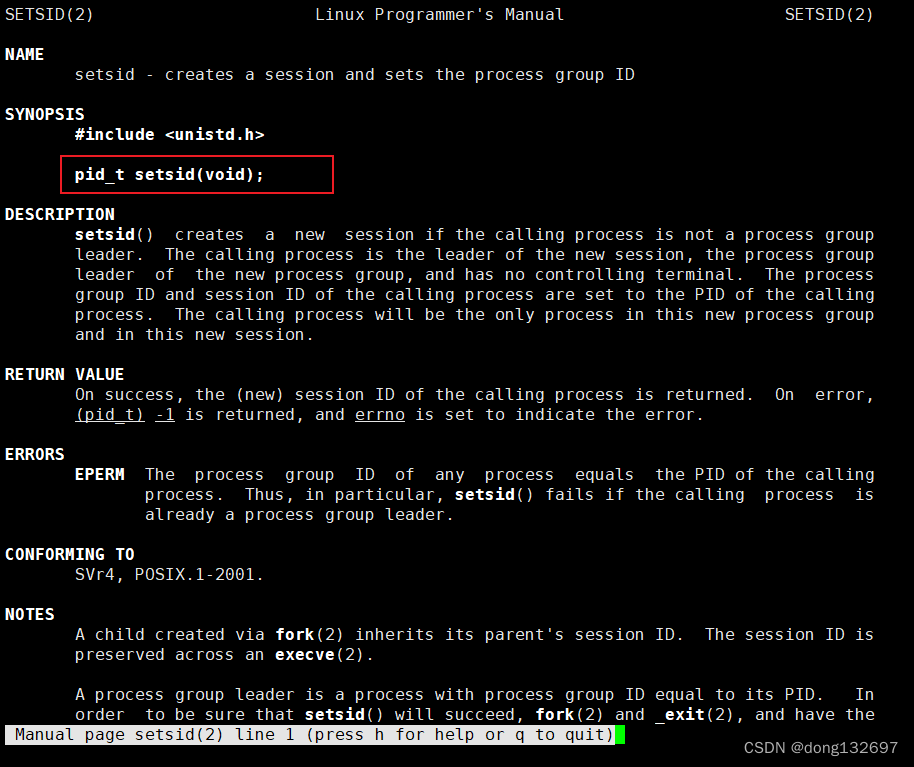
但是setsid要成功被调用,必须保证当前进程不是进程组的组织,所以我们就需要先使用fork让服务器进程不为第一个进程。下面我们来使用代码实现将服务器进程变为守护进程。
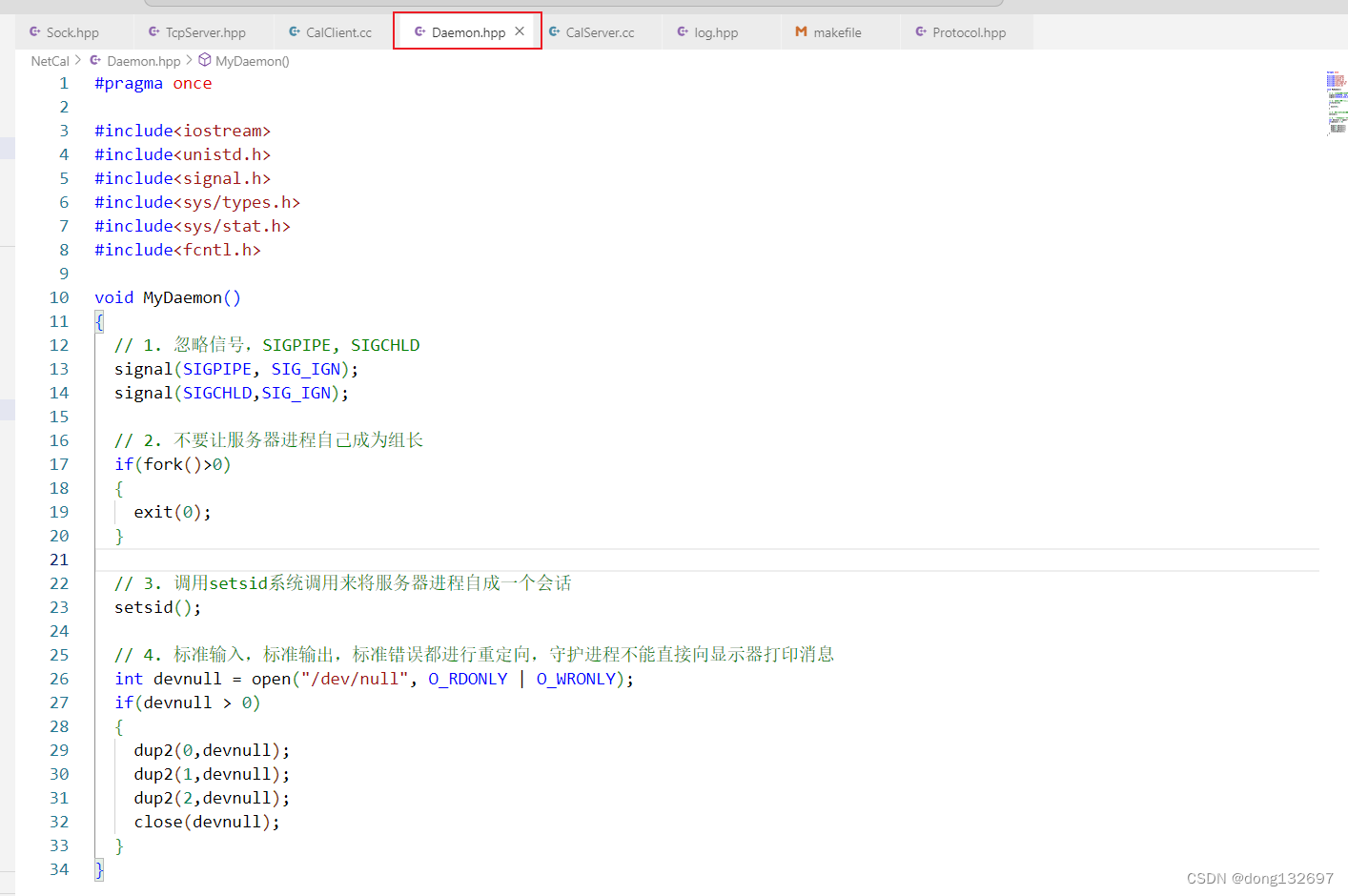
然后我们在启动CalServer服务器时先将这个进程变为守护者进程。
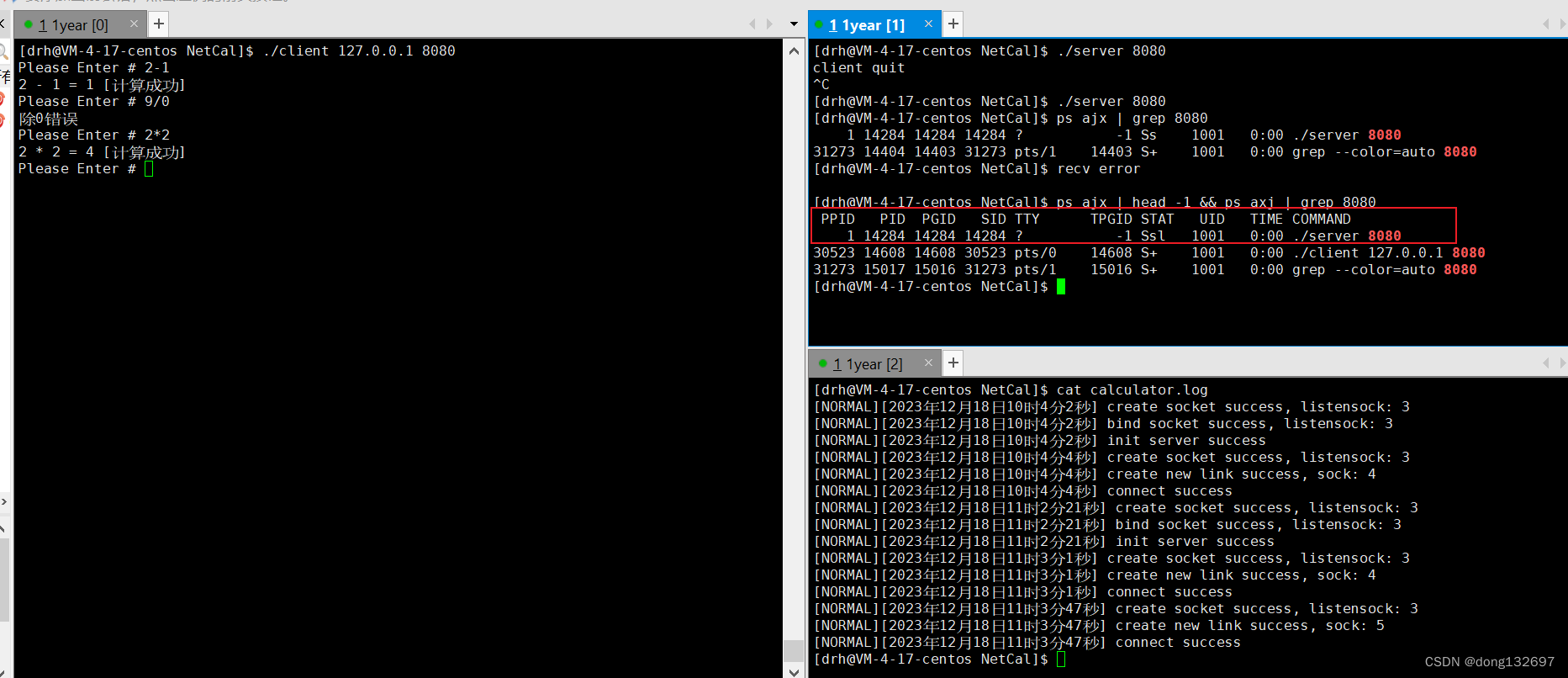
我们看到此时服务器进程server的父进程的pid为1,此时server进程已经自成一个会话了,我们退出xshell这次登录然后再次登录时,这个server进程还在运行,因为我们没有关闭server进程的会话,所以server进程就可以一直运行了。此时我们想要关闭server进程就只能通过kill命令和pid来将server进程关闭了。守护进程本质是孤儿进程的一种,它与孤儿进程不同的就是守护进程自成一个会话。
4.json格式
上面我们用自己实现的协议进行了序列化和反序列化,但是我们自己实现的序列化和反序列化肯定是不完善的,所以我们下面来使用JSON格式。
因为json不是c++自带的类型,所以如果我们想要使用json类型,就需要先下载json库。下面我们来安装jsoncpp库。
sudo yum install jsoncpp-devel
JSON(JavaScript ObjectNotation)是一种轻量级的数据交换格式,常用于在不同系统之间传输和存储数据。它具有以下特点:
- 可读性:JSON使用文本格式表示数据,易于阅读和理解。它采用了类似于JavaScript对象的键值对的形式来组织数据。
- 简洁性:JSON的语法非常简洁,相比于其他数据格式(如XML),它的数据表示更为紧凑,节省了传输和存储空间。
- 支持多种数据类型:JSON支持多种基本数据类型,包括字符串、数字、布尔值、数组、对象和null。这使得JSON非常灵活,可以表示各种类型的数据结构。
- 易于解析和生成:JSON数据可以轻松地由各种编程语言解析和生成。许多编程语言都提供了内置的JSON解析器和生成器,使得处理JSON数据变得简单和方便。
- 跨平台和语言无关:由于JSON是一种通用的数据格式,它不依赖于任何特定的平台或编程语言。这意味着JSON可以在不同的系统和不同的编程语言之间进行数据交换和共享。
- 可扩展性:JSON支持嵌套结构,允许在对象中嵌套其他对象或数组,从而实现复杂的数据结构。这种嵌套结构可以实现数据的层级关系和组织。
- 平台无关的数据交换格式:由于JSON的广泛支持和普及性,它已成为一种通用的数据交换格式。许多Web服务和API都使用JSON作为数据交换的标准格式。
例如下面表示一个包含个人信息的JSON对象。它包括名称、年龄、是否是学生、兴趣爱好和地址等属性。注意JSON中使用双引号表示键和字符串值,使用逗号分隔不同的键值对,使用方括号表示数组,使用花括号表示对象。
{
"name": "John",
"age": 18,
"isStudent": true,
"hobbies": ["runing", "traveling"],
"address": {
"street": "999 Main St",
"city": "hangzhou"
}
}
基本语法:
①.Json 键值对:键值对是 Json 的基本构成。其中,名称即对象的属性名称,必须包含在双引号( " " )中;值即对象对应的属性值;名称和值之间用冒号( : )隔开。
②.Json 值:Json 的值可以是以下几种:字符串、数字( 整型、浮点型 )、布尔值( ture、false )、空值( null )、数组、对象。
③.Json 对象:Json 对象是用大括号( {、} )括起来的一系列 Json 键值对的集合,键值对之间用逗号( , )隔开。
④.Json 数组:Json 数组是用中括号( [、] )括起来的一系列 Json 值的集合,值之间用逗号( , )隔开。
下面我们来使用json数据格式写一个测试程序。
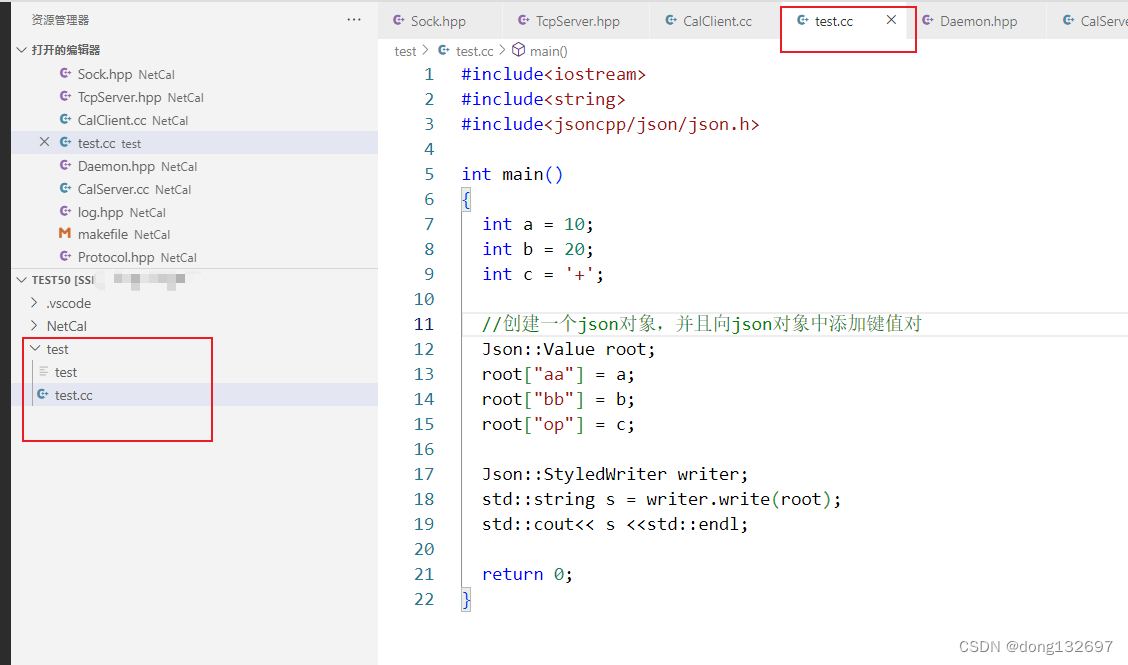
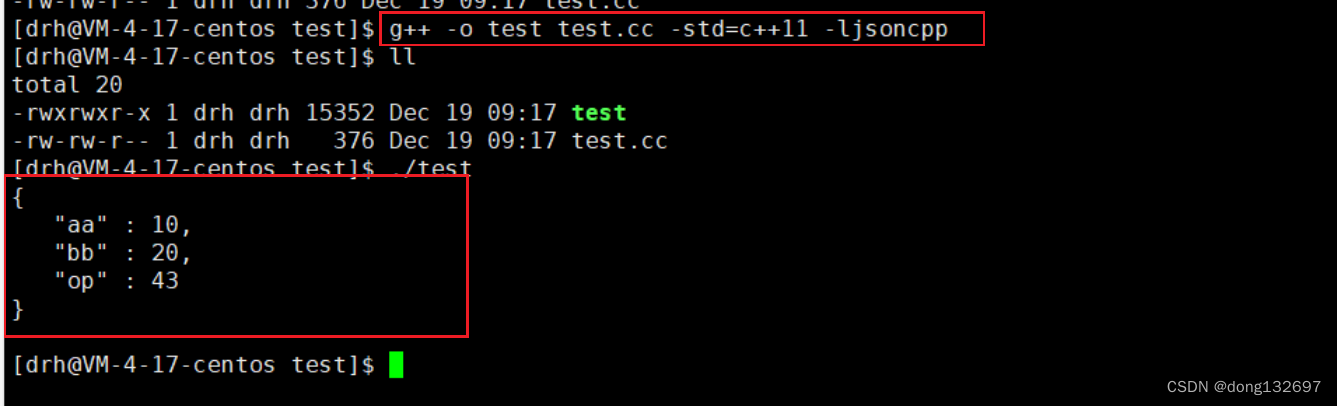
下面为使用json来将数据进行序列化,我们使用了StyleWriter对象的write来将json对象转为字符串,可以看到下面的结果就是序列化之后的json对象。并且我们需要注意,因为我们使用了json库中的方法和变量等,所以我们在编译时需要加上jsoncpp库。
下面我们再使用FastWriter对象的write方法将json对象序列化为字符串,我们看到此时序列化之后的字符串没有了多余的空格和换行,变得更精简了。

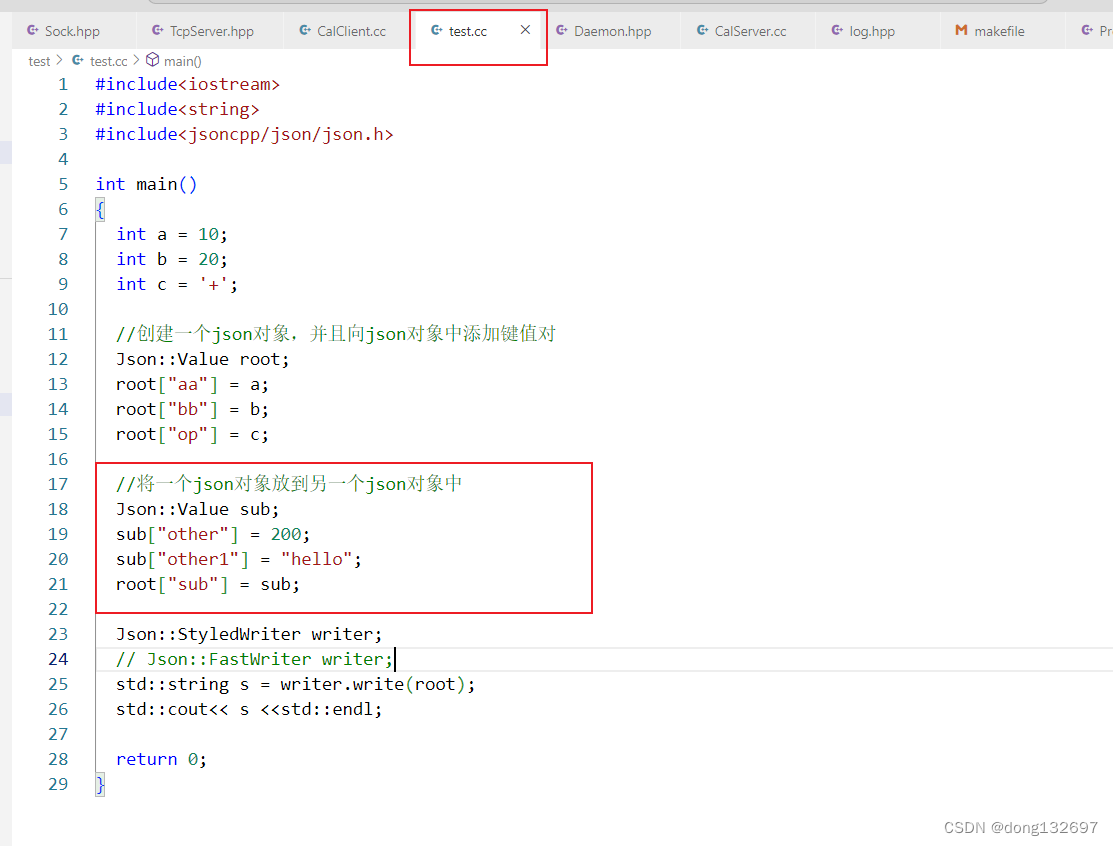
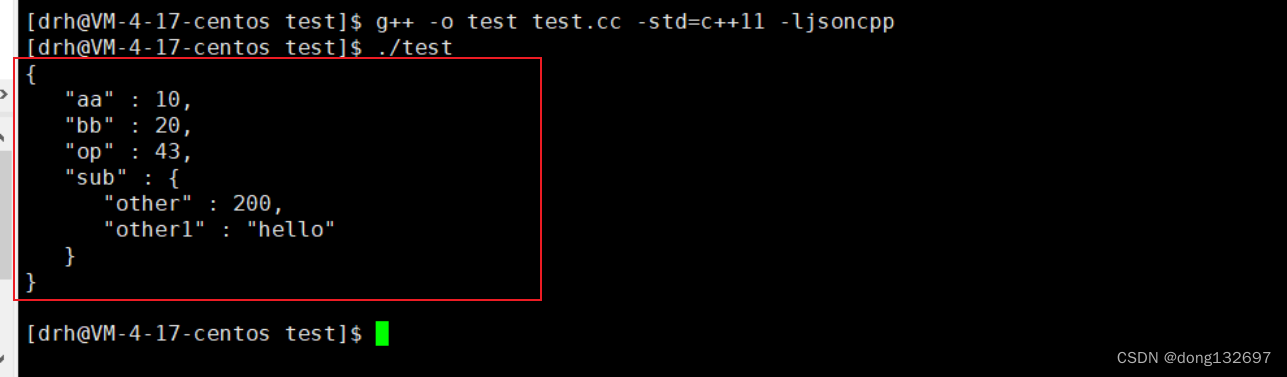
我们还可以把一个json对象放到另一个json对象中。
下面我们就将网络版计算机中的序列化和反序列化的过程使用json库提供的序列化和反序列化方法实现。
json库的头文件在jsoncpp/json文件夹下,所以我们需要将路径都包含清楚。
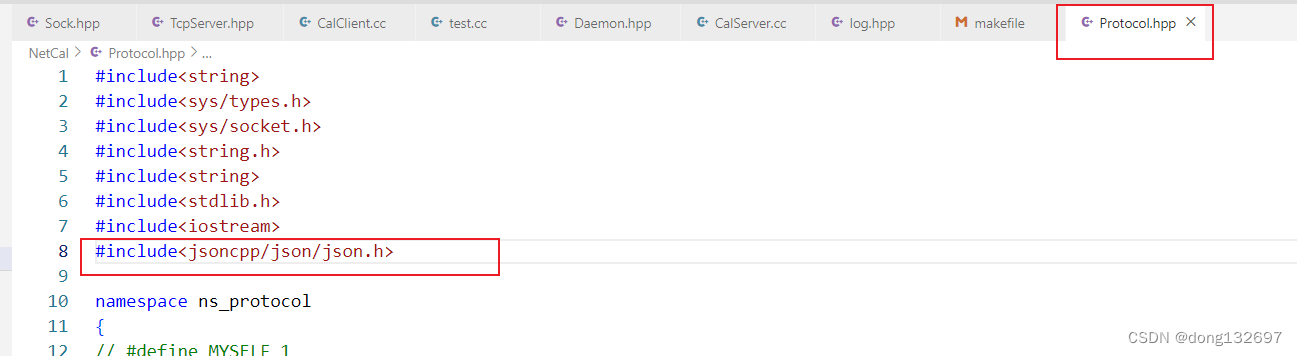
下面我们将Request类的序列化和反序列化函数中使用了json库提供的序列化和反序列化方案,我们看到使用json库提供的方法更简便了。
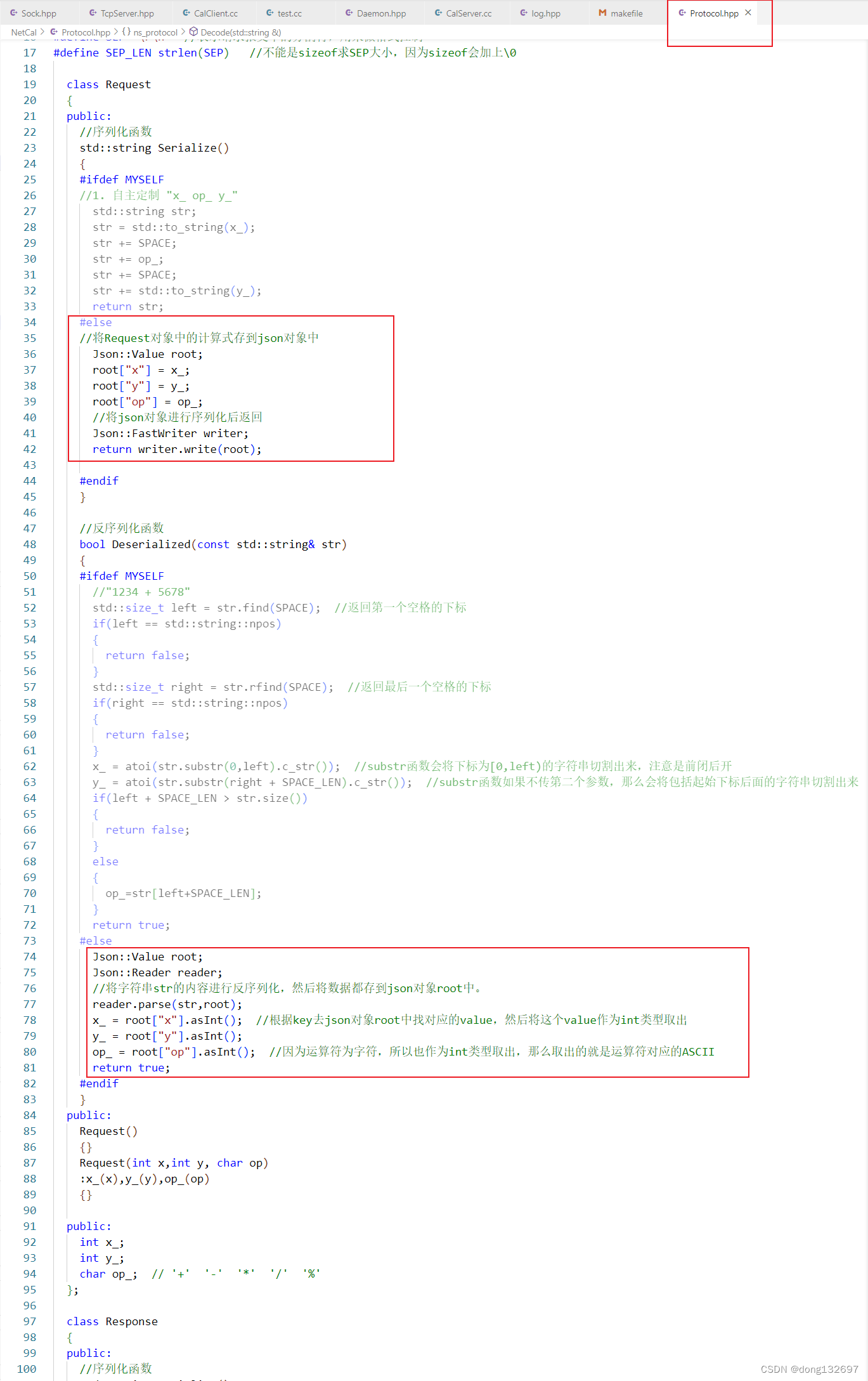
然后我们也将Response类中的序列化和反序列化操作使用json库提供的方法。
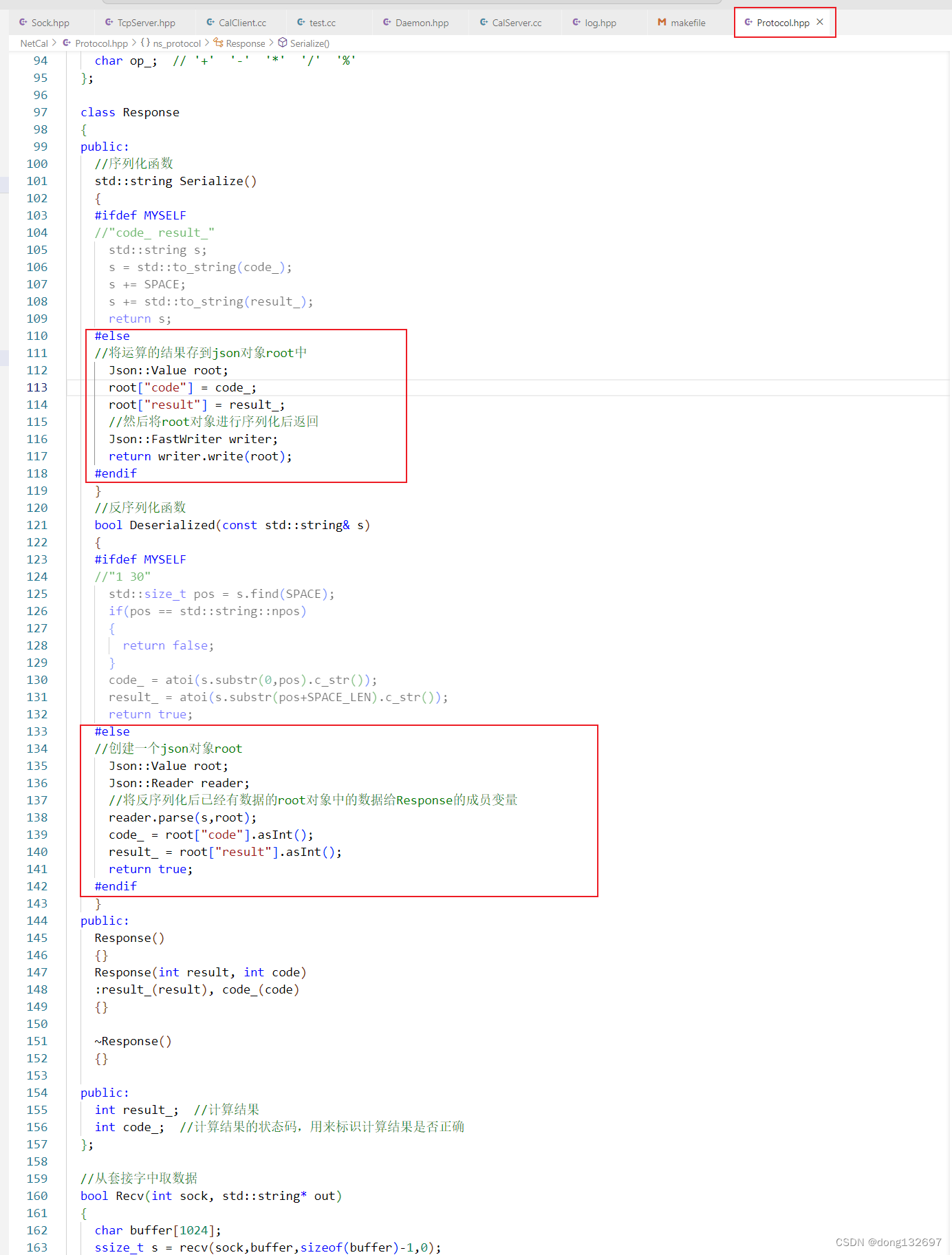
我们看到使用json库题库的序列化和反序列化方案的话,那么在客户端中我们就没有打印出用户输入的计算式。

我们此时可以在协议中做扩展,在Response类中也将计算式的内容存储。那么我们在访问Response类对象时也可以访问到用户输入的计算式了。
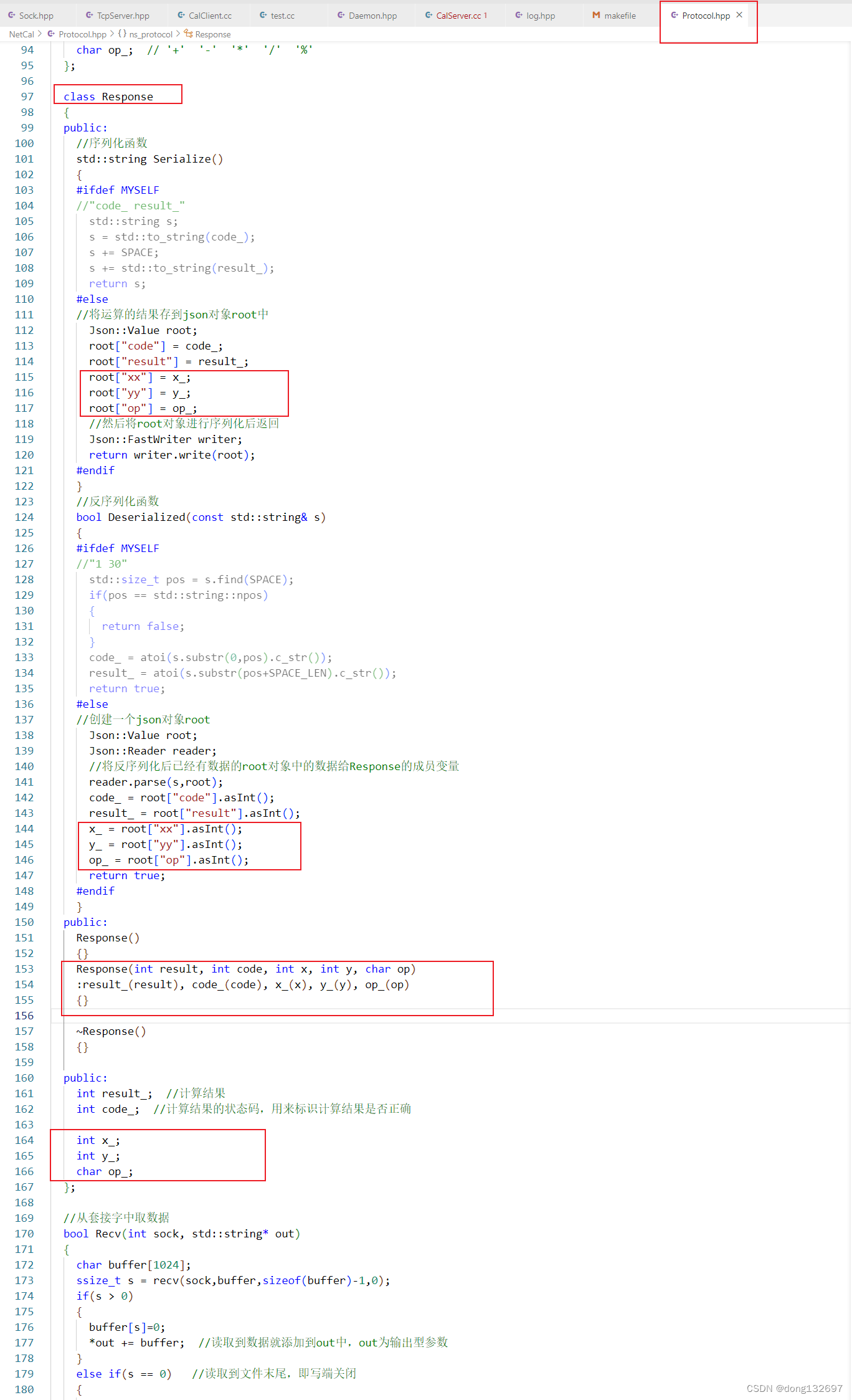
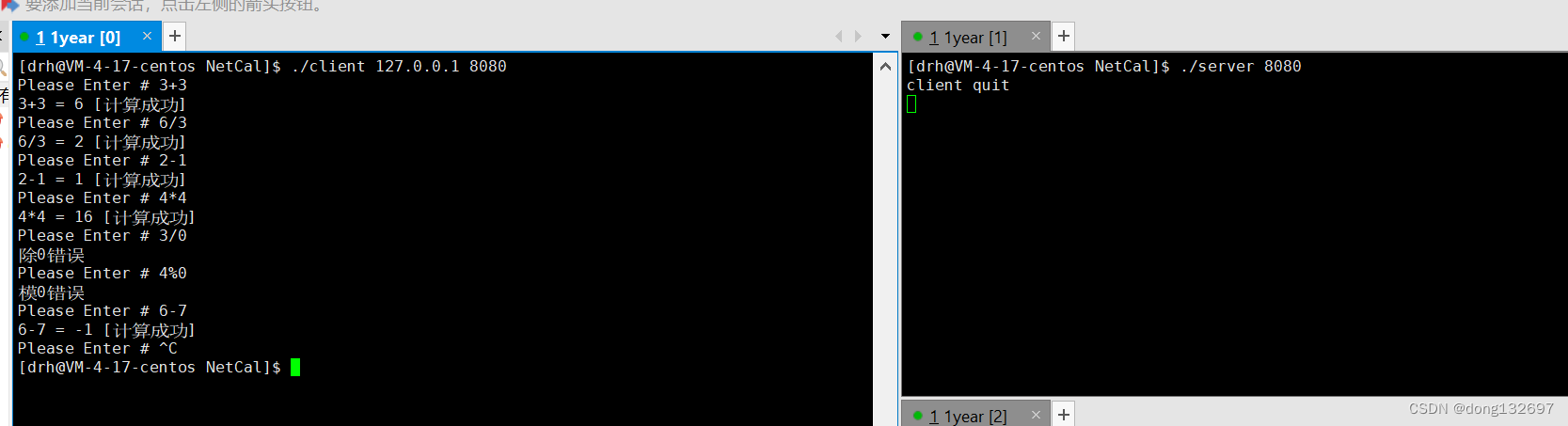
然后我们进行测试就可以看到,用户输入的计算式也被打印出来了。到此我们就简单实现了一个网络版计算器。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 便携式小型气象站-科普知识
- ssm/php/node/python自由教学平台
- 使用ffmpeg+flv.js + websokect播放rtsp格式视频流
- 【MIdjourney】关于图像中人物视角的关键词
- 深度学习小白学习路线规划
- PostGreSQL远程连接
- GVM垃圾收集算法
- 从微信审批表单中拿数据写入MySQL,使用dolphinscheduler定时调度
- 新全国产迅为龙芯 3A6000 处理器板卡
- 基于时空的Ramsar湿地自动淹没映射利用Google Earth Engine