计算机视觉基础(10)——深度学习与图像分类
前言
传统视觉算法采用手工设计特征与浅层模型,而手工设计特征依赖于专业知识,且泛化能力差。深度学习的出现改变了这一状况,为视觉问题提供了端到端的解决方案。在之前的课程中,我们已经学习了图像分类的传统知识。在本节课中,我们将学习到图像分类融合深度学习的方法。
一、视觉算法设计流程的演化
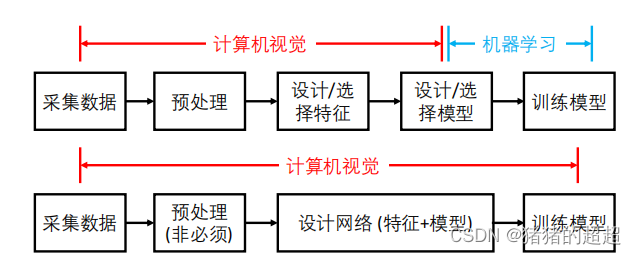
下面是传统视觉算法和深度学习算法的区别:
? 传统视觉算法采用手工设计特征与浅层模型;
? 手工设计特征依赖专业知识(Domain knowledge),且泛化性能差;
? 深度学习的出现改变了这一状况,为视觉问题提供了端到端的解决方案。
接下来,我们以人脸识别任务为例,对传统方法和深度学习方法进行一个比较:
传统方法的思路如下:
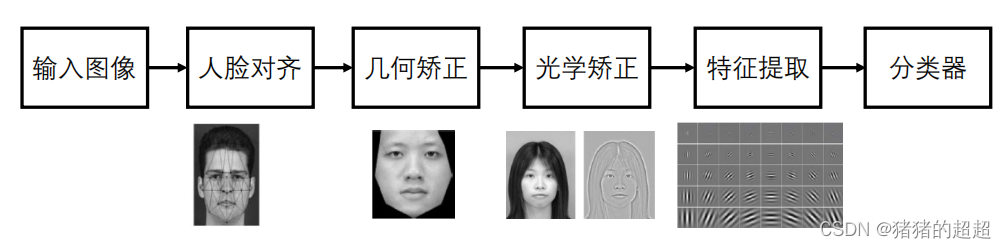
深度学习方法的思路如下:

下面是深度学习方法的一些优点:
- 深度模型更适合处理大数据,随着训练数据规模增大,性能不断提升。
- 而浅层模型随训练数据的增加,性能提升不明显。
如下图所示:

并且,通过数据驱动的方式学出的深度特征,具有更强的泛化性能。

二、分层级深度特征
在了解了深度学习视觉算法的设计流程之后,我们还需要学习一下分层级的深度特征。
不同层级的卷积层所学习到的图像特征具有分层的特性
? 浅层: 学习到图像的低级(Low-level)特征,如颜色、边缘、纹理
? 深层: 学到图像的高级(High-level)特征,如物体位置、语义类别

我们以AlexNet为例,对每一层卷积层进行说明:
1)AlexNet中第一层卷积的滤波器96x[11x11x3] 学到edge, color, blob 等底层特征,与手工设计滤波器组相似。

2)第二层对继续对角点和其他的边缘/颜色信息进行相应

3)第三层具有更复杂的不变性,捕获相似的纹理

4)第四层显示了显著的变化,并且更加类别具体化。而第五层显示了具有显著姿态变化的整个对象。
三、常见的深度神经网络类型
我们将依次介绍如下4种常见的深度神经网络类型,这在之前的深度学习课程上面也学习过,在此仅作为复习使用:
? 全连接网络 (Fully Connected Net)
? 卷积网络 (Convolution Net)
? 递归网络 (Recurrent Net)
? Transformer
3.1? 全连接网络




3.2? 卷积网络
对于卷积神经网络,我们需要知道参数量的计算、卷积层的3个主要特点、卷积的过程和空洞卷积的概念和意义、上采样的概念和计算,批量归一化的定义和优缺点。
3.2.1? 卷积层参数量的计算
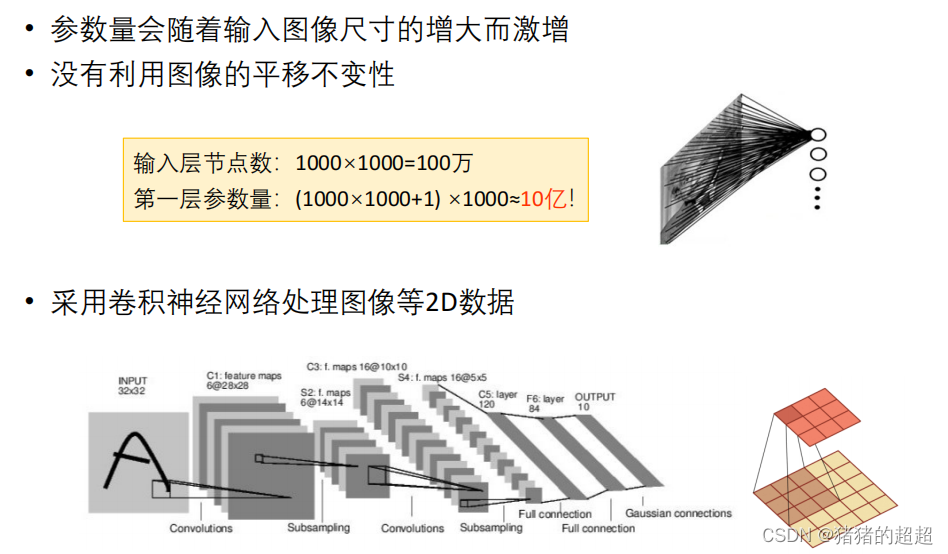
3.2.2? 卷积层的特点(重要)
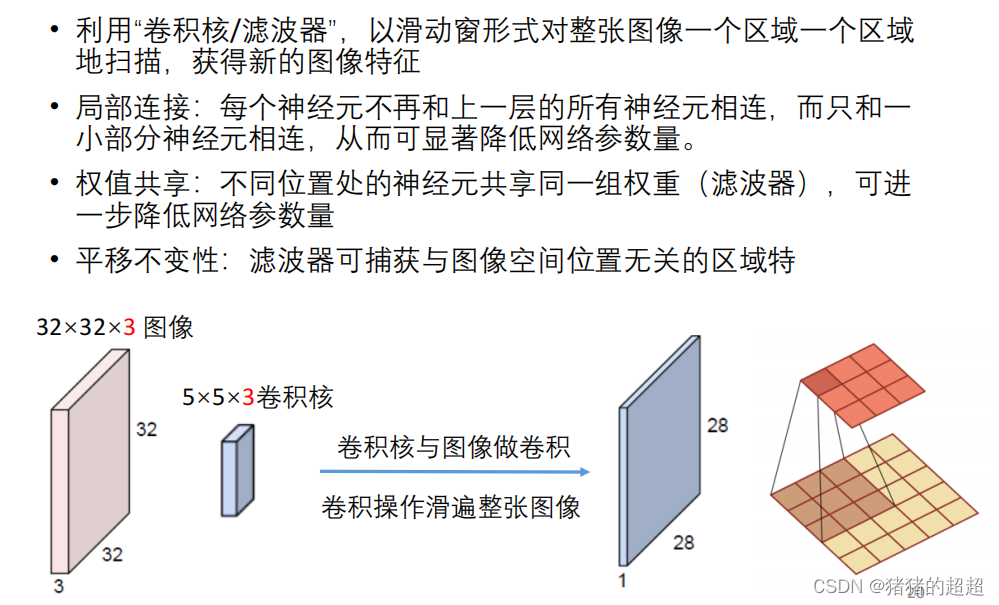
3.2.3? 卷积的过程

3.2.4? 卷积步幅
下图中的步幅 stride = 2

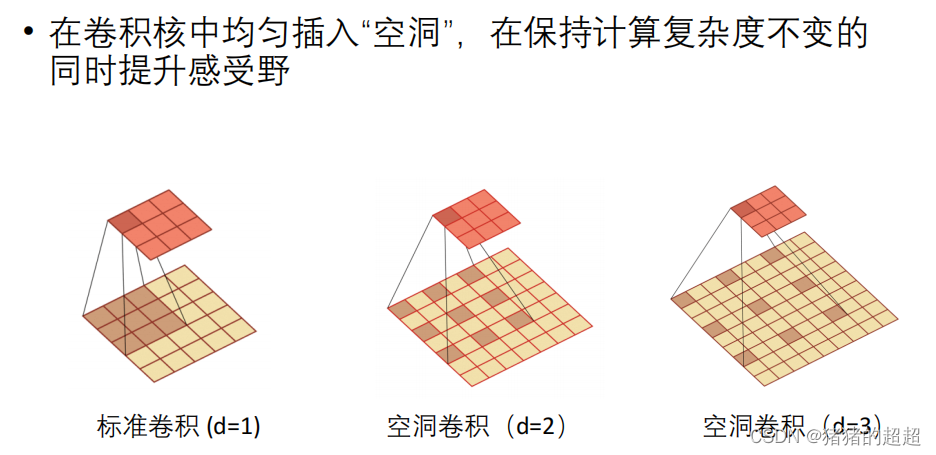
3.2.5? 空洞卷积
3.2.6? 池化层
池化的意义和作用如下:
? 使用某一位置相邻区域的总体统计特性来代替网络在该位置的输出
? 在尽量保留有用信息的同时,实现特征图降采样,提升感受野
1)最大值池化

2)平均值池化

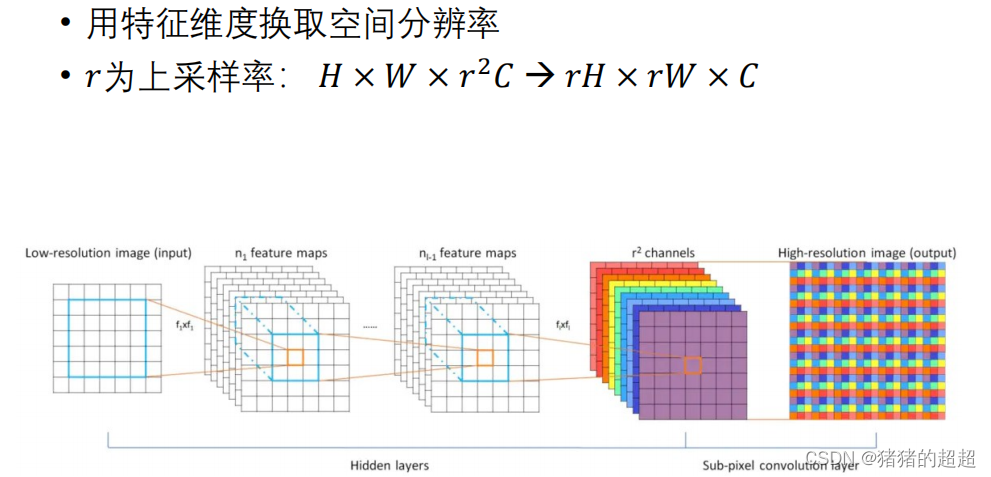
3.2.7? 上采样(反卷积)


3.2.8? 批量归一化(重点)

参考文献:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, ICML 2015
BN的优缺点如下:

需要掌握Batch Norm、Layer Norm、Instance Norm和Group Norm这四个对应的表示形式:

3.3? 递归网络
不是考查的重点,请感兴趣的读者移步参考下方链接:
3.4? Transformer
? Transformer最早针对NLP任务设计,随后推广至视觉领域 (分类、检测、分割、跟踪)
? Transformer最核心的模块是自注意力机制模块,该模块通过将输入特征间的相关性作为权重,对输入特征进行加权,实现管局关系建模

3.4.1? 自注意力机制





参考链接:https://jalammar.github.io/illustrated-transformer/
3.4.2? 多头注意力模块



3.4.3? 常见的损失函数与优化器

四、图像分类
接下来我们将介绍最经典的一些图像分类模型:
4.1? ImageNet数据集

细粒度(Fine-Grained)图像分类是对图像种类进行更精细的划分:
随着旧模型的不断改进,新模型的不断提出,图像分类模型推陈出新,ImageNet精度逐年提升:

4.2? AlexNet

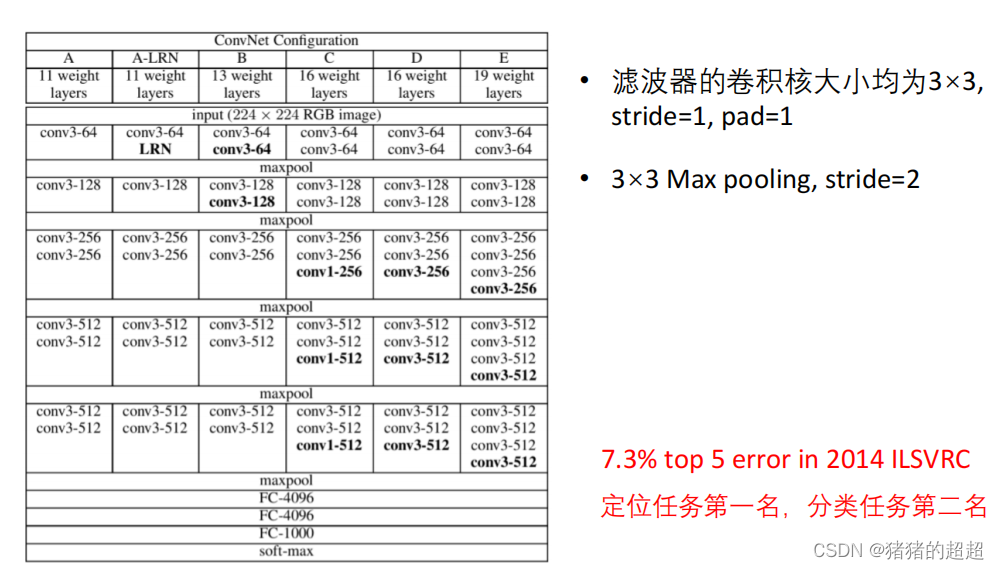
4.3? VGG

4.4? GoogleNet


4.5? ResNet



4.6? DenseNet

4.7? Vision Transformer

4.8? Swing Transformer

Swing Transformer 提出Window based Self-Attention:将输入图像分成互不重叠的Window,自注意机制在每一个Window中独立计算


总结
本文从视觉算法设计流程的演变入手,对比传统视觉算法和深度学习算法的优劣,引出深度学习算法,并依次介绍了深度特征、深度神经网络类型和图像分类的经典模型。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Portraiture磨皮插件2024最新版本下载及使用教程疑难汇总
- 如何像高级软件工程师一样使用vscode做开发
- aigc修复美颜学习笔记
- 劫持最新版 QQNT / QQ / TIM 客户端 ClientKeys
- 材料论文阅读/中文记录:Scaling deep learning for materials discovery
- 全栈没有那么难!15 分钟搞明白 Express.js
- C++-构造与解析
- Agility Robotics和其他七家公司的类人机器人争夺工作岗位
- CUMT--Java复习--异常
- LINUX常见问题之oom kill