数据结构栈、队列、链表、散列表
栈(stack)
栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈顶(top)。它是后进先出(LIFO)的。对栈的基本操作只有 push(进栈)和 pop(出栈)两种,前者相当于插入,后者相当于删除最后的元素。

队列(queue)
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。

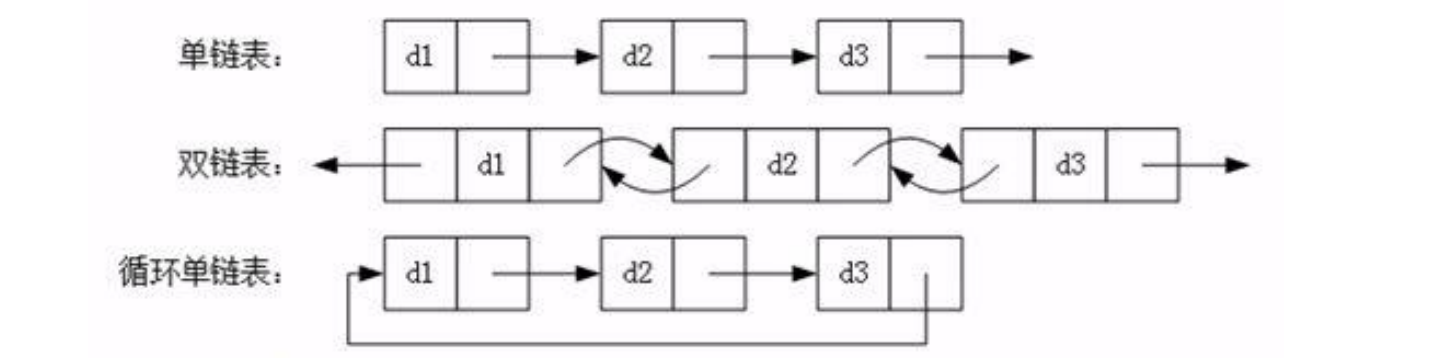
链表(Link)
链表是一种数据结构,和数组同级。比如,Java 中我们使用的 ArrayList,其实现原理是数组。而LinkedList 的实现原理就是链表了。链表在进行循环遍历时效率不高,但是插入和删除时优势明显。
散列表(Hash Table)
散列表(Hash table,也叫哈希表)是一种查找算法,与链表、树等算法不同的是,散列表算法在查找时不需要进行一系列和关键字(关键字是数据元素中某个数据项的值,用以标识一个数据元素)的比较操作。
散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素,因而必须要在数据元素的存储位置和它的关键字(可用 key 表示)之间建立一个确定的对应关系,使每个关键字和散列表中一个唯一的存储位置相对应。因此在查找时,只要根据这个对应关系找到给定关键字在散列表中的位置即可。这种对应关系被称为散列函数(可用 h(key)表示)。
用的构造散列函数的方法有:
(1)直接定址法: 取关键字或关键字的某个线性函数值为散列地址。即:h(key) = key 或 h(key) = a * key + b,其中 a 和 b 为常数。
(2)数字分析法
(3)平方取值法: 取关键字平方后的中间几位为散列地址。
(4)折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。
(5)除留余数法:取关键字被某个不大于散列表表长 m 的数 p 除后所得的余数为散列地址,即:h(key) = key MOD p p ≤ m
(6)随机数法:选择一个随机函数,取关键字的随机函数值为它的散列地址,即:h(key) = random(key)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【TOP顶刊】众望所归!这本IEEE(trans),号称行业白月光,上涨至中科院1区,评职神刊好投吗?
- Parallels deploy K8s
- AIDL接入Android 8.0和Android 11以上版本需要添加的设置
- 2024年【烟花爆竹储存】考试及烟花爆竹储存证考试
- 综述:自动驾驶中的 4D 毫米波雷达
- Vision Transformer原理
- Vue 官方周报 #124 - 使用JSDoc记录组件属性
- [其他] VS Code 配置 Source Insight 主题
- rabbitMq 入门及面试大全
- CP_AutoSar目录