【期末复习向】走进循环神经网络系列-RNN,LSTM,GRU
RNN
上篇文章复习了最简单的神经网络MLP,它是由输入层,隐藏层和输出层构成的。当然这也是所有神经网络最基本的架构。但是MLP过于简单,存在的问题之一就是无法考虑全局的信息,也就是前后输入的信息,这对于解决时间序列的问题是极为不利的。因此引入了存储前一时刻输入信息单元的RNN应运而生。【期末复习向】走进MLP多层感知机-CSDN博客??????文章浏览阅读202次,点赞7次,收藏5次。mlp多层感知机,属于最简单的人工神经网络,也被称为全连接神经网络、前馈网络。它是了解神经网络的基础,包括输入层、隐藏层和输出层3个架构。输入层就是具有维度的向量,输出层也是向量。只有隐藏层是包括了所谓的人造神经元。https://blog.csdn.net/weixin_62588253/article/details/133016982?spm=1001.2014.3001.5502
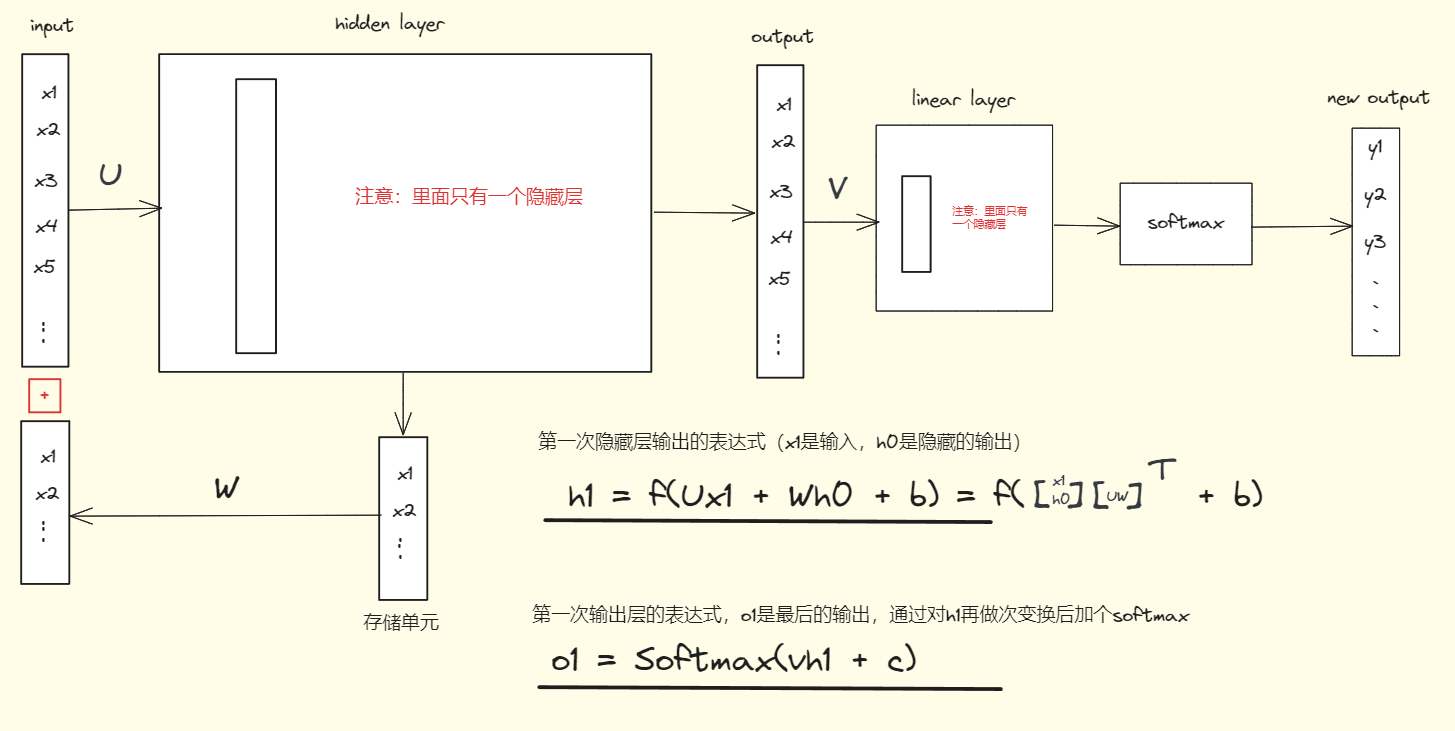
RNN网络中间的隐藏层部分和MLP没有区别,唯一的区别在于RNN最后一个隐藏层的输出会被存储起来,并和下一次输入的向量相加。(如果是第一个输入,那么相加的隐藏层输出设为0)这样每一次的输入都会考虑上一次的输出信息。
RNN就是为了解决时序问题而生的,那么具体到应用,RNN可以解决序列到类别、同步的序列到序列和异步的序列到序列问题。
(1)序列到类别
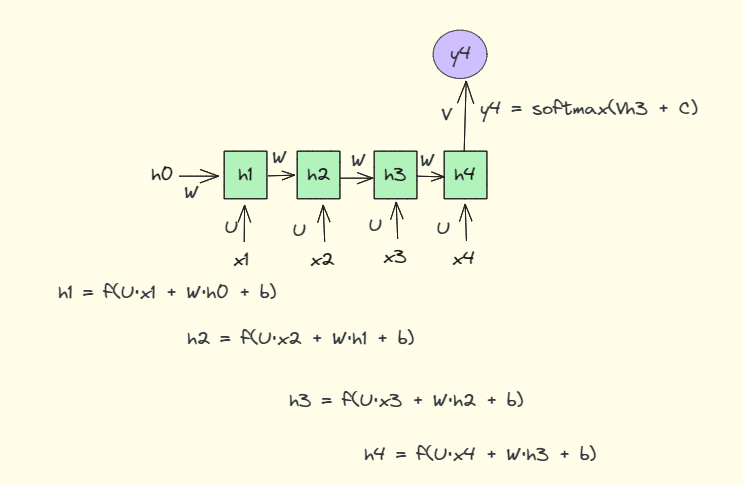
所谓序列到类别就是给一段文本,对文本进行分类的问题。如新闻分类、情感分类等等。如下图是未展开的RNN网络用于分类的示意图。可以输入的维度一个是由词向量决定的,另一个是由隐藏层的输出维度决定的,2者相加构成了输入层的维度大小。同时要注意U,W,b参数是不变的,这个等会把网络展开后容易理解错误。要记住RNN网络每个步骤的参数是共享不变的。
参数U是输入层x1到隐藏层的权重矩阵,参数W是隐藏层输出h0到隐藏层的权重矩阵。有人会说不是把x1和h0拼接起来一起传入到隐藏层吗?那为什么x1和h0分别乘以不同的权重矩阵呢?其实仔细看我下面的图,x1和h0可以看做一个向量,然后他们一起乘以由权重矩阵U和W构成的矩阵的倒置,而这就满足了把上一时刻的隐藏层的输入融入当前时刻的输出,然后再一起经过隐藏层的概念。最后再经过一个激活函数(一般是tanh)。
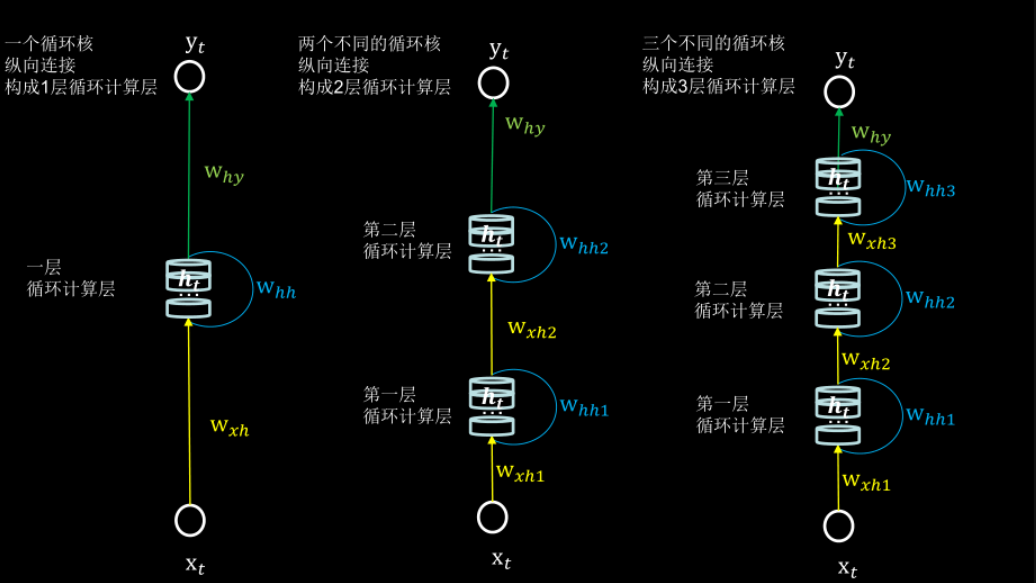
如果hidden layer中有多个隐藏层,那么U和W也就对应的有多个。
多个隐藏层可以参考下面这个图
?下面是按照时间顺序对其展开后的示意图(如果是分类问题的话那么输入只有一个,在最后输出)
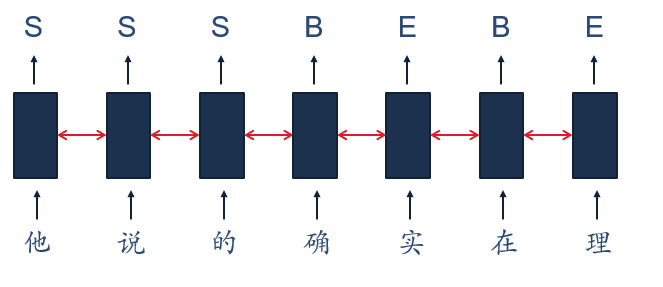
(2)同步的序列到序列
RNN还可以解决例如中文分词、信息抽取、语音识别等同步的序列到序列的问题

(3)异步的序列到序列
对于机器翻译、自动问答等异步的序列到序列问题,RNN也是可以解决的,但是此时就需要采用编码器-解码器架构,利用2个RNN来解决问题。前一个RNN做特征提取,后一个RNN根据第一个输入BOS,逐个输出对应的字(根据字典的数量和最大概率对应的字),最后遇见END字符结束生成。因为这个和后面的transformer重复了,这里就不赘述。可以参考这个文章具体了解编码器-解码器架构:
总结:RNN是最简单的一种循环神经网络。它本身还存在着许多的问题,其中一个便是长期依赖(Long-TermDependencies)问题
所谓长期依赖就是随着RNN处理的序列逐渐变成,前面的信息在传到后面时会逐渐丢失,而在训练时则会导致梯度消失的问题。因此,RNN只具备短时记忆的能力。
LSTM
为了解决RNN的短期记忆问题,LSTM在RNN的基础上学会了利用有限的记忆能力,即忘记不重要的信息,只保留重要的信息。先放出LSTM的一种表示图

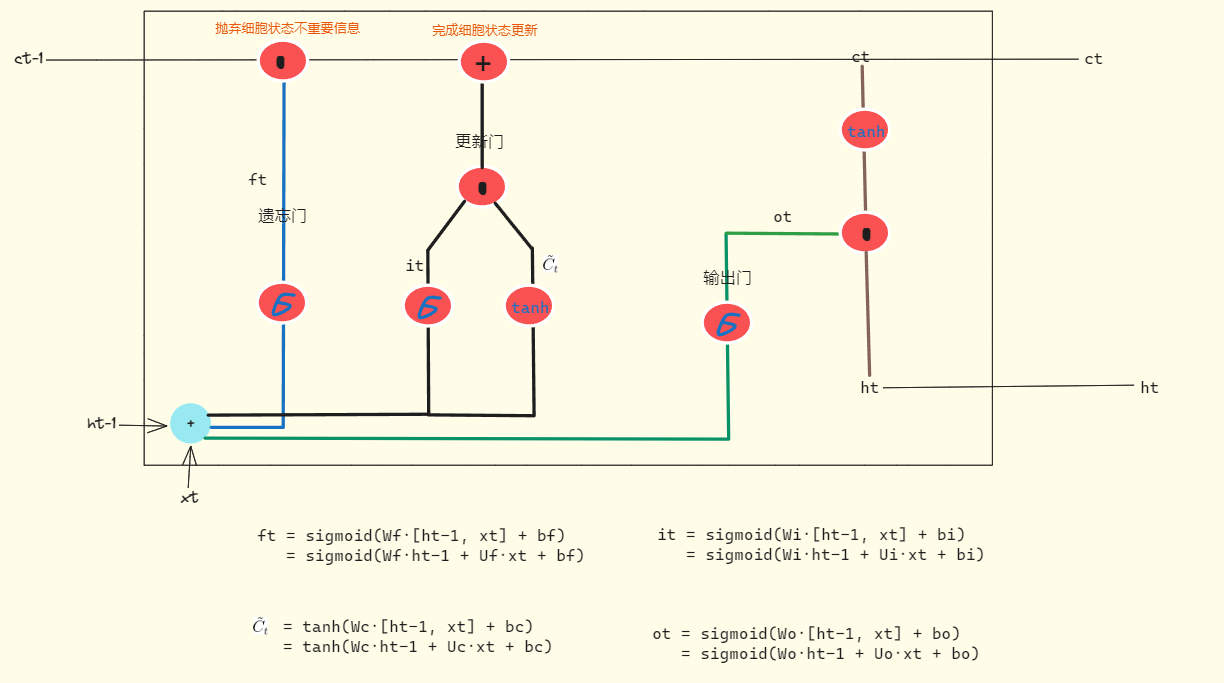
?可以发现相比于RNN,在隐藏层部分,LSTM加入了更多的sigmoid函数,原因就在于它的值域是0-1,0就把不重要的信息遗忘;1就把重要的信息完美的保存下来。除此之外,除了和RNN一样引入之前时刻的信息ht,LSTM还增加了一个细胞状态ct,并通过ct来完成经过遗忘或保留操作后的最终改变。而想要影响到细胞的状态,就要通过三个被称作“门”的结构,分别是遗忘门,更新门(也叫输入门)和输出门,这三个门都会对细胞状态产生影响。
(1)遗忘门
顾名思义,这个门用于决定细胞应该忘记之前的哪些信息。输入是前一时刻的输出ht-1与当前输入xt的拼接,然后经过一个sigmoid激活函数后得到ft。这个ft中的每一维度值的范围都在0-1,表示信息的完全遗忘和完全记住。最后通过与细胞状态ct-1做对位乘(就是向量对应维度相乘,维度大小不变,对应的值相乘)来改变细胞状态。
(2)输入门(更新门)
这一步是为了确定把什么新的信息添加到细胞状态中。其中包括两个部分,一个是sigmoid层,用于决定对原来的信息我们做哪些更新;另一个是tanh层,这个则是在原来信息的基础上产生一个全新的向量![]() ,这个向量是全新的作为候选向量加入到细胞状态中。在产生这2个向量后,对他们同样进行对位乘。
,这个向量是全新的作为候选向量加入到细胞状态中。在产生这2个向量后,对他们同样进行对位乘。
(3)更新细胞状态
基于前面2步,我们就可以完成对细胞状态ct-1的更新。首先是ct-1对位乘ft,用于遗忘掉细胞状态中不重要的信息;然后是让ct-1加上更新门的向量完成对细胞状态信息的更新。
(4)输出门
在完成细胞状态的更新后,我们要依据新的细胞状态决定下一时刻的输出是什么。首先是由输入ht-1与xt经过输出门确定哪些信息需要被输出。同样是经过一个sigmoid激活函数得到ot。接着把更新后的细胞状态通过一个tanh函数,然后与ot进行对位乘得到最终的输出ht。

需要注意的是,LSTM的参数并不是随时间共享的,因此图中一共有4套不同的参数
?GRU
基于LSTM有很多的变种,讲讲其中的GRU。GRU对LSTM的主要改动就在于把细胞状态和隐藏层输出混合在一起,同时只保留了一个重置门和一个更新门。
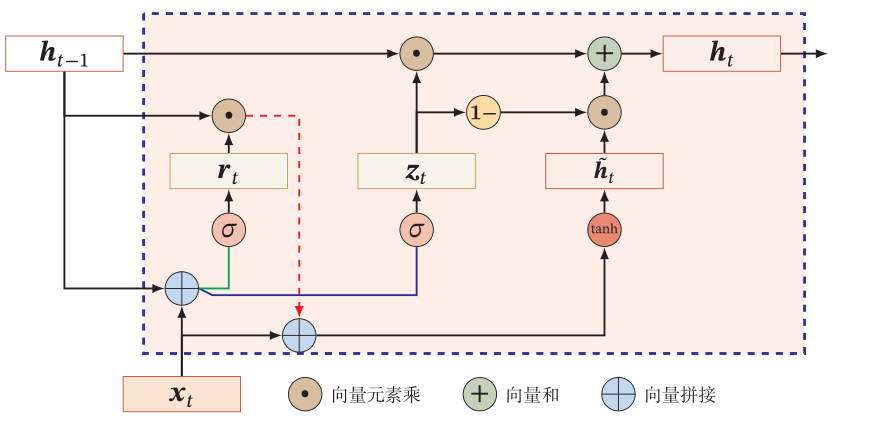
(1)重置门
?重置门rt决定了当前信息与上一时刻的信息如何结合,其实就是遗忘多少信息,具体做法是ht-1与xt拼接后乘一个变换矩阵,然后经过sigmoid函数。
rt = sigmoid(Wr·xt?+ Ur·ht-1?+ br)
(2)更新门
更新门zt决定了如何更新或者更新多少新的信息。具体做法是ht-1与xt拼接后乘一个变换矩阵,然后经过sigmoid函数,与重置门做法是一样的。
zt? =?sigmoid(Wz·xt?+ Uz·ht-1?+ bz)
(3)准备候选隐藏状态
ht-1与rt做对位乘后,再与xt拼接并做变换后,经过一个tanh函数得到候选隐藏状态![]()
?= tanh(Wh·xt + Uh·(ht-1 * rt))
(4)得到隐藏层输出
基于上面3步,可以完成对隐藏层输出的更新。首先是ht-1与更新门的输出zt做对位乘;然后是隐藏状态![]() 与1-zt做对位乘后,加上上一步的输出。
与1-zt做对位乘后,加上上一步的输出。
ht = ht-1 * rt + (1-zt) *
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!