记一次spark-sql数据倾斜解决方案
发布时间:2024年01月09日
spark-sql数据倾斜解决方案
背景
今天在做一张埋点事实表,需要关联几张维表,补充一些维度属性。经过两三个小时,终于把sql写出来,提交到spark集群,跑的时候发现跑了二十多分钟没跑完,心想肯定是倾斜,因为并没有做什么复杂的处理,仅仅是解析一下字段,补充点维度信息。
如何发现倾斜
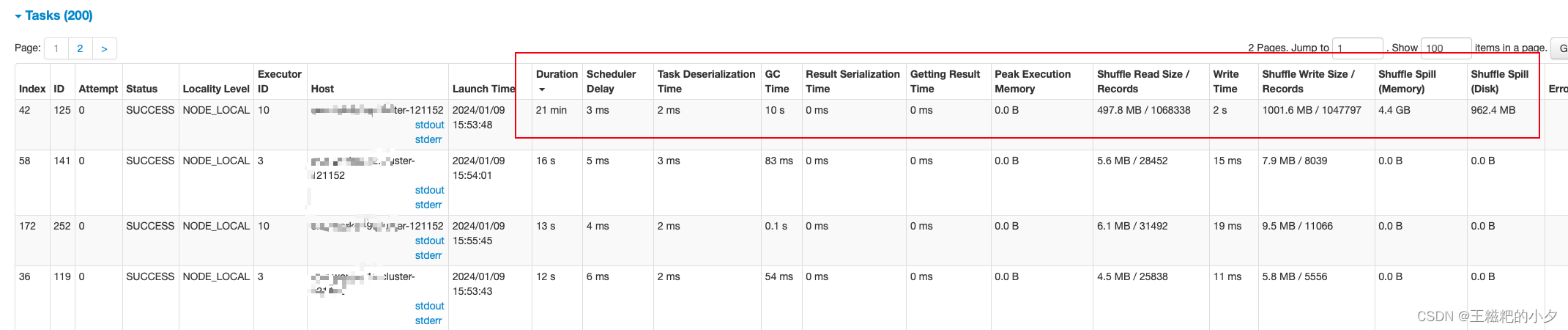
从spark webui中可以看到,只有这一个人task跑了21分钟,其他都是几十秒就跑完了,而且这个task处理了几个G的数据,其他task都是几兆数据。
贴一下sql
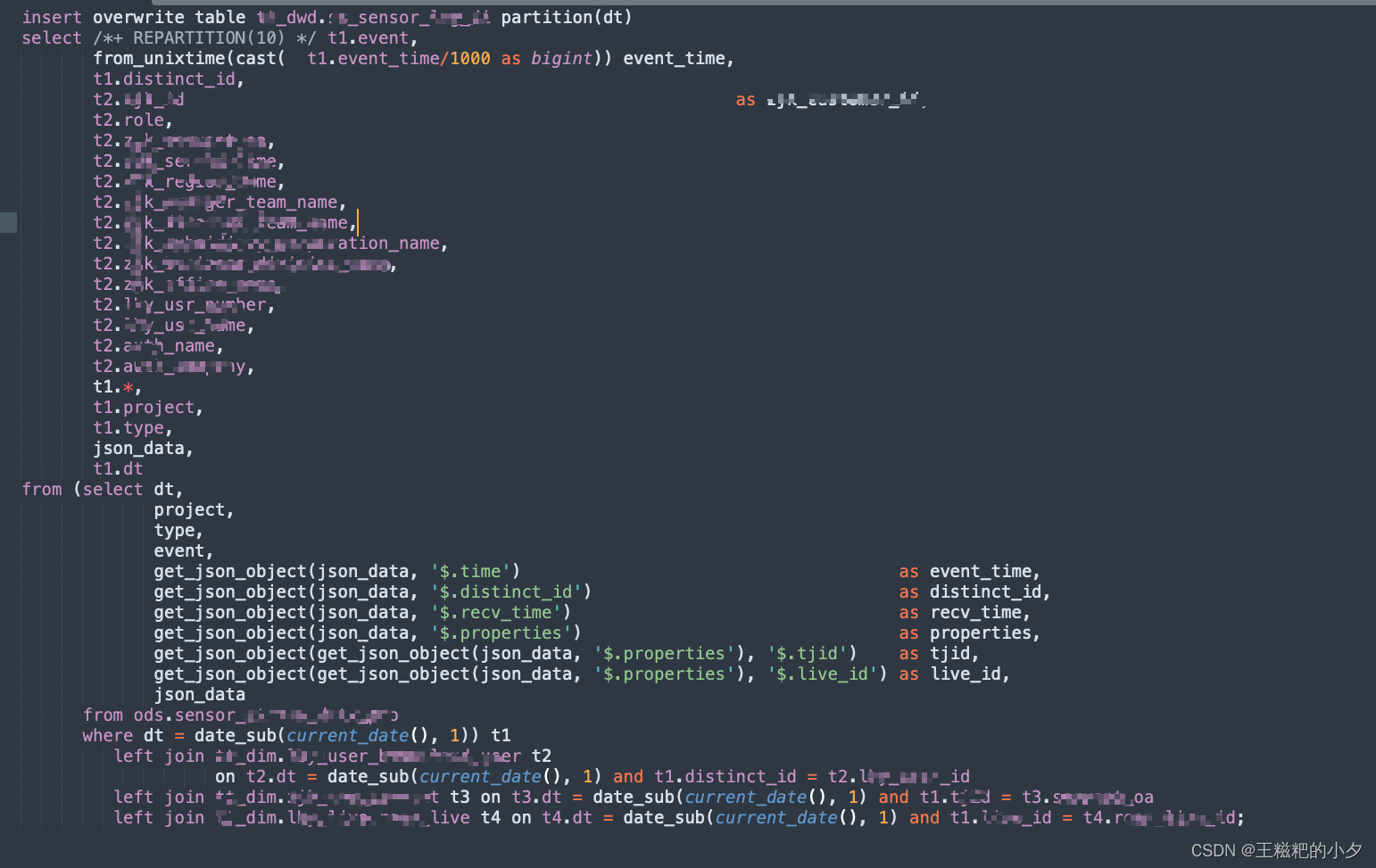
这里解析一下:
hint中的 REPARTITION(10) 是为了合并小文件
t1: ods埋点表 ,一天几百万、几千万条
t2: 用户维度表,全量几百万
t3: 杂项维度,很少
t4: 直播间维度表,很少
定位倾斜的部分
通过前面我们已经知道了发生了数据倾斜,但是到底是哪些发生的倾斜呢?
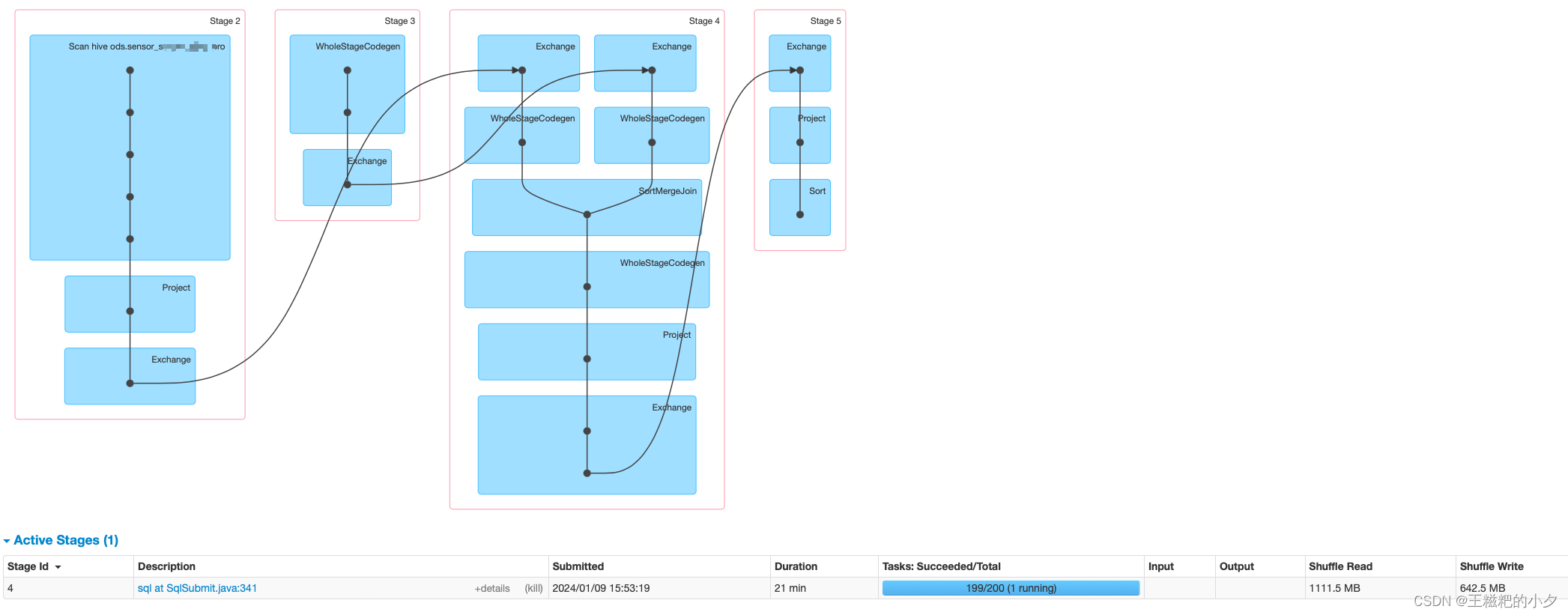
通过上面这个图可以看出是stage4发生了倾斜,那个task跑了二十多分钟还在running。接下来就要定位stage4到底是哪一段sql。
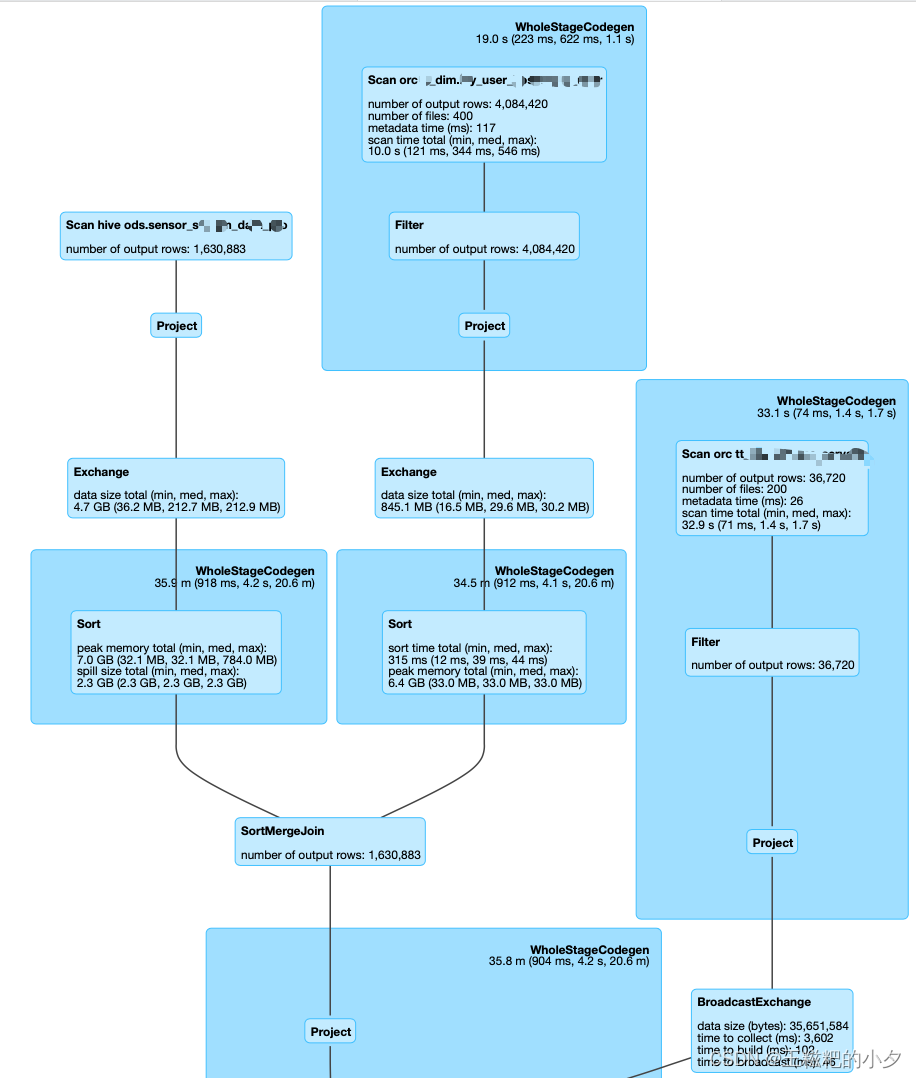
通过观察整体的DAG可以发现,stage4就是关联用户表那部分的sql。既然是关联用户表,那为什么会出现数据倾斜呢?是不是有一部分数据没有关联上呢?
通过统计发现,关联用户表时,有一大半的数据都关联不上,此时关联不上的数据都会被分配到一个task中去计算,所以发生了严重的倾斜

解决方法
既然已经知道是什么原因导致的倾斜,那解决起来就比较简单了,因为是关联的用户表,用户表虽然有几百万的数据,但是不过才一个多G的数据,那我们可以把他广播,自然就不会走shuffle了,修改一下sql,把hint改为 /*+ REPARTITION(10),BROADCAST(t2) */,最后在重新run一下

原本要二十多分钟的任务,通过广播缩短到了4分钟。可以下班了
文章来源:https://blog.csdn.net/weixin_43039757/article/details/135485141
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 类文件结构
- Jmeter性能实战之分布式压测
- webGL技术的难点分析
- 面试官:小伙子来说一说Java中final关键字,以及它和finally、finalize()有什么区别?
- rust 各种骚操作
- 财务数据智能化:用AI工具高效制作财务分析PPT报告
- 快速掌握前端 专为Java程序员定制
- mysql(51) : 大数据导出为insert
- (第9天)SQLPlus 基础使用和进阶玩法
- Linux学习之网络编程2(socket,简单C/S模型)