数据库系统概念 第七版 中文答案 第3章 SQL介绍
3.1 将以下查询使用SQL语言编写,使用大学数据库模式。 (我们建议您实际在数据库上运行这些查询,使用我们在书籍网站db-book.com上提供的示例数据。有关设置数据库和加载示例数据的说明,请参阅上述网站。)
?
a. 查找计算机科学系中学分为3的课程的标题。
b. 查找所有由名为Einstein的教师教授的学生的ID;确保结果中没有重复项。
c. 查找任何教师的最高工资。
d. 查找所有薪水最高的教师(可能有多个薪水相同的教师)。
e. 查找在2017年秋季开设的每个课程部分的注册人数。
f. 查找2017年秋季所有部分中的最大注册人数。
g. 查找在2017年秋季拥有最大注册人数的部分。.
Answer:
a.?? ?查找计算机科学系中学分为3的课程的标题。
?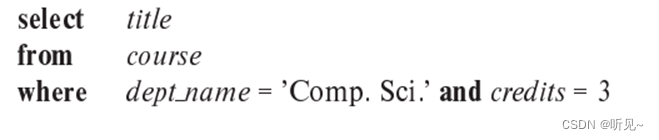
b.?? ?查找所有由名为Einstein的教师教授的学生的ID;确保结果中没有重复项。
?
c.?? ?查找任何教师的最高工资。
?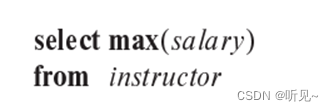
d.?? ?查找所有薪水最高的教师(可能有多个薪水相同的教师)。
?
e.?? ?查找在2017年秋季开设的每个课程部分的注册人数。
?
或者
?
f.?? ?查找2017年秋季所有部分中的最大注册人数。
?
g.?? ?查找在2017年秋季拥有最大注册人数的部分。

3.2 假设你有一个关系grade_points(grade,points),它提供了从takes关系中的用字母表示的成绩等级到数值分数的转换;例如,“A”成绩可以被指定为对应于4分,而“A-”对应于3.7分,“B+”对应于3.3分,“B”对应于3分,依此类推。学生为提供的课程部分获得的成绩点定义为课程的学分乘以学生获得的成绩的数值点。
鉴于上述关系和我们的大学模式,请在SQL中编写以下每个查询。为简化起见,你可以假设takes关系中的元组没有成绩的空值。
a. 查找学生ID为'12345'的学生在所有选修的课程中获得的总成绩点。
b. 查找上述学生的平均绩点(GPA),即总成绩点除以相关课程的总学分。
c. 查找每个学生的ID和平均绩点。
d. 现在重新考虑前面部分的答案,假设某些成绩可能为null。解释你的解决方案是否仍然有效,如果无效,提供适当处理null的版本。
Answer:
a.?? ?查找学生ID为'12345'的学生在所有选修的课程中获得的总成绩点。
?
在上面的查询中,没有上过任何课程的学生不会有任何元组,而我们期望得到0作为答案。解决这个问题的一种方法是使用外部连接操作,我们将在后面的第4章中学习。另一种确保我们得到0作为答案的方法是通过以下查询:
?
b.?? ?查找上述学生的平均绩点(GPA),即总成绩点除以相关课程的总学分。
?
和以前一样,没有修过任何课程的学生不会出现在上述成绩中;我们可以通过使用这个问题前面部分修改过的查询来确保这样一个学生出现在结果中。然而,在这种情况下的另一个问题是,积分的总和也将为0,从而导致除以零的情况。事实上,在这种情况下,唯一有意义的定义GPA的方法是将其定义为null。通过在上面的查询中添加以下联合子句,我们可以确保这样的学生以零GPA出现在结果中。
?
c.?? ?查找每个学生的ID和平均绩点。
?
?
d. 现在重新考虑前面部分的答案,假设某些成绩可能为null。解释你的解决方案是否仍然有效,如果无效,提供适当处理null的版本。
3.3?? ?编写以下在数据库中使用大学模式的插入、删除或更新的SQL语句。
a. 将计算机科学系每位教师的薪水提高10%。
b. 删除所有从未开设过课程的课程(即在“section”关系中不存在的课程)。
c. 将总注册学分大于100的每位学生插入到相同系别作为教师,并设置薪水为$10,000。
Answer:
a. 将计算机科学系每位教师的薪水提高10%。
?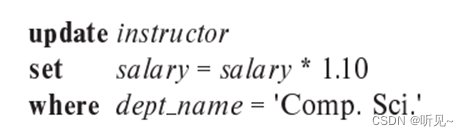
b. 删除所有从未开设过课程的课程(即在“section”关系中不存在的课程)。
?
c. 将总注册学分大于100的每位学生插入到相同系别作为教师,并设置薪水为$10,000。
?
3.4?? ?考虑图3.17中的保险数据库,其中主键已被下划线标识。为该关系数据库构建以下SQL查询。
a. 查找在2017年其车辆出现交通事故的人的总数。
b. 删除属于ID为'12345'的人所有年份为2010的车辆。

Answer:
a.?? ?查找在2017年其车辆出现交通事故的人的总数。
?
b.?? ?删除属于ID为'12345'的人所有年份为2010的车辆。

3.5 ?假设我们有一个关系marks(ID, score),我们希望根据得分为学生分配成绩,规则如下:如果score < 40,则为F级别,如果40 <= score < 60,则为C级别,如果60 <= score < 80,则为B级别,如果80 <= score,则为A级别。编写SQL查询执行以下操作:
a.?? ?根据marks关系显示每个学生的成绩。
b.?? ?查找每个等级的学生数量。?
Answer:
a.根据marks关系显示每个学生的成绩。
. ?
b.?? ?查找每个等级的学生数量.
??
3.6 ?SQL中的LIKE操作符在大多数系统中是区分大小写的,但是可以使用字符串的lower()函数来执行不区分大小写的匹配。为了演示如何做到这一点,请编写一个查询,找到部门名称中包含字符串“si”的子串,而不考虑大小写。
Answer:
?
3.7?? ?考虑以下 SQL 查询
SELECT p.a1 FROM p, r1, r2
WHERE p.a1 = r1.a1 OR p.a1 = r2.a1
在什么条件下,前述查询选择了在 r1 或 r2 中的 p:a1 的值?请仔细分析在 r1 或 r2 可能为空的情况。
Answer:
该查询选择了 p.a1 的那些值,这些值等于 r1.a1 或 r2.a1 的某个值,当且仅当 r1 和 r2 均为非空时。如果 r1 和/或 r2 中有一个或两个为空,则 p、r1 和 r2 的笛卡尔积为空,因此查询的结果为空。如果 p 本身为空,则结果也为空。
3.8 ?考虑图 3.18 中的银行数据库,其中主键已经被下划线标示。构造如下 SQL 查询:
?
a. 查找银行中每个具有账户但没有贷款的客户的 ID。
b. 查找每个与客户 12345 同住在相同街道和城市的客户的 ID。
c. 查找每个至少有一个在银行拥有账户且住在“Harrison”的客户的分行的名称。
Answer:
a.?? ?a. 查找银行中每个具有账户但没有贷款的客户的 ID。
?
b.?? ?查找每个与客户 12345 同住在相同街道和城市的客户的 ID。
?
c.?? ?查找每个至少有一个在银行拥有账户且住在“Harrison”的客户的分行的名称。

3.9?? ?考虑图 3.19 中的关系数据库,其中主键已被下划线标示。给出以下每个查询的 SQL 表达式。
?
a. 查找每个在“First Bank Corporation”工作的员工的 ID、姓名和居住城市。
b. ?查找每个在“First Bank Corporation”工作且薪水超过 $10000 的员工的 ID、姓名和居住城市。
c. ? ?? ?查找每个不在“First Bank Corporation”工作的员工的 ID。
d. ?查找每个收入高于“Small Bank Corporation”所有员工的员工的 ID。
e. ? 假设公司可以位于多个城市。查找每个位于“Small Bank Corporation”所在的每个城市的公司的名称。
f. 查找具有最多员工的公司(或在有最多员工并列的情况下的所有公司)的名称。
g. ?查找每个员工平均工资高于“First Bank Corporation”平均工资的公司的名称。
Answer:
a.?? ?查找每个在“First Bank Corporation”工作的员工的 ID、姓名和居住城市。
?
b.?? ?查找每个在“First Bank Corporation”工作且薪水超过 $10000 的员工的 ID、姓名和居住城市。
?
c.?? ?查找每个不在“First Bank Corporation”工作的员工的 ID。
?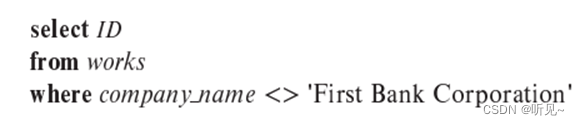
如果允许人们出现在雇员中而不出现在作品中,解决方案就稍微复杂一些。也可以使用第4章中讨论的外连接。
?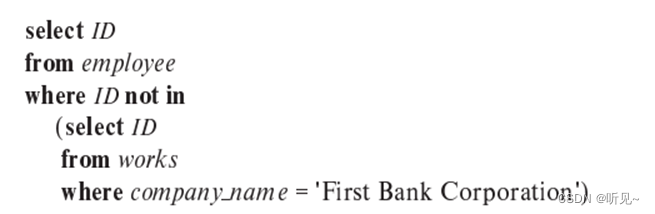
d.?? ?查找每个收入高于“Small Bank Corporation”所有员工的员工的 ID。
?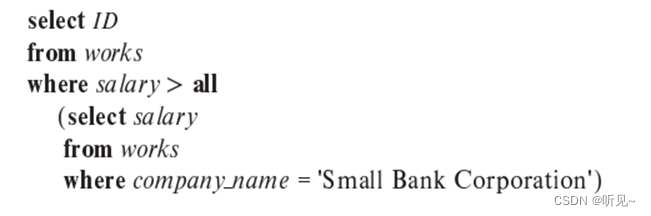
上如果人们可能为几家公司工作,我们希望考虑每个人的总收入,问题就复杂多了。但请注意事实上,ID是works的主键,这意味着情况并非如此。
e.?? ?假设公司可以位于多个城市。查找每个位于“Small Bank Corporation”所在的每个城市的公司的名称。
方法1
?
方法2
?
f.?? ?查找具有最多员工的公司(或在有最多员工并列的情况下的所有公司)的名称。
?
g.?? ?查找每个员工平均工资高于“First Bank Corporation”平均工资的公司的名称。

3.10?? ?考虑图3.19中的关系数据库。为以下每个情况提供一个SQL表达式:
a. 修改数据库,使员工ID为“12345”的员工现居住在“Newtown”。
b. 给“First Bank Corporation”的每位经理加薪10%,除非工资超过$100,000;在这种情况下,只加薪3%。
Answer:
a.?? ?修改数据库,使员工ID为“12345”的员工现居住在“Newtown”。
?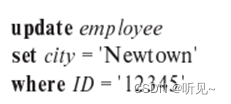
b.?? ?给“First Bank Corporation”的每位经理加薪10%,除非工资超过$100,000;在这种情况下,只加薪3%。

如果以相反的顺序执行上述更新,结果会有所不同。我们以下提供一种更安全的解决方案,使用CASE语句。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机二级C语言的注意事项及相应真题-4-程序填空
- 账号租号平台PHP源码,支持单独租用或合租使用
- 聚簇索引的优化策略与注意事项:挖掘性能潜力的关键
- (笔记总结)C/C++语言的常用库函数(持续记录,积累量变)
- 什么是波分复用 (WDM) 或密集波分复用 (DWDM)?
- 集合基础详细
- 二维码智慧门牌管理系统升级:推动社会治理变革
- 强烈推荐!好玩又好用的开源工具
- Ribbon学习思维导图
- 干掉xshell, 这款远程终端工具:开源、免费、跨平台,同时支持SSH+SFTP+Telent+TCP+Serial,太香了。