设计一个简单的规则引擎
- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
设计一个简单的规则引擎
问题描述
何为规则引擎?按照gpt的给的定义来解释下:
规则引擎是一种计算机软件或系统,用于管理和执行特定规则集合。它基于预定义的规则和逻辑,对输入数据进行处理、评估和决策。规则引擎通常由两个主要组成部分组成:规则管理器和推理引擎。
那么假如说我们需要设计一个简单的规则引擎,那么结合上述需要考虑什么呢?
比如说我们已知一个人的性别和年龄,根据这两个进行规则的判断,然后分流到不同的分支,怎么实现呢?
最简单的方式莫过于几个if,else就能结果,但是假如说后面加入了更多的规则,岂不是我们还要重新进去写代码改这个规则?
所以需要设计一个动态的规则引擎,这样当有新的规则来的时候,我们不需要很大的变动,就可以完成规则的加入。
需求设计

本质上就是要完成这样的一个规则引擎,首先通过性别进行规则判断,然后是通过年龄进行规则判断,这样一个简单的规则殷勤的雏形就设计好了。
数据库设计
一个好的规则引擎还可以用于将来的扩展,所以理论上一些值应该保存在数据库中,将来再由一套管理系统进行动态扩展即可。
那么数据库的设计是什么呢?
从上图也可以看到,这个结构是不是很像一颗二叉树,实际上的设计也是基于此,库表中其实就是将一颗二叉树抽象进去啦,那么这里就需要包括:树根、树茎、子叶、果实。在具体的逻辑实现中则需要通过子叶判断走哪个树茎以及最终筛选出一个果实来。
rule_tree
CREATE TABLE `rule_tree` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tree_name` varchar(64) DEFAULT NULL COMMENT '规则树NAME',
`tree_desc` varchar(128) DEFAULT NULL COMMENT '规则树描述',
`tree_root_node_id` bigint(20) DEFAULT NULL COMMENT '规则树根ID',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10002 DEFAULT CHARSET=utf8;
rule_tree_node
CREATE TABLE `rule_tree_node` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tree_id` int(2) DEFAULT NULL COMMENT '规则树ID',
`node_type` int(2) DEFAULT NULL COMMENT '节点类型;1子叶、2果实',
`node_value` varchar(32) DEFAULT NULL COMMENT '节点值[nodeType=2];果实值',
`rule_key` varchar(16) DEFAULT NULL COMMENT '规则Key',
`rule_desc` varchar(32) DEFAULT NULL COMMENT '规则描述',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=123 DEFAULT CHARSET=utf8;
rule_tree_node_line
CREATE TABLE `rule_tree_node_line` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tree_id` bigint(20) DEFAULT NULL COMMENT '规则树ID',
`node_id_from` bigint(20) DEFAULT NULL COMMENT '节点From',
`node_id_to` bigint(20) DEFAULT NULL COMMENT '节点To',
`rule_limit_type` int(2) DEFAULT NULL COMMENT '限定类型;1:=;2:>;3:<;4:>=;5<=;6:enum[枚举范围];7:果实',
`rule_limit_value` varchar(32) DEFAULT NULL COMMENT '限定值',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
以上就是表的结构,那么将上图中的结构抽象进数据库中数据应该写呢?
rule_tree data

rule_tree_node data

rule_tree_node_line data

以上就是全部的数据库设计啦,其实就是将二叉树的结构抽象进数据库中,然后为每个分支都加上逻辑判断即可,如rule_tree_node_line data 所示。
结构设计
聊完数据库设计,再回到问题描述里说的:
规则引擎是一种计算机软件或系统,用于管理和执行特定规则集合。它基于预定义的规则和逻辑,对输入数据进行处理、评估和决策。规则引擎通常由两个主要组成部分组成:规则管理器和推理引擎。
总结起来就是一句话,规则引擎分为 规则管理器 + 推理引擎。
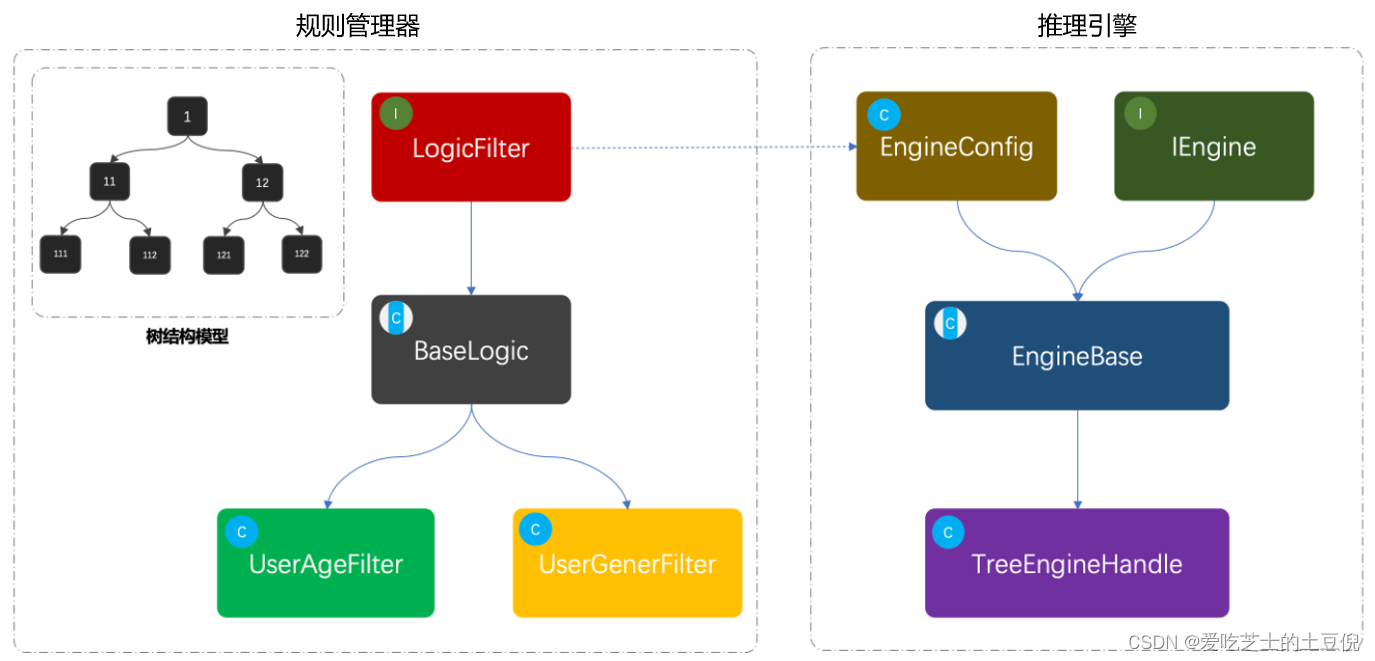
核心代码
规则管理器
// 规则过滤器接口
public interface LogicFilter {
/**
* 逻辑决策器
* @param matterValue 决策值
* @param treeNodeLineInfoList 决策节点
* @return 下一个节点Id
*/
Long filter(String matterValue, List<TreeNodeLineVO> treeNodeLineInfoList);
/**
* 获取决策值
*
* @param decisionMatter 决策物料
* @return 决策值
*/
String matterValue(DecisionMatterReq decisionMatter);
}
filter的核心就是根据当前的决策值返回下一个节点的ID
public abstract class BaseLogic implements LogicFilter {
@Override
public Long filter(String matterValue, List<TreeNodeLineVO> treeNodeLineInfoList) {
for (TreeNodeLineVO nodeLine : treeNodeLineInfoList) {
if (decisionLogic(matterValue, nodeLine)) {
return nodeLine.getNodeIdTo();
}
}
return Constants.Global.TREE_NULL_NODE;
}
/**
* 获取规则比对值
* @param decisionMatter 决策物料
* @return 比对值
*/
@Override
public abstract String matterValue(DecisionMatterReq decisionMatter);
private boolean decisionLogic(String matterValue, TreeNodeLineVO nodeLine) {
switch (nodeLine.getRuleLimitType()) {
case Constants.RuleLimitType.EQUAL:
return matterValue.equals(nodeLine.getRuleLimitValue());
case Constants.RuleLimitType.GT:
return Double.parseDouble(matterValue) > Double.parseDouble(nodeLine.getRuleLimitValue());
case Constants.RuleLimitType.LT:
return Double.parseDouble(matterValue) < Double.parseDouble(nodeLine.getRuleLimitValue());
case Constants.RuleLimitType.GE:
return Double.parseDouble(matterValue) >= Double.parseDouble(nodeLine.getRuleLimitValue());
case Constants.RuleLimitType.LE:
return Double.parseDouble(matterValue) <= Double.parseDouble(nodeLine.getRuleLimitValue());
default:
return false;
}
}
}
以及两个对应的规则
@Component
public class UserAgeFilter extends BaseLogic {
@Override
public String matterValue(DecisionMatterReq decisionMatter) {
return decisionMatter.getValMap().get("age").toString();
}
}
@Component
public class UserGenderFilter extends BaseLogic {
@Override
public String matterValue(DecisionMatterReq decisionMatter) {
return decisionMatter.getValMap().get("gender").toString();
}
}
推理引擎
// 规则过滤器引擎
public interface EngineFilter {
/**
* 规则过滤器接口
*
* @param matter 规则决策物料
* @return 规则决策结果
*/
EngineResult process(final DecisionMatterReq matter);
}
// 规则配置
public class EngineConfig {
protected static Map<String, LogicFilter> logicFilterMap = new ConcurrentHashMap<>();
@Resource
private UserAgeFilter userAgeFilter;
@Resource
private UserGenderFilter userGenderFilter;
@PostConstruct
public void init() {
logicFilterMap.put("userAge", userAgeFilter);
logicFilterMap.put("userGender", userGenderFilter);
}
}
public abstract class EngineBase extends EngineConfig implements EngineFilter {
private Logger logger = LoggerFactory.getLogger(EngineBase.class);
@Override
public EngineResult process(DecisionMatterReq matter) {
throw new RuntimeException("未实现规则引擎服务");
}
protected TreeNodeVO engineDecisionMaker(TreeRuleRich treeRuleRich, DecisionMatterReq matter) {
TreeRootVO treeRoot = treeRuleRich.getTreeRoot();
Map<Long, TreeNodeVO> treeNodeMap = treeRuleRich.getTreeNodeMap();
// 规则树根ID
Long rootNodeId = treeRoot.getTreeRootNodeId();
TreeNodeVO treeNodeInfo = treeNodeMap.get(rootNodeId);
// 节点类型[NodeType];1子叶、2果实
while (Constants.NodeType.STEM.equals(treeNodeInfo.getNodeType())) {
String ruleKey = treeNodeInfo.getRuleKey();
LogicFilter logicFilter = logicFilterMap.get(ruleKey);
String matterValue = logicFilter.matterValue(matter);
Long nextNode = logicFilter.filter(matterValue, treeNodeInfo.getTreeNodeLineInfoList());
treeNodeInfo = treeNodeMap.get(nextNode);
logger.info("决策树引擎=>{} userId:{} treeId:{} treeNode:{} ruleKey:{} matterValue:{}",
treeRoot.getTreeName(), matter.getUserId(), matter.getTreeId(), treeNodeInfo.getTreeNodeId(),
ruleKey, matterValue);
}
return treeNodeInfo;
}
}
上述这段代码也是真正的推理引擎的代码,来解读一下,首先获取到这课规则树,然后遍历这颗规则树,遍历的时候根据对应节点的规则key,从规则管理器中找到对应的规则,然后执行规则,获取到下一个即将要执行的规则,然后在while循环中遍历,并且将每一次找到的规则打印即可。
@Service("ruleEngineHandle")
public class RuleEngineHandle extends EngineBase {
@Resource
private IRuleRepository ruleRepository;
@Override
public EngineResult process(DecisionMatterReq matter) {
// 决策规则树
TreeRuleRich treeRuleRich = ruleRepository.queryTreeRuleRich(matter.getTreeId());
if (null == treeRuleRich) {
throw new RuntimeException("Tree Rule is null!");
}
// 决策节点
TreeNodeVO treeNodeInfo = engineDecisionMaker(treeRuleRich, matter);
// 决策结果
return new EngineResult(matter.getUserId(), treeNodeInfo.getTreeId(), treeNodeInfo.getTreeNodeId(), treeNodeInfo.getNodeValue());
}
}
最终展示
@RunWith(SpringRunner.class)
@SpringBootTest
public class RuleTest {
private Logger logger = LoggerFactory.getLogger(ActivityTest.class);
@Resource
private EngineFilter engineFilter;
@Test
public void test_process() {
DecisionMatterReq req = new DecisionMatterReq();
req.setTreeId(2110081902L);
req.setUserId("nhs");
req.setValMap(new HashMap<String, Object>() {{
put("gender", "man");
put("age", "25");
}});
EngineResult res = engineFilter.process(req);
logger.info("请求参数:{}", JSON.toJSONString(req));
logger.info("测试结果:{}", JSON.toJSONString(res));
}
}
测试结果
09:30:58.874 INFO 53959 --- [ main] c.i.l.d.rule.service.engine.EngineBase : 决策树引擎=>抽奖活动规则树 userId:fustack treeId:2110081902 treeNode:11 ruleKey:userGender matterValue:man
09:30:58.874 INFO 53959 --- [ main] c.i.l.d.rule.service.engine.EngineBase : 决策树引擎=>抽奖活动规则树 userId:fustack treeId:2110081902 treeNode:112 ruleKey:userAge matterValue:25
09:30:59.349 INFO 53959 --- [ main] c.i.lottery.test.domain.ActivityTest : 请求参数:{"treeId":2110081902,"userId":"fustack","valMap":{"gender":"man","age":"25"}}
09:30:59.355 INFO 53959 --- [ main] c.i.lottery.test.domain.ActivityTest : 测试结果:{"nodeId":112,"nodeValue":"100002","success":true,"treeId":2110081902,"userId":"nhs"}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 360沃通亮相2023年深圳市卫生健康信息学术会议,展示医疗行业商密应用方案
- 数据结构及其简单实现
- idea设置注释在鼠标当前位置,使其不从顶格位置添加注释
- 每日一题——LeetCode1128.等价多米诺骨牌对的数量
- 【Spring Cloud】组件概念详解
- antd+vue:tree组件:父级节点禁止选择并不展示选择框——基础积累
- 网络安全(黑客)——自学2024
- JS面试题:说一下什么是原型、原型链?
- 【科学计算语言】实验二 Python函数
- imgaug库指南(16):从入门到精通的【图像增强】之旅