火车票车票查询-Python
发布时间:2024年01月23日
一、相关代码
# @Time: 2024/1/22 20:24
# @Author: 马龙强
# @File: 实现12306查票购票.py
# @software: PyCharm
"""
网址:https://www.12306.cn/index/
数据:车次信息
查票链接:https://kyfw.12306.cn/otn/leftTicket/queryE?leftTicketDTO.train_date=2024-01-23&leftTicketDTO.from_station=LON&leftTicketDTO.to_station=XUN&purpose_codes=ADULT
"""
import requests
from pprint import pprint
import json
#导入漂亮的制表
from prettytable import PrettyTable
"""查票功能
1.输入出发城市
2.输入目的城市
3.输入出发时间
根据输入城市 -> 通过 city.json 找到对应城市字母(station.json 对应车站)
12306自动购票
"""
#读取json文件
f = open('city.json',encoding='utf-8').read()
#转成json字典
city_data = json.loads(f)
# print(city_data)
from_city = input('请输入出发的城市:')
site_city = input('请输入到达的城市:')
from_time = input('请输入出发的时间:') #2024-01-25
print('出发城市字母',city_data[from_city])
print('目的城市字母',city_data[site_city])
"""发送请求:模拟浏览器对于url地址发送请求"""
#请求网址
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
"Cookie": "_uab_collina=170592620040439510680099; JSESSIONID=80E55A815952C4C2E5B1AC826CC88FF0; BIGipServerpassport=1005060362.50215.0000; guidesStatus=off; highContrastMode=defaltMode; cursorStatus=off; route=6f50b51faa11b987e576cdb301e545c4; BIGipServerotn=2095579402.64545.0000; _jc_save_fromStation=%u6F2F%u6CB3%2CLON; _jc_save_toStation=%u4FE1%u9633%2CXUN; _jc_save_fromDate=2024-01-23; _jc_save_toDate=2024-01-22; _jc_save_wfdc_flag=dc"
}
url = f'https://kyfw.12306.cn/otn/leftTicket/queryE?leftTicketDTO.train_date={from_time}&leftTicketDTO.from_station={city_data[from_city]}&leftTicketDTO.to_station={city_data[site_city]}&purpose_codes=ADULT'
#发送请求
response = requests.get(url=url,headers=headers)
# print(response.json())
# print(response.text)
json_data = response.json()
#实例化一个对象
tb = PrettyTable()
#设置一个字段名
tb.field_names = [
'序号',
'车次',
'出发时间',
'到达时间',
'时长',
'特等座',
'一等座',
'二等座',
'软卧',
'硬卧',
'硬座',
'无座',
]
#设置序号
page = 1
# pprint(json_data)
#提取车次信息所在列表
result = json_data['data']['result']
# pprint(result)
#for循环遍历,提取列表里面的元素
for i in result:
# print(i)
#字符串分割 -> index列表
index = i.split('|')
# print(index)
num = index[3] #车次
time_1 = index[8] #出发时间
time_2 = index[9] #到达时间
time_3 = index[10] #时长
topGrade = index[32] #特等座
first_class = index[31] #一等座
second_class = index[30] #二等座
hrad_sleeper = index[28] #硬卧
hard_seat = index[29] #硬座
no_seat = index[26] #无座
soft_sleeper = index[23] #软卧
dit = {
'车次': num,
'出发时间': time_1,
'到达时间': time_2,
'时长': time_3,
'特等座': topGrade,
'一等座': first_class,
'二等座': second_class,
'软卧': soft_sleeper,
'硬卧': hrad_sleeper,
'硬座': hard_seat,
'无座': no_seat,
}
#车次
# print(index)
# page = 0
# for j in index:
# print(page,j,sep='****')
# page+=1
# break
#添加字段内容
tb.add_row([
page,
num,
time_1,
time_2,
time_3,
topGrade,
first_class,
second_class,
soft_sleeper,
hrad_sleeper,
hard_seat,
no_seat,
])
# print(dit)
page +=1
print(tb)二、结果
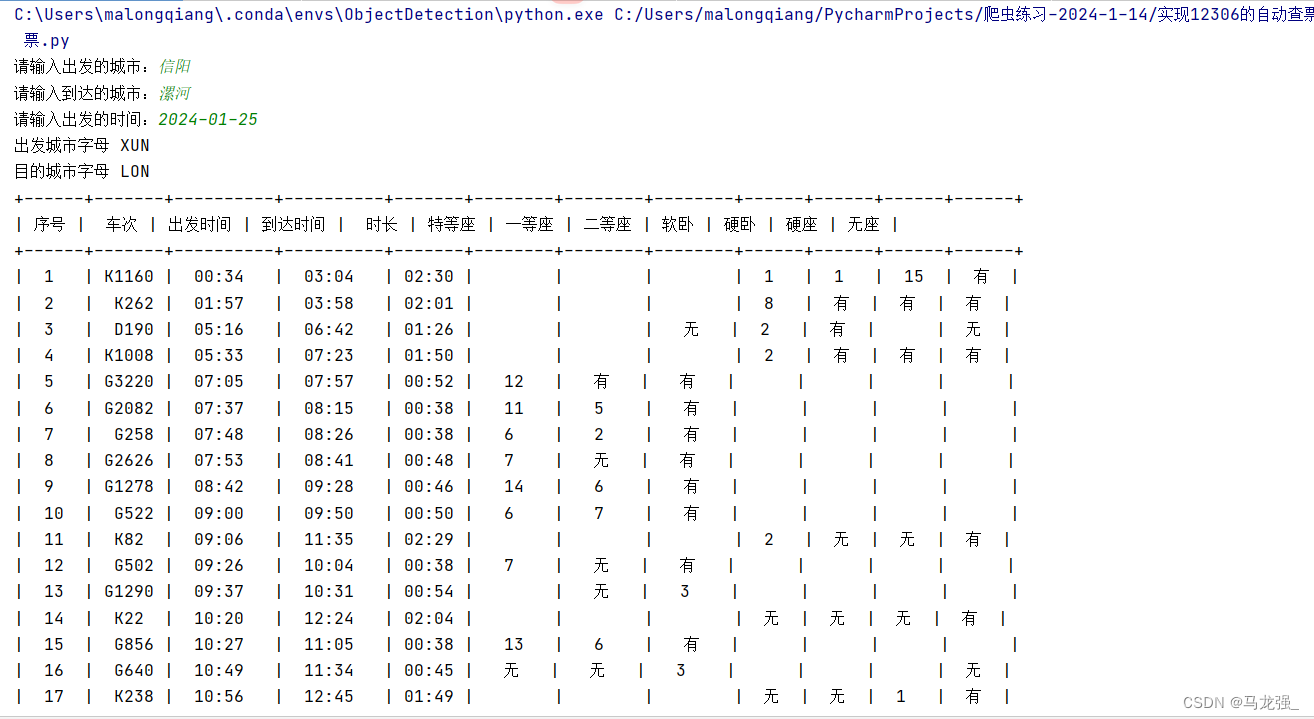

三、注意12306城市对应缩写city.json的获取
1.相关链接:12306城市名对应字母缩写 - 悟透 - 博客园 (cnblogs.com)
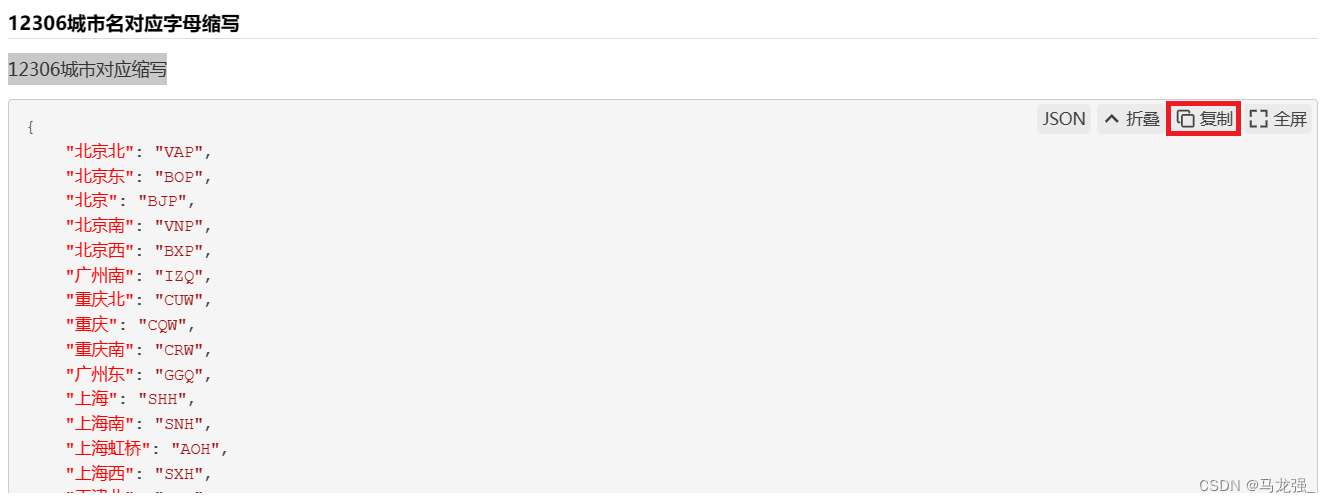
2.在桌面创建文本文件,复制内容到文本文件中,保存后,更改后缀为.json,放到与代码同级的目录中
四、过程请查看代码注释

?
文章来源:https://blog.csdn.net/m0_74972727/article/details/135780107
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [M模拟] lc670. 最大交换(模拟+贪心+技巧)
- OpenEuler校正时间、OpenEuler设置时间
- 工作每天都在用的 DNS 协议,你真的了解么?
- 使用SVM对手写体数字图片分类
- 【华为OD】C卷真题 100%通过:执行时长 python实现 [思路+源码]
- 【浏览器】-- Chrome 清除某个指定网站下的缓存
- Java SM2 国密算法(最权威)!
- Vue.js
- 风力发电机行星齿轮箱数据集 | 写论文再也不用担心没数据集啦!
- 强化学习第1天:马尔可夫过程