ASCII、GBK与UTF-8的前世今生
背景
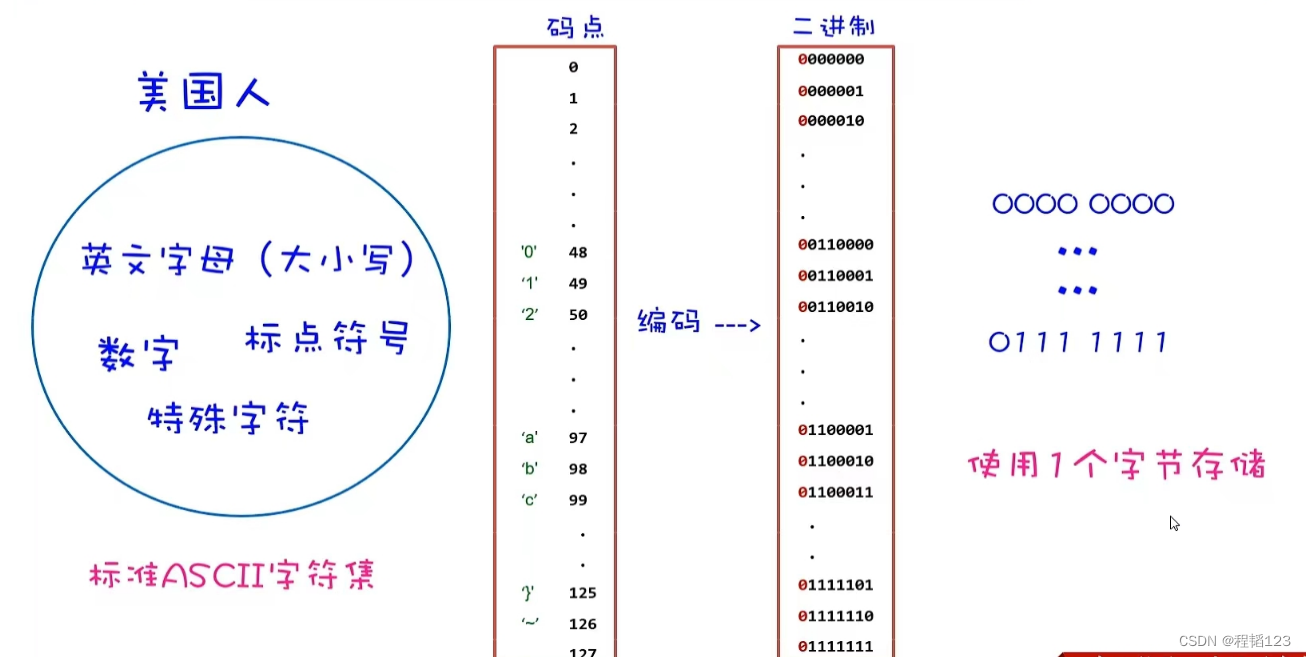
计算机是美国人发明的,美国人最初要往计算机存储数据的时候,那些数据往往只由英文字母(大小写)、数字、标点符号、特殊字符构成,总量被凑到128个。于是美国人就为这些字符编制了码点,一个字符对应一个码点,码点的范围是0~127。
于是计算机要存储的字符,会先转换为码点,码点存储在计算机中就以二进制的形式存在。由于码点用7个bit就可表示完整,于是首位bit统一设为0,一共占据了8个bit,也就是一个字节。
字符、码点、二进制数据的对应关系,也被叫做ASCII(American Standard Code for Information Interchange),美国信息交换标准代码。对于美国人来说完全够用了。
GBK
GBK,guojia biaozhun kuozhan。计算机传入中国之后,对于中国人来说,128个字符是完全不够用的,于是国家规定了汉字字符集,GBK便是其中一种。
GBK兼容了ASCII字符集的同时,还兼容了2万多个汉字,因此GBK的汉字字符集部分用2个字节存储码点。
GBK的汉字字符集对应的二进制数据除了占据2个字节,还以1开头。ascii码下的字符则保持原样。
举例:
我a你。在计算机中对应的二进制数据是:1xxxxxxx xxxxxxxx 0xxxxxxx 1xxxxxxx xxxxxxxx。
当把二进制数据转换为中文字符的之后,碰到1开头的数据,就知道要连着包括1在内的16个bit(2个字节)的数据一起转换为中文。
Unicode
Unicode,Universal Coded Character Set。是国际组织制定的,可以容纳全世界所有文字、符号的字符集。用32个bit(4个字节)表示一个字符,能完整覆盖全世界的文字与符号。
UTF-8
Unicode字符集的出发点是好的,但是太过奢侈,比如对于中文来说,用unicode的形式存储字符,每存储一个中文就比GBK多消耗2个字节。
为了解决存储空间开销过大的问题,国际组织基于unicode字符集,又推出了UTF-8字符集。·UTF-8字符集是unicode字符集分支而出的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节,按需而定。
英文字符、数字等,只占1个字节,汉字字符占用3个字节。
Utf-8的编码规则:

只占1个字节的字符,必须要以0开头。
占据2个字节的字符,第一个字节开头必须是110,第二个字节开头必须是10。
占据3个字节的字符,第一个字节开头必须是1110,第二、三个字节开头必须是10。
占据4个字节的字符,第一个字节开头必须是11110,第二、三、四个字节开头必须是10。
举例:
A我m,用utf-8编码,二进制数据如下:

乱码
以“a我m”字符串为例,存储的时候以utf-8编码,
存储为:01100001 1110xxxx 10xxxxxx 10xxxxxx 01101101
解码的时候以gbk解码:
1、计算机先分别把01100001、01101101解码为a和m,无错。
2、然后把1开头的字节解码为汉字,无法识别,无法匹配规则,产生乱码。
编码注意事项
开发人员尽量以utf-8编码。
数字和英文字符几乎不会乱码。
存储时的编码方式,和解码时候的编码方式,必须一致。
Utf-8和gbk互相转码
思路:如果想把一个字符串从一种编码方式转为另一种编码方式,先转码为unicode,然后再从unicode转为另一种编码。
用python实现gbk字符转utf-8字符串:
# 定义一个以GBK编码的字符串
gbk_string = "中文字符串".encode('gbk')
# 将以GBK编码的字符串解码为Unicode字符串
unicode_string = gbk_string.decode('gbk')
# 将Unicode字符串编码为UTF-8
utf8_string = unicode_string.encode('utf-8')
# 输出UTF-8编码的字符串
print(utf8_string.decode('utf-8'))用python实现utf-8字符转gbk字符串:
# 定义一个以utf-8编码的字符串
utf8_string = "中文字符串".encode('utf-8')
# 将以utf-8编码的字符串解码为Unicode字符串
unicode_string = utf8_string.decode('utf-8')
# 将Unicode字符串编码为GBK
gbk_string = unicode_string.encode('gbk')
# 输出gbk编码的字符串
print(gbk_string.decode('gbk'))本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【QML COOK】- 005-粒子系统(ParticleSystem)
- 双十一邮件群发最佳时间:提升营销效果与转化率的关键节点
- 使用Go编写HTTP中间件
- DC电源模块的使用范围是什么?适用于哪些应用场景?
- Java版企业电子招投标系统源代码,支持二次开发,采用Spring cloud技术
- 【Vue3练习】Vue3使用v-model以及多个v-model
- Required request body is missing报错及解决
- React与Vue性能对比
- springboot listener、filter登录实战
- ROS2如何查看某个主题是由哪个节点发布的