Flink|《Flink 官方文档 - 概念透析 - Flink 架构》学习笔记
发布时间:2023年12月31日
学习文档:概念透析 - Flink 架构
学习笔记如下:
Flink 集群剖析
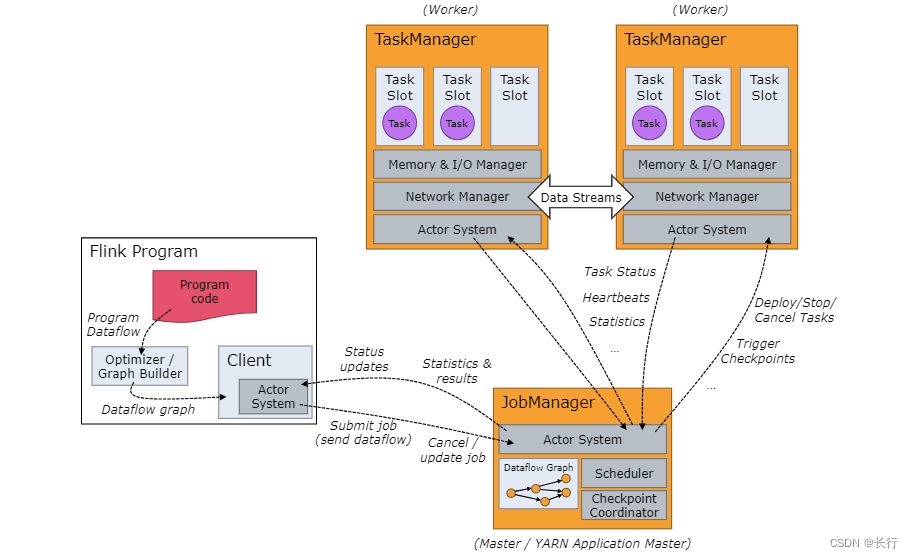
- 客户端(Client):准备数据流程序并发送给 JobManager(不是 Flink 执行程序的进程)
- JobManager:协调 Flink 应用程序的分布式执行
- ResourceManager:负责 Flink 集群中的资源提供、回收、分配
- Dispatcher:提供了用来提交 Flink 应用程序执行的 REST 接口,并为每个提交的作业启动一个新的 JobMaster;运行 Flink WebUI 用来提供作业执行信息
- JobMaster:负责管理单个 JobGraph 的执行;每个作业都有自己的 JobMaster。
- TaskManager:执行作业流的 task,并且缓存和交换数据流
- task slot:TaskManager 中资源调度的最小单位是 task slot;TaskManager 中 task slot 的数量表示并发处理 task 的数量;每个 task slot可以执行多个算子。
Tasks 和算子链
每个 task 由一个线程执行。
合并算子为算子链的原因:
- 减少线程间切换、缓冲的开销
- 减少延迟,增加整体吞吐量
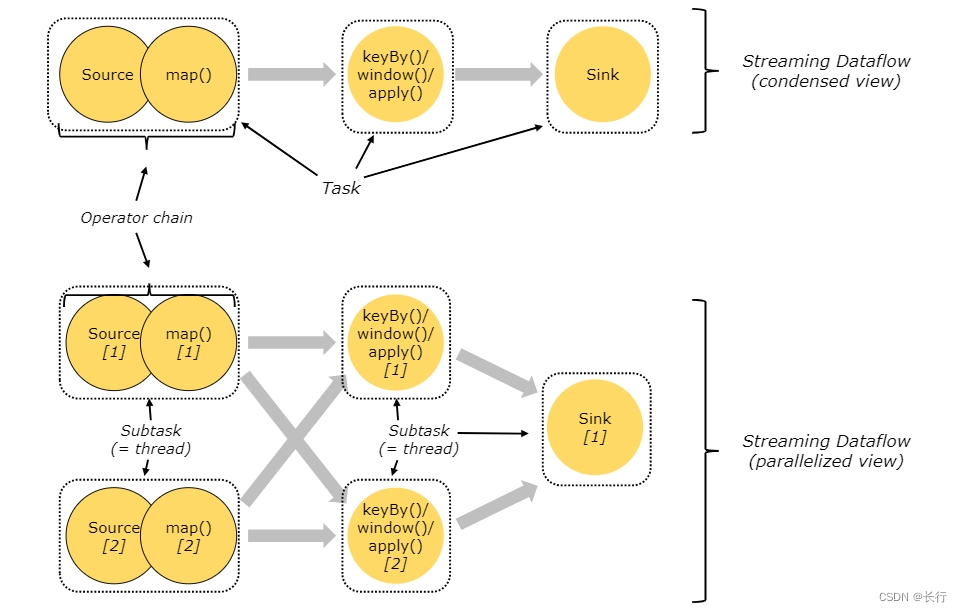
在上图中:
- source 和 map 算子被合并为算子链
- 从 parallelized view 中可以看到 5 个 subtask(每个虚线框为一个 subtask)
Task Slots 和资源
- 每个 TaskManager 是一个 JVM 进程
- 每个 subtask 是一个单独的线程
- task slot 用于管理每个 TaskManager 中能够接收的 task 数量:TaskManager 会将内存平均分给每个 task slot,但不会分隔 CPU
多个 slot 共享同一个 Taskamanger 的示例图

多个 slot 共享同一 JVM 进程的优点:共享 TCP 连接(通过多路复用)和心跳信息,共享数据集和数据结构,从而减少了每个 task 的开销
多个 subtask 共享 slot 的示例图
Flink 允许 subtask 共享 slot,即便它们是不同的 task 的 subtask,只要是来自于同一作业即可。结果就是一个 slot 可以持有整个作业管道。
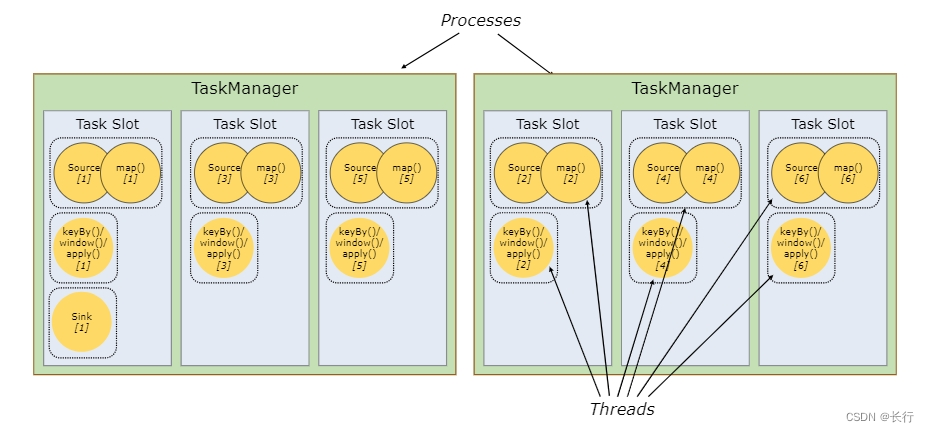
允许 slot 共享有两个主要优点:
- Flink 集群所需的 task slot 和作业中使用的最大并行度恰好一样。无需计算程序总共包含多少个 task(具有不同并行度)。
- 容易获得更好的资源利用。如果没有 slot 共享,非密集 subtask(source/map())将阻塞和密集型 subtask(window) 一样多的资源。通过 slot 共享,我们示例中的基本并行度从 2 增加到 6,可以充分利用分配的资源,同时确保繁重的 subtask 在 TaskManager 之间公平分配。
Flink 应用程序执行
Flink Session 集群
集群生命周期:
- 客户端连接到与现存在的、长期运行的集群
- 集群可以接受多个作业提交
- 即使所有作业完成后,集群(和 JobManager)仍将继续运行直到手动停止为止
- 集群寿命不受任何 Flink 作业寿命的约束
资源隔离:
- TaskManager slot 由 ResourceManager 在提交作业时分配,并在作业完成时释放
- 集群资源方面存在一些竞争 — 例如提交工作阶段的网络带宽
- 如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败
- 如果 JobManager 上发生一些致命错误,它将影响集群中正在运行的所有作业
可以节省大量时间申请资源和启动 TaskManager;适用于作业执行时间短并且启动时间长会对端到端的用户体验产生负面影响的场景。
Flink Job 集群
集群生命周期:
- 客户端首先从集群管理器请求资源启动 JobManager,然后将作业提交给在这个进程中运行的 Dispatcher,然后根据作业的资源请求惰性的分配 TaskManager
- 集群管理器(例如 YARN)为每个提交的作业启动一个集群,并且该集群仅可用于该作业
- 一旦作业完成,Flink Job 集群将被拆除
资源隔离:
- JobManager 中的致命错误仅影响在 Flink Job 集群中运行的一个作业
ResourceManager 必须应用并等待外部资源管理组件来启动 TaskManager 进程和分配资源。适用于更适合长期运行、具有高稳定性要求且对较长的启动时间不敏感的大型作业。
Flink Application 集群
集群生命周期:
- 仅从 Flink 应用程序执行作业,并且
main()方法在集群上而不是客户端上运行 - 在提交作业时,将应用程序逻辑和依赖打包成一个可执行的作业 JAR 中,并且集群入口(
ApplicationClusterEntryPoint)负责调用main()方法来提取 JobGraph - Flink Application 集群的寿命与 Flink 应用程序的寿命有关
资源隔离:
- ResourceManager 和 Dispatcher 作用于单个的 Flink 应用程序
文章来源:https://blog.csdn.net/Changxing_J/article/details/135266706
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【乱七八糟的经验】【个人】打羽毛球如何球球都接稳
- 美国智库发布《用人工智能展望网络未来》的解析
- k8s的陈述式资源管理:
- zabbix监控端口是否打开,被监控主机不需要安装zabbix-agent
- PIG框架学习3——Redisson 实现业务接口幂等
- Vim 用法详解
- 零信任数据安全深研与创新实践,美创论文入选中国科技核心期刊
- 安达发APS|排产软件中超级BOM的应用价值和优势
- facebook广告有哪些获客方式?
- 服务器出现500、502、503错误的原因以及解决方法