RDD算子——转换操作(Transformations )【剩余操作】
发布时间:2024年01月09日
-
mapPartitions

-
mapPartitions操作# (1) @Test def mapPartitions(): Unit = { // 1. 数据生成 // 2. 算子使用 // 3. 获取结果 sc.parallelize(Seq(1, 2, 3, 4, 5, 6),2) .mapPartitions( iter => { iter.foreach(item => println(item)) iter // 传进来要求集合,返回要求是另一个集合,所以传出去也要是集合 })//传递的函数要是迭代器(iterator) .collect() } # (2) @Test def mapPartitions2(): Unit = { // 1. 数据生成 // 2. 算子使用 // 3. 获取结果 sc.parallelize(Seq(1, 2, 3, 4, 5, 6),2) .mapPartitions( iter => { // 遍历 iter 其中每一条数据进行转换,转换完以后,返回这个 iter // iter 是 scala 中的集合类型 iter.map(item => item * 10) // scala 中的 map 返回值是另一个Iterator,刚好有作为最后一行,即满足传进来的是集合,传出去的也是 })//传递的函数要是迭代器(iterator) .collect() .foreach(item => println(item)) }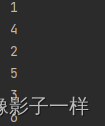
-
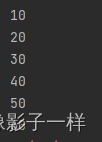
mapPartitionsWithIndex操作@Test def mapPartitionsWithIndex(): Unit = { sc.parallelize(Seq(1, 2, 3, 4, 5, 6),2) .mapPartitionsWithIndex((index, iter) =>{ // 传分区和iterator println("index: "+ index ) iter.foreach(item => println(item)) iter }) .collect() }
-
总结
- map 和 mappartitions的区别
- mapPartitions和map算子是一样的,只不过map是针对每一条数据进行转换,mappartitions是针对一整个分区的数据进行转换。
- 所以map的func参数是单条数据,mappartitions的func参数是一个集合,func的参数是一个集合,一个分区整个的所有数据,
- map的func返回值也是单条数据,mappartitions的func的返回值是一个集合
- mappartitions和mappartitionsindex的区别
- 区别是mappartitionsindex中的func中多了一个参数,是分区号
- map 和 mappartitions的区别
-
-
filter
-
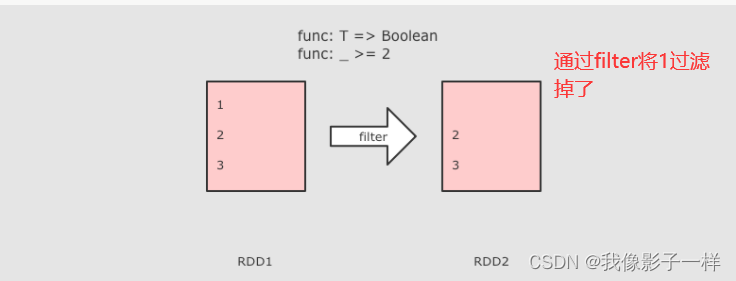
filter操作- filter 可以过滤掉数据集中一部分元素
- filter 中接收的函数,参数是每一个元素,如果这个函数返回ture, 当前元素就会被加入新数据集,如果返回f1ase,当前元素会被过滤掉
@Test def filter(): Unit = { // 1.定义集合 // 2. 过滤数据 // 3. 收集结果 sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) .filter( item => item % 2 ==0) // 取出偶数 .collect() .foreach( item => println(item)) }
-
-
sample(不需要接收任何函数)(是随机的。主要用于随机采样)

sample操作-
作用
Sample算子可以从一个数据集中抽样出来一部分,常用作于减小数据集以保证运行速度,并且尽可能少规律的损失
-
参数
- Sample接受第一个参数为
withReplacement, 意为是否取样以后是否还放回原数据集供下次使用,简单的说,如果这个参数的值为true,则抽样出来的 数据集中可能有重复 - Sample接受第二个参数为
fraction,意为抽样的比例 - Sample 接受的第三个参数为
seed随机种子,用于Sample 内部随机生成
- Sample接受第一个参数为
-
code
@Test def sample(): Unit = { // 1.定义集合 // 2. 随机抽样数据 // 3. 收集结果 val rdd1 = sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) val rdd2 = rdd1.sample(false, 0.6) // false,不放回 val result = rdd2.collect() result.foreach( item => println(item)) }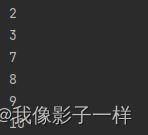
-
-
mapValues
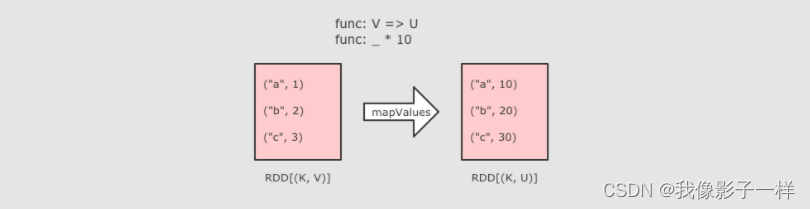
mapValues操作-
作用
- MapValues 只能作用于Key-Value型数据,和Map类似,也是使用函数按照转换数据,不同点是MapValues只转换Key-Value中的Value
-
code
@Test def mapValues():Unit = { sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3))) .mapValues( item => item * 10) // 只有 Value * 10 了 .collect().foreach( item => println(item)) }
-
-
集合操作
-
intersection(交集)-
code
@Test def intersection(): Unit = { val rdd1 =sc.parallelize(Seq(1, 2, 3, 4, 5)) val rdd2 =sc.parallelize(Seq(3, 4, 5, 6, 8)) rdd1.intersection(rdd2) .collect() .foreach(println(_)) }
-
-
union(并集)-
code
@Test def union(): Unit = { val rdd1 =sc.parallelize(Seq(1, 2, 3, 4, 5)) val rdd2 =sc.parallelize(Seq(3, 4, 5, 6, 8)) rdd1.union(rdd2) .collect() .foreach(println(_)) }
-
-
subtract(差集)-
code
@Test def subtract(): Unit = { val rdd1 =sc.parallelize(Seq(1, 2, 3, 4, 5)) val rdd2 =sc.parallelize(Seq(3, 4, 5, 6, 8)) rdd1.subtract(rdd2) .collect() .foreach(println(_)) }
-
-
-
groupByKey
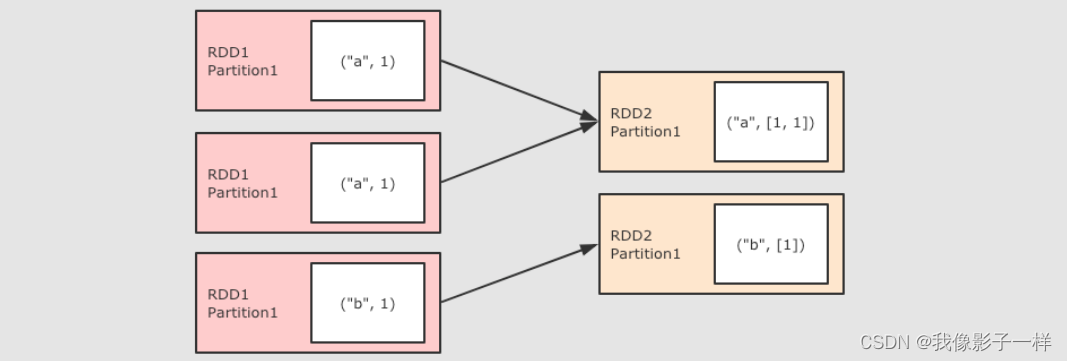
groupByKey操作-
作用
- GroupByKey 算子的主要作用是按照Key分组,和ReduceByKey有点类似,但是GroupByKey并不求聚合,只是列举Key对应的所有Value
-
注意点
- GroupByKey 是一个Shuffled
- GroupByKey 和 ReduceByKey 不同,因为需要列举 Key 对应的所有数据,所以无法在Map端做Combine,所以GroupByKey的性能并没有ReduceByKey好
-
code
@Test def groupByKey(): Unit = { sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1))) .groupByKey() .collect() .foreach( item => println(item)) }有无异议看其是否能减少I/O

-
-
combinerByKey ( groupByKey 和 reduceByKey 都是以他为底层)
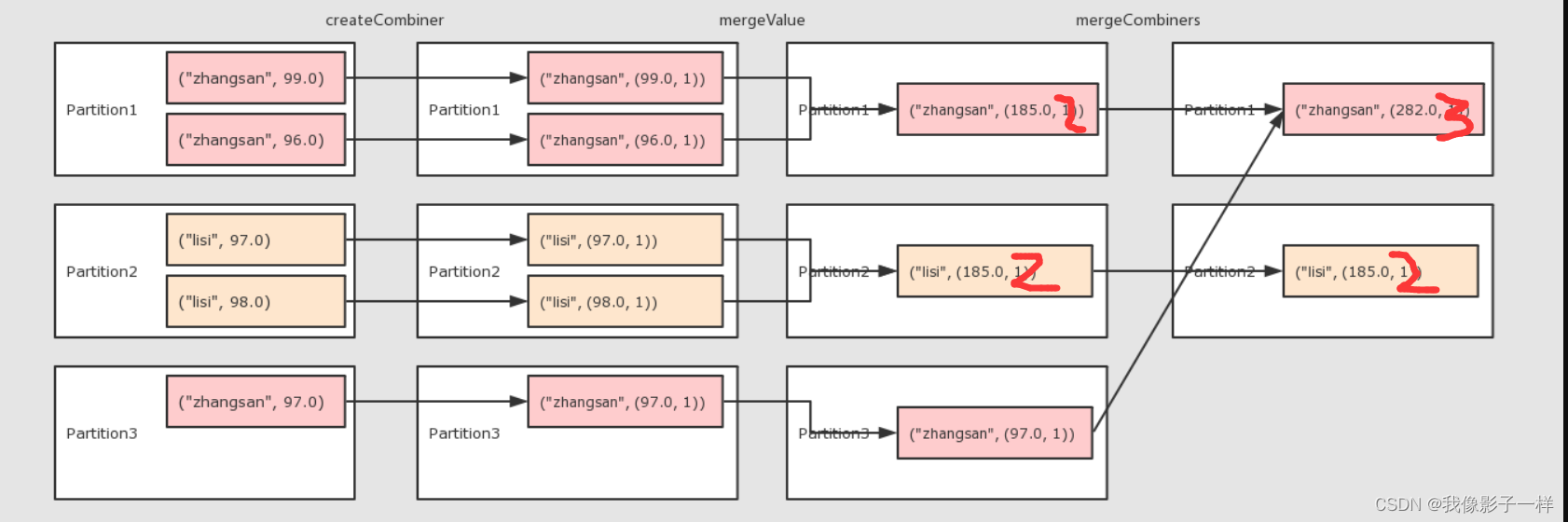
combinerByKey操作-
作用
- 对数据集按照 Key 进行聚合
-
调用
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
-
参数
createCombiner将 Value 进行初步转换mergeValue在每个分区把上一步转换的结果聚合mergeCombiners在所有分区上把每个分区的聚合结果聚合partitioner可选, 分区函数mapSideCombiner可选, 是否在 Map 端 Combineserializer序列化器
-
注意点
combineByKey的要点就是三个函数的意义要理解groupByKey,reduceByKey的底层都是combineByKey
-
code
@Test def combinerByKey(): Unit = { // 1. 准备集合 val rdd: RDD[(String, Double)] = sc.parallelize(Seq( ("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)) ) // 求以上同学成绩的平均数 // 2. 算子操作 // 2.1 createCombiner 转换数据 // 2.2 mergeValue 分区上聚合 // 2.3 mergeCombiners 把所有分区上的结果再次聚合 val combinerResult = rdd.combineByKey( createCombiner = (curr: Double) => (curr, 1), // 先操作第一项 ("zhangsan", 99.0), mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1), // 上面处理后直接到这来处理第二项 ("zhangsan", 96.0), mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2) // Double相加,Int相加 ) // combinerResult: (lisi,(195.0,2)),(zhangsan,(292.0,3)) (“name”,(分数,次数)) val resultRDD = combinerResult.map(item => (item._1, item._2._1 / item._2._2)) // 3. 获取结果,打印数据 resultRDD.collect().foreach(println(_)) }
-
结论
- combinByKey接收三个函数。
- 初始函数, 转换函数,作用于第一条数据,用于开启整个计算
- 在分区上进行计算聚合
- 把所有分区的聚合结果聚合为最终的结果
- combinByKey接收三个函数。
-
-
foldByKey(与reduceByKey的区别是。他有一个初始值,reduceByKey的初始值是0)
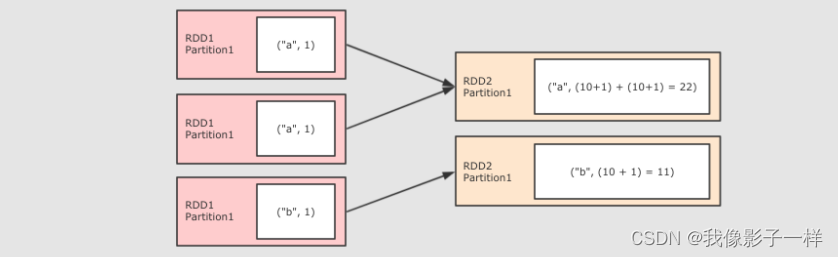
foldByKey操作-
作用
- 和ReduceByKey 是一样的,都是按照 Key 做分组去求聚合,但是 FlodByKey的不同点在于可以指定初始值
-
调用
foldByKey(zeroValue) (func)
-
参数
zeroValue初始值func seqOp和combOp相同,都是这个参数
-
code
@Test def flodByKey():Unit={ sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1))) .foldByKey(zeroValue = 10)( (curr, agg) => curr + agg )//第一个函数传入初始值。第二个传入聚合的规则 .collect() .foreach(println(_)) } }
-
-
aggregateByKey (这个是foldByKey的底层)

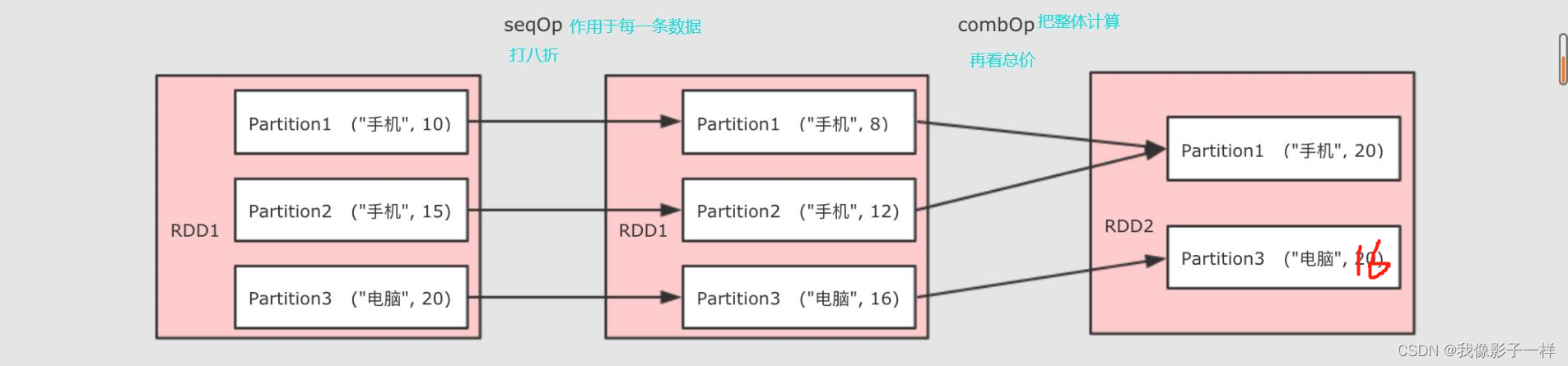
aggregateByKey操作-
作用
- 聚合所有 Key 相同的 Value, 换句话说, 按照 Key 聚合 Value
-
调用
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
-
参数
zeroValue初始值seqOp转换每一个值的函数comboOp将转换过的值聚合的函数
-
注意点
- 为什么需要两个函数?
aggregateByKey运行将一个RDD[(K, V)] 聚合为 RDD[(K, U)], 如果要做到这件事的话, 就需要先对数据做一次转换, 将每条数据从V转为U,seqOp就是干这件事的 , 当seqOp的事情结束以后,combOp把其结果聚合 - 和 reduceByKey 的区别:
- aggregateByKey 最终聚合结果的类型和传入的初始值类型保持一致
- reduceByKey 在集合中选取第一个值作为初始值, 并且聚合过的数据类型不能改变
- 为什么需要两个函数?
-
code
@Test def aggregateByKey(): Unit = { // 东西要打八折 val rdd = sc.parallelize(Seq(("手机", 10), ("手机", 15), ("电脑", 20))) rdd.aggregateByKey(0.8)( seqOp = (zeroValue, price) => price * zeroValue, combOp = (curr, agg) => curr + agg) .collect() .foreach(println(_)) } }
-
-
join
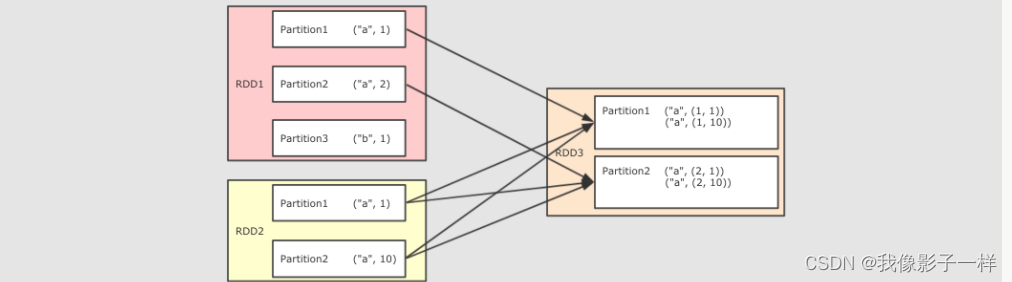
join操作-
作用
- 将两个 RDD 按照相同 Key 进行连接
-
调用
join(other,[partitioner or numPartitions])
-
参数
- other 其它 RDD
- partitioner or numPartitions可选,可以通过传递分区函数或者分区数量来改变分区
-
注意点
- Join 有点类似于 SQL 中的内连接,只会再结果中包含能够连接到的 Key
-
code
@Test def join(): Unit = { val rdd1 = sc.parallelize(Seq(("a",1),("a",2),("b",1))) val rdd2 = sc.parallelize(Seq(("a",10),("a",11),("a",12))) rdd1.join(rdd2) .collect() .foreach(println(_)) } }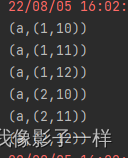
-
-
sortBy 和 sortByKey(两个与排序有关的算子)
sortBy和sortByKey操作-
作用
- 排序相关相关的算子有两个,一个是
sortBy,另外一个是sortByKey
- 排序相关相关的算子有两个,一个是
-
调用
sortBy(func,ascending,numPartitions)
-
参数
func通过这个函数返回要排序的字段ascending是否升序numPartitions分区数
-
注意点
- 普通的 RDD 没有
sortByKey,只有 Key-Value 的RDD 才有 sortBy可以指定按照哪个字段来排序,sortByKey直接按照Key来排序
- 普通的 RDD 没有
-
code
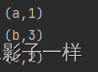
@Test def sort(): Unit = { val rdd1 =sc.parallelize(Seq(2, 4, 1, 5, 8)) val rdd2 =sc.parallelize(Seq(("a", 1), ("b", 3), ("c" ,2))) rdd1.sortBy( item => item).collect().foreach(println(_)) // 1 2 4 5 8 rdd2.sortBy(item => item._2).collect().foreach(println(_)) // (a,1) (c,2) (b,3) rdd2.sortByKey().collect().foreach(println(_)) //(a,1) (b,3) (c,2) }

-
总结
- sortBy 可以作用于任何类型的数据的 RDD,sortByKey 只有KV类型的数据的 RDD 中才有
- sortBy 可以按照任何部分来排序,sortByKey 只能按照Key排序
- sortByKey 写法简单,不用编写函数了
-
-
repartition 和 coalesce重分区(都是改变分区数)
repartition和coalesce重分区操作-
作用
- 一般涉及到分区操作的算子常见的有两个,
repartitioin和coalesce, 两个算子都可以调大或者调小分区数量
- 一般涉及到分区操作的算子常见的有两个,
-
调用
repartitioin(numPartitions)coalesce(numPartitions, shuffle)
-
注意点
repartition和coalesce的不同就在于coalesce可以控制是否 Shufflerepartition是一个 Shuffled 操作
-
code
@Test def partitioning(): Unit = { // 改变分区数 val rdd = sc.parallelize(Seq(2, 4, 1, 5, 8),2) // repartition println(rdd.repartition(5).partitions.size) //repartition可大 println(rdd.repartition(1).partitions.size) //repartition可小 // coalesce println(rdd.coalesce(1).partitions.size) // coalesce可小但是不可大(变大之后还是原来的2) println(rdd.coalesce(5,shuffle = true).partitions.size) //设置shuffle = true之后coalesce可大 }
-
-
转换操作总结
- 转换:map、mapPatrtitions、mapValues
- 过滤:filiter、sample
- 集合操作:intersection、union、subtract
- 聚合操作:reduceByKey、groupByKey、combinByKey、foldByKey、aggregateByKey、sortBy、sortByKey
- 重分区:reparititions、coalesce
- 所有转换操作的子都是惰性的在执行的时候并不会真的去调度运行,求得结果,而是只生成了对应RDD
- 只有在 Action 操作的时候,才会真的运行求得结果
文章来源:https://blog.csdn.net/m0_56181660/article/details/135465238
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Axure骚操作:【制作可暂停与不可暂停进度加载条】
- 服务器磁盘挂载及格式化
- Gitee生成SSH 公钥
- 基于方差分解分析气象/水文干旱驱动因素(含MATLAB全代码)
- 47. 全排列 II - 力扣(LeetCode)
- 程序媛的mac修炼手册-- Pycharm小技巧(一)
- linux网络配置
- vue项目配置后端地址
- 分布式IO在工业自动化中的应用
- Spring ‘24:不容错过的Salesforce Flow 10大新功能!