基于TGI的大模型推理框架适配之昇腾部署
发布时间:2024年01月03日
docker run -it -u root --ipc=host --network host --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /etc/localtime:/etc/localtime -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v /var/log/npu/:/usr/slog -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi -v /home/test:/home/test --name llama13B_910B swr.cn-central-221.ovaijisuan.com/wuh-aicc_dxy/pytorch_kernels:PyTorch_1.11-cann7.0rc1_py_3.9-euler_2.8.3-d910b-1201-test /bin/bash
痛点:
LLM 高并发部署,要求高吞吐,用户体验好(如模型生成文字速度快,用户排队时间缩短)
解决方案
vllm 和 TGI 等(昇腾的AscendIE、MindIE等推理加速引擎)
————————————————————————————————————————————————————————
本文重点介绍下TGI
优势:
- 支持 continuous batching
- 支持flash-attention 和 Paged Attention
- 支持Safetensors 权重加载
- 支持部署 GPTQ 模型服务(量化)

Router和Server是最重要的组件
若干个客户端同时请求Web Server的“/generate”服务后,服务端会将这些请求在“Buffer”组件处整合为Batch,并通过gRPC协议转发请求给GPU推理引擎进行计算生成。至于将请求发给多个Model Shard,多个Model Shard之间通过NCCL通信,这是因为显存容量有限或出于计算效率考虑,需要多张GPU进行分布式推理
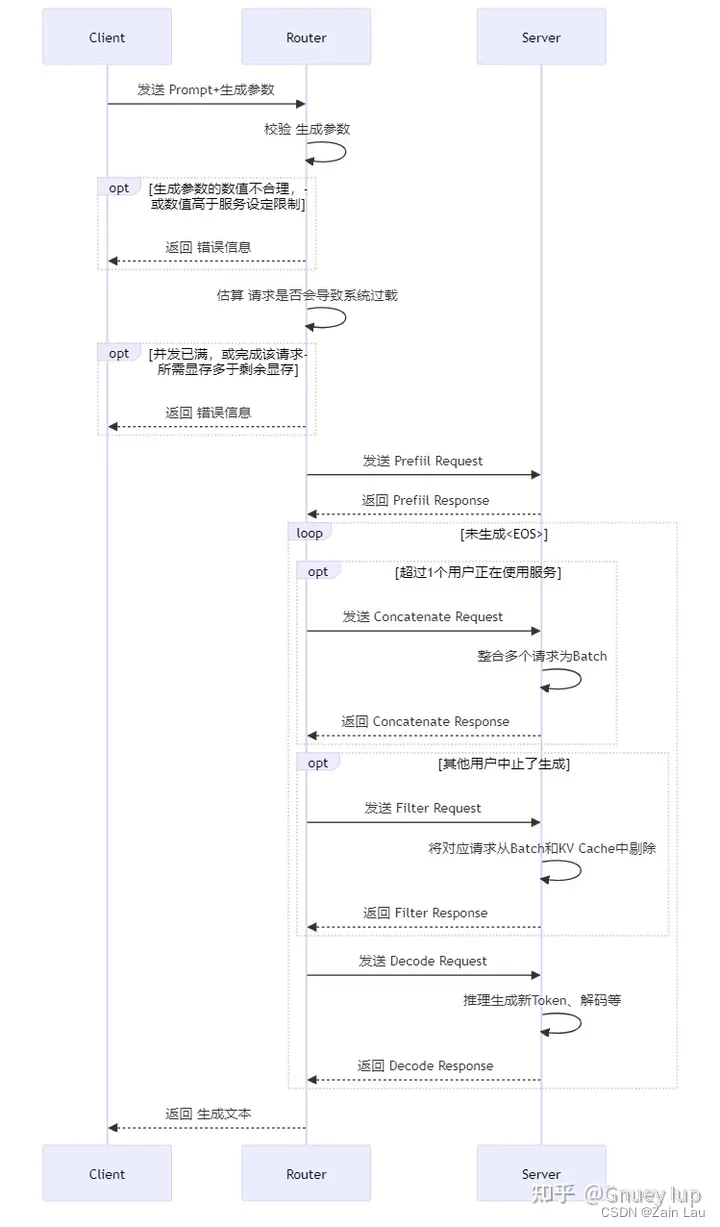
Router和Server的4种交互(Prefill、Decode、Concatenate、Filter)是大模型推理的核心业务逻辑
文章来源:https://blog.csdn.net/weixin_44659309/article/details/134800568
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!