数据库-数据结构
发布时间:2024年01月13日
数据库-数据结构
一、B-树、B+树、B*树
搜索树:左子节点<节点<右子节点。
B-树:多路搜索树。
B+树:B-树的变体,更适用于文件系统,如mysql数据库。具体的,适合通过叶子节点的链指针进行区间查找。
B*树:B+树变体,提高了空间使用率
1
/
2
→
2
/
3
1/2→2/3
1/2→2/3。
参考文章:一文详解 B-树,B+树,B*树
1 B-树
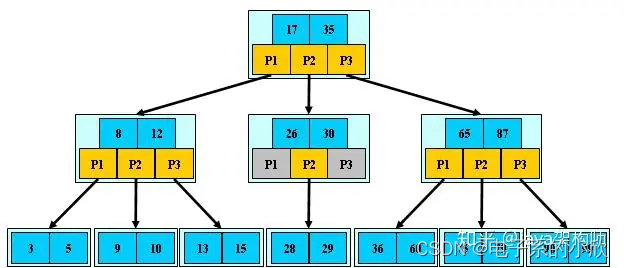
对于一颗m阶B-树(上图m=3)
特点:
- 根节点至少有2个子节点,或者为空树。
- 非叶子节点的子节点数k: ? m / 2 ? ≤ k ≤ m \lceil m/2\rceil ≤k≤m ?m/2?≤k≤m。当一个节点满了,分配一个新节点,把原节点一半的数据移动到新节点,并将该新节点加入到父节点中。此时改动只有该满的节点和其父节点。
- 非叶子节点的关键字数j: j = k ? 1 j=k-1 j=k?1。
- 叶子节点在同一层。
- 对于某个节点的关键字K[1],K[2]…K[M-1],K[i]<K[i+1]。
- 对于某个非叶子节点的指针P[1],P[2]…P[M],P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其他的P[i]指向关键字在范围(K[i],K[i+1])的子树。
- 关键字分布在整棵树。
- 搜索过程中可能在非叶子节点结束。时间复杂度等于一次二分查找。
2 B+树
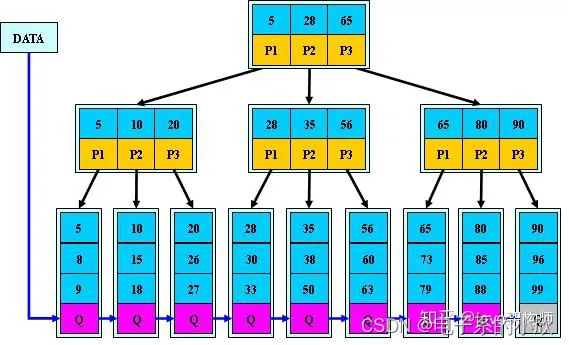
对于一颗m阶B+树(上图m=3)
与B-树的不同:
- 应文件系统所需的B-树变体。
- 非叶子节点的关键字个数j: j = k j=k j=k。
- 关键字不保存数据,仅用于索引。数据保存在叶子节点。
- 对于某个非叶子节点的指针P[1],P[2]…P[M],P[i]指向关键字在范围[K[i],K[i+1])的子树。
- 所有叶子节点由一个链指针链接起来。
- 关键字分布在叶子节点。
- 搜索过程中得到叶子节点才结束。时间复杂度仍然等于一次二分查找。
3 B*树
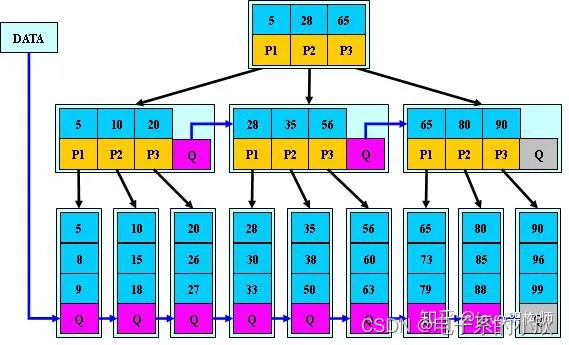
对于一颗m阶B*树(上图m=3)
与B+树的不同:
- 在非根非叶子节点的层增加了兄弟指针。
- 非叶子节点的子节点数k: ? 2 m / 3 ? ≤ k ≤ m \lceil 2m/3\rceil ≤k≤m ?2m/3?≤k≤m,原先是 ? m / 2 ? ≤ k ≤ m \lceil m/2\rceil ≤k≤m ?m/2?≤k≤m,提高了块的最低使用率。当一个节点满了,根据兄弟指针检查兄弟节点是否满了,未满则将一部分数据移动到兄弟节点;如果满了则分配一个新节点,把原节点和兄弟节点各自 1 / 3 1/3 1/3的数据移动到新节点,并将该新节点加入到父节点中。此时改动有该满的节点、其父节点、兄弟节点、兄弟指针。
文章来源:https://blog.csdn.net/weixin_45034895/article/details/135570060
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年开启重学前端和深入浅出系列
- 编程笔记 html5&css&js 043 CSS尺寸属性
- 欢迎来到Web3.0的世界:常见的DeFi黑客攻击
- 整除的特征及解释
- 《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(7)
- FTP文件传输与vsftpd配置
- redisson分布式锁实现方式
- 2023年中国充电桩激增89万!但布局不够完善,提升潜力大
- 代码随想录算法训练营第60天|● 84.柱状图中最大的矩形
- 视角与焦距