用pandas实现用前一行的excel的值填充后一行
发布时间:2024年01月19日
今天接到一份数据需要分析,数据在一个excel文件里,内容大概形式如下:

后面空的格子里的值就是默认是前面的非空的值,由于数据分析的需要需要对重复的数据进行去重,去重就需要把控的cell的值补上,然后根据几个关键的cell的值计算一个唯一的key, 类似如下:
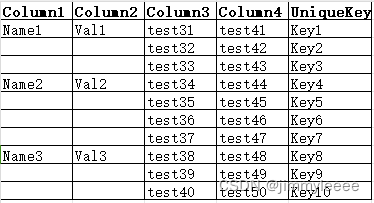
如果UniqueKey有重复的,就可以通过Excel的去重复数据的功能,直接将重复的行去掉。
接下来就需要一个简单的方法,把后面的空的cell的内容填上,这样通过公式计算UniqueKey时,就可以很容易。虽然Excel也提供了可以使用其他的Cell的值填充空白Cell的值,但是操作步骤有点作,而且对于操作有几千上万行的excel文件来说,太不方便,万一出错,就需要重来一遍。
正好学习了pandas库,发现用它的dataframe可以很轻松地实现。
Python代码如下:
import pandas as pd
data_file = "F:\\1.xlsx"
data_info = pd.read_excel(data_file)
data_info.fillna(method="ffill", inplace=True)
data_info.to_excel("2.xlsx")代码运行之后,打开输出文件,内容如下:
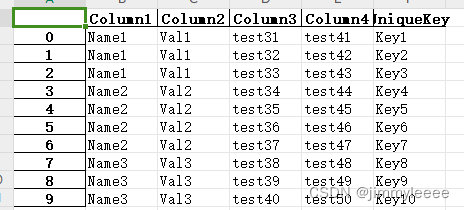
几行代码就可以轻松搞定几万行的文件的数据处理!
文章来源:https://blog.csdn.net/jimmyleeee/article/details/135676933
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java编程强化练习(三)
- R语言【paleobioDB】——pbdb_ref_taxa():根据输入的类群返回原始文献的信息
- Redis高并发分布式锁
- whale-quant 学习 part2:金融市场的基本概念
- 【MySQL】utft8mb4 字符集及其排序规则(字符集校验规则)
- Python多元线性回归sklearn
- zkSend — — 在Sui上发红包像发电子邮件一样简单
- 【KMP】【二分查找】【C++算法】100207. 找出数组中的美丽下标 II
- 深入理解PyTorch中的Hook机制:特征可视化的重要工具与实践
- 23/76-LeNet