第三次面试总结 - 吉云集团 - 全栈开发
🧸欢迎来到dream_ready的博客,📜相信您对专栏 “本人真实面经” 很感兴趣o?(ˉ▽ˉ;)
目录
11、left join 、right join 和 inner join
总结(非详细)
- 面试结果:非常好
- 面试内容:全面,Java基础、MySQL、项目
- 原因:先下面试,问的也都有所了解,不过MySQL稍弱
面试内容(提问内容) - 带答案
- continue、break、return有什么区别
- 讲讲Java的集合
- 迭代器与循环的区别
- 讲一下AOP
- 保存用户相关文件中文件名相关的操作
- 下载文件(上传和下载)的逻辑和后端的处理方式
- 讲项目,基于项目提问
- MySQL中的limit
- MySQL中的排序和分组
- 如果A字段升序,B字段降序,写个SQL该如何写
- left join 、right join 和 inner join
1、continue、break、return有什么区别
在Java中, continue、break、return 是控制流关键字,它们的作用和用法大有差别
这里引入一下控制流关键字的概念,控制流关键字是编程语言中用于控制程序执行流程的关键字或语句。这些关键字通常用于改变程序的执行顺序或决定代码块是否执行的方式。控制流关键字无处不在,不止 continue、break、return,像 for、while等也都是控制流关键字,只是平常我们不太在意 “控制流关键字” 这个专用名词
回到我们原来的问题上
三者的区别我们从两方面开始进行讲解
首先呢,是使用场景上:
- return用于方法中 ,可以说方法中绝大部分场景和位置都可以使用,当然,有些特殊情况,比如在一个代码块里,原本已经有 return 了,又在后面加个return,这当然会报错
- 而continue只可以用在循环语句中
- break不仅可以用在循环语句中,也可以用在 switch 语句中
当然,这些使用场景说的是绝大部分的情况下,有些太少见了,我也就没提,不过我依稀记得是存在其他很偏门的用法的
其次,是作用上:
- return 用于结束方法的执行,并返回对应的结果
- continue 表示跳过本次循环 continue 位置后面剩余的代码,直接进行下一次循环
- break 表示退出整个循环 或 “switch” 结构
2、讲讲Java的集合
Java集合分三种,分别是 List、Set、Map,这三种集合适用于不同的场景
- List:适用于有序,可重复的集合
- Set:适用于不可重复集合
- Map:适用于键值对的存储
注:通常List与Map最为常用
- List 常见的实现类:ArrayList(列表) ?、 LinkedList(链表)
- Set 常见的实现类:HashSet、LinkedHashSet和TreeSet
- Map 常见的实现类:HashMap 、 TreeMap 与 HashTable
上面的实现类大多都是线程不安全的,因此,Java也提供了对应的线程安全版本:
- 比如 List 中的 Victor、CopyOnWriteArrayList等
- Set本身就用的少,所以线程安全的Set实体类用的更少,我确实没太记得住,个人感觉记这个不如到时候查询性价比高(面试可以这样说,一般不会让面试官感觉你不会)
- 比如Map中的HashTable,当然这个太古老了,用的很少,但是另一个 ConcurrentHashMap 用的非常多,ConcurrentHashMap 也是线程安全的,当然,也有其他实现方式,看具体使用情况选择合适的实现类就好
3、迭代器与循环的区别
首先,来看一下使用迭代器的代码 (这个代码是给读者看的)
import java.util.ArrayList;
import java.util.Iterator;
public class IteratorExample {
public static void main(String[] args) {
// 创建一个列表
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
// 获取列表的迭代器
Iterator<String> iterator = list.iterator();
// 使用迭代器遍历列表元素
while (iterator.hasNext()) { // 检查是否还有下一个元素
String element = iterator.next(); // 获取下一个元素
System.out.println(element);
}
}
}
可以看到,迭代器也有着循环的功能
迭代器和循环都用于遍历数据集合,但有几点不同之处
3.1、本质:
循环是编程语言提供的结构,用于重复执行一段代码,例如 for、while、foreach 等。它需要手动控制迭代次数和终止条件
迭代器是一种对象,提供了对集合元素的顺序访问,它可以遍历集合并获取下一个元素。迭代器提供了一种统一的方式来访问不同类型集合的元素,例如列表、集合、映射等
3.2、使用方式
循环通常需要在代码中显式编写,使用特定的循环结构来遍历集合中的元素
迭代器是集合类提供的一种机制,可以通过 “iterator()” 方法获取迭代器对象,然后使用迭代器的方式来访问集合中的元素,如 hasNext()、next()
3.3、使用场景:
循环适用于已知循环次数或特定条件下的重复执行。在编码中,循环结构被直接嵌入到程序中
迭代器更适用于需要逐个处理集合元素,但不需要知道具体集合大小或索引的情况。它提供了一种统一的方式来处理不同类型的集合,使得代码更加灵活
总体而言,循环是编程语言的一部分,用于重复执行代码块,而迭代器是一种抽象的集合遍历机制,提供了对集合元素的顺序访问,可以被循环或者其他遍历方式使用
这里写的特别八股文,需要转换成自己的语言才能给面试官讲哦
4、讲一下AOP
注:这里我就主要以自己的语言阐述,方便大家理解,但会少一些关键的回答,官方的回答直接gpt就行。我这里主要还是让大家理解为主,能给面试官交一份起码及格的答卷
AOP是一种思想,也就是所谓的 “面向切面编程”,其实这里有些见字知意,面向 “切面” 嘛,程序或功能的一整个方面。简单来说,面向切面编程就是做一些功能上的统一处理,这个功能大部分情况下指的是与核心业务逻辑关系不大,但会影响多个模块的功能或特性的方面。
因此,我们将这部分功能(方面) 单独拎出来,做一下同意功能的处理,使代码更模块化、易于维护和理解,也可以实现代码的重用
其实,AOP中有很多专业名词,包括刚才我们讲的 “统一功能”,它更专业的名字叫做 “横切关注点”,像日志记录、安全、事务管理、异常处理、性能监控等都是常见的横切关注点。
当然,也有其他专业名词,比如 切面、连接点、通知、切点。
在AOP中:
- 切面是横切关注点的模块化实现。
- 连接点是在应用程序执行过程中可以应用切面的点,例如方法执行、异常处理等。
- 通知是在连接点上执行的动作,如在方法执行之前或之后执行特定代码
- 切点是连接点的集合,确定切面将被应用的位置
这几个专业名字固然拗口和难理解,但总得有些八股嘛,后续我找到更容易理解的解释会回来将这里改一下
最后呢,结合以上讲解,其实AOP意在解决在传统面向对象编程中难以处理的一些问题,刚才也都有讲到,这里总结一下,主要涉及以下几个方面:模块化横切关注点, 切面、连接点、通知、切点, 横切关注点的重用 、 提高可维护性和扩展性
在Java中,常用的AOP实现框架包括Spring AOP 和 AspectJ,它们提供了丰富的功能和注解,允许开发者轻松地使用AOP这种编程范式
5、保存用户相关文件中文件名相关的操作
注:文件名的注意事项有很多,我会一一列举,大家可以不全记住,只要给面试官讲上几个重要的即可
首先,前端将文件传过来后,咱们可以将文件进行保存,保存到项目中相对路径,绝对路径,或者保存到数据库中都可以,但实际场景还是保存到相对路径或绝对路径,毕竟文件多的话,会大大影响数据库的效率,数据库可以保存对应文件的位置
这里主要对文件名进行讲解
最重要的是 文件名唯一,处理方法有很多,比如在文件名中添加随机字符串或者使用UUID等确保文件名的唯一性,避免文件名冲突
其次就是文件名的规范,安全,长度限制,编码等
规范主要是确保文件名符合系统或业务规划,比如加上统一的字符串前缀等等
这里主要对安全再做下讲解,对于用户输入的文件名,要进行安全验证和过滤,防止恶意代码或路径遍历攻击,确保文件名不会引发安全风险
总的来说,文件名相关的操作需要谨慎处理,确保安全性、唯一性和合法性,并且要考虑到文件系统和数据库的特性,以及用户体验
6、下载文件(上传和下载)的逻辑和后端的处理方式
注:这个我没有实操过,仅有过图片提交给后端保存和后端返回给前端的经验,并没有各种类型文件的操作,这里讲的答案 仅供参考
首先,我们可以使用Java中相关的库和模块,例如 FileInputStream、FileOutputStream,文件的输入输出流,然后文件的类型有 MultipartFile 等,可以根据实际需要选择实际的返回类型
然后呢,上传的方式有很多,满足多元化的上传需要,比如有的文件特比大,就可以采取分片上传这种方法,当然,也有秒传、大文件上传、断点续传等上传的方式,下载的话也有断点下载和多线程下载等多种方式
7、讲项目,基于项目提问
项目嘛,我在这里写出来,你们的参考意义也不大,就不在这里赘述了
不过有个小技巧,像前面有些问题我很多都会说这个知识点在我项目哪里哪里也用到了,这也是个加分项
8、MySQL中的limit
在MySQL中,limit 用于限制查询结果集返回的行数,通俗点讲,limit就是用于指定查询结果返回的条数,比如在原本的 select 语句后加上 limit 5 ,就是将这次查询结果的前5条显示或者说返回出来
limit经常与 offset 在一起使用
offset 指的是起始行的偏移量(从 0 开始),即要跳过的行数,通俗点讲,就是从第几行开始查询,比如 offset 5 就是跳过前 5 行数据,从第 5 行开始查询(行数是从 0 开始算的,所以此处是5不是6)
比如在原本的 select 语句后加上 limit 5 offset 6,表示从第6行数据开始查询,查询5条数据
需要注意的是,MySQL是先执行查询,再应用 limit 条件,这意味着MySQL?会尝试获取满足查询条件的所有记录,然后再截取所需的行数返回给用户
这当然会影响性能,但是,如果使用了一些优化技术(例如索引、分区等),MySQL可能会尽量使用这些优化来提前终止或限制查询,以优化性能。此外,某些情况下也可以通过 order by 和 where 子句的优化来提前限制数据,但这并不是MySQL的标准行为
当然,兵来将挡,水来土掩,方法总比困难多,因此,这里的问题也不会是太大的问题
9、MySQL中的排序和分组
?在MySQL中,order by 和 group by 是用于查询结果进行排序和分组的关键字
order by 相对来说在实际开发中用的更多,它的作用是对查询结果按照指定的列进行排序,默认是升序排序,手动指定升序排序关键字是 ASC,需要在列名后使用,降序排序关键字是 DESC
例如将name按照升序排序:
SELECT * FROM table_name ORDER BY name ASC;
将name按照降序排序:
SELECT * FROM table_name ORDER BY name DESC;
group by 的作用是对查询结果按照指定的列进行分组,通常与聚合函数一起使用(如 sum()、count() )等
比如,现在要计算员工工资,按照 department 列进行分组:
SELECT department, SUM(salary) as total_salary
FROM employees
GROUP BY department;
?使用group by 需要满足两个条件,其实,有些条件不属于死规定的条件,而是代码写出来后冲突与规范渐渐形成的条件
- 出现在 select 列表中的列名必须在 group by 子句中
- 如果 select 中使用了 聚合函数,则可以不用出现在 group by 中
order by 和 group by 可以结合使用,可以在 group by 之后对分组的结果进行排序
注:当面试官问到9问题时,我们可以主动把10也讲给他,绝对加分!
10、如果A字段升序,B字段降序,写个SQL该如何写
?注:若你只是单独看了10,没看9,建议把9也回去看一下
SELECT *
FROM your_table
ORDER BY column1 ASC, column2 DESC; -- 按第一列升序,第二列降序
?以上查询将对第一列按升序排序,对第二列按降序排序?
11、left join 、right join 和 inner join
?left join 、right join 和 inner join 都是 SQL 中用于合并表的方法,但它们有着不同的行为
在SQL中,这几个join都需要配合 on 子句来指定连接条件?
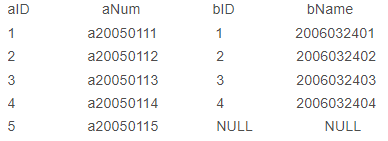
left join
以A表(左表)为基础,返回A表中的所有行,以及与B表(右表)中所匹配的行
如果右表中没有与之匹配的行,则右表返回 NULL 值
SELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column;例如sql语句: select * from A left join B on A.aID = B.bID
结果如下:
right join
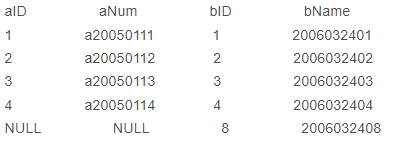
与 left join 相反?
以B表(右表)为基础,返回B表中的所有行,以及与A表(左表)中所匹配的行
如果左表中没有与之匹配的行,则左表返回 NULL 值
例如sql语句: select * from A right join B on A.aID = B.bID
结果如下:
inner join
不以谁为基础,只返回符合匹配条件的行
例如sql语句: select * from A inner join B on A.aID = B.bID
结果如下:
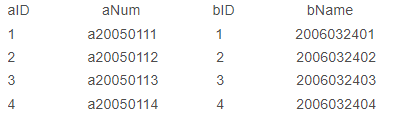
详细总结(注意事项)
- 这里就把薄弱点都说一下吧,迭代器忘得有点狠,下载文件具体的逻辑和操作确实也不是非常了解
- MySQL基础较差,这个确实怪自己,现在智能工具太多了,自己就懒了
- 不过这几个问题看一下八股和复习一下,都很好解决,下载文件这个需要具体在项目中实操一下,“下载文件” 这个还是非常重要的,会有很多面试问到
?
?🧸祝大家拿到理想的 offer !!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python爬虫框架选择与使用:推荐几个常用的高效爬虫框架
- 服务器运维小技巧(一)——如何进行远程协助
- [计网]运输层 湖科大第五章
- ADKEY多按键制作阻值选择2(回答网友问题)
- HTML5+CSS3小实例:人物介绍卡片2.0
- Intel? Enclave Exiting Events(四)
- springboot基于Java的大学生迎新系统
- AOSP源码下载方法,解决repo sync错误:android-13.0.0_r82
- CogAgent:带 Agent 能力的视觉模型来了
- 计算机组成原理(存储器的校验)